 除了史上最大芯片之外,Hot Chips還有哪些值得關注的內容?
除了史上最大芯片之外,Hot Chips還有哪些值得關注的內容?

今年的Hot Chips,Cerebras搞了個大新聞,各種媒體刷屏。那么,除了史上最大芯片之外,Hot Chips還有哪些值得關注的內容?一起來看芯片專家唐杉的解讀。
首先,Cerebras這次確實做了非常好的宣傳,各種介紹和分析也很多,我就不多說了。不管大家怎么評價,我個人還是很欽佩他們的工作的,所以拼了一張AI芯片的圖,算是致敬一下給我們帶來“美感”的工程師們。
這幾天介紹Hot Chips的文章也很多,我就全憑個人興趣挑幾個點和大家一起看一下。今年我自己沒有參會,所以主要是根據演講的材料以及Anandtech上的Live Blog做一些分析。如果大家感興趣,也可以看看我去年寫的文章(Hot Chips 30,黃金時代的縮影,Hot Chips 30 - 機器學習,Hot Chips 30 - 巨頭們亮“肌肉”),有些內容可以作為參考。
摩爾定律怎么“續命”
從某種意義上說,我們整個半導體產業都是在為摩爾定律的延續而努力,即我們希望能給18個月之后的應用需求提供成倍增長的“性能”支撐,只不過現在這個承諾不再是單單靠工藝節點的演進和晶體管數目來支撐了。
這次Hop Chips上的兩個主旨演講,可以說就是從不同角度討論了這個問題。一個是處理器巨頭AMD的Dr. Lisa Su分享的“Delivering the Future of High-Performance Computing”;另一個是TSMC的Dr. Philip Wong分享的“What Will the Next Node Offer Us?”。先看看Lisa Su的總結,為了給未來十年提供高性能計算能力,我們可做和要做的事情還是很多的。
source:Hot Chips 2019[1]
從Foundry的角度,Dr. Philip Wong講的就更直接,“MOORE’S LAW IS WELL AND ALIVE”,不過他的說法也不是單獨針對晶體管的性能,而是各種技術綜合發展的結果。
source:Hot Chips 2019[2]
從架構“黃金時代”(黃金時代)的說法來看,工藝演進速度放緩并不一定是壞事情,大家為了延續摩爾定律會在更多的方向上努力。比如,在這次會議上,Nvidia展示的工作[3]就是一個覆蓋了很多領域和設計環節的實驗。它包括Multi-chip架構,NoC(Network-on-Chip)和NoP(Network-on-Package)構成的層次化通信,高帶寬的inter-chip互聯,甚至是敏捷開發方法,挺有意思。而Facebook的講演[4]也介紹了大型系統協同設計的非常好的實踐。而在其它很多講演中,比如Intel,Nvidia,AMD,華為等等,我們也可以大量看到新型封裝和集成技術的應用和快速進展。
