 電子發燒友App
電子發燒友App


人工智能正在不僅僅是芯片和系統設計的話題,它承擔著越來越復雜的任務,這些任務現在已成為許多市場的競爭要求。
但是,人工智能及其機器學習和深度學習子類別的加入也給電子產品的各個方面注入了廣泛的混亂和不確定性。這部分是因為它涉及許多不同的設備和流程,部分原因是人工智能本身在不斷變化。
人工智能涵蓋了從訓練算法到推理的方方面面。它包括大量的訓練計劃,以及可以適應微型物聯網設備的tinyML算法。此外,它越來越多地用于芯片設計的許多方面,以及在晶圓廠中,以關聯來自這些芯片的制造、檢查、計量和測試的數據。它甚至在現場用于識別故障模式,這些模式可以反饋到未來的設計和制造過程中。
在這個廣泛的應用程序和技術集合中,有幾個共同的目標:
對于任何 AI 風格或應用,每瓦或每次操作的性能都是一個關鍵指標。需要生成和存儲能量以執行 AI/ML/DL 計算,并且在資源、公用事業和面積方面存在相關成本。
算法的訓練通常涉及乘法/累加運算的大規模并行化。效率來自超大規模數據中心中計算元素的彈性——能夠根據需要增加計算資源,并在不需要時將其轉移到其他項目——以及更智能地使用這些資源以及越來越精細的稀疏性模型。
谷歌首席科學家杰夫·迪恩(Jeff Dean)指出了機器學習模型的三個趨勢——稀疏性、自適應計算和動態變化的神經網絡。“密集模型是指為每個輸入示例或生成的每個代幣激活整個模型的模型,”他在最近的Hot Chips會議上的演講中解釋道。“雖然它們很棒,并且已經取得了重要成就,但稀疏計算將成為未來的趨勢。稀疏模型具有不同的路徑,可以根據需要自適應調用。
正在改變的是人們認識到,這些稀疏模型可以更智能地跨處理元素進行分區。“在每個示例上花費相同數量的計算是沒有意義的,因為有些示例的難度是原來的 100 倍,”Dean 說。“因此,我們應該將100倍的計算花在真正困難的事情上,而這些事情非常簡單。
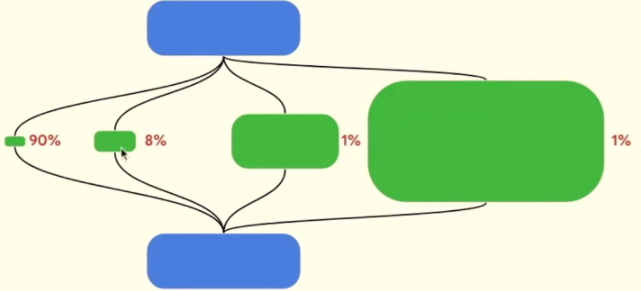
圖 1:具有粒度稀疏性的自適應計算。資料來源:Google/Hot Chips 2023
邊緣的資源和計算模型有很大不同,但抽象、自定義和調整大小的相同基本原則仍然適用。
抽象更多的是著眼于局部和系統級別的權衡。例如,基本上可以硬連接處理器或加速器的某些元素,同時提供足夠的靈活性來整合未來的變化。當一個器件可能用于多個應用,并且芯片的預期壽命足夠長以保證一定程度的可編程性時,這尤其有用。這與為先進節點 SoC 開發的一些模擬 IP 的方法類似,其中大部分架構都是數字架構。
Flex Logix首席技術官兼聯合創始人Cheng Wang表示:“重要的是,從這些硬連線塊饋入和饋出的內存或數據路徑能夠支持我們需要的排列,因為很多時候,對于AI工作負載,訪問模式可能有點不穩定。“對于人工智能來說,這也是很常見的,在將數據輸入引擎之前,你需要添加一些偏移量作為數據的一些比例因子。當然,引擎是硬連線的,輸出必須經過一些靈活的激活功能,并根據工作負載的需求路由到SRAM或DRAM或兩者兼而有之。因此,所有這些靈活性都是必需的,并且需要到位以保持MAC的效率。例如,如果您的內存帶寬不足,則必須停止,在這種情況下,MAC的速度有多快都無關緊要。如果你停滯不前,你將以內存的速度運行,而不是以計算機的速度運行。
