 NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄
NVIDIA Blackwell GPU優化DeepSeek-R1性能 打破DeepSeek-R1在最小延遲場景中的性能紀錄

近年來,大語言邏輯推理模型取得了顯著進步,但也帶來了新的部署挑戰。其中,因復雜的“思考與邏輯推理”過程而引起的輸出序列長度 (OSL) 的加長已成為一大難題。OSL 的加長提高了對 token 間延遲 (Token-to-Token Latency, TTL) 的要求,往往會引發并發限制。在最極端的情況下,實時應用會面臨單并發(最小延遲場景)這一特別棘手的問題。
本文將探討NVIDIATensorRT-LLM如何基于 8 個 NVIDIA Blackwell GPU 的配置,打破 DeepSeek-R1 在最小延遲場景中的性能紀錄:在 GTC 2025 前將 67 token / 秒 (TPS) 的速度提升至 253 TPS(提速3.7 倍),而目前這一速度已達 368 TPS(提速5.5 倍)。
實現配置
一、工作負載配置文件
輸入序列長度 (ISL):1000 token
輸出序列長度 (OSL):2000 token
二、模型架構
DeepSeek-R1 的基礎主模型包含:3 個密集層(初始)和 58 個 MoE 層,此外還有 1 個多 token 預測 (Multi-Tokens Prediction, MTP) 層(相當于 MoE 架構)用于推測性解碼。我們的優化配置將 MTP 層擴展成 3 個層,采用自回歸方法探索其最大性能。
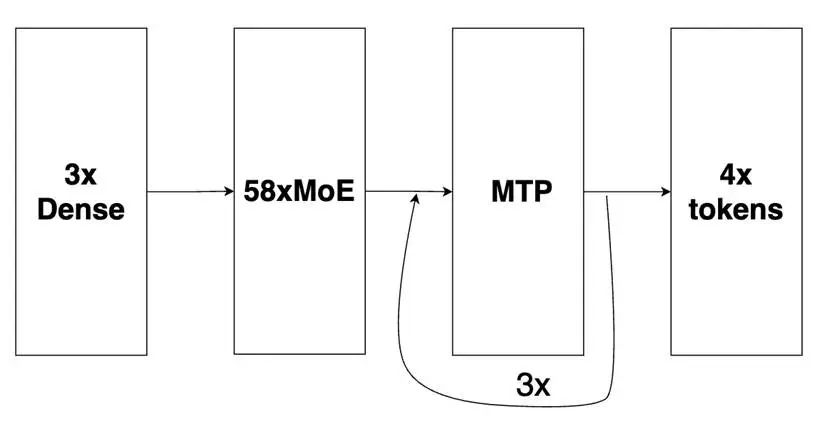
圖1: DeepSeek-R1 的基礎主模型
該圖片來源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
三、精度策略
我們探索出了一種能夠更好平衡準確度與性能的混合精度方案。
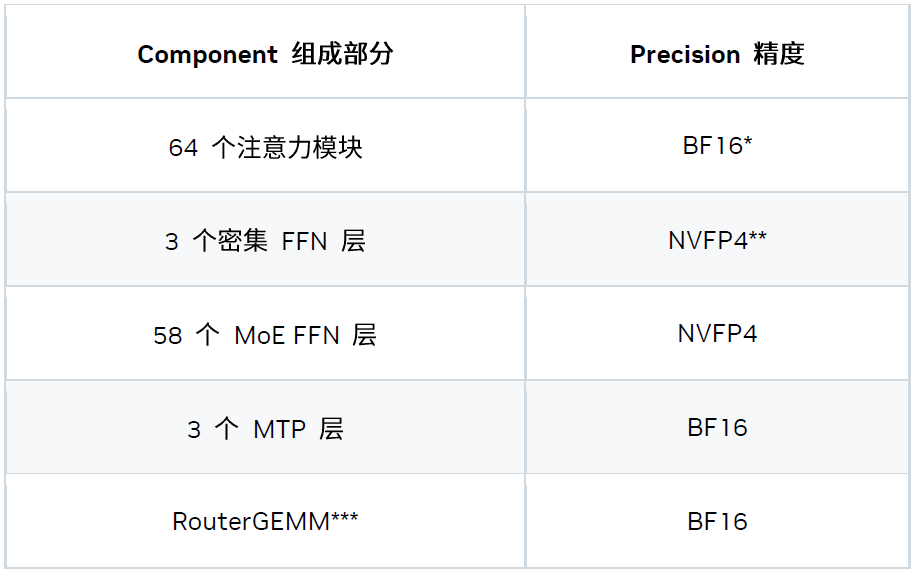