NN加速器架構的下一步
這次也有幾家展示了NN加速器的架構,比較詳細的包括華為和Tesla。我們先看看Tesla。
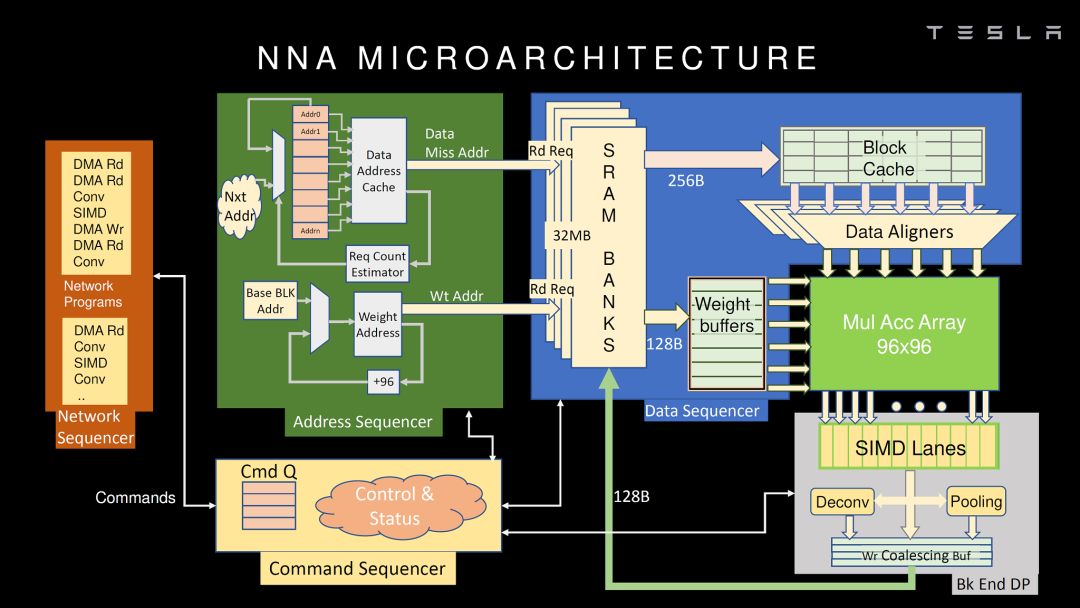
source:Hot Chips 2019 [3]
應該說,Tesla的NNA不管從指令集還是微架構都和Google TPU(公開的第一代)非常類似,MAC矩陣實現卷積和矩陣乘,SIMD實現其它運算,再加一些特殊運算的硬件加速。這種架構應該是目前看到最多的設計,簡單直接,硬件實現比較容易,挑戰是MAC矩陣的使用效率。當然,在很多細節上,Tesla的NNA還是做了不少優化。如我之前的文章的分析,Tesla的芯片完全是自用的,合適就好,沒有太多可比性(多角度解析Tesla FSD自動駕駛芯片)。
相比之下,華為的DaVinci Core應該是結合了這幾年的AI芯片經驗和深入的思考。其特點是在一個Core里面同時支持3D(Cube),2D(Vector)和1D(Scalar)的運算,以適應不同網絡和不同層的運算分布的變化。當然,把各種運算架構放在一個Core里面并不是特別困難的事情,更難的是設計參數的選擇,運算和存儲的比例,軟件mapping工具等等。這些問題在華為的talk里也給出了一些分析。
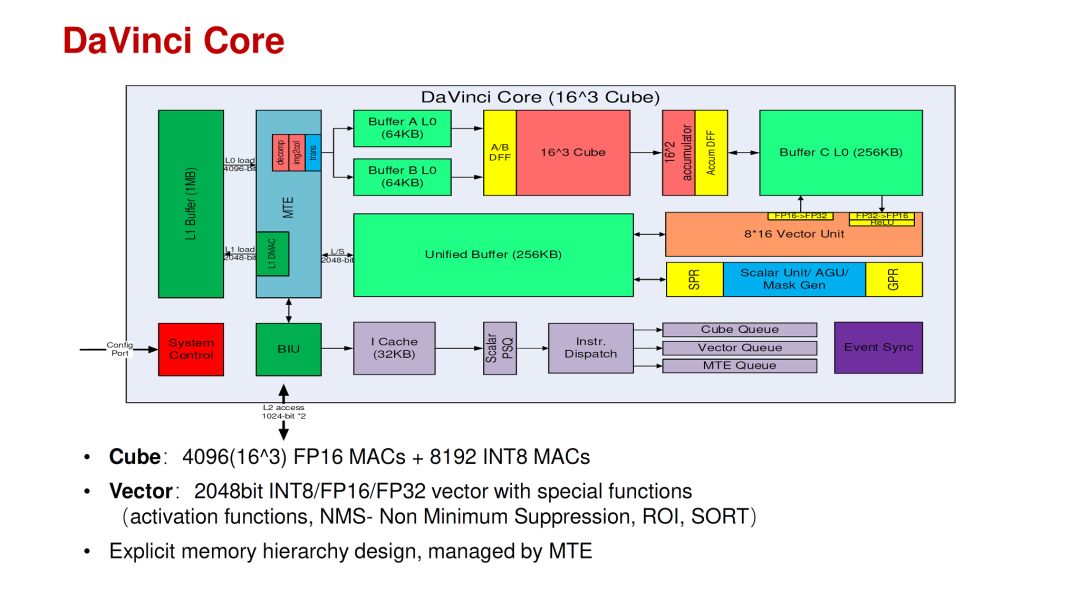
source:Hot Chips 2019 [4]
另外,Intel和Xilinx也展示了他們的AI加速Core的設計。如下:
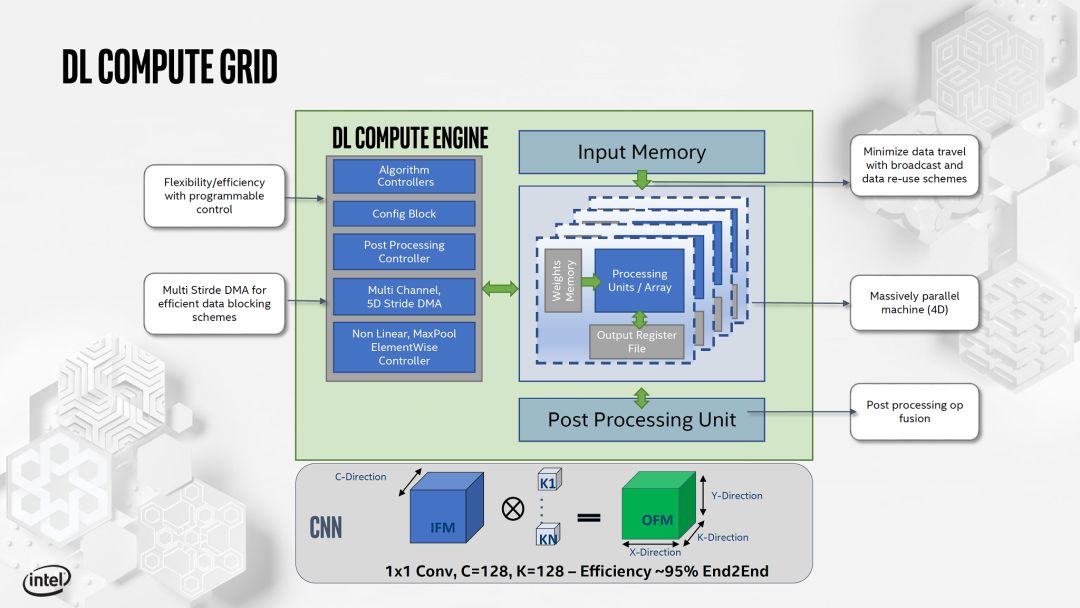
source:Hot Chips 2019 [5]
source:Hot Chips 2019 [6]
從指標來看,目前比較容易對比的主要是云端inference芯片,Nvidia的T4,Habana的Goya,Intel的NNP-I,都有ResNet-50的IPS(Image Per Second)和IPSW(IPS/W)數據。
data source:廠商
如果考慮到T4并不是單純的inference功能,以及NNP-I的工藝優勢,那么大家的Inference IPSW指標的差異并沒有太大。當然,可能得等大家都提交了MLPerf的結果,我們才可能進行更完整和公平的對比。對于指標的分析,大家也可以看看我之前的文章,“數據中心AI Inference芯片今年能達到什么樣的性能?”,看起來我之前的預測沒太大問題。
