 探究當量子計算遇上到機器學習會摩擦出什么火花?
探究當量子計算遇上到機器學習會摩擦出什么火花?

機器學習一直都很熱門,自不必多言;量子計算能引起這么高的熱度,到底是憑什么?一起來看看本文如何解讀~
作者 | Dr.Alessandro Crimi
譯者| 蘇本如
量子計算和機器學習已經成為當今炙手可熱的話題。排除一些明顯的炒作外,這當中也有一些真正的基礎。隨著傳統計算技術的發展,基于機器學習等領域的圖像相關分析已經取得了令人難以置信的成果。另一方面,量子物理學一直是一個令人難解的神秘領域,它引起了數學(以及許多完全不科學的偽科學)發展的突飛猛進。量子計算正在成為克服傳統計算的一些局限性的新方法,包括晶體管小型化的物理限制。 1在過去的一年里,人們已經將量子計算作為神經網絡的層級,或者將其視為樸素貝葉斯分類器。2020 年 3 月,谷歌宣布發布 TensorFlow Quantum,這是一系列將最先進的機器學習與量子計算算法結合在一起的工具。 簡而言之,這個工具的思路是將量子計算作為分類系統中的一個步驟,但我們也可能反過來考慮。
量子機器學習分類器的典型設置(圖片由作者提供)
另一種方法是由 Q-CTRL 公司創新提出的,Q-CTRL 一家專注于量子計算的公司,位于悉尼和洛杉磯。這種方法已經得到驗證,它將重點放在量子計算上,并有效地使用機器學習來抑制量子硬件噪聲和缺陷的影響。
大多數量子計算機硬件可以在不到一毫秒的時間內完成計算,但是因為噪音的影響而需要復位,其導致的性能目前還不如低成本的筆記本電腦。這個結果比我們聽到的要糟糕得多,在下一節中我會詳細解釋這一點。
量子退相干(DECOHERENCE)
量子位(也叫量子比特,qu-bits),這個經典二進制位在量子計算機中的量子版本,當它暴露于硬件噪聲中時,其中的信息非常容易退化。這個過程被稱為量子退相干(decoherence)。這是我們仍處于量子計算初期的原因之一。
下面是我提供的屏幕截圖,一個是理想情況下的一個量子位的預期結果,另一個是在硬件噪聲影響下的結果。從一個量子位來看,結果似乎沒有那么糟糕,但是想象一下執行一項任務所需要的所有量子位,就可以想象被噪聲影響的結果有多大(即使和一個樹莓派卡式電腦或手機相比)。
從上圖看到的一個量子位的預期結果
受噪聲影響的一個量子位的結果
如何解決量子退相干問題?自 90 年代后期以來,像安德魯·斯蒂恩(Andrew Steane)和彼得·肖爾(PeterShor)這樣的專家已經提出了一些模型,這些模型通過引入某種冗余來補償它。然而,如果考慮到需要引入大量的量子位(你需要將每個量子比特重復幾次),這種方法在我們現有的量子計算機上實際是不可行的。
Q-CTRL 公司的解決方案是創建基于機器學習的固件,該固件可以修復量子退相干,而不需要額外的不可行的硬件。
量子計算硬件是基于光-物質的交互作用(光學硬件)來執行量子邏輯運算的。這些電磁信號的組成實際上是一種算法,可由機器學習工具定義/細化。這個笨重的圓圈應該會減少量子退相干。要真正理解這種方法,需要具備一個典型的機器學習專家所不具備的量子計算方面的知識。我將在下面部分盡力做個介紹。 Q-CTRL 解決方案被稱為 BOULDER OPAL,它是一個 Python 包,可以通過在終端機器中鍵入如下命令來輕松安裝:
pipinstallqctrl并簡單地執行以下的導入命令:
fromqctrlimportQctrl
接下來的工作就是如何設置哈密頓算子(Hamiltonian),dephase,control 等等參數了…,這些是另外一個單獨的話題(如果你感興趣,可以從下面給出的的參考資料中學習,或者閱讀這個文檔)。關鍵點是要實現控制并降低噪聲,可以通過使用 TensorFlow 或其他機器學習工具來獲得基于復雜梯度的優化方法,這些將在下面關于強化學習的部分中討論。
強化學習(REINFORCEMENTLEARNING)