* TensorRT-LLM 已支持 FP8 Attention。但在該延遲場景下,低精度注意力計算并不能提升性能,因此我們為注意力模塊選擇了 BF16 精度。
** NVFP4 模型檢查點由 NVIDIA TensorRT 模型優化器套件生成。
*** RouterGEMM 使用 BF16 輸入 / 權重與 FP32 輸出來確保數值的穩定性
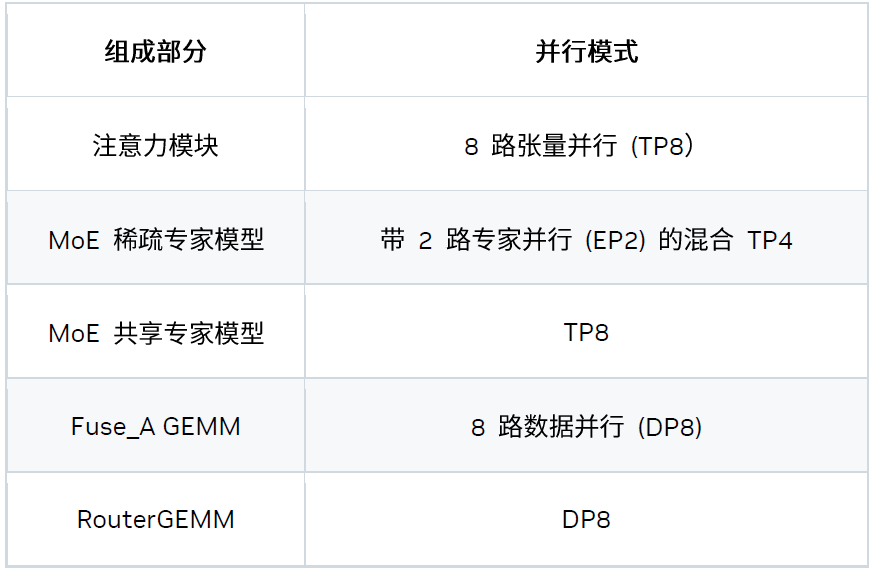
四、并行策略
我們還在 8 個 Blackwell GPU 上嘗試并引入了混合并行策略。具體而言,該延遲場景的最佳策略為 “TP8EP2”,其定義如下:
五、一圖整合
現在,我們將所有內容整合成一張圖,該圖表示的是解碼迭代中的一個 MoE 層。

該圖片來源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
圖中的模塊包括:
-
輸入模塊:一個形狀為 [m, 7168] 的 BF16 張量,其中 m 表示 token 數量(例如使用 3 個 MTP 層時 m = 4),7168 為模型的隱藏大小。
-
模塊 1:Fuse_A_GEMM 拼接 WDQ、WDKV 和 WKR 的權重,以減少內核調用開銷。
-
模塊 2:2 個 RMSNorm 對 Q / K 張量進行歸一化。這些張量可以重疊在多個流上,也可以合并成單個分組 RMSNorm。
-
模塊 3:UQ_QR_GEMM 拼接 WUQ 和 WQR 的權重,以減少內核調用開銷。
-
模塊 4:UK_BGEMM 在批量 GEMM 中使用 WUK。為防止權重規模膨脹和產生新的加載成本,我們未加入模塊 3 和 4。
-
模塊 5:Concat KVCache & applyRope 合并 K / V 緩存并應用 ROPE(旋轉位置編碼)。
-
模塊 6:genAttention 在生成階段執行 MLA,作用類似于 num_q_heads = 128 / TP8 = 16 的 MQA
-
模塊 7:UV_GEMM 執行帶 WUV 權重的批量 GEMM。
-
