 電子發(fā)燒友App
電子發(fā)燒友App


近些年來,深度卷積神經(jīng)網(wǎng)絡(luò)(DCNN)在圖像分類和識別上取得了很顯著的提高。回顧從2014到2016這兩年多的時間,先后涌現(xiàn)出了R-CNN,F(xiàn)ast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CNN, SSD等越來越快速和準確的目標檢測方法。
1、基于Region Proposal的方法
該類方法的基本思想是:先得到候選區(qū)域再對候選區(qū)域進行分類和邊框回歸。

1.1 R-CNN [1]
R-CNN是較早地將DCNN用到目標檢測中的方法。其中心思想是對圖像中的各個候選區(qū)域先用DCNN進行特征提取并使用一個SVM進行分類,分類的結(jié)果是一個初略的檢測結(jié)果,之后再次使用DCNN的特征,結(jié)合另一個SVM回歸模型得到更精確的邊界框。
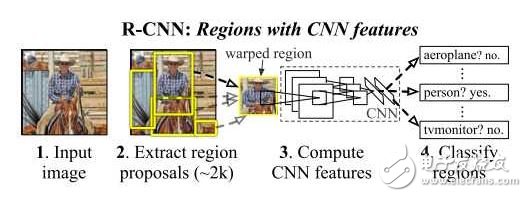
其中獲取候選區(qū)域的方法是常用的selective search。 一個圖形中可以得到大約2000個不同大小、不同類別的候選區(qū)域,他們需要被變換到同一個尺寸以適應(yīng)CNN所處理的圖像大小(227x227)。
該文章中使用的CNN結(jié)構(gòu)來自AlexNet,已經(jīng)在ImageNet數(shù)據(jù)集上的1000個類別的分類任務(wù)中訓(xùn)練過,再通過參數(shù)微調(diào)使該網(wǎng)絡(luò)結(jié)構(gòu)適應(yīng)該文章中的21個類別的分類任務(wù)。
該方法在VOC 2011 test數(shù)據(jù)集上取得了71.8%的檢測精度。該方法的缺點是:1,訓(xùn)練和測試過程分為好幾個階段:得到候選區(qū)域,DCNN 特征提取, SVM分類、SVM邊界框回歸,訓(xùn)練過程非常耗時。2,訓(xùn)練過程中需要保存DCNN得到的特征,很占內(nèi)存空間。3, 測試過程中,每一個候選區(qū)域都要提取一遍特征,而這些區(qū)域有一定重疊度,各個區(qū)域的特征提取獨立計算,效率不高,使測試一幅圖像非常慢。
1.2 Fast R-CNN[2]
在R-CNN的基礎(chǔ)上,為了使訓(xùn)練和測試過程更快,Ross Girshick 提出了Fast R-CNN,使用VGG19網(wǎng)絡(luò)結(jié)構(gòu)比R-CNN在訓(xùn)練和測試時分別快了9倍和213倍。
