 關于WEBM視頻解壓縮硬件IP的介紹和分析
關于WEBM視頻解壓縮硬件IP的介紹和分析
WebM 項目 (www.webmproject.org) 定義了一種開放文件格式,用于在 Web 上分發壓縮媒體內容。Google是 WebM 項目的主要貢獻者,最近著手設計和開發了第一個用于 WebM 的硬件解碼器 IP,也稱為 VP9 G2解碼器。利用這種免版稅的硬件 IP,開發多媒體片上系統 (SoC) 設計的公司能夠實現下一代性能和功率效率,在智能電視、平板電腦、移動電話以及傳統個人計算機和筆記本電腦等消費電子設備上實現高達4K (2160p 60FPS) 分辨率的播放效果。VP9 G2 IP 采用全新硬件架構實現,主要是用標準 C++ 編碼和驗證,并利用 Catapult High-Level Synthesis (HLS) 綜合為寄存器傳輸級 (RTL) 邏輯,以支持不同的目標技術和性能點。
本文介紹用于開發 VP9 G2 硬件解碼器的 HLS 方法,并說明它如何支持實現 WebM 項目的目標和戰略。本文解釋了為什么HLS 方法令設計實現和驗證比傳統RTL 設計流程快 50%,以及它如何讓不同最終產品的設計團隊能夠協作并為同一 IP做出貢獻。

圖1. VP9 G2 解碼器硬件
本文還會介紹WebM 團隊在成功實現 G2 VP9 的過程中如何實際使用 Catapult HLS,并分享一些結果和感想。圖 1 顯示了該硬件,包括 HLS 生成的 RTL 模塊和手寫 RTL 模塊。順便提一下,該硬件大約有 200 萬門電路,采用 65 納米 TSMC 技術,支持 4K (2160p) @ 60fps。
WEBM 項目與 G2 VP9
Google WebM 項目的主要目的是改善最終用戶的網絡視頻體驗。用戶收到的視頻質量在很大程度上取決于所使用的壓縮格式,但遺憾的是,與消費者對在線視頻的期望相比,壓縮格式的發展慢如龜速。例如,高效視頻編碼標準(HEVC,也稱為 H.265)花了 10 年時間才從 H.264 發展出來。然后,IP 設計人員又花了 1 年時間編寫和驗證 RTL,總共耗費 11 年時間才推出一代可用硬件。
WebM 項目的目標是大幅縮短編解碼器設計周期,并計劃每隔幾年更新一次開放格式視頻編解碼器。WebM 項目的主要好處是促進硬件 IP 協作,加速創新,并加快部署新的和更好的視頻壓縮標準。在 WebM模型中,Google 為其半導體合作伙伴提供全功能基礎 IP,鼓勵他們增強 IP 并與 Google 共享這些改進,使IP 迅速發展。
目前有十億多端點提供 VP9 解碼支持,包括 Chrome 瀏覽器、Android、FFmpeg 和 Firefox。通過WebM 網站可索取使用 Catapult C 開發的 VP9 硬件編碼器和解碼器。該網站包含有關編碼器和解碼器性能的詳細信息。
快速硬件創新的挑戰
在 VP9 G2 硬件項目即將開始時,WebM 團隊意識到需要一種新的硬件設計方法來支持快速創新。理想情況下,初始硬件和軟件將與技術規范在同一天交付,這意味著設計人員必須能夠隨著規范發展而輕松調整和更新代碼。
與前一代硬件相比,VP9 G2 視頻硬件的復雜度增加了一倍。這意味著仿真運行時間會過于漫長,全部驗證工作預計要花費數月時間。另外,在這個特定領域中,測試向量的數量相當巨大。復雜度的增加不僅會影響總驗證時間,還會影響在合理時間范圍內可以測試的內容。采用 RTL 仿真時,若不大幅增加測試資源,團隊將無法達到所需的測試水平。
