") 微軟在EMNLP2020上發(fā)表最新工作
微軟在EMNLP2020上發(fā)表最新工作
來自:NLPCAB
句子表示在很多任務中都是重要的一環(huán)。尤其是在大數據量的場景下,很多場景都需要召回+排序兩個步驟,如果第一個環(huán)節(jié)沒有召回候選結果,那最后的排序模型再怎么優(yōu)秀也沒法給出正確答案。
今天就給大家介紹一個微軟在EMNLP2020上發(fā)表的最新工作,利用transformer生成更高質量的句子編碼。
雖然BERT式模型的出現解決了很多判別問題,但直接用無監(jiān)督語料訓練出的BERT做句子表示并不理想:
如果只取CLS,這個表示是針對NSP進行優(yōu)化的,表示的信息有限
如果取平均或最大池化,可能會把無用信息計算進來,增加噪聲
所以作者的改進目的是設計一個下游任務,直接優(yōu)化得到的句子embedding。
那怎么設計目標才能充分利用無監(jiān)督數據呢?
作者給出了一個巧妙的方法,就是用周邊其他句子的表示預測當前句子的token。
具體的做法是:先利用Transformer抽取句子表示,再對句子表示進行attention,選取相關的句子預測當前token。有點Hierarchical Attention的意思。

比如在預測上圖中最后一句的黃藍兩個token時,明顯第一句的信息就夠用了,那目標函數的設置會讓第一句的權重變大,也會讓抽取出的句子表示去包含這些信息。
接下來詳細介紹一下預訓練和精調的步驟,以及作者加入的其他tricks。
Cross-Thought模型
預訓練
下圖是預訓練的模型結構,計算的步驟是:
將段落按順序拆成獨立短句,通過12層Transformer(藍色半透明的矩形)分別進行編碼。在實際的預訓練中,每個sample包含500個長度為64的短句,batch size是128(16張V100)
取出