合理調整規模
出于類似的原因,內存架構也在發生變化。“人工智能越來越多地被用于提取有意義的數據并將其貨幣化,”Rambus的研究員和杰出發明家Steven Woo在最近的一次演講中說。“它確實需要非常快的內存和快速接口,不僅用于服務器,還用于加速引擎。我們看到對性能更快的內存和互連的無情需求,我們預計這一趨勢將持續到未來很長一段時間。我們看到該行業正在做出回應。數據中心正在不斷發展,以滿足數據驅動型應用程序(如人工智能和其他類型的服務器處理)的需求。隨著我們從 DDR4 過渡到 DDR5,我們看到主內存路線圖發生了變化,我們也看到 CXL 等新技術進入市場,因為數據中心從更多的專屬資源演變為池化資源,可以改善我們今天所處的水平的計算。
同樣的趨勢也在重新定義邊緣。“芯片組制造商正在與芯片開發團隊合作,從系統的角度來看待它的性能和功耗,”華邦市場主管C.S. Lin說。“那么對于這種產品,你需要什么樣的帶寬呢?而SoC端需要什么樣的工藝,需要什么樣的內存?例如,所有這些都需要配對在一起才能實現每秒 32 Gb 的速度(對于 NVMe PCIe Gen 3)。然后,為了做到這一點,你需要在芯片中集成一個協議,只有最先進的工藝才能提供這種東西。
無論是云還是邊緣,AI 應用程序越來越需要定制和調整規模。如今,幾乎所有的算法訓練都是在大型數據中心完成的,其中MAC功能的數量可以增加或減少,計算可以在不同的元素之間進行分區。隨著算法變得更加成熟、稀疏和越來越個性化,這種情況可能會改變。但大多數計算世界將利用這些人工智能算法進行推理,至少目前是這樣。
“到75年,大約2025%的數據將來自網絡的邊緣和端點,”瑞薩電子執行副總裁Sailesh Chittipeddi在SEMICON West的小組討論中表示。“你預測邊緣和端點發生的情況的能力確實產生了巨大的影響。當您想到計算時,您會想到微控制器、微處理器以及 CPU 和 GPU。最新的嗡嗡聲都是關于 GPU 以及 GPT3 和 GPT4 正在發生的事情。但這些都是大型語言模型。對于大多數數據集,你不需要如此巨大的處理能力。
邊緣的挑戰之一是快速丟棄無用的數據,只保留需要的數據,然后更快地處理這些數據。“當人工智能處于邊緣時,它正在與傳感器打交道,”艾伯德首席科學家兼聯合創始人Sharad Chole說。“數據是實時生成的,需要處理。因此,傳感器數據的傳入方式以及 AI NPU 處理數據的速度會改變很多事情,包括需要緩沖的數據量、需要使用多少帶寬以及整體延遲。目標始終是盡可能低的延遲。這意味著從傳感器輸入到輸出的延遲應該盡可能低,輸出可能會進入應用處理器進行進一步的后處理。我們需要確保我們能夠以確定性的方式提供這些數據作為保證。
準確性的代價
對于任何 AI 應用程序,性能都是衡量獲得結果時間的指標。人工智能系統通常會在乘法/累加元素之間劃分計算以并行運行,然后盡快收集和混合結果。獲得結果的時間越短,所需的能源就越多,這就是為什么圍繞加工元素和架構的定制有如此多的嗡嗡聲。
