 簡述OpenVINO? + ResNet實現圖像分類
簡述OpenVINO? + ResNet實現圖像分類
推理引擎(IE)應用開發流程
與相關函數介紹
通過OpenVINO的推理引擎跟相關應用集成相關深度學習模型的應用基本流程如下:
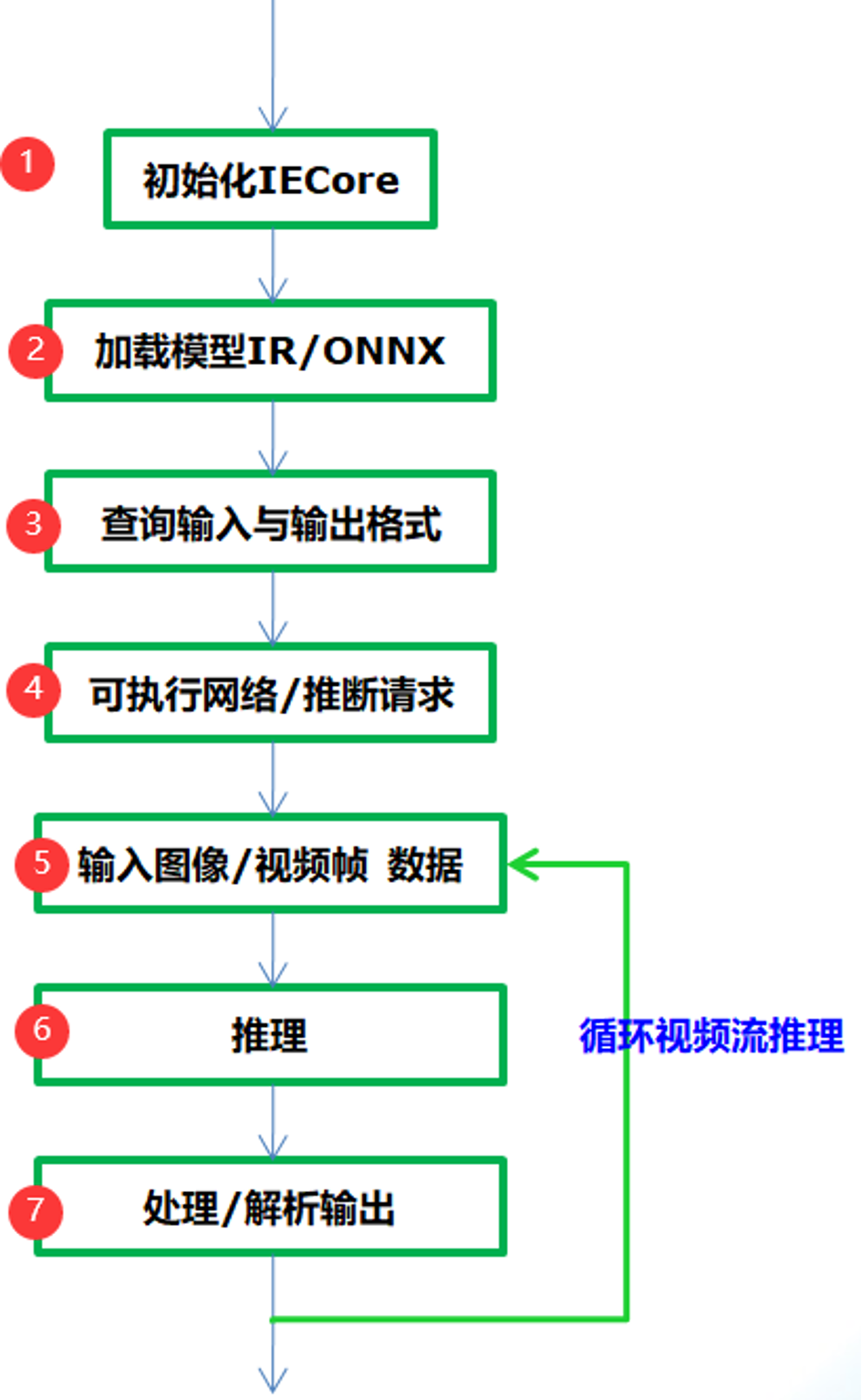
圖-1
從圖-1可以看到只需要七步就可以完成應用集成,實現深度學習模型的推理預測,各步驟中相關的API函數支持與作用解釋如下:
Step 1:
InferenceEngine::Core // IE對象
Step 2:
Core.ReadNetwork(xml/onnx)輸入的IR或者onnx格式文件,返回CNNNetwork對象
Step 3:
InferenceEngine::InputsDataMap, InferenceEngine::InputInfo, // 模型輸入信息
InferenceEngine::OutputsDataMap // 模型輸出信息
使用上述兩個相關輸入與輸出對象就可以設置輸入的數據類型與精度,獲取輸入與輸出層的名稱。
Step 4:
ExecutableNetwork LoadNetwork (
const CNNNetwork &network,
const std::string &deviceName,
const std::map< std::string, std::string > &config={}
)
通過Core的LoadNetwork方法生成可執行的網絡,如果你有多個設備,就可以創建多個可執行的網絡。其參數解釋如下:
network 參數表示step2加載得到CNNNetwork對象實例
deviceName表示模型計算所依賴的硬件資源,可以為CPU、GPU、 FPGA、 FPGA、MYRIAD
config默認為空
