 讀懂NeurIPS2019最佳機器學習論文
讀懂NeurIPS2019最佳機器學習論文

引言
NeurIPS是全球頂級的機器學習會議。沒有其他研究會議可以吸引6000多位該領域內真正的精英同時參加。如果你非常想了解機器學習最新的研究進展,就需要關注NeurIPS。
每年,NeurIPS都會為機器學習領域的頂級研究論文頒發各類獎項。考慮到這些論文的前沿水平,它們對于大多數人來說通常晦澀難懂。
但是不用擔心!我瀏覽了這些優秀論文,并在本文總結了要點!我的目的是通過將關鍵的機器學習概念分解為大眾易于理解的小點來幫助你了解每篇論文的本質。
以下是我將介紹的三個NeurIPS2019最佳論文的獎項:
最佳論文獎
杰出新方向論文獎
經典論文獎
讓我們深入了解吧!
NeurIPS 2019最佳論文獎
在NeurIPS 2019上獲得的最佳論文獎是:
具有Massart噪聲的半空間的獨立分布的PAC學習(Distribution-Independent PAC Learning of Halfspaces with MassartNoise)
這是一篇非常好的論文!這讓我開始思考機器學習中的一個基本概念:噪聲和分布。這需要對論文本身進行大量研究,我將盡力解釋論文的要點而不使其變得復雜。
我們先重述標題。本文的研究討論了一種用于學習半空間的算法,該算法在與分布無關的PAC模型中使用,且研究的半空間具有Massart噪聲。該算法是該領域中最有效的算法。
本文的關鍵術語如下。
回顧布爾函數和二進制分類的概念。本質上,
一個半空間是一個布爾函數,其中兩個類(正樣本和負樣本)由一個超平面分開。由于超平面是線性的,因此它也被稱為線性閾值函數(LTF)。
在數學上,線性閾值函數或半空間是一個閾值函數,可以由以某個閾值T為邊界的輸入參數的線性方程表示。布爾函數如果具有以下形式,則為線性閾值函數:
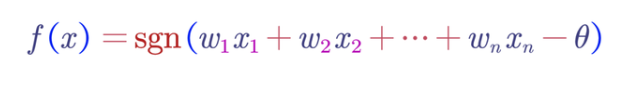
其中:
是權重
是特征
表示給出實數符號的符號函數
是閾值
我們也可以將LTF稱為感知器(此處需要使用神經網絡知識!)。
PAC(Probably Approximately Correct)模型是二分類的標準模型之一。
“Massart噪聲條件,或僅僅是Massart噪聲,是每個樣本/記錄的標簽以學習算法未知的很小概率進行的翻轉。”
翻轉的可能性受某個始終小于1/2的因子n的限制。為了找到使得誤分類錯誤較小的假設,我們在先前的論文中進行了各種嘗試來限制錯誤以及與數據噪聲相關的風險。
這項研究在確定樣本復雜性的同時,證明了多項式時間(1/epsilon)的額外風險等于Massart噪聲水平加上epsilon。
本文是邁向僅實現ε過量風險這一目標的巨大飛躍。
獲得NeurIPS杰出論文獎提名的其他論文:
1. Besov IPM損耗下GAN的非參數密度估計和收斂速度(Nonparametric Density Estimation & Convergence Rates for GANs under Besov IPM Losses)
2. 快速準確的最小均方求解(Fast andAccurate Least-Mean-Squares Solvers)
NeurIPS 2019杰出新方向論文
今年的NeurIPS2019為獲獎論文設置了一個新獎項杰出新方向論文獎。用主辦方的話來說: “該獎項旨在表彰為未來研究建立新途徑的杰出工作。”
該獎項的獲獎文章是 ——《一致收斂性可能無法解釋深度學習中的泛化性》(Uniform convergence may be unable to explain generalization in deeplearning)
今年我最喜歡的論文之一!本文從理論和實踐兩個方面闡述了當前的深度學習算法無法解釋深度神經網絡中的泛化。讓我們來更詳細地了解這一點。
一致收斂性可能無法解釋深度學習中的泛化性(Uniform convergence may be unable to explain generalization in deeplearning)
大型網絡很好地概括了看不見的訓練數據,盡管這些數據已被訓練為完全適合隨機標記。但是,當特征數量大于訓練樣本的數量時,這些網絡的表現就沒那么好了。
盡管如此,它們仍然為我們提供了最新的性能指標。這也表明這些超參數化模型過度地依賴參數計數而沒有考慮批量大小的變化。如果我們遵循泛化的基本方程:
測試誤差 – 訓練誤差 《= 泛化界限
對于上面的方程式,我們采用所有假設的集合,并嘗試最小化復雜度并使這些界限盡可能地窄。
迄今為止的研究都集中于通過獲取假設類別的相關子集來收緊界限。在完善這些約束方面也有很多開創性的研究,所有這些都基于統一收斂的概念。
但是,本文解釋這些算法可能出現的兩種情況:
太大,并且其復雜度隨參數數量而增加;
很小,但是在修改后的網絡上設計而來
“該論文定義了一組用于泛化界限的標準,并通過一組演示實驗證明統一收斂為何無法完全解釋深度學習中的泛化。”
泛化界限如下:
1. 理想情況下必須 《1(空)
2. 隨著寬度的增加變小
3. 適用于由SGD(隨機梯度下降)學習的網絡
4. 隨著隨機翻轉的訓練標簽的比例而增加
5. 應該與數據集大小成反比
之前提到的實驗是在MNIST數據集上使用三種類型的過度參數化模型(均在SGD算法上進行訓練)完成的:
1. 線性分類器
2. 具有ReLU的寬神經網絡
3. 具有固定隱藏權重的無限寬度神經網絡
本文繼而演示了針對不同訓練集大小的不同超參數設置。
“一個非常有趣的發現是,盡管測試集誤差隨訓練集大小的增加而減小,但泛化界限實際上卻有所增加。 ”
如果網絡只是記住了我們不斷添加到訓練集中的數據點,該怎么辦?
以研究人員給出的例子為例。對于一個擁有1000個維度的數據集的分類任務,使用SGD訓練具有1個隱藏層ReLU和10萬個單位的超參數化模型。訓練集大小的增加可提高泛化性并減少測試集錯誤。
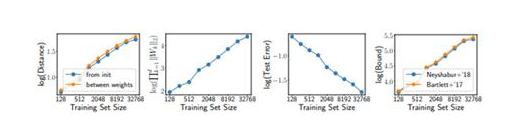
盡管進行了泛化,它們仍然證明了決策邊界非常復雜。這是它們違背統一收斂思想的地方。
因此,即使對于線性分類器,統一收斂也不能完全解釋泛化。實際上,當增加樣本數量時,這可以認為是導致界限增加的一個因素!
盡管先前的研究已將發展深度網絡的方向朝著依賴于算法的方向發展(以便堅持一致收斂),但本文提出了開發不依賴于算法的技術的需求,這些技術不會局限于一致收斂來解釋泛化。
我們可以清楚地知道,為什么該機器學習研究論文在NeurIPS 2019上獲得了杰出新方向論文獎。
研究人員已經表明,僅僅用一致收斂不足以解釋深度學習中的泛化。同樣,不可能達到滿足所有5個標準的小界限。這開辟了一個全新的研究領域來探索可能解釋泛化的其他工具。
NeurIPS在杰出新方向論文獎上的其他提名包括:
1. 端到端:表征的梯度隔離學習(Putting AnEnd to End-to-End: Gradient-Isolated Learning of Representations)
2. 場景表示網絡:連續的3D-結構感知神經場景表示(SceneRepresentation Networks: Continuous 3D-Structure-Aware Neural SceneRepresentations)
NeurIPS 2019的經典論文獎
每年,NeurIPS還會獎勵10年前在大會上發表的一篇論文,該論文對該領域的貢獻產生了深遠的影響(也是廣受歡迎的論文)。
今年,“經典論文獎”授予了LinXiao寫作的“正則隨機學習和在線優化的雙重平均法”。這項研究基于基本概念,這些基本概念為眾所周知的現代機器學習奠定了基礎。
正則隨機學習和在線優化的雙重平均法(Dual Averaging Method for Regularized Stochastic Learning and OnlineOptimization)
讓我們分解一下這篇極佳的論文中涵蓋的四個關鍵概念:
隨機梯度下降:隨機梯度下降已經正式成為機器學習中的最優化方法。它可以通過以下隨機優化來實現。回顧SGD和大樣本隨機優化方程——這里,w是權重向量,z是輸入特征向量。對于t = 0,1,2…
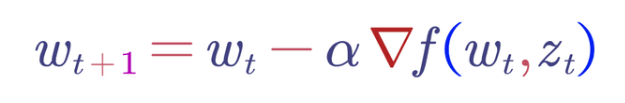
在線凸優化:另一項開創性的研究。它被模擬為游戲,玩家將嘗試預測權重向量,并在每個t處計算出最終的損失。主要目的是最大程度地減少這種損失——結果與我們使用隨機梯度下降進行優化的方式非常相似
壓縮學習:這包括套索回歸,L1正則化最小二乘和其他混合正則化方案
近端梯度法:與早期的技術相比,這是一種減少損耗且仍保留凸度的更快的方法
盡管先前的研究開發了一種收斂到O(1/t)的有效算法,但數據稀疏性是在那之前一直被忽略的一個因素。本文提出了一種新的正則化技術,稱為正則化雙重平均法(RDA),用于解決在線凸優化問題。
當時,這些凸優化問題效率不高,特別是在可伸縮性方面。
這項研究提出了一種批處理優化的新方法。這意味著最初僅提供一些獨立樣本,并且基于這些樣本(在當前時間t)計算權重向量。相對于當前權重向量的損失與次梯度一起計算。并在迭代中(在時間t + 1)再次使用它。
具體而言,在RDA中,考慮了平均次梯度,而不是當前的次梯度。
“當時,對于稀疏的MNIST數據集,此方法比SGD和其他流行技術獲得了更好的結果。實際上,隨著稀疏度的增加,RDA方法也具有明顯更好的結果。”
在進一步研究上述方法的多篇論文中,如流形識別、加速RDA等,都證明了這篇論文被授予經典論文獎是當之無愧。
結語
NeurIPS 2019再次成為了一次極富教育意義和啟發性的會議。我對杰出新方向論文獎以及它如何解決深度學習中的泛化問題特別感興趣。
哪一篇機器學習研究論文引起了你的注意?或者是否有其他的論文,讓你想要去嘗試或者啟發了你?請在下面的評論區中告訴我們吧。
-
二進制
+關注
關注
2文章
807瀏覽量
42323 -
函數
+關注
關注
3文章
4381瀏覽量
64857 -
機器學習
+關注
關注
66文章
8503瀏覽量
134598
發布評論請先 登錄
機器學習賦能的智能光子學器件系統研究與應用

機器學習模型市場前景如何
嵌入式機器學習的應用特性與軟件開發環境
傳統機器學習方法和應用指導

如何選擇云原生機器學習平臺
學習硬件的第一節課:學習讀懂原理圖
螞蟻數科與浙大團隊榮獲NeurIPS競賽冠軍
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別

2024 年 19 種最佳大型語言模型





 工商網監
工商網監
評論