把每列句子表示作為一個序列輸入到cross-sequence transformer(藍色弧線,每一列的cross-sequence transformer參數都不同),輸出attention分數加權后的新表示
將新的句子表示與第一步的token表示進行拼接,經過一層transformer,預測被mask的15%個token(每個句子都這么處理,圖中只畫了第一個句子的)
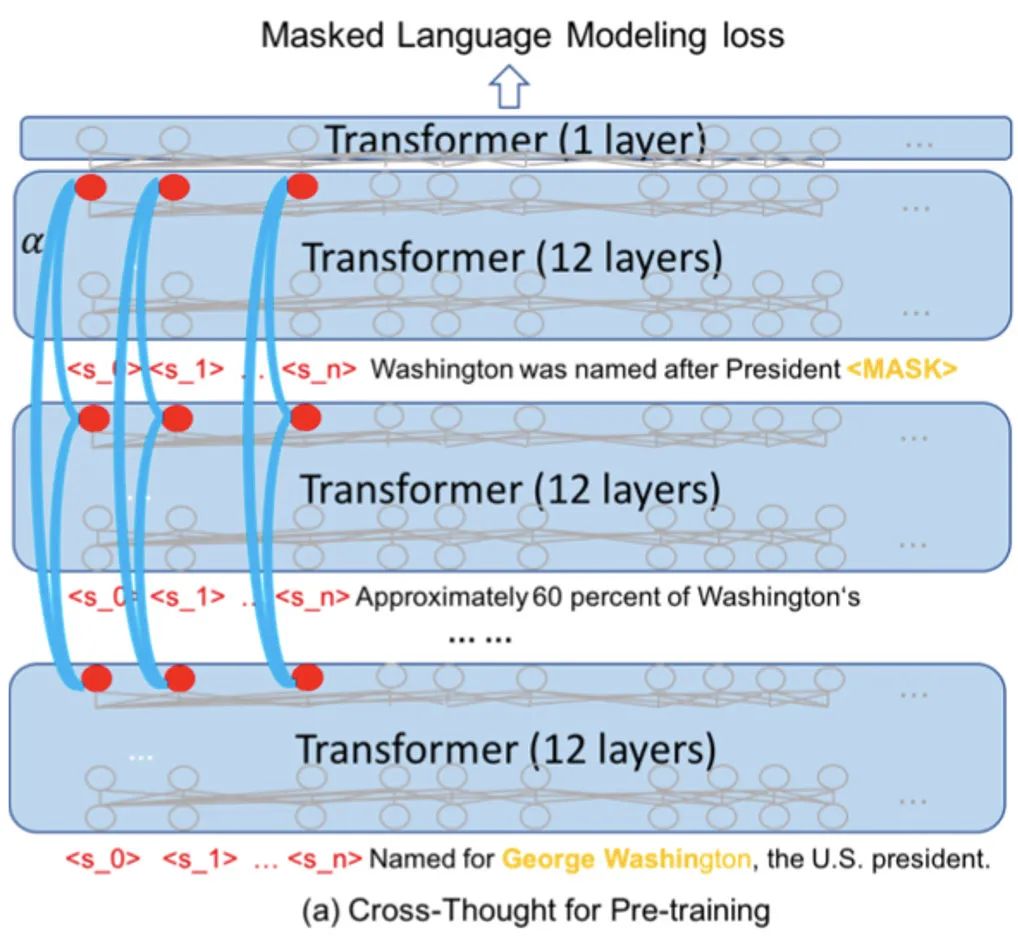
整體流程理解起來比較簡單,作者還用了一些額外的tricks提升效果:
為了抽取更多的信息,在句子開頭加入了多個占位token(之前BERT只有一個[CLS]),在實驗結論中發(fā)現5個占位的表現較好(但占位token的增加會加大計算量)
占位token的位置表示是固定的,而真實token是隨機從0-564中抽取連續(xù)的64個,這樣可以訓練更多的位置表示,方便之后對更長的序列進行編碼
精調
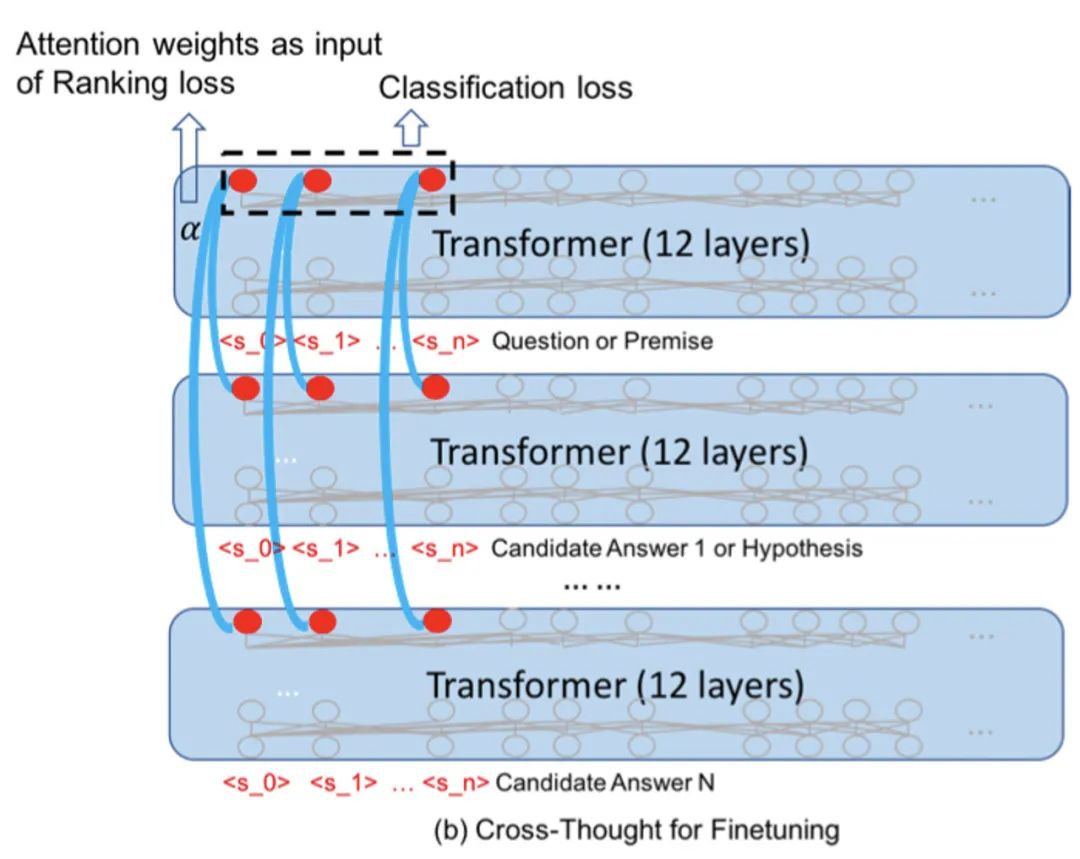
精調主要是考慮和下游任務的銜接。作者選擇了問答和句子對分類來驗證模型的表現。
對于問答任務,假設答案句子的表示都已經編碼好了:
輸入問題,經過12層Transformer得到問題表示
利用cross-sequence transformers,對問題表示與答案表示進行計算,得到各個答案的權重 (每列都會得到一個,作者對所有列取了平均)
根據gold answer的index m,計算Ranking loss(代表第0個答案的權重)
對于句子對分類任務比較簡潔,輸入兩個句子A和B:
分別對A和B進行編碼,取出句子表示,輸入cross-sequence transformers得到融合后的句子表示
將兩個句子的所有表示拼接起來,得到2Nxd的矩陣(N是占位token的個數,d是表示的維度)
把第二步得到的表示flatten,得到一個長度 2Nd 的一維向量,輸入到分類層
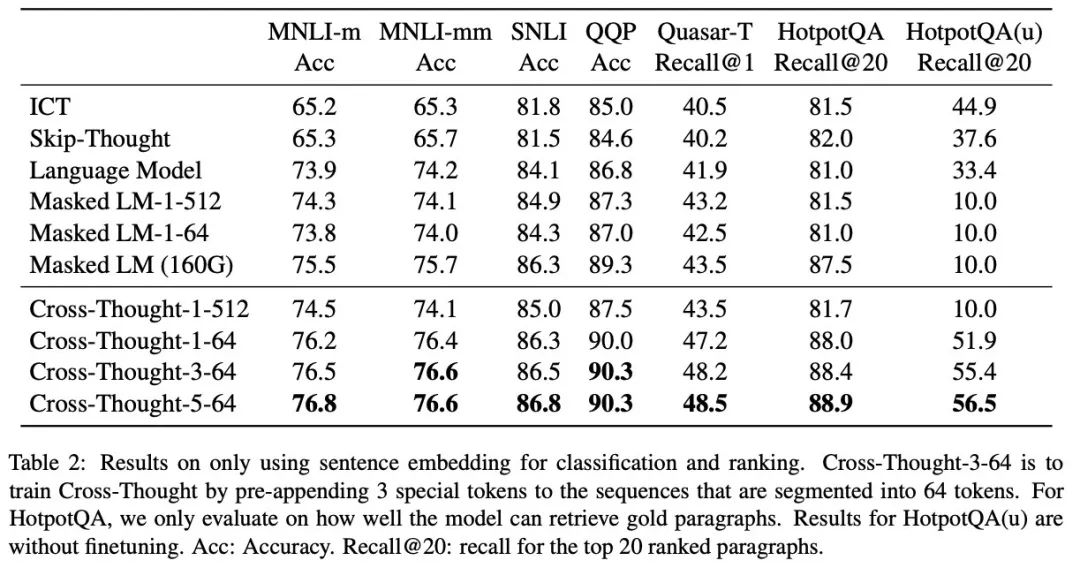
實驗效果