通常,需要更多的計算元素才能在更短的時間內生成更準確的結果。這在某種程度上取決于數據質量,數據質量需要既好又相關,并且需要針對任務對算法進行適當的訓練。通用處理器的效率較低,通用算法也是如此。此外,對于許多終端應用來說,人工智能的數量(包括機器學習和深度學習等子類別)可能會受到整體系統設計的限制。
這是一個架構改進的成熟領域,一些創新的權衡開始出現。例如,Arm 首席 CPU 架構師兼研究員 Magnus Bruce 表示,Arm 專門為云、高性能計算和 AI/ML 工作負載創建了一個新的 Neoverse V2 平臺。在最近的 Hot Chips 會議上的一次演講中,他強調了分支預測與提取的分離,以提高分支預測管道中的性能,以及包括準確性監控在內的高級預取。簡而言之,目標是更精細地預測芯片的下一步操作,并在出現錯誤預測時縮短恢復時間。
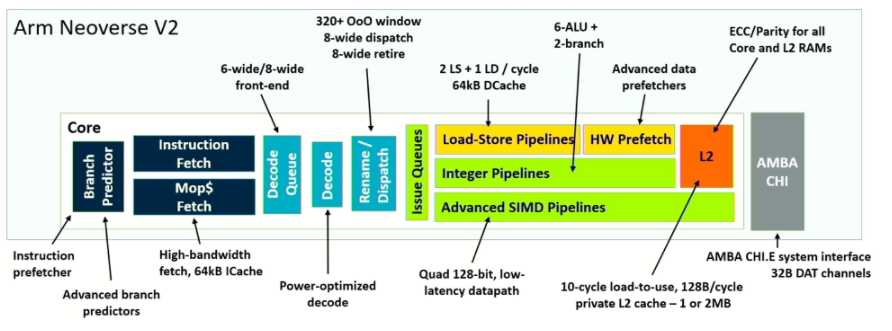
圖 2:基于精度提高的架構和微架構效率。資料來源: Arm/Hot Chips 23
使用 AI進行設計
除了架構更改之外,人工智能還可能幫助改進、加速硬件設計。
“客戶關心的基本指標仍然是功耗、性能、面積和進度,”Synopsys EDA 部門總經理 Shankar Krishnamoorthy 說。“但改變的是,由于負載復雜性、設計復雜性和驗證復雜性,實現這一目標的工程成本急劇上升。有幾位客戶告訴我們,這是必不可少的 4 倍的工作量。他們幾乎不能再增加 10% 或 20% 的工程師,那么誰來縮小這一差距呢?這確實是人工智能介入的地方,在幫助解決這個問題方面,它已經成為一個很大的顛覆者。
其他人也同意。“AI/ML是一個熱門話題,但它改變了哪些市場,并撼動了人們以前沒有想到的市場?EDA就是一個很好的例子,“Quadric營銷副總裁Steve Roddy說。“經典合成/布局布線的核心是從一種抽象到另一種抽象的轉換。從歷史上看,這是通過啟發式方法、編譯器創建者和生成器完成的。突然之間,如果你能使用機器學習算法來加速或獲得更好的結果,你就完全擾亂了現有的行業。機器學習的出現是否會動搖一些現有的硅平臺?我的筆記本電腦會繼續使用四核處理器,還是會突然讓機器學習處理器定期完成大量工作?圖形一直是一場持續的競賽,以在手機和電視上獲得更高的圖形生成以獲得更清晰的分辨率,但人們越來越多地談論部署機器學習升級。因此,您可以使用低得多的分辨率使用 GPU 渲染某些內容,并使用機器學習算法對其進行升級。然后,您就不再是可以將多少個 GPU 集成到手機中并保持在電源包中。而是,“讓我回到五代,擁有更小、更節能的 GPU,并對其進行升級,因為也許人眼看不到它。或者,根據照明和一天中的時間,您可以以不同的方式對其進行升級。這些事情會讓標準變得不合時宜。
這對于加快設計的復雜建模可能特別有用,特別是當同一芯片或同一封裝中有許多不同的計算元素時。“如果你在模型中加入太多的依賴關系,那么模擬它們需要比實際更多的時間,”Fraunhofer IIS自適應系統工程部設計方法負責人Roland Jancke說。“然后你過度設計了模型。但是,建模始終是盡可能抽象和準確的問題。多年來,我們一直建議采用多層次的方法,這樣你就有了不同層次抽象的模型,而你想真正研究的地方,你就更深入地了解更多細節。
