 電子發(fā)燒友App
電子發(fā)燒友App


確保將最高質量的產品運往市場,并保證它們在其生命周期內持續(xù)工作,是汽車芯片制造商的首要目標。的確,我們需要大力改進和加強制造測試程序,以使整個芯片種群中的潛在故障少之又少。然而,高質量的生產必須遵循現(xiàn)場可靠性;制定戰(zhàn)略和活動來面對前方生命周期的關鍵問題也具有非常高的優(yōu)先地位。
本文的貢獻包括以下幾個方面的描述和結果:(1)一種非常精確的方法來評估FLASH制造測試的功耗;(2)一種有效的多核基于軟件的自檢生成策略,面向人工智能的計算機體系結構;(3)一個高水平和非常快速的系統(tǒng)級芯片的架構仿真器,用于原型設計輻照實驗和預測運動結果,對處理器和外圍核心的單一事件設置具有良好的準確等級。
I.簡介
詳細介紹了重新調整制造測試流程的最佳做法,通過考慮克服結構測試在線限制的測試技術來達到標準預期,并節(jié)省時間和計算資源來評估利用所有系統(tǒng)級芯片(SoC)功能的汽車應用的穩(wěn)健性,包括CPU和外圍核心。
第二節(jié)介紹了如何對嵌入式FLASH存儲器的制造測試進行非常準確的功率表征。正如后面所詳述的那樣,該技術的目標是測量一個復合DfT模式的電流吸收,該模式可以通過調整固件來滿足不同的期望。為了在測試執(zhí)行過程中設置正確的測試電壓裕度,并允許詳細說明與FLASH測試并行進行的其他測試,澄清該評估是至關重要的。In?neon科技公司報告了有關嵌入式FLASH存儲器測試的數據,顯示了各種測試固件版本的功耗趨勢。
第三節(jié)說明了如何為一個包括幾個計算核心的面向人工智能的設備創(chuàng)建一個基于軟件的自我測試套件。網表的大小和復雜性是這個方向的主要關注點;可能的自動化和巧妙的分級程序是本節(jié)討論的關鍵點。Dolphin設計公司對其汽車AI芯片所報告的結果表明,基于軟件的自我測試策略是可擴展的,并適用于大型多處理器設備的適當在線測試策略。然而,產生的功能測試程序可用于補充制造測試期間的結構方法,即查看系統(tǒng)級測試覆蓋率。