模塊 8:WO_GEMM 使用 WO 權重運行密集 GEMM。為避免增加權重加載的開銷,我們未加入模塊 7 和 8。
-
模塊 9:融合內核將 oneshotAllReduce、Add_RMSNorm 和 DynamicQuant (BF16->NVFP4) 整合到單個內核中。
-
模塊 10:routerGEMM & topK 處理路由器 GEMM (Router GEMM) 和 topK 選擇。
-
模塊 11:共享專家模型與模塊 10 和模塊 12 部分重疊。
-
模塊 12:稀疏專家模型通過分組 GEMM (Grouped GEMM) 實現專家層。
-
模塊 13:最終融合內核同時執行 localReduction、oneshotAllReduce 和 Add_RMSNorm 操作。
主要優化
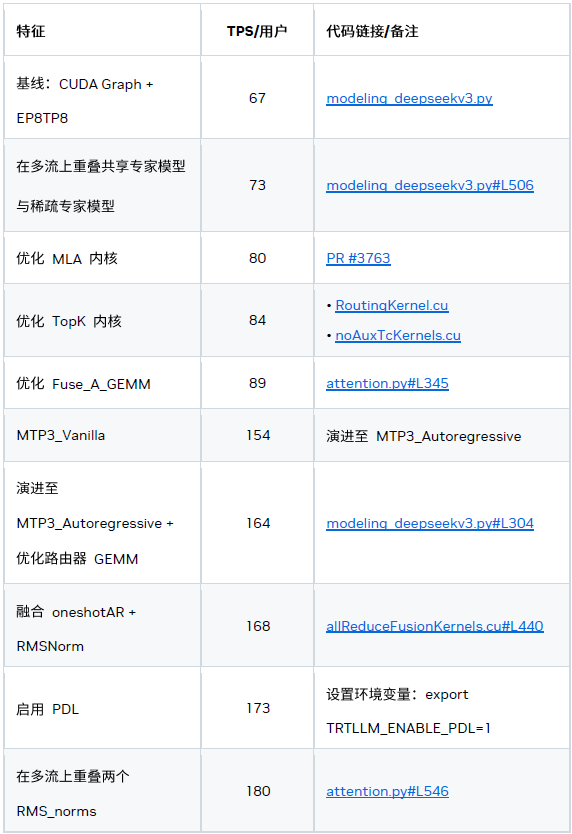
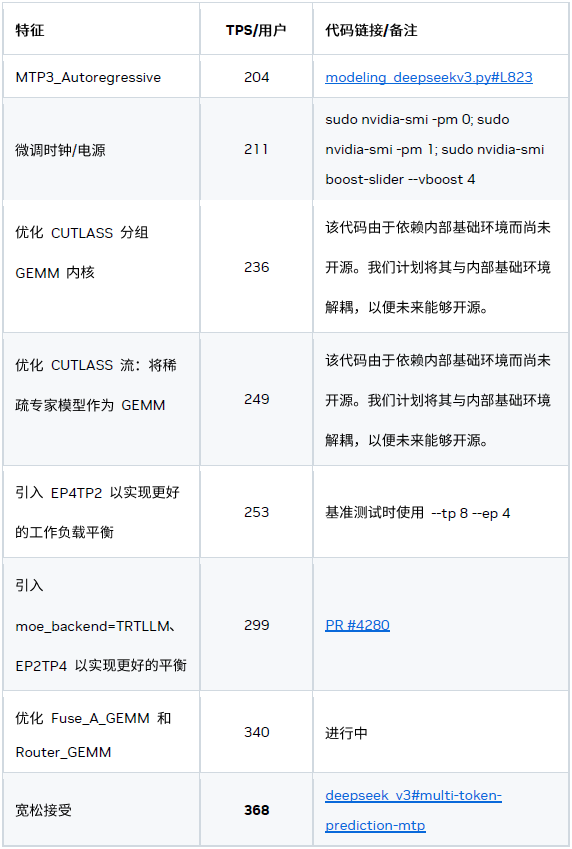
一、系統級優化
1、CUDA Graph 與可編程依賴啟動
CUDA Graph 對于克服小型工作負載中的 CPU 開銷必不可少,而可編程依賴啟動可進一步降低內核啟動延遲。
2、MTP
基于 MTP 的兩種優化措施:
1) 自回歸 MTP 層
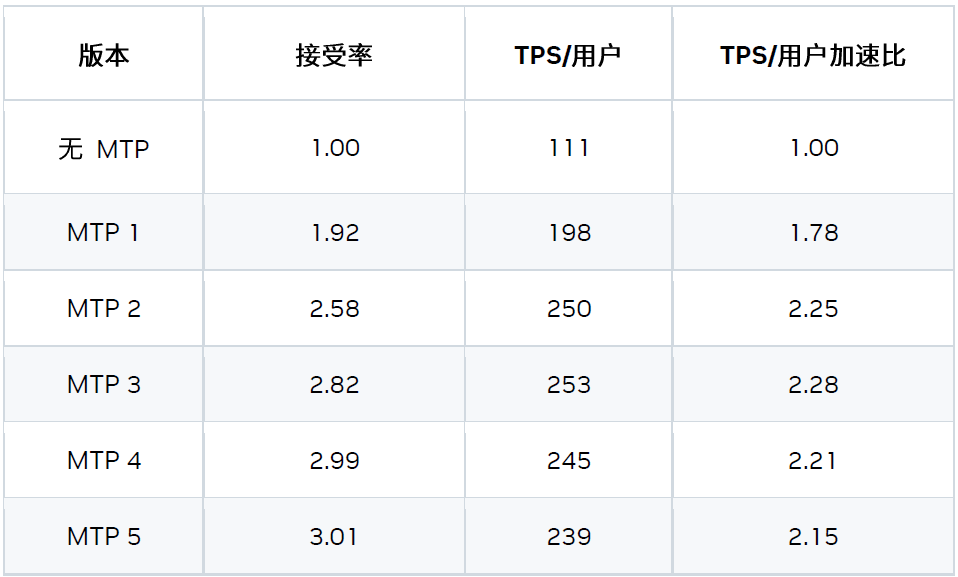
根據我們的研究結果,3x MTP 層的配置性能最佳。
2) 寬松接受驗證
邏輯推理模型 (如 DeepSeek R1) 的生成過程可以分為兩個階段:思考階段和實際輸出階段。在思考階段,如果啟用寬松接受 (Relax Acceptance) 模式,候選 token 處于候選集時即可被接受。該候選集基于 logits topN 和概率閾值生成。
-
topN:從 logits 中采樣前 N 個 token。
-
概率閾值:基于 topN 個候選 token,只有概率大于 Top1 的概率減去 delta 的 token 時可保留在候選集。
在非思考階段,我們仍采用嚴格接受模式。
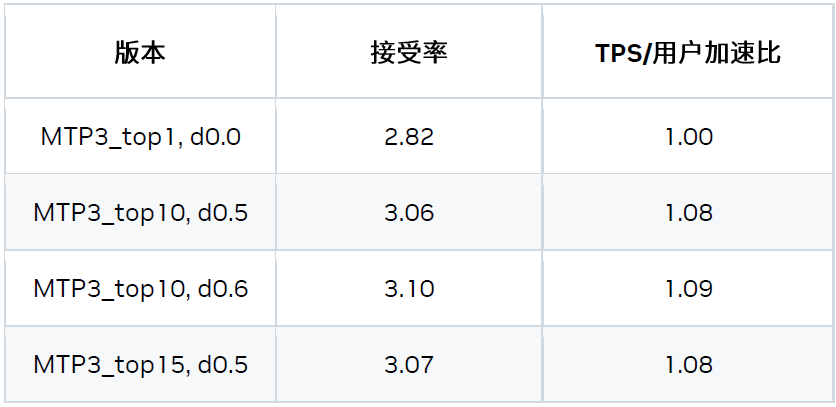