其主要想法是:
1)對整個圖像進行卷積得到特征圖像而不是對每個候選區(qū)域分別算卷積;
2)把候選區(qū)域分類和邊框擬合的兩個步驟結(jié)合起來而不是分開做。
原理圖如下:
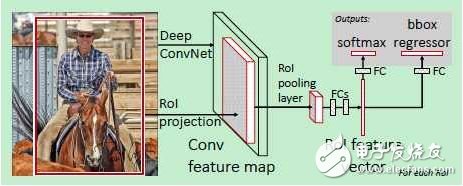

公式中的兩項分別是classification loss 和regression loss。該方法相比于R-CNN快了不少。特別是在測試一幅新圖像時,如果不考慮生成候選區(qū)域的時間,可以達到實時檢測。生成候選區(qū)域的selective search算法處理一張圖像大概需要2s的時間,因此成為該方法的一個瓶頸。
1.3 Faster R-CNN[3]
上面兩種方法都依賴于selective search生成候選區(qū)域,十分耗時,那么可不可以直接利用卷積神經(jīng)網(wǎng)絡(luò)得到候選區(qū)域呢?這樣的話就幾乎可以不花額外的時間代價就能得到候選區(qū)域。
Shaoqing Ren提出了Faster R-CNN來實現(xiàn)這種想法:假設(shè)有兩個卷積神經(jīng)網(wǎng)絡(luò),一個是區(qū)域生成網(wǎng)絡(luò),得到圖像中的各個候選區(qū)域,另一個是候選區(qū)域的分類和邊框回歸網(wǎng)路。這兩個網(wǎng)絡(luò)的前幾層都要計算卷積,如果讓它們在這幾層共享參數(shù),只是在末尾的幾層分別實現(xiàn)各自的特定的目標任務(wù),那么對一幅圖像只需用這幾個共享的卷積層進行一次前向卷積計算,就能同時得到候選區(qū)域和各候選區(qū)域的類別及邊框。
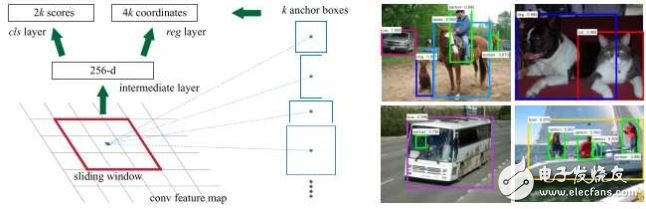
?

使用RPN得到候選區(qū)域后,對候選區(qū)域的分類和邊框回歸仍然使用Fast R-CNN。這兩個網(wǎng)絡(luò)使用共同的卷積層。 由于Fast R-CNN的訓(xùn)練過程中需要使用固定的候選區(qū)域生成方法,不能同時對RPN和Fast R-CNN使用反向傳播算法進行訓(xùn)練。
該文章使用了四個步驟完成訓(xùn)練過程:
1)單獨訓(xùn)練RPN;
2)使用步驟中1得到的區(qū)域生成方法單獨訓(xùn)練Fast R-CNN;
3)使用步驟2得到的網(wǎng)絡(luò)作為初始網(wǎng)絡(luò)訓(xùn)練RPN。
4)再次訓(xùn)練Fast R-CNN, 微調(diào)參數(shù)。