第四節(jié)完成了本文所描述的方法和策略的概述。在這一部分,重點是瞬態(tài)故障的影響,并提出了一種方法來估計可能影響整個系統(tǒng)級芯片(SoC)的單一事件顛覆的影響。所描述的解決方案是基于一個仿真引擎,能夠快速重現(xiàn)包括處理器和外設核心在內的SoC的行為;在特殊情況下,Xilinx Zynq UltraScale+ MPSoC是通過使用QEMU平臺進行仿真的,QEMU平臺是以這樣一種方式進行檢測的,它可以在應用程序的執(zhí)行過程中注入瞬時故障效應。通過使用這樣的環(huán)境,有可能獲得快速、略微不準確的關于瞬態(tài)故障對功能的影響的的估計。因此,這種方法可以對輻照實驗中觀察到的故障水平進行原始但非常便宜的預測。
第五節(jié)得出了一些結論,并強調了汽車主題的合理看法。
II.嵌入式FLASH的功率表征測試
每個內存測試的特點是有一定的電流消耗水平。通常,這種水平在測試執(zhí)行過程中不是恒定的,而且在許多情況下,峰值可能會出現(xiàn)在平均水平上。了解產生這些峰值的原因是很重要的,即識別相關的IR-droop問題可能會減少矯枉過正,并使更多的測試并行化,可能允許在同一時間測試不同的芯片部件,以減少測試時間。
在這些段落中,我們專注于FLASH存儲器測試,特別是尋找有關所謂的 "驗證測試 "技術的功率信息,該技術旨在測試存儲在片上系統(tǒng)(SoC)中的FLASH存儲器陣列。對測試步驟中的功耗水平進行認真的調查,也可以對測試條件的余量達到更高的置信度,這也是達到大批量制造質量的一個不可缺少的因素。 隨著測試場景變得復雜,超出功率限制的風險也會相應增加。
如今,集成在SoC中的嵌入式可測試性設計(DFT)功能可能是非常復合的,因此功率表征可能會被所有這些組件污染。為了更好地了解每個角色者在所考慮的測試場景中的貢獻,調試設置變得非常重要。在接下來的段落中,我們將描述如何收集英飛凌Aurix系統(tǒng)在多種條件下運行時的重要功率測量數據。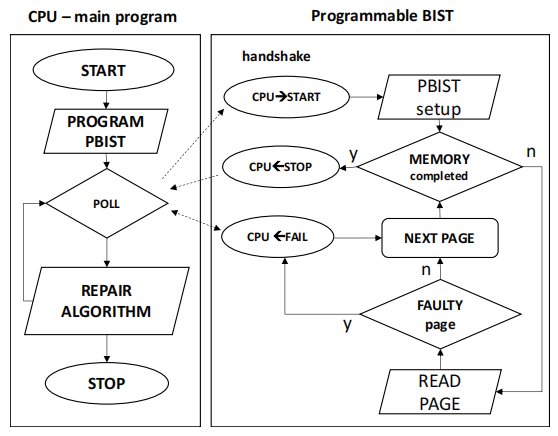
圖1?總體環(huán)境和工作原則
如圖1所示,Aurix FLASH存儲器測試涉及許多電路。高速和背對背的訪問是由一個可編程的內置自檢(可編程BIST)授予的,它由一個Tricore處理器核心控制。PBIST功能允許在不同條件下進行驗證測試,如內部電壓和頻率參數。 在我們的工作中,主要調查了CPU組件行為的影響,因為它在純PBIST功率特性方面引入了一個額外的電流消耗因素。