InferRequest InferenceEngine::CreateInferRequest()
表示從可執行網絡創建推理請求。
Step 5:
根據輸入層的名稱獲取輸入buffer數據緩沖區,然后把輸入圖像數據填到緩沖區,實現輸入設置。其中根據輸入層名稱獲取輸入緩沖區的函數為如下:
Blob::Ptr GetBlob (
const std::string &name // 輸入層名稱
)
注意:返回包含輸入層維度信息,支持多個輸入層數據設置!
Step 6:
推理預測,直接調用推理請求的InferRequest.infer()方法即可,該方法無參數。
Step 7:
調用InferRequest的GetBlob()方法,使用參數為輸出層名稱,就會得到網絡的輸出預測結果,根據輸出層維度信息進行解析即可獲取輸出預測信息與顯示。
圖像分類與ResNet網絡
圖像分類是計算機視覺的關鍵任務之一,關于圖像分類最知名的數據集是ImageNet,包含了自然場景下大量各種的圖像數據,支持1000個類別的圖像分類。OpenVINO在模型庫的public中有ResNet模型1000個分類的預訓練模型支持,它們主要是:
- resnest-18-pytorch
- resnest-34-pytorch
- resnest-50-pytorch
- resnet-50-tf
其中18、34、50表示權重層,pytorch表示模型來自pytorch框架訓練生成、tf表示tensorflow訓練生成。ResNet系列網絡的詳細說明如下:
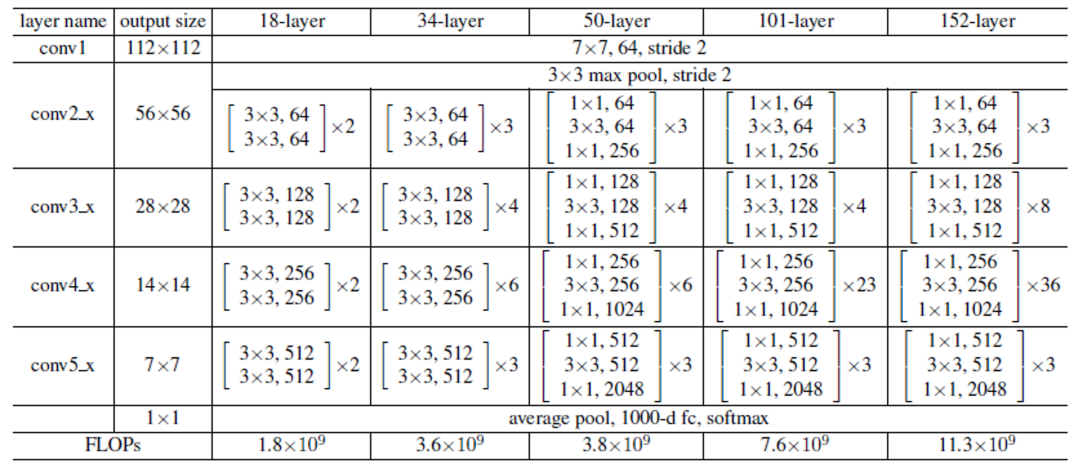
圖-2(來自《Deep Residual Learning for Image Recognition》論文)
我們以ResNet18-pytorch的模型為例,基于Pytorch框架我們可以很輕松的把它轉換為ONNX格式文件。然后使用Netron工具打開,可以看到網絡的輸入圖示如下:

