") 深度解讀對殘差網(wǎng)絡(luò)動機的理解
深度解讀對殘差網(wǎng)絡(luò)動機的理解

神經(jīng)網(wǎng)絡(luò)以其強大的非線性表達(dá)能力而獲得人們的青睞,但是將網(wǎng)絡(luò)層數(shù)加深的過程中卻遇到了很多困難,隨著批量正則化,ReLU 系列激活函數(shù)等手段的引入,在多層反向傳播過程中產(chǎn)生的梯度消失和梯度爆炸問題也得到了很大程度的解決。然而即便如此,隨著網(wǎng)絡(luò)層數(shù)的增加導(dǎo)致的擬合能力退化現(xiàn)象依然存在,如下圖所示
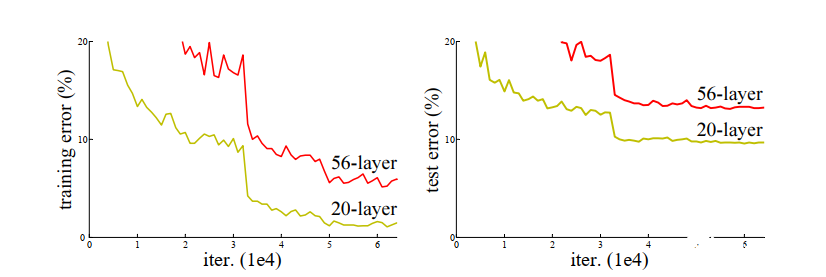
可以看到,訓(xùn)練誤差和測試誤差都隨網(wǎng)絡(luò)層數(shù)的增加而增加,可以排除過擬合造成的預(yù)測性能退化。所以這里存在一個邏輯上講不通的問題,通常來說,我們認(rèn)為神經(jīng)網(wǎng)絡(luò)可以學(xué)習(xí)出任意形狀的函數(shù),具體到這個問題上來,假如淺層網(wǎng)絡(luò)可以獲得一個不錯的效果,那么理論上深層網(wǎng)絡(luò)增加的額外層只需要學(xué)會恒等映射,即可獲得與淺層網(wǎng)絡(luò)相同的預(yù)測精度
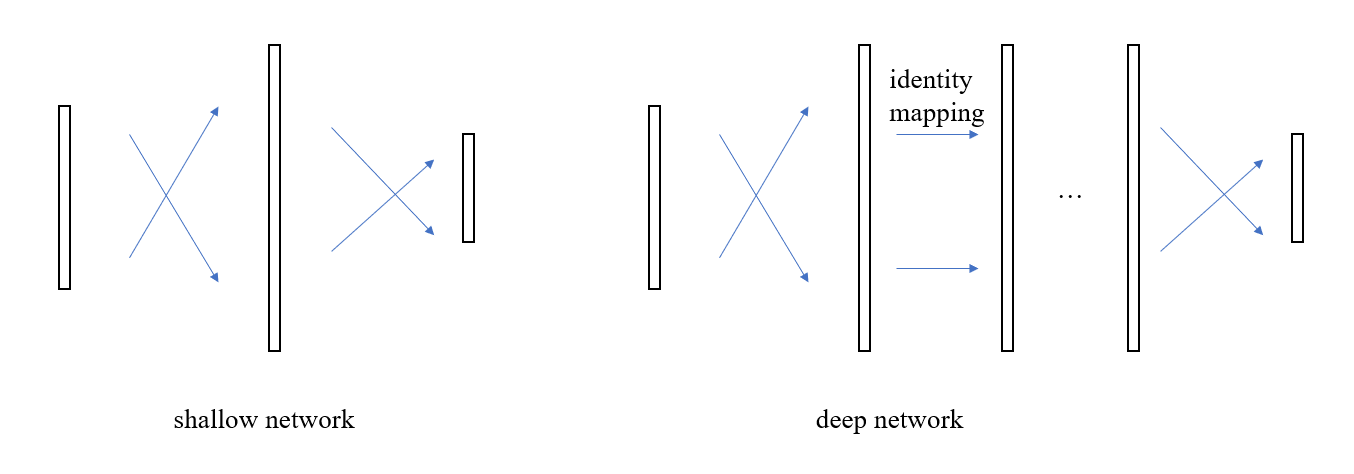
但實際情況根本不是這么回事兒,那么問題出在哪兒了呢?我們一廂情愿的認(rèn)為中間層能夠?qū)W會恒等映射,但事與愿違,這一假設(shè)不成立,也就是說,具有很強的非線性擬合能力的傳統(tǒng)神經(jīng)元結(jié)構(gòu)卻連最簡單的恒等映射都模擬不了,抓住這一要點后,新的優(yōu)化方向便映入眼簾了,既然這種交叉連接的神經(jīng)元無法實現(xiàn)恒等映射,那么再增加一路恒等映射的連接不就行了
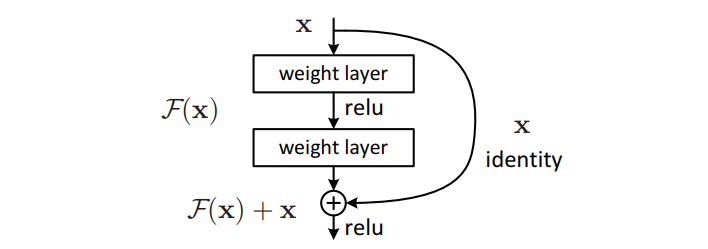
這樣一來,假如兩層之間的恒等映射是最優(yōu)解,就像之前提到的那種情況,那么只需要權(quán)重層,即圖中的 weight layer,學(xué)會把所有的權(quán)重都設(shè)為 0 就行了,而這種學(xué)習(xí)任務(wù)是很簡單的。
所以可以總結(jié)道,resnet 的提出是因為發(fā)現(xiàn)了普通的神經(jīng)網(wǎng)絡(luò)連接方式無法實現(xiàn)有效的恒等映射,于是額外增加了一路恒等連接層來輔助學(xué)習(xí)。體現(xiàn)在最終效果上就是說普通神經(jīng)網(wǎng)絡(luò)的連接方式更容易學(xué)習(xí)到殘差,所以這種方式就被稱為殘差學(xué)習(xí)。
編輯:jq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103550 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4379瀏覽量
64827
發(fā)布評論請先 登錄
直播 | GB/T 45086與ISO11451標(biāo)準(zhǔn)深度解讀研討會筆記請查收!

輪式移動機器人電機驅(qū)動系統(tǒng)的研究與開發(fā)
革命性神經(jīng)形態(tài)微控制器 ?**Pulsar**? 的深度技術(shù)解讀
瑞薩365 深度解讀
ARM Mali GPU 深度解讀
Arm 公司面向 PC 市場的 ?Arm Niva? 深度解讀
英偉達(dá)Cosmos-Reason1 模型深度解讀
DLP3010顯示殘影是什么原因?qū)е碌模吭趺唇鉀Q?
深度解讀 30KPA64A 單向 TVS:64V 擊穿機制與高效防護(hù)策略

BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
請問DAC5682z內(nèi)部FIFO深度為多少,8SAMPLE具體怎么理解?
4G模組加解密藝術(shù):通用函數(shù)的深度解讀






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論