我們再看Trainning芯片,不論是Nvidia,Google,Habana還是Intel這次發布NNP-T,更重要的已經不是NN加速器core的架構,而是存儲容量,訪存帶寬,和可擴展能力。
所以,不管是從大家公布的架構,還是從指標來看,從TPU,Eyeriss,NVDLA到今天的Tesla FSD芯片和華為的DaVinci Core,如果不考慮基于新型存儲和器件的特殊設計,可以說NN加速器基本的硬件架構已經定型,主要工作是設計參數的優化或者針對不同應用的 trade off。換句話說,新架構(專用處理器相對CPU和GPGPU)的紅利已經充分兌現了。那么,對于架構設計者來說,下一步的機會是什么呢?個人感覺可能有下面一些方向。也歡迎大家留言討論。
第一,更專用NNA的設計。一般來說我們即使是做Domain-Specific設計,也希望芯片能夠面向一類而非一個應用。但如果一個應用(比如只跑一個典型網絡)有足夠大的市場和更嚴格的PPA要求(一般芯片滿足不了),做一個更專用的設計也未嘗不可,甚至可能是很好的機會。這種情況在我們說的IoT應用里比較多,芯片不大,但對PPA很敏感,適合算法硬件協同能力強,并且可以快速迭代的團隊。當然,這種模式成立有個大前提,即AI使能更多新的應用,并越來越快的落地。
第二,從單純NN加速設計到“NN+非NN”加速設計。在NN可以實現真正的end-to-end之前,即使是所謂的AI應用,NN算法和非NN算法也會在一起共存很長時間。一個好的架構應該是加速完整的應用而不僅僅是NN部分(其實用戶根本不在乎你的架構),這個需求在Edge/Device這個應用領域更為明顯。解決這個問題有兩種思路,一個是異構架構的優化,特別是NN和非NN算法在不同硬件架構上的mapping和協同。另一個思路是以比較傳統的Vector DSP(即可以做NN加速,也可以做很多傳統算法,包括CV和語音,有可能會有優勢)為基礎,以特殊指令或緊耦合的加速器的形式集成小規模的Tensor Core,來找到更好的平衡點。
第三,軟硬件協同設計還是有很大空間。在DaVinci的例子里,即使硬件支持不同粒度的運算,在實際網絡怎么用好這些硬件也還是非常困難的課題。最近我討論這個話題也比較多(AI芯片“軟硬件協同設計”的理想與實踐)。其實這次Hot Chips上Google的tutorial就是“Cloud TPU: Codesigning Architecture and Infrastructure”。這里并沒有太多的介紹TPU架構,而是把重心放在了協同設計上,其的內容也遠遠超出了NN加速本身。從這里也可以看出,未來的協同設計不僅僅是NN加速器這一個點,而在“高手過招”當中,必須要完整考慮整個系統的優化。
source:Hot Chips 2019 [7]