人工智能可能會有很大幫助,因為它能夠關聯數據,這反過來又應該會支持人工智能市場,因為設計過程可以自動化,用于開發人工智能芯片和芯片本身。
Synopsys的Krishnamoorthy表示:“目前,AI芯片社區的收入約為20億至30億美元,預計到本世紀末將增長到100億美元。“[在EDA方面],它是關于如何優化設計以獲得更好的PPA,并與經驗早期的工程師一起獲得專家級質量的結果。在驗證的情況下,它實現了比當前方法更高的覆蓋率,因為人工智能可以自主搜索更大的空間。在測試的情況下,它減少了測試儀上的圖案計數,這直接轉化為測試成本和測試時間。在定制設計的情況下,它會自動將模擬電路從 5nm 遷移到 3nm,或從 8nm 遷移到 5nm。在過去,這曾經是手動工作。
定制價格
但是,即使在設計最好的系統中,也存在許多變量和意想不到的結果,它們會影響從數據路徑建模到MAC功能如何在不同處理元素之間分區的方方面面。例如,這種分區可能在晶圓廠或封裝廠中得到完美調整,但隨著加工元件的老化,它們可能會不同步,使其中一些元件在等待其他元件完成加工時閑置并燃燒電力。同樣,互連、存儲器和 PHY 可能會隨著時間的推移而退化,從而產生時序問題。更糟糕的是,算法中幾乎不斷的變化可能會對整體系統性能產生重大影響,遠遠超出單個MAC元素。
在過去的十年中,其中許多問題已經在大型系統公司內部得到解決,這些公司越來越多地設計自己的芯片供內部使用。隨著越來越多的計算轉移到邊緣,這種情況正在發生變化,在邊緣,功耗直接影響車輛每次充電的行駛里程,或者如果可穿戴設備執行的操作超過最基本的操作,它的實用性會有多大。
這里的關鍵是了解這些設計中要整合多少 AI,以及 AI 究竟應該做什么。高效的 SoC 通常會根據需要使用可能較暗或“熱”的處理內核來打開和關閉各種組件。但是,高效的 AI 架構可以使許多處理元素以最大速度運行,因為它將計算分解為并行操作,然后收集結果。如果其中任何一個元素的計算延遲,就會浪費時間和精力。如果做得好,這可能會導致超快的計算速度。然而,這種速度確實是有代價的。
其中一個問題是,學習并沒有在整個行業中得到廣泛共享,因為其中許多前沿設計都是為系統公司的內部使用而開發的。這減緩了知識轉移和行業學習的速度,而這些知識轉移和行業學習通常發生在處理器系列的每個新版本或市場上用戶審查的消費產品中。
結論
雖然圍繞 AI/ML/DL 有很多嗡嗡聲,但它不再是炒作。它正在實際應用中使用,并且隨著設計團隊找出最有效的方法以及如何將其應用于他們的設計,它只會在效率、性能和準確性方面得到提高。幾乎可以肯定的是,會有一些小問題和更多的不確定性,比如人工智能在適應和優化系統時如何隨著時間的推移而老化。但毫無疑問,在可預見的未來,人工智能已經到來,只要有足夠的資源和興趣,它就會繼續變得更好。
“您今天看到的真實用例每天都在發生,甚至從語音處理開始,”瑞薩電子的Chittipeddi說。“這在10年前是不可能的。從根本上改變的是將人工智能應用于實際用例的能力。它正在改變景觀。
審核編輯:黃飛















 工商網監
工商網監
評論