圖-3
查看網絡的輸出:
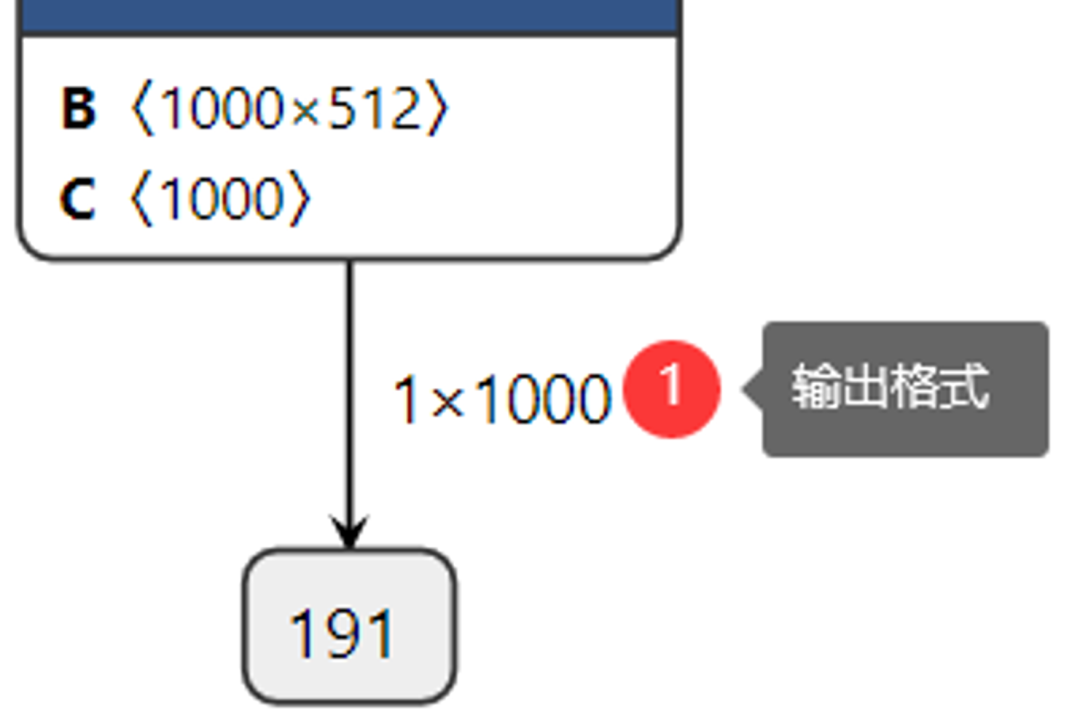
圖-4
這樣我們很清楚的知道網絡的輸入與輸出層名稱,輸入數據格式與輸出數據格式,其中輸入數據格式NCHW中的N表示圖像數目,這里是1、C表示圖像通道數,這里輸入的是彩色圖像,通道數為3、H與W分別表示圖像的高與寬,均為224。在輸出格式中1x1000中1表示圖像數目、1000表示預測的1000個分類的置信度數據。
程序實現的基本流程與步驟
前面已經介紹了IE SDK相關函數,圖像分類模型ResNet18的輸入與輸出格式信息。現在我們就可以借助IE SDK來完成一個完整的圖像分類模型的應用部署了,根據前面提到的步驟各步的代碼實現與解釋如下:
1. 初始化IE
InferenceEngine::Core ie;
2. 加載ResNet18網絡
InferenceEngine::CNNNetwork network = ie.ReadNetwork(onnx);
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
3. 獲取輸入與輸出名稱、設置輸入與輸出數據格式
std::string input_name = "";
for (auto item : inputs) {
input_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);
std::cout << "input name: " << input_name << std::endl;
}
std::string output_name = "";
for (auto item : outputs) {
output_name = item.first;
auto output_data = item.second;
output_data->setPrecision(Precision::FP32);
std::cout << "output name: " << output_name << std::endl;
}
4. 獲取推理請求對象實例
auto executable_network = ie.LoadNetwork(network, "CPU");
auto infer_request = executable_network.CreateInferRequest();
5. 輸入圖像數據設置
auto input = infer_request.GetBlob(input_name);
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h*w;
cv::Mat blob_image;
cv::resize(src, blob_image, cv::Size(w, h));
cv::cvtColor(blob_image, blob_image, cv::COLOR_BGR2RGB);
blob_image.convertTo(blob_image, CV_32F);
blob_image = blob_image / 255.0;
cv::subtract(blob_image, cv::Scalar(0.485, 0.456, 0.406), blob_image);
cv::divide(blob_image, cv::Scalar(0.229, 0.224, 0.225), blob_image);
