完善資料讓更多小伙伴認(rèn)識(shí)你,還能領(lǐng)取20積分哦,立即完善>
標(biāo)簽 > 梯度
文章:25個(gè) 瀏覽:10446次 帖子:2個(gè)
你知道XGBoost背后的數(shù)學(xué)原理是什么嗎?
在第一種方法的基礎(chǔ)上,每走過特定數(shù)量的臺(tái)階,都由韓梅梅去計(jì)算每一個(gè)臺(tái)階的損失函數(shù)值,并從中找出局部最小值,以免錯(cuò)過全局最小值。每次韓梅梅找到局部最小值,...
2018-08-22 標(biāo)簽:梯度機(jī)器學(xué)習(xí) 6.5萬 0
AdaBoost效果不錯(cuò),但為何這一算法如此成功卻缺乏解釋,這正是一些疑惑產(chǎn)生的源頭。有些人認(rèn)為AdaBoost是一個(gè)超級(jí)算法,一枚銀彈,但另一些人顧慮...
2018-11-08 標(biāo)簽:梯度機(jī)器學(xué)習(xí)數(shù)據(jù)科學(xué) 2.5萬 0
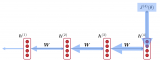
RNN存在的問題及其改進(jìn)方法,并介紹更多復(fù)雜的RNN變體
梯度爆炸/消失不僅僅是RNN存在的問題。由于鏈?zhǔn)椒▌t和非線性激活函數(shù),所有神經(jīng)網(wǎng)絡(luò)(包括前向和卷積神經(jīng)網(wǎng)絡(luò)),尤其是深度神經(jīng)網(wǎng)絡(luò),都會(huì)出現(xiàn)梯度消失/爆炸...
2019-05-05 標(biāo)簽:神經(jīng)網(wǎng)絡(luò)梯度rnn 1.7萬 0
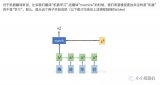
為什么要有attention機(jī)制,Attention原理
沒有attention機(jī)制的encoder-decoder結(jié)構(gòu)通常把encoder的最后一個(gè)狀態(tài)作為decoder的輸入(可能作為初始化,也可能作為每一...

Attention Transfer , 傳遞teacher網(wǎng)絡(luò)的attention信息給student網(wǎng)絡(luò)。首先,CNN的attention一般分為兩...
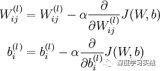
最近在做一個(gè)文本檢測(cè)的項(xiàng)目,在訓(xùn)練的過程中遇到了很嚴(yán)重的梯度爆炸情況,今天就來談?wù)勌荻缺ㄔ趺唇鉀Q。
2018-04-30 標(biāo)簽:神經(jīng)網(wǎng)絡(luò)梯度 1.5萬 0

微流控技術(shù)為在推動(dòng)生物學(xué)眾多領(lǐng)域的強(qiáng)大工具做出了巨大貢獻(xiàn)
微流控技術(shù)可以控制通道中的流體層流流動(dòng),從而產(chǎn)生多個(gè)數(shù)量級(jí)的濃度梯度。目前已經(jīng)有一些研究使用這些梯度來分析蛋白梯度中的中性粒細(xì)胞的遷移和白細(xì)胞介素-8(...
2018-02-05 標(biāo)簽:算法梯度機(jī)器學(xué)習(xí) 9972 0
通過Python將故宮的建筑物圖片,轉(zhuǎn)化為手繪圖
把圖像看成二維離散函數(shù),灰度梯度其實(shí)就是這個(gè)二維離散函數(shù)的求導(dǎo),用差分代替微分,求取圖像的灰度梯度。常用的一些灰度梯度模板有:Roberts 梯度、So...
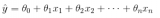
梯度下降是一種非常通用的優(yōu)化算法,它能夠很好地解決一系列問題。梯度下降的整體思路是通過的迭代來逐漸調(diào)整參數(shù)使得損失函數(shù)達(dá)到最小值。
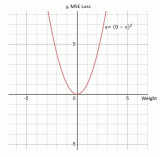
三種常見的損失函數(shù)和兩種常用的激活函數(shù)介紹和可視化
從上面闡釋的步驟可以看出,神經(jīng)網(wǎng)絡(luò)中的權(quán)重由損失函數(shù)的導(dǎo)數(shù)而不是損失函數(shù)本身來進(jìn)行更新或反向傳播。因此,損失函數(shù)本身對(duì)反向傳播并沒有影響。下面對(duì)各類損失...

