 如何讓神經聲碼器高效地用于序列到序列聲學模型
如何讓神經聲碼器高效地用于序列到序列聲學模型
往往在放下手機之后你才會意識到,電話那頭的客服其實是個機器人;或者準確地說,是“一位”智能客服。
沒錯,今天越來越多的工作正在被交給人工智能技術去完成,文本轉語音(TTS,Text To Speech)就是其中非常成熟的一部分。它的發展,決定了今天我們聽到的許多“人聲”,是如此地逼真,以至于和真人發聲無異。
除了我們接觸最多的智能客服,智能家居中的語音助手、可以服務聽障人士的無障礙播報,甚至是新聞播報和有聲朗讀等服務,事實上都基于TTS這項技術。它是人機對話的一部分——簡單地說,就是讓機器說人話。
它被稱為同時運用語言學和心理學的杰出之作。不過在今天,當我們稱贊它的杰出時,更多的是因為它在在線語音生成中表現出的高效。
要提升語音合成效率當然不是一件容易的事。這里的關鍵是如何讓神經聲碼器高效地用于序列到序列聲學模型,來提高TTS質量。
科學家已經開發出了很多這樣的神經網絡聲碼器,例如WaveNet、Parallel WaveNet、WaveRNN、LPCNet 和 Multiband WaveRNN等,它們各有千秋。
WaveNet聲碼器可以生成高保真音頻,但在計算上它那巨大的復雜性,限制了它在實時服務中的部署;
LPCNet聲碼器利用WaveRNN架構中語音信號處理的線性預測特性,可在單個處理器內核上生成超實時的高質量語音;但可惜,這對在線語音生成任務而言仍不夠高效。
科學家們希望TTS能夠在和人的“交流”中,達到讓人無感的順暢——不僅是語調上的熱情、親切,或冷靜;更要“毫無”延遲。
新的突破出現在騰訊。騰訊 AI Lab(人工智能實驗室)和云小微目前已經率先開發出了一款基于WaveRNN多頻帶線性預測的全新神經聲碼器FeatherWave。經過測試,這款高效高保真神經聲碼器可以幫助用戶顯著提高語音合成效率。
英特爾的工程團隊也參與到了這項開發工作中。他們把面向第三代英特爾至強可擴展處理器所做的優化進行了全面整合,并采用了英特爾深度學習加速技術(英特爾 DL Boost)中全新集成的 16 位 Brain Floating Point (bfloat16) 功能。
bfloat16是一個精簡的數據格式,與如今的32位浮點數(FP32)相比,bfloat16只通過一半的比特數且僅需對軟件做出很小程度的修改,就可達到與FP32同等水平的模型精度;與半浮點精度 (FP16) 相比,它可為深度學習工作負載提供更大的動態范圍;與此同時,它無需使用校準數據進行量化/去量化操作,因此比 INT8 更方便。這些優勢不僅讓它進一步提升了模型推理能力,還讓它能為模型訓練提供支持。
事實上,英特爾至強可擴展處理器本就是專為運行復雜的人工智能工作負載而設計的。借助英特爾深度學習加速技術,英特爾志強可擴展處理器將嵌入式 AI 性能提升至新的高度。目前,此種處理器現已支持英特爾高級矢量擴展 512 技術(英特爾AVX-512 技術)和矢量神經網絡指令 (VNNI)。
在騰訊推出的全新神經聲碼器FeatherWave 聲碼器中,就應用了這些優化技術。
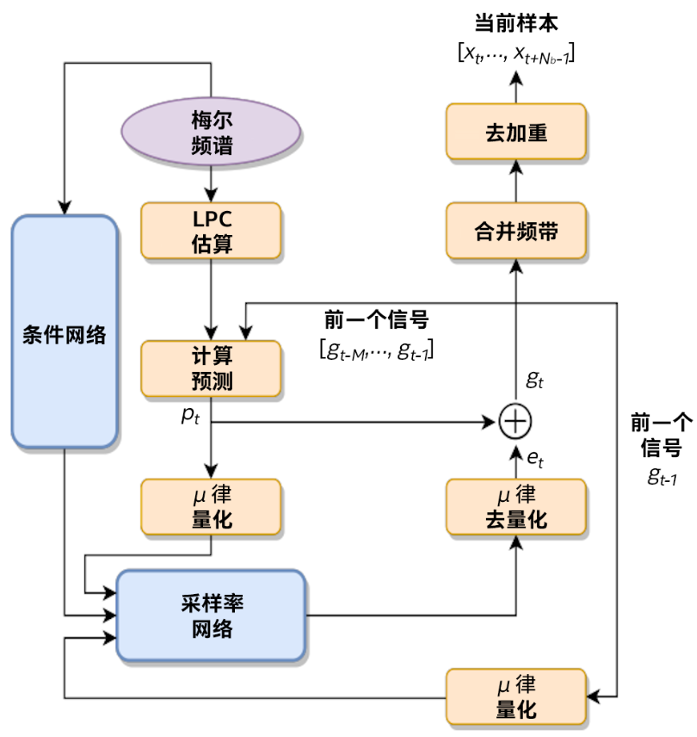
FeatherWave 聲碼器框圖