為了識別功率峰值并確定其最大振幅,我們評估了幾個CPU固件版本。圖2總結了一組測量的構架: 1) 未經優(yōu)化的CPU固件版本,該版本 a) 不斷地輪詢PBIST以獲取故障信息 b) 包括調試功能,如跟蹤特殊用途寄存器的讀寫操作 c) 實施高水平的嵌套功能,以達到重復使用的目的。 2) 減少對PBIST的輪詢頻率 3) 利用在輪詢事件之間進入的空閑模式 4) 通過 "簡化 "的代碼(但不太通用)最小化上下文切換事件。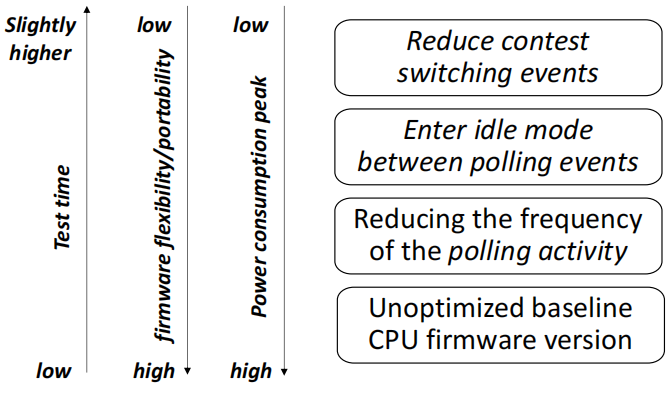
圖2 固件級別探索及其利弊
圖2說明了優(yōu)化級別,并已經報告了一些權衡的結果。隨著我們引入優(yōu)化,功率消耗的峰值往往會減少很多。這是一個主要目標,但它也帶來了一些重要的缺陷。
在每一個優(yōu)化步驟中,我們都觀察到CPU固件的靈活性和可移植性的損失。同樣,閑置空閑能力時。
為了進行目標測量,我們準備了圖3所示的裝置。安裝的基礎是一個開發(fā)板,包括一個用于承載芯片樣本的螺絲插座。這樣的板然后連接到幾個控制和測量工具。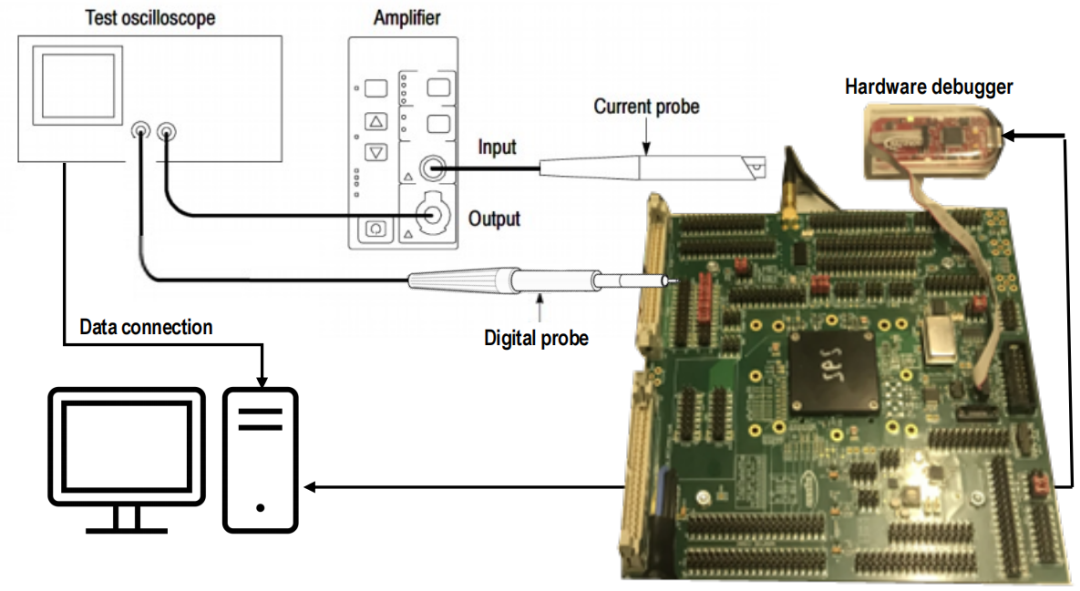
圖3 實驗裝置
一個硬件調試器被連接到電路板上,以便主機啟動和控制CPU功能的執(zhí)行。 然后,電路板通過兩種類型的探頭連接到示波器上。電流探頭用于測量測試執(zhí)行過程中的電流變化:這種探針 "窺探 "了沿測試執(zhí)行過程中給磁芯供電的電源線。此外,一個數字探針被用來捕捉數字引腳的值。這種操作對于確定正確的時間來觀察測試流程中的功耗變化非常重要。
在以下圖表中,我們報告了與FLASH存儲器兩個連續(xù)扇區(qū)的測試有關的測量。數字探頭用于識別輪詢間隔,用黃色報告,而用電流探頭測量的功耗趨勢用藍色報告。 圖4顯示了基線CPU固件的應用。我們用百分比來做一個公平的比較,在這種情況下,功率峰值振幅和測試時間是100%。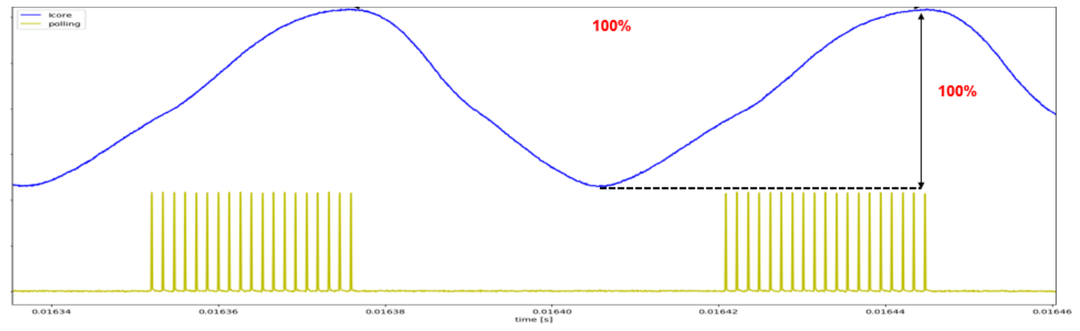
圖4 CPU應用程序的基線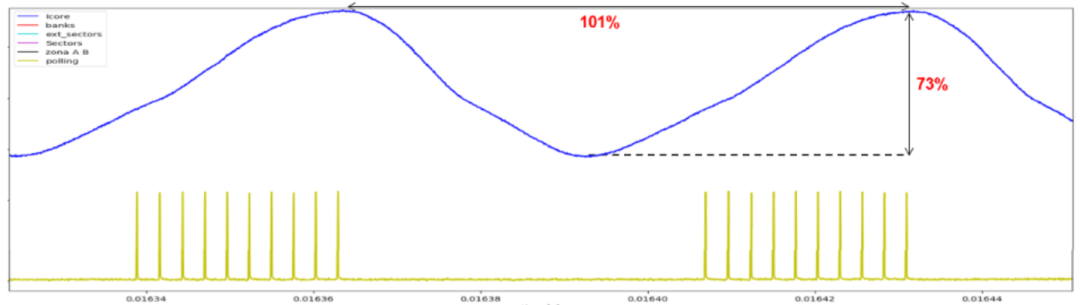