一個有趣的插曲是,當我在朋友圈分享這個內容的時候。一個評論是“每次這種會上,都會覺得“哇好有道理”,然后一想好像又啥都沒說”。其實協同設計的現狀也類似,就是看起來很美,做起來不易。
另外,這次會議還有一個來自Stanford AHA Agile Hardware Center的名為“Creating An Agile Hardware Flow”的演講,也是在講如何快速進行軟硬件協同設計。他們的一個思考是,協同設計最大的挑戰在于設計空間太大,為了縮小探索的空間,我們可以使用CGRA可重構硬件架構作為硬件基礎(只需探索CGRA的配置);以HalideDSL作為穩定的軟硬件接口,實現優化的解耦。所以,從軟硬件協同設計這個角度來看,CGRA架構也是非常值得關注的。這個話題我后面會找時間詳細討論。
存內計算和“近存儲”計算
去年的Hot Chips上,基于Flash Cell做存內計算的初創公司Mythic很受關注,我也做過比較詳細的分析(Hot Chips 30 - 機器學習)。這一年以來,基于各種memory cell,包括SRAM,DRAM,FLASH和新型存儲器件,MRAM,RRAM等等的存內計算初創公司大量涌現,非常熱鬧。其實除了存內計算,還有另一類“近存儲”計算。借杜克大學燕博南同學的一張圖說明一下。
其中In-Memory的意思是直接使用存儲單元陣列來做計算,一般是模擬方式,通過AD/DA和數字邏輯部分交互。而Near-Memory則是盡量把運算邏輯(處理器或者加速器)放在離存儲單元比較近的地方。
在這次的會議上,一個初創公司upmem,雖然自稱是PIM,但實際走的是近存儲計算的路線。upmem的產品看起來和傳統的DRAM顆粒和DIMM沒有什么區別,但在每個4Gb DRAM顆粒里嵌入了8個處理器核。
source:Hot Chips 2019 [10]
這是近存儲計算的一個很好的例子,在DRAM里的處理器可以分擔CPU的工作,減少不必要的數據搬移,當然有很多好處。但是要真正把計算邏輯和DRAM放在一起并不是那么容易的,其中最大的挑戰就是如何使用DRAM工藝來支持處理器設計,下圖列舉了主要的困難。
source:Hot Chips 2019 [10]
所以,這個講演的大量內容是如何克服DRAM工藝的這些困難設計處理器,包括:
1. 在DRAM工藝上建立數字邏輯的flow,比如Logic cell library,SRAM IP和Logic Design & Validation flow,這些是處理器設計和實現的基礎;
2. 使用比較“慢”的晶體管設計實現“快”的處理器的方法,14級流水實現500MHz,Interleaved pipeline,24個硬件線程(這個是保證深流水線效率的主要方式)。
