") AI芯片的架構(gòu)和傳統(tǒng)芯片有什么不同?
AI芯片的架構(gòu)和傳統(tǒng)芯片有什么不同?
前兩天成立僅兩年國內(nèi)專做人工智能FPGA加速算法的初創(chuàng)公司深鑒科技被國際巨頭賽靈思收購了,在業(yè)界引起不小的震動(dòng)。目前國內(nèi)做AI芯片的公司可謂不少了,AI芯片已然成為了當(dāng)下芯片行業(yè)最熱領(lǐng)域。但是大部分人對AI芯片的架構(gòu)應(yīng)該都不是太了解。那么AI 芯片和傳統(tǒng)芯片有何區(qū)別?AI芯片的架構(gòu)到底是怎么樣的?帶著這個(gè)疑問小編搜集到了來自知乎上的一些業(yè)內(nèi)行家的觀點(diǎn),現(xiàn)在整理轉(zhuǎn)發(fā)給大家。
(1)性能與傳統(tǒng)芯片,比如CPU、GPU有很大的區(qū)別。在執(zhí)行AI算法時(shí),更快、更節(jié)能。
(2)工藝沒有區(qū)別,大家都一樣。至少目前來看,都一樣。
所謂的AI芯片,一般是指針對AI算法的ASIC(專用芯片)。
傳統(tǒng)的CPU、GPU都可以拿來執(zhí)行AI算法,但是速度慢,性能低,無法實(shí)際商用。
比如,自動(dòng)駕駛需要識(shí)別道路行人紅綠燈等狀況,但是如果是當(dāng)前的CPU去算,那么估計(jì)車翻到河里了還沒發(fā)現(xiàn)前方是河,這是速度慢,時(shí)間就是生命。如果用GPU,的確速度要快得多,但是,功耗大,汽車的電池估計(jì)無法長時(shí)間支撐正常使用,而且,老黃家的GPU巨貴,經(jīng)常單塊上萬,普通消費(fèi)者也用不起,還經(jīng)常缺貨。另外,GPU因?yàn)椴皇菍iT針對AI算法開發(fā)的ASIC,所以,說到底,速度還沒到極限,還有提升空間。而類似智能駕駛這樣的領(lǐng)域,必須快!在手機(jī)終端,可以自行人臉識(shí)別、語音識(shí)別等AI應(yīng)用,這個(gè)必須功耗低,所以GPU OUT!
所以,開發(fā)ASIC就成了必然。
說說,為什么需要AI芯片。
AI算法,在圖像識(shí)別等領(lǐng)域,常用的是CNN卷積網(wǎng)絡(luò),語音識(shí)別、自然語言處理等領(lǐng)域,主要是RNN,這是兩類有區(qū)別的算法。但是,他們本質(zhì)上,都是矩陣或vector的乘法、加法,然后配合一些除法、指數(shù)等算法。
一個(gè)成熟的AI算法,比如YOLO-V3,就是大量的卷積、殘差網(wǎng)絡(luò)、全連接等類型的計(jì)算,本質(zhì)是乘法和加法。對于YOLO-V3來說,如果確定了具體的輸入圖形尺寸,那么總的乘法加法計(jì)算次數(shù)是確定的。比如一萬億次。(真實(shí)的情況比這個(gè)大得多的多)
那么要快速執(zhí)行一次YOLO-V3,就必須執(zhí)行完一萬億次的加法乘法次數(shù)。
這個(gè)時(shí)候就來看了,比如IBM的POWER8,最先進(jìn)的服務(wù)器用超標(biāo)量CPU之一,4GHz,SIMD,128bit,假設(shè)是處理16bit的數(shù)據(jù),那就是8個(gè)數(shù),那么一個(gè)周期,最多執(zhí)行8個(gè)乘加計(jì)算。一次最多執(zhí)行16個(gè)操作。這還是理論上,其實(shí)是不大可能的。
那么CPU一秒鐘的巔峰計(jì)算次數(shù)=16X4Gops=64Gops。
這樣,可以算算CPU計(jì)算一次的時(shí)間了。
同樣的,換成GPU算算,也能知道執(zhí)行時(shí)間。因?yàn)閷PU內(nèi)部結(jié)構(gòu)不熟,所以不做具體分析。
再來說說AI芯片。比如大名鼎鼎的谷歌的TPU1.