圖5?減少輪詢活動頻率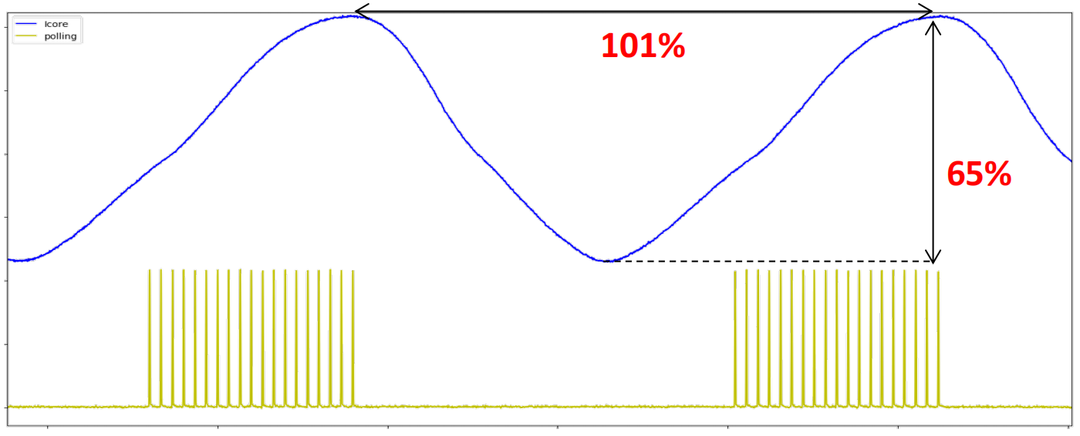
圖6 空閑模式激活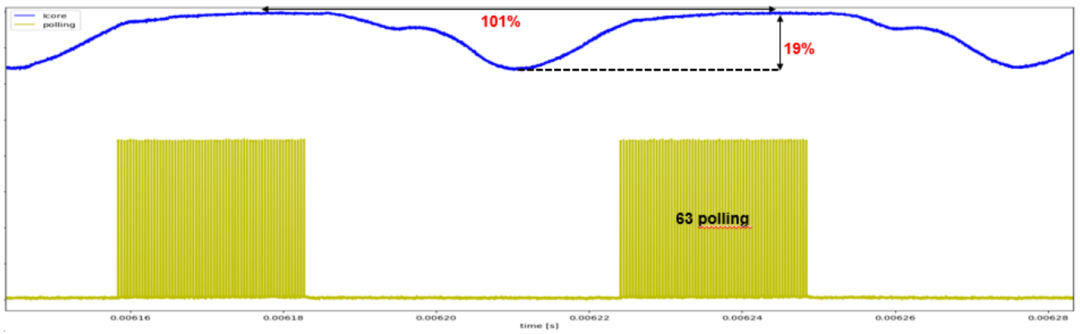
圖7 減少了上下文切換事件
總的來說,我們觀察到,有幾種方法可以用來減少功率峰值的振幅,這對于安全地規(guī)劃其他測試與FLASH內存測試程序的并行化至關重要。以靈活性和可移植性為代價,減少CPU的 "無用 "活動(例如,通過減少代碼中對函數的嵌套調用數量來最小化上下文切換)看起來是最有效的方法,它對測試時間沒有影響。
另外,基于空轉的方法可以節(jié)省較少但顯著的電流輸入,并且對測試時間影響有限。
III.基于軟件的自測試開發(fā)和AI芯片的分級
汽車的功能安全標準,如ISO26262,要求使用硬件和軟件技術對潛在的故障進行現(xiàn)場測試。基于軟件自檢(SBST)的軟件測試庫(STL)是一種靈活的潛伏故障測試解決方案,可替代基于可測試性設計(DfT)特征的硬件方法。STL可以被集成到任務操作系統(tǒng)中,并在空閑時間定期執(zhí)行。
然而,在為基于多核處理器的人工智能芯片開發(fā)STL時,徹底優(yōu)化故障分級過程和用適當的軟件模塊管理STL的執(zhí)行是至關重要的。 在下面的小節(jié)中,描述了經典案例,STL的開發(fā)策略,以及如何將它們集成到系統(tǒng)中。最后,展示了故障仿真結果。
A.經典案例
該經典案例是由Dolphin Design公司開發(fā)的一個多核人工智能芯片,用于加速神經網絡所需的操作(見圖1)。該模塊包括一個由16個PULP-NN RISC-V核(Core0 - Core15)組成的集群,有128kB的L1內存。
指令是在一個與集群外的二級存儲器通信的指令緩存內獲取的。外部總線提供了與內部L1的通信,并可由核心0或通過DMA訪問。內部總線負責連接所有的內部模塊,為并發(fā)的訪問提供調解。事件單元提供硬件事件來協(xié)調集群內部的操作。最后,一個共享浮點單元(FPU)包含8個計算核心,用于浮點之間的“經典”操作,以及一個用于DIV和SQRT的計算核心。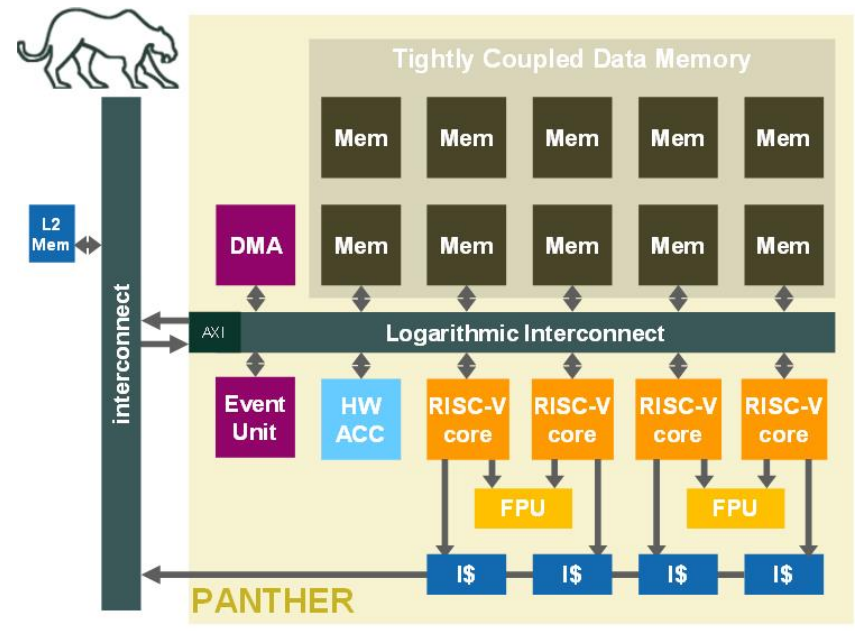
圖8 多核AI設計框圖的案例研究