利用英特爾AVX-512技術和bfloat16指令,騰訊的科學家們確保了GRU模塊和Dense運算符中粗略部分/精細部分的所有SGEMV計算都使用512位矢量進行矢量化,并采用bfloat16點積指令;對于按元素逐個加/乘等運算以及其他非線性激活,都使用最新的英特爾AVX-512 指令運行。
在最終都性能測試中,通過優化,相同質量水平(MOS4.5)的文本轉語音速度比FP32提升了高達1.54倍。
此外,騰訊還以 GAN 和 Parallel WaveNet (PWaveNet)為基礎,推出了一種改進后的模型,并基于第三代英特爾至強可擴展處理器對模型性能進行了優化,最終使性能與采用FP32相比提升了高達1.89倍,同時質量水平仍保持不變 (MOS4.4)。
騰訊在TTS領域的進展顯示出了人工智能領域的一個趨勢,那就是科學家們越來越多開始利用英特爾深度學習加速技術在CPU平臺上開展工作。
就像騰訊在針對TTS的探索中獲得了性能提升那樣,第二代和第三代英特爾至強可擴展處理器在集成了加速技術后,已經顯著提升了人工智能工作負載的性能。
在更廣泛的領域內,我們已經能夠清楚地看到這種變化——在效率表現上,由于針對常見人工智能軟件框架,如TensorFlow和PyTorch、庫和工具所做的優化,CPU平臺可以幫助保持較高的性能功耗比和性價比。
尤其是擴展性上,用戶在設計系統時可以利用如英特爾以太網700系列,和英特爾傲騰內存存儲技術,來優化網絡和內存配置。這樣一來,他們就可以在充分利用現有硬件投資的情況下,輕松擴展人工智能訓練的工作負載,獲得更高的吞吐量,甚至處理巨大的數據集。
不止于處理器平臺本身,英特爾目前在面向人工智能優化的軟件,以及市場就緒型人工智能解決方案兩個維度,都建立起了差異化的市場優勢。
例如在軟件方面,英特爾2019年2月進行的 OpenVINO/ResNet50 INT8 性能測試顯示,使用 OpenVINO或TensorFlow和英特爾深度學習加速技術時,人工智能推理性能可提高多達 3.75 倍。
今天,英特爾已經攜手解決方案提供商,構建了一系列的精選解決方案。這些方案預先進行了配置,并對工作負載進行了優化。這就包括了如基于人工智能推理的英特爾精選解決方案,以及面向在面向在Apache Spark上運行的BigDL的英特爾精選解決方案等。
這些變化和方案的出現對于那些希望能從整體業務視角,去觀察人工智能進展的機構或企業的管理層顯然也很有意義——如果只通過優化,就能在一個通用平臺上完成所有人工智能的探索和落地,那么投資的價值就能夠實現最大化。
許多企業做出了這樣的選擇,GE醫療就是其中一家。作為GE集團旗下的醫療健康業務部門,它構建了一個人工智能醫學影像部署架構。
通過采用英特爾至強可擴展處理器,和英特爾固態盤,以及多項英特爾關鍵技術——例如英特爾深度學習開發工具包,和面向深度神經網絡的英特爾數學核心函數庫等;GE醫療收獲了未曾預料到的成果:
這一解決方案最終比基礎解決方案的推理速度提升了多達14倍,且超過了GE原定推理目標5.9倍。
責任編輯:xj
-
機器人
+關注
關注
213文章
29568瀏覽量
211982 -
神經網絡
+關注
關注
42文章
4811瀏覽量
103066 -
智能化
+關注
關注
15文章
5109瀏覽量
57038
發布評論請先 登錄





 工商網監
工商網監
評論