TPU1,大約700M Hz,有256X256尺寸的脈動(dòng)陣列,如下圖所示。一共256X256=64K個(gè)乘加單元,每個(gè)單元一次可執(zhí)行一個(gè)乘法和一個(gè)加法。那就是128K個(gè)操作。(乘法算一個(gè),加法再算一個(gè))
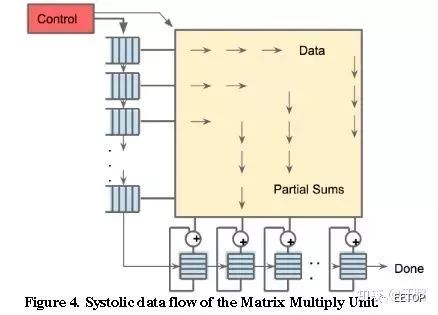
另外,除了脈動(dòng)陣列,還有其他模塊,比如激活等,這些里面也有乘法、加法等。
所以,看看TPU1一秒鐘的巔峰計(jì)算次數(shù)至少是=128K X 700MHz=89600Gops=大約90Tops。
對比一下CPU與TPU1,會(huì)發(fā)現(xiàn)計(jì)算能力有幾個(gè)數(shù)量級的差距,這就是為啥說CPU慢。
當(dāng)然,以上的數(shù)據(jù)都是完全最理想的理論值,實(shí)際情況,能夠達(dá)到5%吧。因?yàn)椋酒系拇鎯?chǔ)不夠大,所以數(shù)據(jù)會(huì)存儲(chǔ)在DRAM中,從DRAM取數(shù)據(jù)很慢的,所以,乘法邏輯往往要等待。另外,AI算法有許多層網(wǎng)絡(luò)組成,必須一層一層的算,所以,在切換層的時(shí)候,乘法邏輯又是休息的,所以,諸多因素造成了實(shí)際的芯片并不能達(dá)到利潤的計(jì)算峰值,而且差距還極大。
可能有人要說,搞研究慢一點(diǎn)也能將就用。
目前來看,神經(jīng)網(wǎng)絡(luò)的尺寸是越來越大,參數(shù)越來越多,遇到大型NN模型,訓(xùn)練需要花幾周甚至一兩個(gè)月的時(shí)候,你會(huì)耐心等待么?突然斷電,一切重來?(曾經(jīng)動(dòng)手訓(xùn)練一個(gè)寫小說的AI,然后,一次訓(xùn)練(50輪)需要大約一天一夜還多,記得如果第一天早上開始訓(xùn)練,需要到第二天下午才可能完成,這還是模型比較簡單,數(shù)據(jù)只有幾萬條的小模型呀。)
修改了模型,需要幾個(gè)星期才能知道對錯(cuò),確定等得起?
突然有了TPU,然后你發(fā)現(xiàn),吃個(gè)午飯回來就好了,參數(shù)優(yōu)化一下,繼續(xù)跑,多么爽!
計(jì)算速度快,才能迅速反復(fù)迭代,研發(fā)出更強(qiáng)的AI模型。速度就是金錢。
GPU的內(nèi)核結(jié)構(gòu)不清楚,所以就不比較了。肯定的是,GPU還是比較快的,至少比CPU快得多,所以目前大多數(shù)都用GPU,這玩意隨便一個(gè)都能價(jià)格輕松上萬,太貴,而且,功耗高,經(jīng)常缺貨。不適合數(shù)據(jù)中心大量使用。
總的來說,CPU與GPU并不是AI專用芯片,為了實(shí)現(xiàn)其他功能,內(nèi)部有大量其他邏輯,而這些邏輯對于目前的AI算法來說是完全用不上的,所以,自然造成CPU與GPU并不能達(dá)到最優(yōu)的性價(jià)比。
谷歌花錢研發(fā)TPU,而且目前已經(jīng)出了TPU3,用得還挺歡,都開始支持谷歌云計(jì)算服務(wù)了,貌似6點(diǎn)幾美元每小時(shí)吧,不記得單位了,懶得查.