軟件開發(fā)工具包(SDK)可用于配置和編程SoC。使用SDK,用戶可以決定如何安排測試和組織測試程序作為操作系統(tǒng)(OS)的任務。 B.STL 開發(fā) 整體的STL開發(fā)被分割成幾個測生成,使用較小的故障列表。一些模塊(如CPU核,或FPU共享子單元)被多次復制,可以通過專注于一個模塊,然后通過在其他模塊上做測試程序的移植來解決。
關注每個子模塊可以減少執(zhí)行故障模擬和評估目標模塊測試程序質量所需的時間。對于特定部件,為其他模塊開發(fā)的測試產生的副作用是不可忽略的(例如,在互連的仲裁和多路復用邏輯上); 通過在目標模塊上模擬這些測試程序,可以精簡故障列表,減少生成時間。
測試策略包括在對RTL設計進行仔細分析后,使用偽隨機和ATPG約束方法產生的模式。每個測試程序首先通過考慮所有子模塊的主要輸出(Pos)進行故障模擬,并細化直至達到目標故障覆蓋率;最后對程序進行重新模擬,掩蓋數據結果傳播過程中所沒有的所有POs;測試程序將測試結果壓縮為一種形式的簽名,保存在內存位置,并在測試結束時與預期的結果進行比較。
C.STL 集成 軟件測試庫的結構分三個層次,如圖9所示: 1) 最底層包括用C語言和匯編開發(fā)的測試程序,以更好地運行內部模塊。 2) 中間層直接與SDK進行溝通,以協(xié)調和評估整個集群內的測試操作。 3) 最高層與操作系統(tǒng)同時工作,在任務運行期間安排測試階段。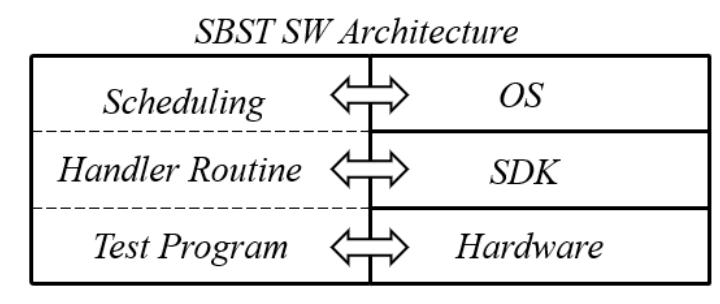
圖9 STL架構
為了保證穩(wěn)健性,軟件必須考慮到所有可能的故障,這些故障的存在會導致系統(tǒng)死鎖: ●? 當測試操作啟動時,軟件會使用內核軟件提供的適當程序來處理上下文切換。 ● 由于在失敗的情況下會出現(xiàn)異常,所以必須修改相對處理程序,以便與影響測試結果的測試軟件溝通。 ●? 最后,在開始測試階段之前,必須初始化一個看門狗定時器,以便在發(fā)生不可預見的事件時強制停止測試。 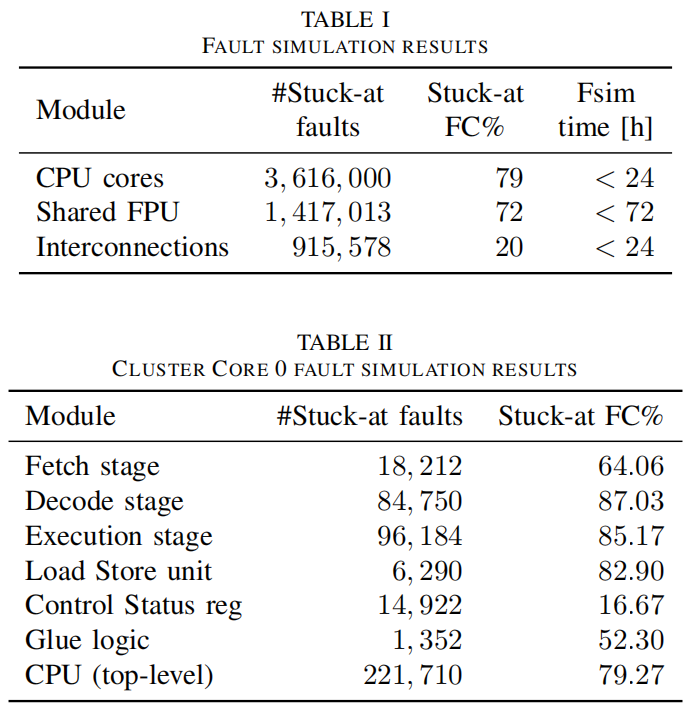