這是一種寬松的驗證和比較方法,可以在對精度影響很小的情況下,提升接受率并帶來加速。
如需了解更多信息,請訪問:
multi-token-prediction-mtp
3、多流
我們引入了基于多流的優化措施以隱藏部分內核的開銷,例如:
-
將共享專家模型與稀疏專家模型重疊
-
將 Concat_KVCache 內核與 GEMM 重疊
稀疏專家模型作為 GEMM (僅當 moe_backend=CUTLASS 時有效)
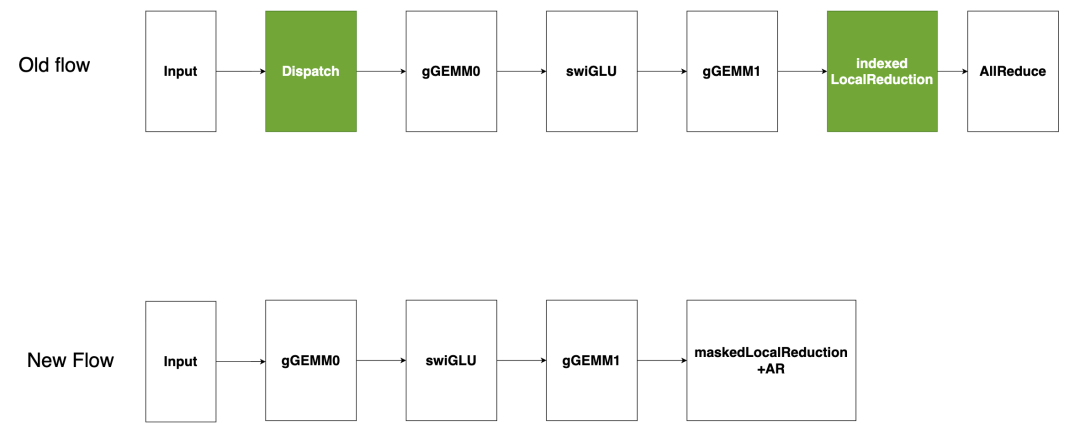
該圖片來源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
現有的基于 CUTLASS 的稀疏專家模型流(如圖所示)將輸入的 token 分發到指定的專家模型,然后在每個專家模型的輸出上進行索引式的局部歸約,最后進行全局AllReduce。分發和索引局部歸約在低延遲場景下會產生高開銷。為解決此問題,我們提出將“稀疏專家模型作為 GEMM”處理,即將所有 token 發送至每個激活的專家模型,并在局部歸約前屏蔽不需要的輸出。由于分組 GEMM 受顯存限制,冗余 token 產生的額外計算開銷幾乎沒有影響,有效避免了昂貴的分發,同時減少開銷。
4、重新平衡稀疏專家模型
稀疏專家模型常用的并行化策略有兩種:專家并行 (EP) 和張量并行 (TP)。專家并行 (EP) 將每個專家模型分配到獨立的 GPU,以此實現高顯存和計算效率。但 token 放置依賴于數據,導致 GPU 間工作負載分布不均,并在 MoE 模塊后的 AllReduce 步驟中顯示額外開銷。張量并行 (TP) 將每個專家模型均勻劃分到多個 GPU,雖平衡了工作負載,但卻犧牲了數學 / 顯存效率。
-
混合 ETP
結合 EP / TP 的混合方法可緩解上述問題。實驗結果表明,TP4EP2 配置在實際中表現最佳。
-
智能路由器
另一方案是將所有專家模型權重存儲在由 4 個 GPU 組成的集群中,隨后將其復制到另一個 4 GPU 集群,智能路由器可將 token 動態地分配到各集群。該設計在不顯著影響本地顯存和計算效率的前提下,保持了工作負載分布的平衡。