可見,谷歌覺得很有必要自己研發(fā)TPU。
目前在圖像識(shí)別、語音識(shí)別、自然語言處理等領(lǐng)域,精度最高的算法就是基于深度學(xué)習(xí)的,傳統(tǒng)的機(jī)器學(xué)習(xí)的計(jì)算精度已經(jīng)被超越,目前應(yīng)用最廣的算法,估計(jì)非深度學(xué)習(xí)莫屬,而且,傳統(tǒng)機(jī)器學(xué)習(xí)的計(jì)算量與 深度學(xué)習(xí)比起來少很多,所以,我討論AI芯片時(shí)就針對計(jì)算量特別大的深度學(xué)習(xí)而言。畢竟,計(jì)算量小的算法,說實(shí)話,CPU已經(jīng)很快了。而且,CPU適合執(zhí)行調(diào)度復(fù)雜的算法,這一點(diǎn)是GPU與AI芯片都做不到的,所以他們?nèi)咧皇轻槍Σ煌膽?yīng)用場景而已,都有各自的主場。
至于為何用了CPU做對比?
而沒有具體說GPU。是因?yàn)椋艺f了,我目前沒有系統(tǒng)查看過GPU的論文,不了解GPU的情況,故不做分析。因?yàn)榉e累的緣故,比較熟悉超標(biāo)量CPU,所以就用熟悉的CPU做詳細(xì)比較。而且,小型的網(wǎng)絡(luò),完全可以用CPU去訓(xùn)練,沒啥大問題,最多慢一點(diǎn)。只要不是太大的網(wǎng)絡(luò)模型。
那些AI算法公司,比如曠世、商湯等,他們的模型很大,自然也不是一塊GPU就能搞定的。GPU的算力也是很有限的。
至于說CPU是串行,GPU是并行
沒錯(cuò),但是不全面。只說說CPU串行。這位網(wǎng)友估計(jì)對CPU沒有非常深入的理解。我的回答中舉的CPU是IBM的POWER8,百度一下就知道,這是超標(biāo)量的服務(wù)器用CPU,目前來看,性能已經(jīng)是非常頂級的了,主頻4GHZ。不知是否注意到我說了這是SIMD?這個(gè)SIMD,就代表他可以同時(shí)執(zhí)行多條同樣的指令,這就是并行,而不是串行。單個(gè)數(shù)據(jù)是128bit的,如果是16bit的精度,那么一周期理論上最多可以計(jì)算八組數(shù)據(jù)的乘法或加法,或者乘加。這還不叫并行?只是并行的程度沒有GPU那么厲害而已,但是,這也是并行。
不知道為啥就不能用CPU來比較算力?