// HWC =》NCHW
float* data = static_cast
}
}
}
在輸入數據部分OpenCV導入的圖像三通道順序是BGR,所以要轉換為RGB,resize到224x224大小、像素值歸一化為0~1之間、然后要減去均值(0.485, 0.456, 0.406),除以方差(0.229, 0.224, 0.225)完成預處理之后再填充到Blob緩沖區中區。
6. 推理
infer_request.Infer();
7. 解析輸出與顯示結果
auto output = infer_request.GetBlob(output_name);
const float* probs = static_cast
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[0] << "x" << outputDims[1] << std::endl;
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++) {
if (max < probs[i]) {
max = probs[i];
max_index = i;
}
}<:fp32>
cv::putText(src, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("輸入圖像", src);
cv::waitKey(0);
解析部分代碼首先通過輸出層名稱獲取輸出數據對象BLOB,然后根據輸出格式1x1000,尋找最大值對應的index,根據索引index得到對應的分類標簽,然后通過OpenCV圖像輸出分類結果。
運行結果
圖-5(來自ImageNet測試集)
這樣我們就使用OpenVINO 的推理引擎相關的SDK函數支持成功部署ResNet18模型,并預測了一張輸入圖像。你可以能還想知道除了圖像分類模型,OpenVINO 推理引擎在對象檢測方面都有哪些應用,我們下次繼續…….
編輯:jq
-
函數
+關注
關注
3文章
4368瀏覽量
64180 -
代碼
+關注
關注
30文章
4886瀏覽量
70245 -
OpenCV
+關注
關注
32文章
642瀏覽量
42420 -
SDK
+關注
關注
3文章
1065瀏覽量
47673
原文標題:OpenVINO? + ResNet實現圖像分類
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
在友晶LabCloud平臺上使用PipeCNN實現ImageNet圖像分類

基于RV1126開發板實現自學習圖像分類方案

基于RV1126開發板的resnet50訓練部署教程

在Visual Studio中使用OpenVINO? C API時無法讀取網絡怎么解決?
如何部署OpenVINO?工具套件應用程序?
使用Python API在OpenVINO?中創建了用于異步推理的自定義代碼,輸出張量的打印結果會重復,為什么?
安裝OpenVINO? 2023.2使用pip install openvino-dev命令的開發工具后報錯怎么解決?
安裝OpenVINO?工具包穩定擴散后報錯,怎么解決?
C#集成OpenVINO?:簡化AI模型部署

高通AI Hub:輕松實現Android圖像分類

使用卷積神經網絡進行圖像分類的步驟
基于改進ResNet50網絡的自動駕駛場景天氣識別算法






 工商網監
工商網監
評論