以不同產品或應用為目標的多個設計團隊和公司會提出不同的 RTL 變更,合并這些變更也是不切合實際的。以 RTL 代碼編寫的 IP 包含一定程度的與實現相關的細節,這會顯著降低 IP 的可復用性。如果設計人員想要針對不同的 ASIC 技術復用該代碼,或者以更高時鐘速度運行,或者改變吞吐量,他們要么必須大幅重寫 RTL,要么就得接受次優的功耗、性能或面積。
WebM 團隊評估了若干較高抽象層次的工具流程,發現 Catapult C 最符合其需求。
使用 C++ 相比使用 RTL 的優勢
C++ 支持 Google
實現快速創新目標
Innovation
基于 C 語言的 HLS 流程大大減輕了整體 RTL 驗證工作,因為它讓工程團隊可以更迅速地測試源代碼的每項更改,并在不同的硬件和軟件團隊之間共享代碼。源代碼中的低層實現細節越少,仿真、調試和修改的速度越快。更高的仿真性能意味著可以運行更多測試以更充分地演練源代碼;利用行業標準工具來監視和檢查測試集提供的功能覆蓋率。設計人員可以快速高效地修改并重新驗證 C++ 模型來對備選算法和架構執行一系列假設評估,從而能夠基于實際功耗、性能和面積(而非理論估計)來選擇最佳實現。
(向上滑動查看細節)
C++ 是大多數微電子工程師熟悉的語言,常用于硬件和軟件工程設計。C++ 描述代表了一種比 RTL 更抽象的編碼風格,其給出的是算法和架構的描述,而不是精確到每個周期的信號和寄存器行為。與 VHDL 和Verilog 的情況非常相似,C++ 有一個可綜合子集可用于建模和硬件設計。標準 C++ 結構體和方法的絕大部分都是可以使用的,只有少數例外,其依賴于底層軟件處理器架構來執行(例如 “malloc”),這在硬件實現中是沒有意義的。與 RTL 相比,可綜合 C++ 表示的代碼行數平均減少 80%,冗長細節的縮減使其對人類更有意義,調試也更容易、更快捷。類似的功能用C++ 仿真的速度要比用 RTL 快 50-1000 倍;當設計和調試復雜硬件時,使用 C++ 的硬件開發人員只需大約一半的時間。
C++ 模型常常被開發為黃金參考模型,硬件設計對照該模型進行驗證。這些參考模型用作硬件實現的起點。如果 C++ 模型本身是可綜合的,則可以避免手動重寫入 RTL,軟件或算法工程師與硬件團隊之間將能實現平滑交接。這會減少因為規范模糊和誤讀而出錯的機率。在硬件設計過程中,系統架構師和硬件設計工程師均可使用相同的共享代碼庫。以這種方式共享可執行代碼意味著概念易于傳達,構思不會有被誤解的風險,并且從概念到實現,所有人都可以共享并明確無誤地使用統一的規范。
在很多不同小組之間共享代碼還需要一個標準化環境。對用 C++ 建模的設計進行功能驗證時,可以使用眾多行業標準編譯器和調試工具中的任何一個,例如 gcc 或 MSVisual C++。還有許多其他工具可用于分析源代碼,對源代碼數據庫版本加以控制,以及合并來自多個開發人員的 C++ 更改。
對于 WebM 團隊的硬件 IP 開發,可在該 IP 仍處于開發階段時,將 C++ 代碼和標準化開發環境與其 IP 合作
伙伴共享。反過來,合作伙伴在此過程中也能分享見解并糾正錯誤,使得生產硬件幾乎可以在標準最終確定并發布的同時交付。