有評論很推崇GPU。說用CPU來做比較,不合適。
拜托,GPU本來是從CPU中分離出來專門處理圖像計(jì)算的,也就是說,GPU是專門處理圖像計(jì)算的。包括各種特效的顯示。這也是GPU的天生的缺陷,GPU更加針對圖像的渲染等計(jì)算算法。但是,這些算法,與深度學(xué)習(xí)的算法還是有比較大的區(qū)別,而我的回答里提到的AI芯片,比如TPU,這個(gè)是專門針對CNN等典型深度學(xué)習(xí)算法而開發(fā)的。另外,寒武紀(jì)的NPU,也是專門針對神經(jīng)網(wǎng)絡(luò)的,與TPU類似。
谷歌的TPU,寒武紀(jì)的DianNao,這些AI芯片剛出道的時(shí)候,就是用CPU/GPU來對比的。
看看,谷歌TPU論文的摘要直接對比了TPU1與CPU/GPU的性能比較結(jié)果,見紅色框:
這就是摘要中介紹的TPU1與CPU/GPU的性能對比。
再來看看寒武紀(jì)DianNao的paper,摘要中直接就是DianNao與CPU的性能的比較,見紅色框:
回顧一下歷史
上個(gè)世紀(jì)出現(xiàn)神經(jīng)網(wǎng)絡(luò)的時(shí)候,那一定是用CPU計(jì)算的。
比特幣剛出來,那也是用CPU在挖。目前已經(jīng)進(jìn)化成ASIC礦機(jī)了。比特大陸了解一下。
從2006年開始開啟的深度學(xué)習(xí)熱潮,CPU與GPU都能計(jì)算,發(fā)現(xiàn)GPU速度更快,但是貴啊,更多用的是CPU,而且,那時(shí)候GPU的CUDA可還不怎么樣,后來,隨著NN模型越來越大,GPU的優(yōu)勢越來越明顯,CUDA也越來越6,目前就成了GPU的專場。
寒武紀(jì)2014年的DianNao(NPU)比CPU快,而且更加節(jié)能。ASIC的優(yōu)勢很明顯啊。這也是為啥要開發(fā)ASIC的理由。
至于說很多公司的方案是可編程的,也就是大多數(shù)與FPGA配合。你說的是商湯、深鑒么?的確,他們發(fā)表的論文,就是基于FPGA的。
這些創(chuàng)業(yè)公司,他們更多研究的是算法,至于芯片,還不是重點(diǎn),另外,他們暫時(shí)還沒有那個(gè)精力與實(shí)力。FPGA非常靈活,成本不高,可以很快實(shí)現(xiàn)架構(gòu)設(shè)計(jì)原型,所以他們自然會(huì)選擇基于FPGA的方案。不過,最近他們都大力融資,官網(wǎng)也在招聘芯片設(shè)計(jì)崗位,所以,應(yīng)該也在涉足ASIC研發(fā)了。
如果以FPGA為代表的可編程方案真的有巨大的商業(yè)價(jià)值,那他們何必砸錢去做ASIC?
說了這么多,我也是半路出家的,因?yàn)楣ぷ餍枰鴮W(xué)習(xí)的。按照我目前的理解,看TPU1的專利及論文,一步一步推導(dǎo)出內(nèi)部的設(shè)計(jì)方法,理解了TPU1,大概就知道了所謂的AI處理器的大部分。然后研究研究寒武紀(jì)的一系列論文,有好幾種不同的架構(gòu)用于不同的情況,有興趣可以研究一下。然后就是另外幾個(gè)獨(dú)角獸,比如商湯、深鑒科技等,他們每年都會(huì)有論文發(fā)表,沒事去看看。這些論文,大概就代表了當(dāng)前最先進(jìn)的AI芯片的架構(gòu)設(shè)計(jì)了。當(dāng)然,最先進(jìn),別人肯定不會(huì)公開,比如谷歌就不曾公開關(guān)于TPU2和TPU3的相關(guān)專利,反正我沒查到。不過,沒事,目前的文獻(xiàn)已經(jīng)代表了最近幾年最先進(jìn)的進(jìn)展了。
作者:Bluebear
鏈接:https://www.zhihu.com/question/285202403/answer/444457305