在可以用來控制噪聲的優化中,強化學習已經得到了成功的應用。強化學習是機器學習的一個領域,在該領域中,智能代理(agent)會在一個環境中采取行動,以最大化累積獎勵。
量子硬件中強化學習的整體視圖。圖片來源于iStock 通過量子計算中的強化學習,學習者(Learner)可以通過對量子設備本身進行實驗來創建一個優化的脈沖。此外,強化學習可以發現和利用我們不知道的新物理機制。然而,這樣做的缺點是學習者無法告訴你如何找到解決方案,因此我們無法了解設備中噪聲抑制的物理原理。 對于那些習慣于機器學習而非量子計算的人們,我將在量子物理和強化學習使用的術語之間建立一座橋梁:量子計算機被視為是一個機器學習代理(agent)的環境。該代理的任務是實現執行高保真門的目標。agent 能夠對環境做出各種動作(在我們的例子中,是將脈沖施加到量子計算機)。
agent 通過使用一組可測量的可觀察值和基于與目標的接近程度的獎勵來學習,以實現其目標。我們的獎勵來自門保真度。經過多次實驗,學習算法利用這些信息來提高 agent 的性能。 總結
為了了解環境和狀態,agent 向量子計算機部署了一系列脈沖。
然后 agent 獲取此狀態,并使用此信息來決定下一步要執行的操作。
在實踐中,agent 獲取狀態并使用神經網絡來決定對下一段脈沖采取什么行動。我們對脈沖的幅度進行量化,以便 learner 從一組有限的選項中進行選擇。 一個完整的門脈沖被稱為一個 episode,在 episode 結束時對 agent 的獎勵(在強化學習術語中)由狀態給出。這使我們能夠將誤差信號提升到測量噪聲之上。 上述強化學習可以在多種學習者中進行,包括深度策略梯度(DPG)、深度確定性策略梯度(DDPG)和 SAC(Soft Actor Critic)算法。所有這些 learner 都有超參數,必須先對其進行調整,然后才能用于真正的實驗 實驗可以在 IBM 的量子計算機上運行,也可以結合眾所周知的量子計算工具(如 QSkit)和機器學習工具(如 SciKit-learn)。 這種基于機器學習的優化量子計算方法已經證明可以減少硬件錯誤并提高門保真度(如下圖):
圖片來源:Q-CTRL/悉尼大學(Mavadiaet al. Nature Com. 2017)
參考資料
M. Hidary:Quantum computing: an applied approach
T.Jaksch、R.Ortner和P.Auer:Near-optimal Regret Bounds forReinforcement Learning
Q-CTRL Quantum Firmware
英文標題:Don’t ask what Quantum Computing can do for MachineLearning
編輯:lyn
-
機器學習
+關注
關注
66文章
8499瀏覽量
134394 -
量子計算
+關注
關注
4文章
1144瀏覽量
35640
原文標題:當量子計算遇到機器學習
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
量子計算最新突破!“量子+AI”開啟顛覆未來的指數級革命

基于玻色量子相干光量子計算機的混合量子經典計算架構
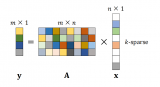
機器人與火炬手擊掌互動!搭載KaihongOS的樂聚“夸父”人形機器人助力亞冬會


量子通信與量子計算的關系
量子計算機與普通計算機工作原理的區別

當AI遇上質檢會擦出什么樣的火花
華為公開量子計算新專利
本源產品丨量子計算機應用——《QPanda量子計算編程》

中國量子計算機證明是可用的——《瞭望》刊發中國量子信息奠基人郭光燦院士專訪
會議通知 | 2024量子計算產業峰會暨量子計算開發者大會將在廣州舉辦





 工商網監
工商網監
評論