作者在不少數據集上都驗證了效果,單純從輸出句子表示的效果來看,不僅是句間關系還是問答的候選召回上都有不小的提升,尤其是召回:
除了指標對比外,作者還展示了兩個無監(jiān)督預訓練模型的打分結果:

總結
近兩年句子表示的研究越來越少了,因為句子表示經常用于句間關系判斷的任務,而交互式的判別顯然比雙塔效果要好。所以研究者們要不在研究更輕量的句間匹配模型(比如RE2、Deformer),要不就是繼續(xù)用BERT類模型做出更好的效果。但對于業(yè)界來說,句子表示在召回上的速度還是最快的,效果也比單純的字面匹配要好。
為了充分利用無監(jiān)督數據、得到更高質量的句子表示,Cross-Thought提供了一個新的預訓練思路:用句子表示預測token。同時也給我們展現出了它在候選召回上的巨大潛力,添加的額外cross-sequence transformer對速度的影響也不會太大。另外,作者只使用了wiki語料進行預訓練,如果有更多語料相信效果會更好。
目前源碼還未放出,希望開源社區(qū)的富有大佬們早日訓一個中文的Cross-Thought~
原文標題:【EMNLP2020】超越MLM,微軟打造全新預訓練任務
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
微軟
+關注
關注
4文章
6673瀏覽量
105389 -
函數
+關注
關注
3文章
4371瀏覽量
64238
原文標題:【EMNLP2020】超越MLM,微軟打造全新預訓練任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
微軟科技重磅發(fā)布兩款企業(yè)級AI應用
晶科能源受邀擔任B20南非工業(yè)轉型與創(chuàng)新工作組聯席主席
無人機消防巡檢的新工作日志
RT-Thread睿賽德出席中國工博會科技論壇,共話開源硬件與新工業(yè)革命







 工商網監(jiān)
工商網監(jiān)
評論