二、內核級優化
1、注意力內核
我們開發了定制的 MLA 注意力內核,以便更好地使用 GPU 資源應對延遲場景。
2、分組 GEMM
-
CUTLASS 后端(默認后端)
我們的默認 MoE 后端基于 CUTLASS,該后端具有靈活性和穩定性,但可能不是最佳的性能方案。
-
TensorRT-LLM 后端
另一個 MoE 后端是 TensorRT-LLM,其性能更優。我們正在努力提高其靈活性和穩定性,未來將作為延遲場景中分組 GEMM 計算的默認后端。
3、通信內核
對于小規模消息,受常規 NCCL 延遲影響的 AllReduce 內核效率低下,為此我們開發了一款定制化的一次性 AllReduce 內核。該內核通過先模仿初始廣播,然后進行局部歸約的方式,利用 NVSwitch 的強大硬件能力在最小延遲場景中實現了更優的性能。
4、密集 GEMM 優化
我們重點優化兩種密集 GEMM:Fuse_A_GEMM 和 RouterGEMM。因為這兩種 GEMM 占據了大部分執行時間、顯存效率低下且難以分片(兩者均基于 DP)。
-
Fuse_A_GEMM
我們開發了一個定制的 Fuse_A_GEMM,通過將大部分權重預先載入到共享顯存(通過 PDL 實現并與 oneshot-AllReduce 重疊),大幅提升了性能。當 num_tokens < 16 時,該內核性能較默認的 GEMM 實現有明顯提升。
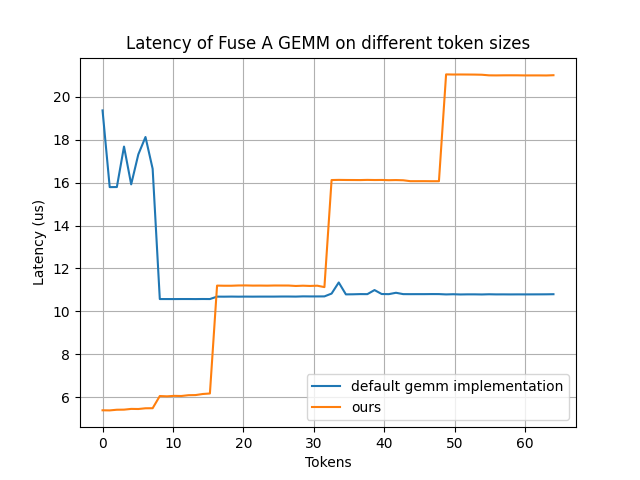
該圖片來源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
-
RouterGEMM
我們通過使用內部的 AI 代碼生成器,自動生成經過優化的 RouterGEMM 內核。在 num_tokens ≤ 30 時,該內核性能較默認的 GEMM 實現有顯著提升。
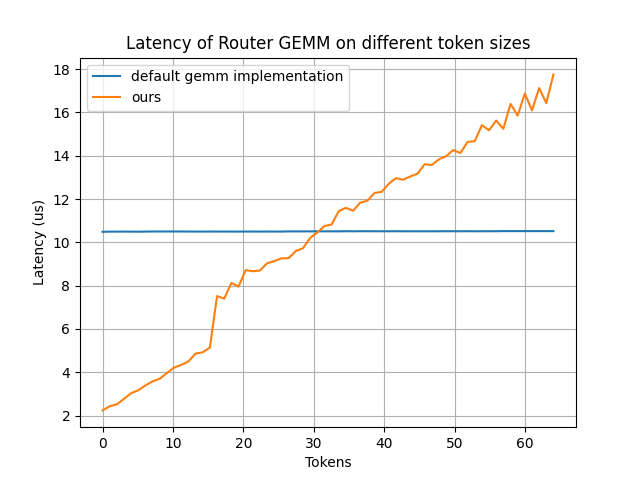