Faster R-CNN的精度和Fast R-CNN差不多,但是訓(xùn)練時間和測試時間都縮短了10倍。
1.4 ION: Inside-Outside Net[4]
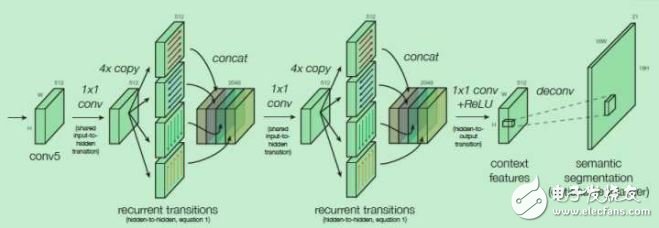
ION也是基于Region Proposal的,在得到候選區(qū)域的基礎(chǔ)上,為了進一步提高在每一個候選感興趣區(qū)域ROI的預(yù)測精度,ION考慮了結(jié)合ROI內(nèi)部的信息和ROI以外的信息,有兩個創(chuàng)新點:一是使用空間遞歸神經(jīng)網(wǎng)絡(luò)(spatial recurrent neural network)把上下文(context)特征結(jié)合,而不是只使用ROI內(nèi)的局部特征 ,二是將不同卷積層得到的特征連接起來,作為一個多尺度特征用來預(yù)測。
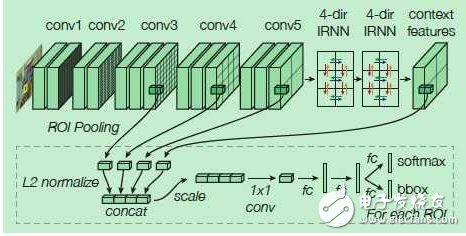
ION在上、下、左、右四個方向獨立地使用RNN,并把它們的輸出連接起來組合成一個特征輸出,經(jīng)過兩次這樣的過程得到的特征作為上下文特征,再與之前的幾個卷積層的輸出特征連接起來,得到既包括上下文信息,又包括多尺度信息的特征。
1.5 HyperNet[5]
HyperNet在Faster R-CNN的基礎(chǔ)上,在得到更好的候選區(qū)域方面比Faster R-CNN中使用的RPN有了進一步的提高。其想法也是把不同卷積層得到的特征圖像結(jié)合起來,產(chǎn)生更好的region proposal和檢測準確率。
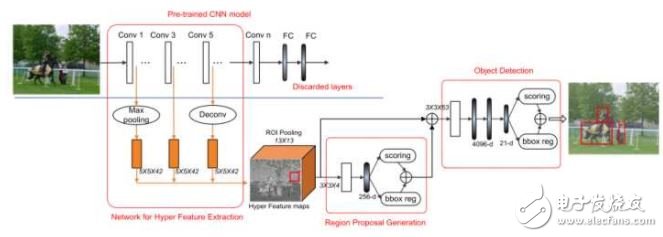
該文章把不同卷積層的輸出結(jié)合起來得到的特征成為Hyper Feature。由于不同卷積層的輸出大小不一樣,較淺層的特征圖像分辨率較高,對提高邊界框的精確性有益,但是容易對邊界框內(nèi)的物體錯誤分類;較深層得到的特征圖像分辨率很低,對小一些的物體的邊界框定位容易不準確,但這些特征更加抽象,可以讓對物體的分類的準確性更高。因此二者的結(jié)合,對目標檢測的正確率和定位精度都有幫助。
1.6SDP-CRC[6]
SDP-CRC在處理不同尺度的目標和提高對候選區(qū)域的計算效率上提出了兩個策略。第一個策略是基于候選區(qū)域尺度的池化,即Scale Department Pooling (SDP)。在CNN的框架中,由于輸入圖像要經(jīng)過多次卷積,那些尺寸小的物體在最后一層的卷積輸出上的特征不能很好的描述該物體。如果用前面某一層的特征,則能夠更好的描述小物體,用靠后的層的特征,則能更好地描述較大的物體。