用 C++ 能夠準確描述硬件的一個重要方面是使用比特精確數據類型,運用 C++ 類庫可以在任何標準 C++環境中執行。其他硬件設計特性,如時鐘頻率、并行性、寄存器和組件共享以及許多其他微架構細節,均未寫入 C++ 代碼中。C++ 模型中僅描述了算法和功能行為。這意味著只需修改用于驅動綜合工具的命令和約束,同一 C++ 表示便可輕松適用于不同的微架構或性能點以及不同的實現技術(ASIC 和 FPGA)。
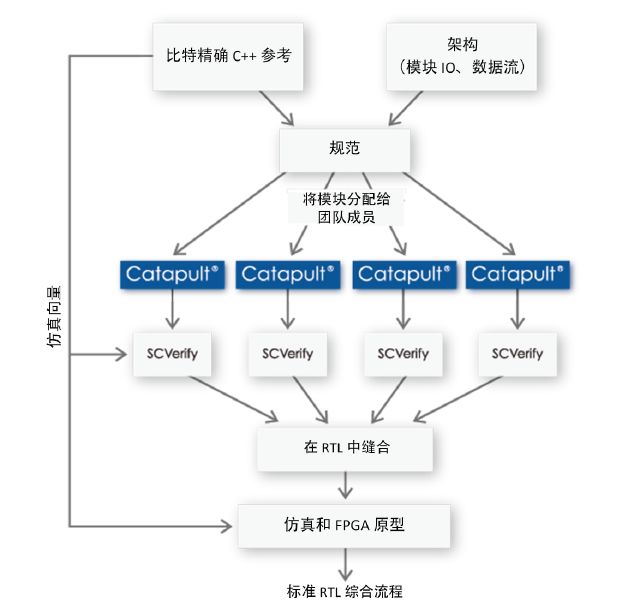
圖 2. G2 VP9 設計和驗證流程
為了管理其第一個 HLS 項目的風險,WebM 團隊決定將視頻解碼器的每個模塊作為一個單獨的項目來實現。該流程允許多個模塊由不同工程師并行優化,而頂層互連模型則是手動編寫。它還支持將 Catapult 用在能夠產生最大益處的地方,對算法模塊進行一些必要的探索以確定最優架構。其他包含 SoC 集成關鍵部件(例如時鐘門控、SRAM 容器)的模塊則是用 RTL 實現。其結果便是圖 1 所示的硬件劃分,相應的設計和驗證流程如圖 2 所示。
WebM 工程師需要接受培訓才能使用 HLS,但他們很快意識到,用 C++ 編寫與用 VHDL 或 Verilog 編寫具有相同的“體驗”。就像用 RTL 一樣,設計人員首先需要可視化其想要構建的硬件,然后以該硬件為目標來編寫代碼。要學習的主要內容是編寫什么樣的 C++ 代碼。
通過轉向使用 C++ 的 HLS 流程來開發 VP9 G2 硬件,團隊獲得了以下好處:
1. 一個包含 14 個模塊設計的總代碼行數約為 69,000。硬件設計團隊估計,要描述相同的模塊,基于 RTL的方法將需要大約 300,000 行代碼。
2. C++ 仿真運行比 RTL 快 50 多倍。這大大減少了驗證工作的跟蹤需求,開發人員可以整天編寫代碼,晚上離開后開始進行回歸處理,第二天早上獲得套件中每項測試的結果。
3. 使用 C++ 實現了 IP 協作,允許多個貢獻者共享對同一文件的改進,并支持標準工具和流程來合并更改。
4. HLS 可以在大約一個小時內處理完每個模塊。因此,通過修改 C 代碼或改變工具的約束,可以快速完成對模塊不同架構的探索。設計和驗證硬件的總工作量大約為六個月,而用 RTL 手動編寫代碼預計需要一年。
使用 CATAPULT HLS 流程
實現 G2 VP9 解碼器 IP 的示例
幀間預測模塊是 VP9 硬件中最復雜的部分之一。如圖 1 顯示,它是幀間/幀內預測模塊的一部分。該模塊負責計算連續視頻幀之間的像素預測值。
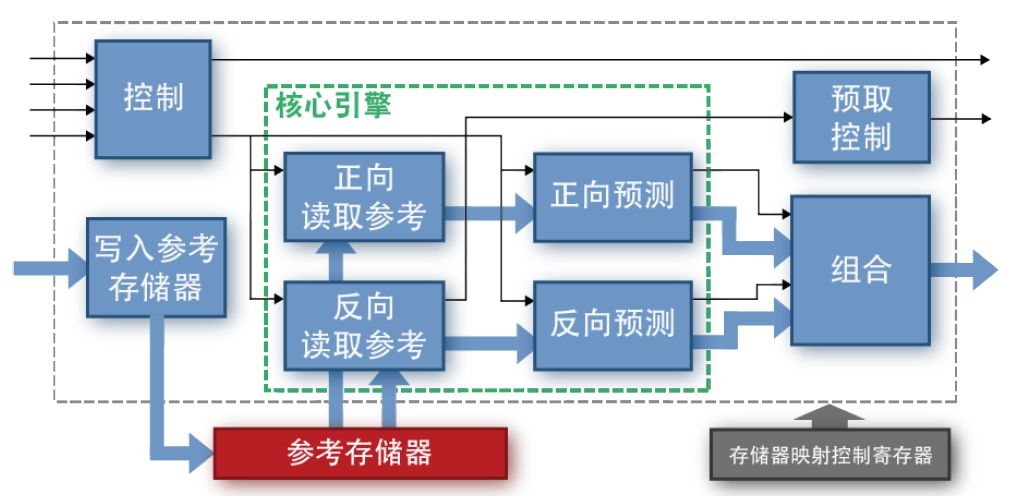
圖 3. 幀間預測模塊的高層次框圖
如圖 3 所示,幀間預測模塊中有八個進程。該模塊以三種方式進行控制。首先,使用存儲器映射寄存器配置該模塊。其次,將命令流發送到控制進程,然后控制進程向幀內預測模塊中的核心引擎發出命令。
還有一個單獨的預取控制進程會監視設計中參考存儲器的狀態,并預取新數據。最后,使用流控制握手功能將數據流送到“寫入參考存儲器”(Write Ref Mem) 進程。
一旦參考存儲器中有足夠的存儲器可用,該架構便允許幀間預測模塊預取數據。然后在正向和反向預測數據合并為一個輸出流之前,控制核心 Ref 和 Pred 引擎盡可能快地處理數據。幀間預測模塊隨后將數據和命令轉發到子系統中的下一模塊,即去塊濾波器。
在硬件中,各模塊必須并行運行,速率常常不同。但是,源代碼是順序 C++,因此使用算法 C (AC) ac_channel數據類型來模擬模塊之間的并行性和不同速率。以下代碼是幀間預測模塊的頂層源代碼的簡化版本。


