") 關于Dropout、BN及數(shù)據(jù)預處理方案
關于Dropout、BN及數(shù)據(jù)預處理方案

一、隨機失活(Dropout)
具體做法:在訓練的時候,隨機失活的實現(xiàn)方法是讓神經(jīng)元以超參數(shù)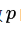 的概率被激活或者被設置為 0。如下圖所示:
的概率被激活或者被設置為 0。如下圖所示:
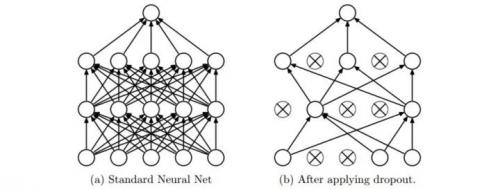
Dropout 可以看作是 Bagging 的極限形式,每個模型都在當一種情況中訓練,同時模型的每個參數(shù)都經(jīng)過與其他模型共享參數(shù),從而高度正則化。在訓練過程中,隨機失活也可以被認為是對完整的神經(jīng)網(wǎng)絡抽樣出一些子集,每次基于輸入數(shù)據(jù)只更新子網(wǎng)絡的參數(shù)(然而,數(shù)量巨大的子網(wǎng)絡們并不是相互獨立的,因為它們都共享參數(shù))。在測試過程中不使用隨機失活,可以理解為是對數(shù)量巨大的子網(wǎng)絡們做了模型集成(model ensemble),以此來計算出一個平均的預測。
關于 Dropout 的 Motivation:一個是類似于性別在生物進化中的角色:物種為了生存往往會傾向于適應這種環(huán)境,環(huán)境突變則會導致物種難以做出及時反應,性別的出現(xiàn)可以繁衍出適應新環(huán)境的變種,有效的阻止過擬合,即避免環(huán)境改變時物種可能面臨的滅絕。還有一個就是正則化的思想,減少神經(jīng)元之間復雜的共適應關系,減少權重使得網(wǎng)絡對丟失特定神經(jīng)元連接的魯棒性提高。
這里強烈推薦看下論文原文。雖然是英文的,但是對于更深刻的理解還是有很大幫助的!
二、圖像數(shù)據(jù)的預處理
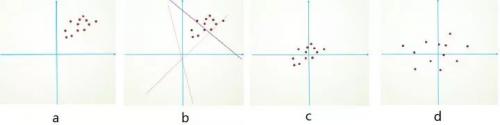
為什么要預處理:簡單的從二維來理解,首先,圖像數(shù)據(jù)是高度相關的,假設其分布如下圖 a 所示(簡化為 2 維)。由于初始化的時候,我們的參數(shù)一般都是 0 均值的,因此開始的擬合 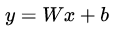 ,基本過原點附近(因為 b 接近于零),如圖 b 紅色虛線。因此,網(wǎng)絡需要經(jīng)過多次學習才能逐步達到如紫色實線的擬合,即收斂的比較慢。如果我們對輸入數(shù)據(jù)先作減均值操作,如圖 c,顯然可以加快學習。更進一步的,我們對數(shù)據(jù)再進行去相關操作,使得數(shù)據(jù)更加容易區(qū)分,這樣又會加快訓練,如圖 d。
,基本過原點附近(因為 b 接近于零),如圖 b 紅色虛線。因此,網(wǎng)絡需要經(jīng)過多次學習才能逐步達到如紫色實線的擬合,即收斂的比較慢。如果我們對輸入數(shù)據(jù)先作減均值操作,如圖 c,顯然可以加快學習。更進一步的,我們對數(shù)據(jù)再進行去相關操作,使得數(shù)據(jù)更加容易區(qū)分,這樣又會加快訓練,如圖 d。
下面介紹下一些基礎預處理方法:
歸一化處理
均值減法(Mean subtraction):它對數(shù)據(jù)中每個獨立特征減去平均值,從幾何上可以理解為在每個維度上都將數(shù)據(jù)云的中心都遷移到原點。(就是每個特征數(shù)據(jù)減去其相應特征的平均值)
歸一化(Normalization);先對數(shù)據(jù)做零中心化(zero-centered)處理,然后每個維度都除以其標準差。
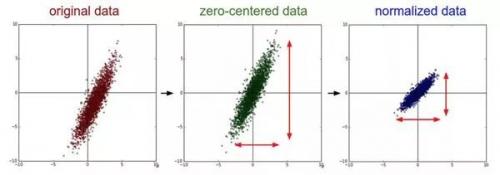
(中間零中心化,右邊歸一化)
PCA 和白化(Whitening)
白化(Whitening):白化操作的輸入是特征基準上的數(shù)據(jù),然后對每個維度除以其特征值來對數(shù)值范圍進行歸一化。該變換的幾何解釋是:如果數(shù)據(jù)服從多變量的高斯分布,那么經(jīng)過白化后,數(shù)據(jù)的分布將會是一個均值為零,且協(xié)方差相等的矩陣
特征向量是按照特征值的大小排列的。我們可以利用這個性質(zhì)來對數(shù)據(jù)降維,只要使用前面的小部分特征向量,丟棄掉那些包含的數(shù)據(jù)沒有方差的維度。這個操作也被稱為主成分分析( Principal Component Analysis)簡稱 PCA)降維
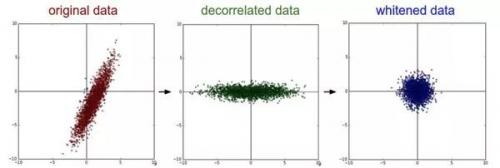
(中間是經(jīng)過 PCA 操作的數(shù)據(jù),右邊是白化)
需要注意的是:
對比與上面的中心化,與 pca 有點類似,但是不同的是,pca 把數(shù)據(jù)變換到了數(shù)據(jù)協(xié)方差矩陣的基準軸上(協(xié)方差矩陣變成對角陣),也就是說他是軸對稱的,但簡單的零中心化,它不是軸對稱的;還有 PCA 是一種降維的預處理,而零中心化并不是。
常見錯誤:任何預處理策略(比如數(shù)據(jù)均值)都只能在訓練集數(shù)據(jù)上進行計算,算法訓練完畢后再應用到驗證集或者測試集上。例如,如果先計算整個數(shù)據(jù)集圖像的平均值然后每張圖片都減去平均值,最后將整個數(shù)據(jù)集分成訓練 / 驗證 / 測試集,那么這個做法是錯誤的。應該怎么做呢?應該先分成訓練 / 驗證 / 測試集,只是從訓練集中求圖片平均值,然后各個集(訓練 / 驗證 / 測試集)中的圖像再減去這個平均值。
三、Batch Normalization