測試程序的并行執(zhí)行是通過在L1內存中保留一個專用空間來實現(xiàn)的,其中包含有關測試程序狀態(tài)的參數結構。通過訪問這些內存區(qū)域,可以利用內核功能在內部集群核心和外部之間進行同步操作。 D.故障模擬結果 實驗是在Xeon Gold 6126工作站的4個核心上使用商用順序故障模擬器進行的,該工作站配備128GB RAM。
在對每個集群的子模塊進行故障仿真后,通過邏輯仿真驗證了STL的功能;為了加快這一過程,使用RTL描述對外部芯片進行仿真,同時為集群保留門級。 表一報告了16個CPU核、FPU和互連的故障模擬結果。對于每個模塊,我們報告了卡住故障的數量、故障覆蓋率和故障模擬時間。
該表顯示,所有內核區(qū)域的故障覆蓋率都很好,共享FPU的故障覆蓋率為離散值。我們通過運行為其他區(qū)塊編寫的測試程序來計算互連上的FC。 表二中報告了一個CPU核心(Core 0)的子模塊的細節(jié)。其他CPU核顯示了類似的結果,盡管故障列表有輕微的差異。
整個STL在16個CPU核心上同步運行的測試應用間在100MHz下約為8ms,大小約為20KB,這驗證了在實時系統(tǒng)的現(xiàn)場測試中采用這種測試技術的可能性。
IV.用于汽車應用可靠性評估的高級故障注入
在接下來的段落中,描述了一種基于高級軟件仿真和QEMU仿真引擎,快速評估復雜SoC上單次事件顛覆(SEU)影響的方法。這一策略被用來對運行在Xilinx Ultrascale+ MPSoC上的幾個應用進行分級。SEU是由電離粒子擊中SoC中的敏感點(如CPU寄存器、外設寄存器或互連)而引起的位缺陷。根據執(zhí)行的程序和涉及的外圍模塊,這些位缺陷可能會對系統(tǒng)造成影響。
評估SEU對運行在特定設備上的應用的影響通常是一項非常困難的任務。輻照測試,即設備在離子流下運行,是最精確的測量,但也非常昂貴。此外,在離子流下的實驗失敗可能會導致沉重的額外費用。無論如何,測試和可靠性工程師需要提前驗證他們的實驗流程,以證明準備的設置是有效的,不會導致收集無用的數據。
在這方面,基于仿真的方法近年來被廣泛使用;在這種情況下,需要使用網格列表,而實驗在CPU時間和內存方面要求極高,往往導致不可行。因此,進一步減輕這些初步評估成本正成為一個首要目標。我們建議采用一種替代性的模擬方法,以軟件仿真為代表。軟件仿真器,如QEMU引擎,運行的不是電路的一對一模型,而是程序員對設備的模型行為的精確模型,并非常迅速地再現(xiàn)系統(tǒng)的功能。