3. 不使用Cache,而是Explicit memory hierarchy,這個也和多線程有關系。
4. 優化的指令集,專門強調了沒有使用ARM和RISC-V。這里也解釋了,由于不需要運行OS,所以沒有必要考慮兼容性問題,只要實現CLANG/LLVM的支持。
此外,在DRAM中加了這么多處理器核,怎么使用(編程模型)是個問題。在upmem的講演中也分析了這方面的內容。(此處圖配錯了,抱歉)
source:Hot Chips 2019 [10]
如果我們考慮近存儲計算,其實還有一個大量存儲數據的地方,就是硬盤。因此,現在也有很多的SSD控制器芯片加入的更多的計算功能。比如前一段時間我們看到初創公司InnoGrit就在SSD控制器芯片中加入了NDLA專門加速AI運算。當然除了直接在芯片中增強算力,還有一種模式就是在SSD控制器外增加FPGA,比如三星的Smart SSD方案(下圖)。在這次Hot Chips的Poster里面,就有一個來自Bigstream的工作是基于Smart SSD構建的應用框架。
source:samsungatfirst.com/smartssd/
總的來說,相對存內計算,不依賴工藝進展的近存儲計算可能更容易在短期內落地。但和存內計算一樣,近存儲計算也需要有完整的軟硬件解決方案,否則簡單增加的算力可能僅僅是雞肋。
-
芯片
+關注
關注
459文章
52498瀏覽量
440715 -
半導體
+關注
關注
335文章
28902瀏覽量
237703 -
AI芯片
+關注
關注
17文章
1983瀏覽量
35906
原文標題:史上最大芯片長得像iPad?那你還沒看懂Hot Chips
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
當我問DeepSeek國內芯片封測有哪些值得關注的企業,它這樣回我
【「芯片通識課:一本書讀懂芯片技術」閱讀體驗】圖文并茂,全面詳實,值得閱讀的芯片科普書
Meta啟動史上最大海底電纜項目
ADS1298ECG FE進行設計ECG模擬前端, 有哪些辦法可以最大程度縮小面板的面積?
柵極驅動芯片最大開關頻率的估算方法
ADS1298改DVDD大小除了會影響SCLK的最大速率,還有無其他影響呢?
結合芯片行業現狀,數字芯片設計什么方向最值得投身?


請問同一款芯片,SOIC和SOP除了封裝不同外,還有其他區別嗎?

史上最大屏幕Apple Watch亮相 屏幕面積增加了30%
電流反饋運放的反相輸入端和同相輸入端除了輸入阻抗不同之外還有什么區別嗎?
NVIDIA 在 Hot Chips 大會展示提升數據中心性能和能效的創新技術






 工商網監
工商網監
評論