該圖片來源于 Github: Pushing Latency Boundaries: Optimizing DeepSeek-R1 Performance on NVIDIA Blackwell GPUs 一文,若您有任何疑問或需要使用該圖片,請聯系該文作者
5、內核融合
為了減少最小延遲場景中額外的全局顯存寫讀開銷,內核融合必不可少。我們目前支持以下融合模式:
-
將兩個重疊的 RMS_Norm 融合成一個 GroupedRMSNorm
-
將 (LocalReduction) + AR + RMS_Norm + (Dynamic_Quant_BF16toNVFP4) 融合成一個內核
-
將 Grouped GEMM_FC1 + 點激活 (當 moe_backend=TRTLLM 時) 融合成一個內核
如何復現
https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/Best_perf_practice_on_DeepSeek-R1_in_TensorRT-LLM.md#b200-min-latency
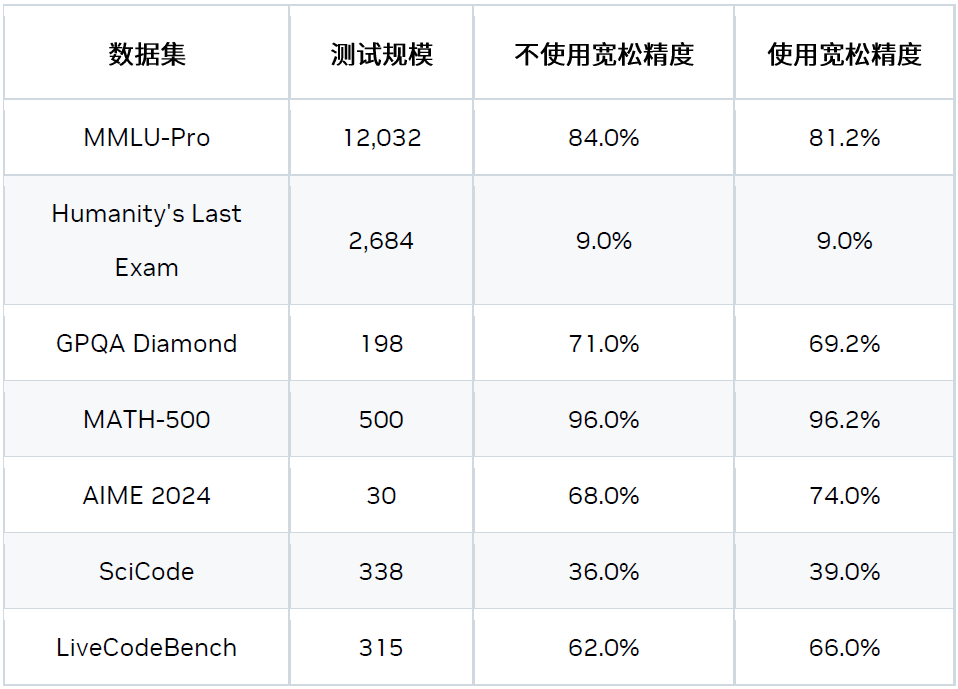
需要注意的是,寬松接受模式是 Deepseek-R1 模型的特有模式。若要啟用該模式,需在準備基準數據集時設置 add_generation_prompt = True,示例代碼如下:
input_ids= tokenizer.encode(tokenizer.apply_chat_template(msg, tokenize=False, add_generation_prompt=True), add_special_tokens=False)
還需在 speculative_config 中設置 use_relaxed_acceptance_for_thinking: true, relaxed_topk: 10 和 relaxed_delta: 0.6。
后續工作
-
增加融合
-
增加重疊
-
增加對注意力內核的優化
-
增加對 MTP 的研究
結語