當使用仿真器時,程序員仍然可以看到用戶手冊中描述的所有寄存器,這些值與真實電路的行為是一致的。 這是提出的方法的出發(fā)點。我們對Xilinx Ultrascale+ MPSoC的QEMU版本進行了檢測,在CPU和外圍模塊的寄存器中注入SEU。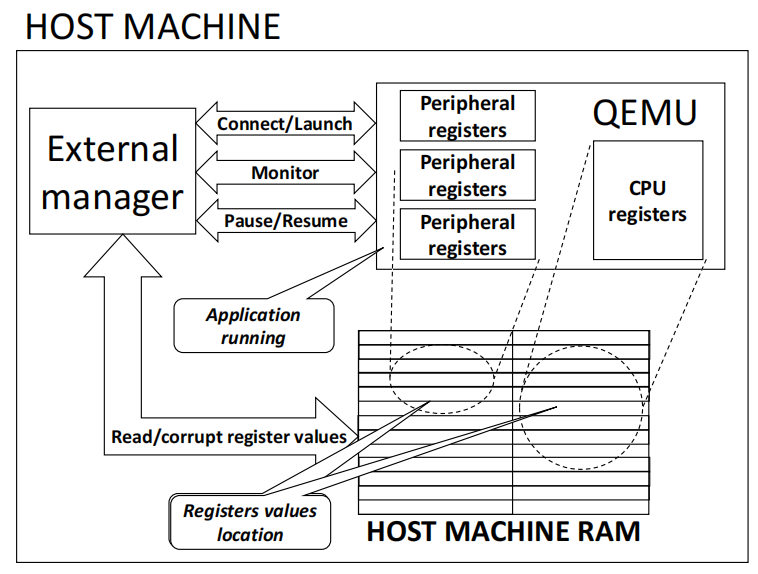
圖10 總體環(huán)境和工作原理
圖10說明了該方法的總體情況。我們開發(fā)了一個外部管理器,它連接到QEMU進程,以啟動應用程序的并監(jiān)測其行為。外部管理器還負責處理SEU的注入,方法是暫停應用程序,破壞其中一個可用的資源(通過作用于主機RAM內存內容),并恢復正在運行的程序的執(zhí)行,以觀察故障效應是否導致故障發(fā)生。 圖11進一步說明了注入流。?
外部管理器暫停TA的執(zhí)行并注入一個故障。然后,它恢復執(zhí)行并監(jiān)控結果。結果被分成三類:錯誤的回答、沒有效果、和基于程序運行結果的超時。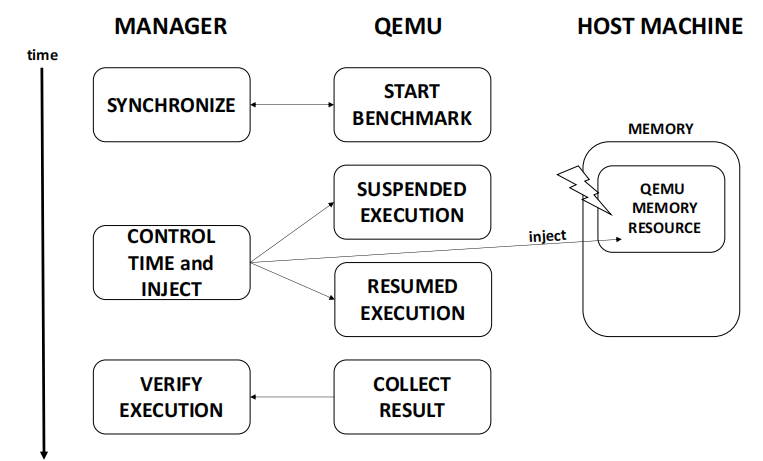
圖11 基于QEMU的注入方法的總體視圖
重要的是要注意,故障注入不僅是在CPU寄存器上進行。我們的環(huán)境可以注入映射在設備內存中的外圍寄存器。在下面的實驗結果中,將看到一些破壞其中一個集成DMA的寄存器的例子。我們在一個 Fast ?Fourier ?Transform (FFT)程序上實驗了這個設置,該程序也與它的反FFT程序相連接。我們也用它來驗證關于SoC外圍設備注入的環(huán)境。
圖12展示了應用程序的流程。在一個循環(huán)中,執(zhí)行以下一組操作: 1) 所用的CPU對給定的一系列數值執(zhí)行FFT,產生結果值 2)? 觸發(fā)DMA傳輸,將FFT的結果移動到內存中的一個新位置 3)? 然后通過使用轉移的FFT結果執(zhí)行iFFT 4) 最后將iFFT結果與原始結果進行對比測試。