幀間預測模塊大約有 8000 行 C++ 代碼,包括所有相關的頭文件。設計的結構使用 ac_channel 和函數調用來描述,然后將每個函數映射到進程或其他級別的層次結構。ac_channel 的方向取決于 C 代碼中如何使用它,Catapult 檢查每個通道只有一個進程寫入。
在 C++ 仿真中,ac_channel 是一個無限深度的 FIFO,支持簡單的分層子系統仿真,就好像函數并行運行一樣。然后在用 C++ 編寫的完整子系統內部仿真源代碼,以確認硬件和軟件都正常工作。為了測試該模塊,每個函數調用都包含一個循環,其迭代到所有輸入數據都消耗完畢為止。
接下來,pred_inter 函數被綜合為 RTL。在綜合期間,函數轉換為模塊之間具有固定深度 FIFO 的并行進程。Catapult 為 RTL 生成 SystemC 封裝器,以便可以使用原始測試環境來確認 RTL 是否正常運行。
然后,pred_inter 的 RTL 需要與其他生成的 RTL 模塊集成,如圖 2 所示。對于 VP9,這種集成是在 Verilog中手動完成。圖 1 顯示了此子系統中的模塊以及用來連接它們的手工編碼 FIFO。然后運行該子系統,使用的仿真向量與測試原始可綜合 C++ 子系統所用的向量相同。
最后將 RTL 用于 FPGA 進行原型開發,或用于 ASIC 以完成最終實現。對于這兩個目標,C++ 代碼相同,因此 FPGA 原型開發可以輕松完成而不會犧牲最終 ASIC 實現的質量。
與 VP9 子系統的其余部分一樣,該模塊最初僅針對 VP9 開發,然后做了改進以支持 H.265。根據編譯時轉換,可以將整個子系統重新配置和重新優化為僅支持 VP9 或同時支持 VP9 與 H.265。
總結和結語
Catapult
與許多前沿硬件設計團隊一樣,WebM 硬件團隊需要找到更好的辦法來構建硬件。驗證預計要占開發工作量的相當大一部分,而且硬件難以復用。最重要的是,這意味著團隊沒有足夠的時間去構建最小、最快、功率效率最高的硬件。
現在,Google 工程師已完成第一個項目,他們學會了在編寫可綜合 C++ 的同時“看見硬件”。他們還學會了為特定類型的硬件編寫什么樣的代碼。
-
模塊
+關注
關注
7文章
2783瀏覽量
49553 -
編譯
+關注
關注
0文章
676瀏覽量
33746 -
C代碼
+關注
關注
1文章
90瀏覽量
14674
發布評論請先 登錄
有人接rk3576的安卓視頻硬件解碼的實現么?
EE-257:面向Blackfin處理器的引導壓縮/解壓縮算法

嵌入式學習-飛凌嵌入式ElfBoard ELF 1板卡-Linux內核移植之內核啟動流程
飛凌嵌入式ElfBoard ELF 1板卡-Linux內核移植之內核啟動流程
飛凌嵌入式ElfBoard ELF 1板卡-內核源代碼的目錄結構和文件說明
[匠芯創科技]匠芯創AIUIBuilder工具使用初體驗
慧視高效壓縮技術 解決多路視頻傳輸難點

在米爾電子MPSOC實現12G SDI視頻采集H.265壓縮SGMII萬兆以太網推流
在米爾電子MPSOC實現12G SDI視頻采集H.265壓縮SGMII萬兆以太網推流
如何使用gzip壓縮和解壓縮技術
【米爾NXP i.MX 93開發板試用評測】2、異構通信環境搭建和源碼編譯
SAP B1 Web Client & MS Teams App集成連載二:安裝Install/升級Upgrade/卸載Uninstall






 工商網監
工商網監
評論