其中 W^ 卷積層的權(quán)重,* 是卷積運(yùn)算。將圖2 所示作為一個(gè)例子,WS方法不會(huì)直接在原始權(quán)重上進(jìn)行優(yōu)化,而是采用另一個(gè)函數(shù) W^=WS(W)來表示原始...
2019-04-08 標(biāo)簽:算法梯度深度學(xué)習(xí) 7461 0
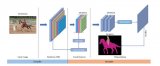
我們可以看到,該網(wǎng)絡(luò)將傳統(tǒng)的非線性插值替換成 DUpsample,同時(shí)在 feature fuse 方面,不同于之前方法將 Decoder 中的特征上采...
2019-04-08 標(biāo)簽:函數(shù)梯度數(shù)據(jù)集 6716 0
SGD的隨機(jī)項(xiàng)在其選擇最終的全局極小值點(diǎn)的關(guān)鍵性作用
在這篇題為《將擬勢(shì)函數(shù)視為隨機(jī)梯度下降損失函數(shù)中的隱式正則項(xiàng)》的論文中,作者提出了一種統(tǒng)一的方法,將擬勢(shì)作為一種量化關(guān)系的橋梁,在SGD隱式正則化與SG...
2019-03-06 標(biāo)簽:神經(jīng)網(wǎng)絡(luò)梯度機(jī)器學(xué)習(xí) 5585 0
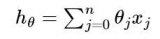
以線性回歸算法來對(duì)三種梯度下降法進(jìn)行比較
從上面公式可以注意到,它得到的是一個(gè)全局最優(yōu)解,但是每迭代一步,都要用到訓(xùn)練集所有的數(shù)據(jù),如果樣本數(shù)目 m 很大,那么可想而知這種方法的迭代速度!所以,...
2019-04-19 標(biāo)簽:函數(shù)梯度機(jī)器學(xué)習(xí) 4309 0
一些人會(huì)懷疑:難道神經(jīng)網(wǎng)絡(luò)不是最先進(jìn)的技術(shù)?
如上圖所示,sigmoid的作用確實(shí)是有目共睹的,它能把任何輸入的閾值都限定在0到1之間,非常適合概率預(yù)測(cè)和分類預(yù)測(cè)。但這幾年sigmoid與tanh卻...
2018-06-30 標(biāo)簽:神經(jīng)網(wǎng)絡(luò)梯度深度學(xué)習(xí) 3510 0

梯度下降算法在深度學(xué)習(xí)中扮演著舉足輕重的地位
這里的歐幾里得距離公式也可以換成其他距離公式(下文延伸分享其他距離公式)。這同樣也解釋了,我們?yōu)槭裁从袝r(shí)候在損失函數(shù)里面加上一個(gè)L2損失函數(shù)會(huì)更好,這樣...
2019-04-10 標(biāo)簽:算法梯度深度學(xué)習(xí) 2811 0
好像我們已經(jīng)解決了這個(gè)問題,感覺有點(diǎn)輕松啊。高興之余,突然回過神來,那個(gè)步長(zhǎng)我設(shè)的好像有點(diǎn)隨意啊,迭代了20輪還沒有完全收斂,是不是我太保守了,設(shè)得有點(diǎn)...
2023-03-13 標(biāo)簽:函數(shù)梯度機(jī)器學(xué)習(xí) 598 0
 換一批
換一批
編輯推薦廠商產(chǎn)品技術(shù)軟件/工具OS/語言教程專題
| 電機(jī)控制 | DSP | 氮化鎵 | 功率放大器 | ChatGPT | 自動(dòng)駕駛 | TI | 瑞薩電子 |
| BLDC | PLC | 碳化硅 | 二極管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 無刷電機(jī) | FOC | IGBT | 逆變器 | 文心一言 | 5G | 英飛凌 | 羅姆 |
| 直流電機(jī) | PID | MOSFET | 傳感器 | 人工智能 | 物聯(lián)網(wǎng) | NXP | 賽靈思 |
| 步進(jìn)電機(jī) | SPWM | 充電樁 | IPM | 機(jī)器視覺 | 無人機(jī) | 三菱電機(jī) | ST |
| 伺服電機(jī) | SVPWM | 光伏發(fā)電 | UPS | AR | 智能電網(wǎng) | 國(guó)民技術(shù) | Microchip |
| Arduino | BeagleBone | 樹莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 華秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS |
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1