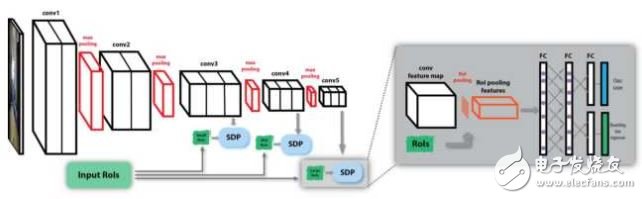
因此SDP的想法是根據(jù)物體大小選擇合適的卷積層上的特征來描述該物體。例如一個候選區(qū)域的高度在0-64個像素之間,則使用第三個卷積層上(例如VGG中的Conv3)的特征進行pooling作為分類器和邊框回歸器的輸入特征,如果候選區(qū)域高度在128個像素以上,則使用最后一個卷積層(例如VGG中的Conv5)的特征進行分類和回歸。
第二個策略是使用舍棄負樣本的級聯(lián)分類器,即Cascaded Rejection Classifer, CRC。Fast RCNN的一個瓶頸是有很多的候選區(qū)域,對成千上萬個候選區(qū)域都進行完整的分類和回歸計算十分耗時。CRC可以用來快速地排除一些明顯不包含某個物體的候選區(qū)域,只將完整的計算集中在那些極有可能包含某個物體的候選區(qū)域。該文章中使用了AdaBoost的方法,按順序使用每一個卷積層的特征,由一些級聯(lián)的弱分類器來排除負樣本。在最后一層卷積的特征圖像上,留下來的那些候選區(qū)域再進行分類和回歸。
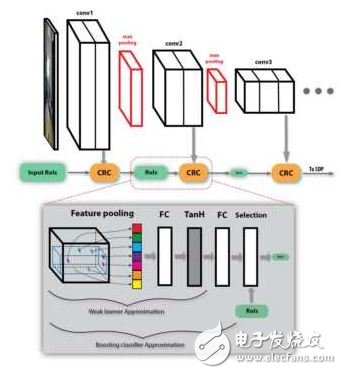
SDP-CRC的準確率比Fast RNN提高了不少,檢測時間縮短到了471ms每幀。
2、不采用Region Propsal, 直接預(yù)測邊界框的方法
2.1 YOLO[7]
YOLO的思想是摒棄生成候選區(qū)域的中間步驟,通過單個卷積神經(jīng)網(wǎng)絡(luò)直接對各個邊界框進行回歸并且預(yù)測相應(yīng)的類別的概率。
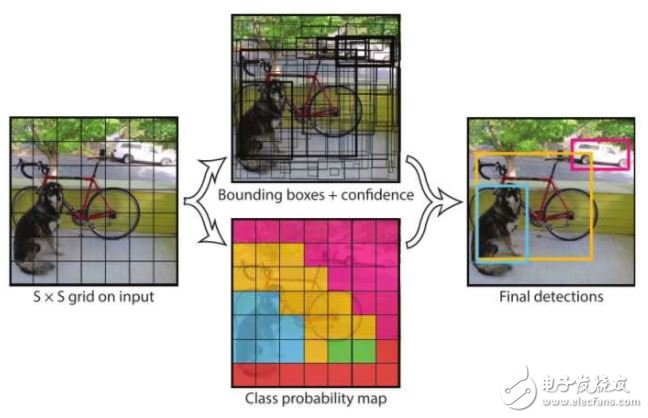

在測試階段,單元格的類別概率與該單元格的B個邊界框的可信度相乘,得到各個邊界框分別包含各個類別的物體的可信度。
YOLO的優(yōu)點是速度快,該文章中使用的24層卷積網(wǎng)絡(luò)在測試圖像上可達到45幀每秒,而使用另一個簡化的網(wǎng)絡(luò)結(jié)構(gòu),可達到155幀每秒。該方法的缺點有:1, 邊界框的預(yù)測有很大的空間限制,例如每一個單元格只預(yù)測兩個邊界框,并且只有一個類別。2,該方法不能很好地檢測到成群出現(xiàn)的一些小的目標,比如一群鳥。3,如果檢測目標的長寬比在訓(xùn)練數(shù)據(jù)中沒有出現(xiàn)過或者不常見,該模型的泛化能力較弱。