原論文中,作者為了計算的穩(wěn)定性,加了兩個參數(shù)將數(shù)據(jù)又還原回去了,這兩個參數(shù)也是需要訓練的。說白了,就是對每一層的數(shù)據(jù)都預處理一次。方便直觀感受,上張圖:
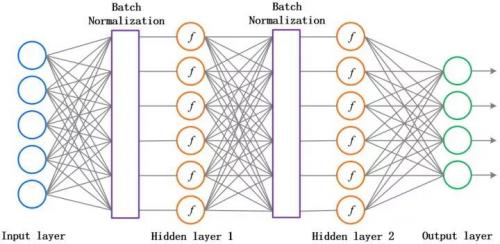
這個方法可以進一步加速收斂,因此學習率可以適當增大,加快訓練速度;過擬合現(xiàn)象可以得倒一定程度的緩解,所以可以不用 Dropout 或用較低的 Dropout,而且可以減小 L2 正則化系數(shù),訓練速度又再一次得到了提升。即 Batch Normalization 可以降低我們對正則化的依賴程度。
還有要注意的是,Batch Normalization 和 pca 加白化有點類似,結果都是可以零均值加上單位方差,可以使得數(shù)據(jù)弱相關,但是在深度神經(jīng)網(wǎng)絡中,我們一般不要 pca 加白化,原因就是白化需要計算整個訓練集的協(xié)方差矩陣、求逆等操作,計算量很大,此外,反向傳播時,白化操作不一定可導。最后,再次強烈直接看 BN 的相關論文,有很多細節(jié)值得一看!
編輯:hfy
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4814瀏覽量
103550
發(fā)布評論請先 登錄
機器學習為什么需要數(shù)據(jù)預處理

請教大家一下關于數(shù)據(jù)預處理
數(shù)據(jù)探索與數(shù)據(jù)預處理
工業(yè)蒸汽量預測的數(shù)據(jù)預處理知識有哪些
C預處理與C語言基本數(shù)據(jù)類型
C語言的編譯預處理
Python數(shù)據(jù)清洗和預處理入門完整指南
什么是大數(shù)據(jù)采集和預處理
PyTorch教程之數(shù)據(jù)預處理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論