在延遲敏感型應用中突破 DeepSeek R1 的性能極限是一項非凡的工程。本文詳細介紹的優化措施是整個 AI 技術棧各個領域的協作成果,涵蓋了內核級優化、運行時增強、模型量化技術、算法改進以及系統性能分析與調優。希望本文介紹的技術和最佳實踐,能夠幫助開發者社區在任務關鍵型 LLM 推理應用中更充分地發揮 NVIDIA GPU 的性能。
-
NVIDIA
+關注
關注
14文章
5284瀏覽量
106139 -
gpu
+關注
關注
28文章
4930瀏覽量
131014 -
大模型
+關注
關注
2文章
3105瀏覽量
4001 -
LLM
+關注
關注
1文章
324瀏覽量
796 -
DeepSeek
+關注
關注
1文章
793瀏覽量
1595
原文標題:突破延遲極限:在 NVIDIA Blackwell GPU 上優化 DeepSeek-R1 的性能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何使用OpenVINO運行DeepSeek-R1蒸餾模型

RK3588開發板上部署DeepSeek-R1大模型的完整指南
行芯完成DeepSeek-R1大模型本地化部署
Infinix AI接入DeepSeek-R1滿血版
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
超星未來驚蟄R1芯片適配DeepSeek-R1模型
OPPO Find N5將接入DeepSeek-R1,可直接語音使用
AIBOX 全系產品已適配 DeepSeek-R1

軟通動力天璇MaaS融合DeepSeek-R1,引領企業智能化轉型
deepin UOS AI接入DeepSeek-R1模型
芯動力神速適配DeepSeek-R1大模型,AI芯片設計邁入“快車道”!

網易有道全面接入DeepSeek-R1大模型
原生鴻蒙版小藝App上架DeepSeek-R1, AI智慧體驗更豐富
中軟國際JointPilot平臺上線DeepSeek-R1模型
對標OpenAI o1,DeepSeek-R1發布





 工商網監
工商網監
評論