2.2 G-CNN[8]
G-CNN將目標檢測問題看作是把檢測框從一些固定的網(wǎng)格逐漸變化到物體的真實邊框的問題。 這是一個經(jīng)過幾次迭代,不斷更新的過程。
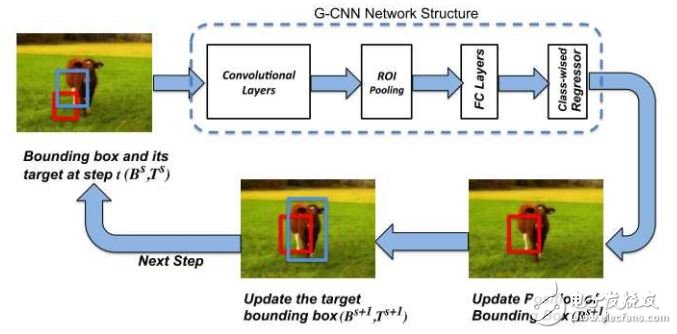
其原理圖如上所示,初始檢測框是對整個圖像進行不同尺度的網(wǎng)格劃分得到的,在經(jīng)過卷積后得到物體的特征圖像,將初始邊框?qū)?yīng)的特征圖像通過Fast R-CNN 中的方法轉(zhuǎn)化為一個固定大小的特征圖像,通過回歸得到更加準確的邊框,再次將這個新邊框作為初始邊框,做新的一次迭代。經(jīng)過若干次迭代后的邊框作為輸出。
G-CNN中使用約180個初始邊框,經(jīng)過5次迭代, 檢測幀率在3fps左右,準確率比Fast R-CNN要好一些。
2.3 SSD[9]
SSD也是使用單個的卷積神經(jīng)網(wǎng)絡(luò)對圖像進行卷積后,在特征圖像的每一個位置處預(yù)測一系列不同尺寸和長寬比的邊界框。在測試階段,該網(wǎng)絡(luò)對每一個邊界框中分別包含各個類別的物體的可能性進行預(yù)測,并且對邊界框進行調(diào)整以適應(yīng)目標物體的形狀。
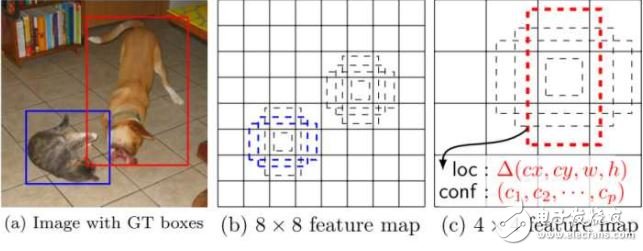
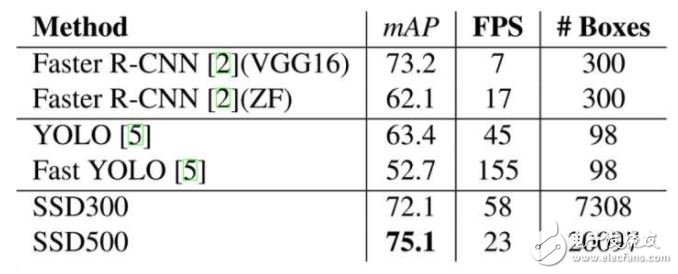
SSD在訓(xùn)練時只需要一幅輸入圖像和該圖像中出現(xiàn)的物體的邊界框。在不同的卷積層輸出是不同尺度的特征圖像(如上圖中的8x 8和4x 4),在若干層的特征圖像上的每一個位置處, 計算若干個(如4個)默認邊界框內(nèi)出現(xiàn)各個目標物體的置信度和目標物體的真實邊界框相對于默認邊界框的偏差。因此對于大小為mn的特征圖像,共產(chǎn)生(c+4)kmn個輸出。這有點類似于Faster R-CNN 中的錨的概念,但是將這個概念用到了不同分辨率的特征圖像上。SSD和YOLO的對比如下圖:
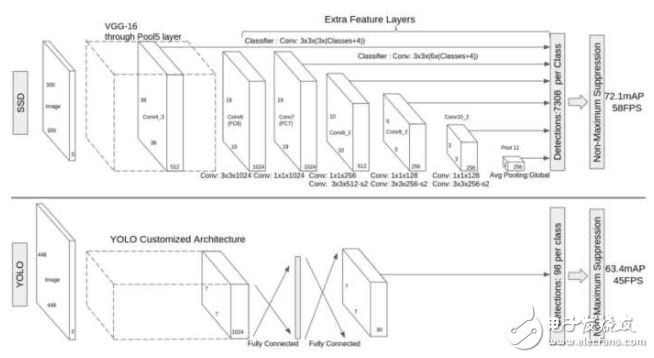
在VOC 2007測試圖像上,對于300\times300大小的輸入圖像,SSD可達到72.1% mAP的準確率,速度為58幀每秒,且能預(yù)測7k以上個邊界框,而YOLO只能預(yù)測98個。下圖是上述幾個算法在性能上的對比:












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論