如果這個最終的檢查結果顯示最終的數值與原來的不同,那么就有一個錯誤的答案。如果程序進入了循環(huán)或陷阱,那么就有一個超時。其他的所有情況下,歸結為無效果。表三 包括在隨機寄存器和隨機時間點中注入10000個SEU的結果,這些結果收集在一個故障列表中。在注入每個SEU后,觀察程序運行的結果。然后重新啟動系統(tǒng),繼續(xù)處理故障列表中的下一個SEU。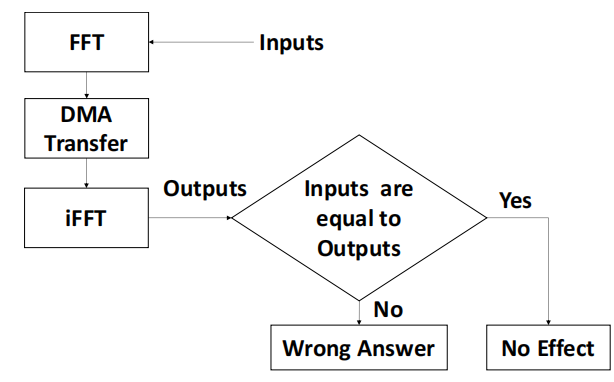
圖12 FFT+iFFT應用
從表中可以看出,注入10,000個故障需要35分鐘左右,主要是因為超時的數量相對較多。此外,我們對一個神經網絡應用的軟件實施了注入故障,該軟件經過訓練,可以識別來自修改后的國家標準和技術研究所(MNIST)數據庫的手寫數字。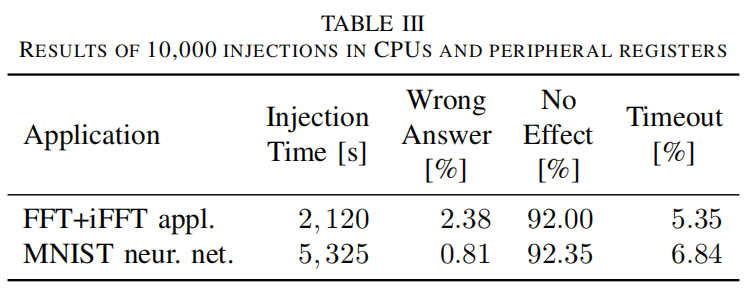
與沒有錯誤的黃金執(zhí)行相比,我們將每個做出不同猜測的執(zhí)行都標記為錯誤答案。從表III中可以看出,神經網絡似乎對SEUs很有彈性,在10,000次隨機注入的CPU寄存器上,只有0.81%的錯誤答案。注入的時間達到89分鐘。這是由于要執(zhí)行的程序的復雜性,以及發(fā)現(xiàn)的超時次數造成的。
作為最終數字的驗證,并了解用QEMU模擬得到的結果是否能代表輻照測試結果,我們將其與[13]中的結果進行了比較,并觀察到有很強的相關性。當然,仿真不能取代輻照活動,但它可以用來描述即將被輻照的應用的特征,或對許多應用進行比較,以預測哪一個是最敏感的。
綜上所述,該方法允許在輻照實驗前快速運行應用程序評估,以預測應用程序本身的敏感性或表征技術,或在部署用戶應用程序之前。
值得注意的是,這種方法不需要芯片的網表,因此既可以被芯片供應商采用,以提前表述其設計,也可以被終端用戶采用,后者可以快速運行其應用程序,并在輻照芯片之前獲得近似的結果進行分析。
V.結論
本文描述了汽車領域的重要參與者所使用的一些方法和技術,以達到不可缺少的可靠性水平要求的最新標準。圖示的典型案例與汽車芯片在其生命周期中所包含的幾個測試階段有關,包括制造結構和功能測試,以及確保在現(xiàn)場使用期間有可靠行為的方法。
作為一個經驗教訓,對最合適的測試程序進行準確的評估和規(guī)劃,可以使高質量的汽車產品符合半導體生產商以及更高層次的期望。
審核編輯:劉清















 工商網監(jiān)
工商網監(jiān)
評論