現(xiàn)在所說的AI芯片,可以分兩類,一類是面向訓(xùn)練和推斷(Inference)皆可的,這個(gè)活GPGPU可以干,CPU也可以干,F(xiàn)PGA(Altera的Stratix系列)也都行,但是Google的TPU2和Bitmain的sophon之類因?yàn)閷iT設(shè)計(jì)可能在能耗比上有優(yōu)勢。這類產(chǎn)品相對GPGPU,整體類似,保留了相當(dāng)多的浮點(diǎn)處理單元的同時(shí)(或者說建立了很多張量計(jì)算單元),拋棄了一些沒啥用的圖形流水線的玩意,提高了能耗表現(xiàn)。這部分玩家少,但是卻更有趣。當(dāng)然ICLR也有琢磨用定點(diǎn)器件訓(xùn)練的工作,Xilinx家是希望XNOR-net讓定點(diǎn)器件都能參與訓(xùn)練。
另一類是Inference Accelerator推斷加速芯片,簡單說就是把訓(xùn)練好的模型在芯片上跑。這塊是真的百花齊放,比如的寒武紀(jì)NPU,Intel Movidius(還有個(gè)Nervana應(yīng)該類似XeonPhi用來訓(xùn)練的),深鑒的DPU,地平線BPU,Imagination的PowerVR 2NX,ARM的Project Trillium,還有一堆IP。這類產(chǎn)品既有產(chǎn)品,又提供IP讓其他開發(fā)者講深度學(xué)習(xí)加速器集成到SoC內(nèi)。另外這里需要單獨(dú)說下Tegra X2這個(gè)產(chǎn)品,這個(gè)相當(dāng)于一個(gè)小的桌面平臺(tái),ARM處理器加Nvidia GPU可以提供完整的訓(xùn)練推斷能力,當(dāng)然功耗也很高。其他的加速芯片,我覺得最好分成兩類,浮點(diǎn)的和定點(diǎn)的。浮點(diǎn)的也只是FP16半精度的,當(dāng)然支持FP16也支持INT8,比如寒武紀(jì)的NPU和Intel Movidius。一類就是純定點(diǎn)的比如地平線的BPU還有Imagination的PowerVR 2NX之類。當(dāng)然也有混合的,這塊后面細(xì)說。
首先說下非ASIC的,Deephi部分產(chǎn)品使用了ZYNQ實(shí)現(xiàn),使用ZYNQ最大的好處就是省了流片費(fèi)用,使用DSP48和資源實(shí)現(xiàn)乘加器完成定點(diǎn)操作,浮點(diǎn)交給CortexA9硬核,Deephi主要是工作在模型剪枝定點(diǎn)化方面,之前和汪玉老師交流,網(wǎng)絡(luò)定點(diǎn)化時(shí)候部分層定點(diǎn)化定點(diǎn)化損失較高,因此保留部分層(主要是最后的)浮點(diǎn),和嘉楠智耘做加速的人聊也印證這部分,用SOPC比較省事。再就是兼職的比如高通AI平臺(tái)使用了Adreno GPU和Hexagon DSP做(主要是DSP,風(fēng)評貌似能耗比970那個(gè)好看),SNPE主要是OpenCL折騰用GPU和DSP之類資源推斷,MTK和AAPL也類似。其他的差別就很大了Intel Movidius發(fā)布較早,支持浮點(diǎn)推斷,實(shí)際里面是VLIW的SIMD單元,這玩意和之前ATi顯卡,或者說DSP設(shè)計(jì)類似。其他的因?yàn)樵谙驴吹焦_資料不多,瞎說說,一般AI加速器都主要是針對現(xiàn)有網(wǎng)絡(luò),做定點(diǎn)或者浮點(diǎn)計(jì)算的優(yōu)化,當(dāng)然首先還是堆運(yùn)算單元(矩陣運(yùn)算單元,乘加),然后減少內(nèi)存數(shù)據(jù)搬運(yùn),970上那個(gè)可能掛在CCI上,然后靠較多緩存,PowerVR 2NX那個(gè)貌似是優(yōu)化到4bit的內(nèi)存控制器?通過優(yōu)化內(nèi)存數(shù)據(jù)通路,減少一些內(nèi)存帶寬需求之列,總體其實(shí)還是關(guān)聯(lián)的。感覺上這類東西接近超多核的DSP,不過是精簡的畢竟DSP還能做點(diǎn)控制,笑。
另外某種程度上說,對新的網(wǎng)絡(luò)優(yōu)化很差,一般工業(yè)比學(xué)術(shù)慢一年多,比如DenseNet出來了,片子只支持到Resnet。
關(guān)于下面兩個(gè)問題:
如果讓GPGPU或者CPU做inference能耗比肯定不好看,但是浮點(diǎn)inference一般比定點(diǎn)化或者精度降低后的情況準(zhǔn)確率高(當(dāng)然存在定點(diǎn)化后泛化能力好的情況)。但是NPU只能在CPU控制下做特定任務(wù)就很丟人了,沒有很多的應(yīng)用支持,NPU就很雞肋,在手機(jī)上,很多時(shí)候你根本用不到NPU,所以我覺得需要的時(shí)候用Mali啥的頂頂?shù)昧恕?/p>
沒有啥差別,和別的比如手機(jī)SoC,顯卡GPU用一套工藝,有錢上新制程,新工藝咯。
人工智能究竟能給我們的生活帶來什么?以我們最熟悉的手機(jī)為例,日常的拍照美顏已經(jīng)稀松平常,但目前的自拍軟件在拍攝完成后,需要上傳到云端,通過通用模型來完成“一鍵美顏”。而移動(dòng)端的 AI 芯片則可根據(jù)用戶平時(shí)的喜好,在照片拍攝完成后(甚至拍攝之前的取景階段)就同步完成照片美化,這對于現(xiàn)有的CPU來說是難以完成的。
那么二者的差別在哪里呢?首先,傳統(tǒng)芯片在運(yùn)算時(shí)只需要根據(jù)指令來調(diào)用相應(yīng)系統(tǒng)進(jìn)行工作,而 AI 指令之下則包含大量并行計(jì)算與建模。這無疑對處理器的計(jì)算能力提出了很高要求。
其次是移動(dòng)端的數(shù)據(jù)收集能力,尤其是手機(jī)。優(yōu)秀的 AI 應(yīng)用要收集大量的數(shù)據(jù)來對模型進(jìn)行訓(xùn)練,而手機(jī)無疑是最好的數(shù)據(jù)收集工具。隨著諸如麥克風(fēng)、攝像頭、重力感應(yīng)器、定位裝置等越來越多的傳感器加入手機(jī)中,一種能實(shí)時(shí)收集、同步處理、連接協(xié)調(diào)不同傳感器的“人工智能”芯片就顯得尤為重要。
當(dāng)然,一片在指甲蓋大小的面積上集成了超過 55 億個(gè)晶體管的 AI 芯片不可能只用來拍拍照這么簡單。目前手機(jī)上已經(jīng)有語音服務(wù)、機(jī)器視覺識(shí)別、圖像處理等智能應(yīng)用,未來還會(huì)增加包含醫(yī)療、AR、游戲 AI 等更多元化的應(yīng)用類型。
除了滿足手機(jī)上的應(yīng)用,未來AI芯片也將有機(jī)會(huì)拓展其他更有潛力的市場,最典型的例子的例子就是自動(dòng)駕駛,特斯拉就在去年挖來了AMD的傳奇架構(gòu)師 Jim Keller開發(fā)自主的AI芯片。甚至在未來,上至火箭航天器、下至深海探測器,其上的控制系統(tǒng)所仰賴的芯片都將會(huì)越來越AI化。
-
cpu
+關(guān)注
關(guān)注
68文章
11028瀏覽量
215709 -
gpu
+關(guān)注
關(guān)注
28文章
4903瀏覽量
130570 -
AI芯片
+關(guān)注
關(guān)注
17文章
1965瀏覽量
35664
原文標(biāo)題:AI 芯片和傳統(tǒng)芯片有何區(qū)別?
文章出處:【微信號:iotmag,微信公眾號:iotmag】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

手把手教你設(shè)計(jì)人工智能芯片及系統(tǒng)--(全階設(shè)計(jì)教程+AI芯片FPGA實(shí)現(xiàn)+開發(fā)板)
AI發(fā)展對芯片技術(shù)有什么影響?
AI芯片熱潮和架構(gòu)創(chuàng)新有什么作用
arm架構(gòu)的芯片有哪些
AI芯片什么是AI芯片的架構(gòu)、分類及關(guān)鍵技術(shù)概述
AI芯片和傳統(tǒng)芯片到底有什么區(qū)別
為何AI需要新的芯片架構(gòu)?
ai芯片技術(shù)架構(gòu)有哪些?FPGA芯片定義及結(jié)構(gòu)分析
ai芯片和傳統(tǒng)芯片的區(qū)別
ai芯片技術(shù)架構(gòu)有哪些
AI芯片有哪些特點(diǎn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論