 智源論壇第4期——《知識與認知圖譜》在清華大學順利舉辦
智源論壇第4期——《知識與認知圖譜》在清華大學順利舉辦

5月30日,由北京智源人工智能研究院主辦的智源論壇第4期——《知識與認知圖譜》在清華大學順利舉辦。清華大學計算機系長聘副教授劉洋針對基于神經網絡、深度學習的機器翻譯面臨三大挑戰,即知識整合、可解釋/可視化和魯棒性。并針對上述三大挑戰做了團隊最新研究與突破工作介紹。
因為人類的語言不通,《圣經》故事中的“巴別塔”沒能建成,以失敗告終。如何打破人類語言之間的屏障,也成為了人類一直希望解決的問題。
世界語言分布地圖(來源:維基百科)
地址:
https://en.wikipedia.org/wiki/Linguistic_map
目前,世界上大概有6000多種語言,其中3000多種語言是具有數學體系的。正如上圖所示,可以看到不同國家、不同地區所說的語言是大不相同的。不同語言之間的交流存在非常多的問題,這些問題就是我們通常所說的“語言屏障”。
機器翻譯就是用來解決語言屏障問題非常關鍵的技術。
機器翻譯的概念已經存在了幾個世紀,但直到20世紀50年代初才開始成為現實。從那以后,機器翻譯已經取得了巨大的進步。
機器翻譯的主要任務就是把一種語言自動翻譯成另外一種語言,看上去就像是函數映射問題。但是其難點就在于語言本身的復雜性和種類的多樣性。
世界上的語言按形態分類可分為:屈折語、黏著語和孤立語。如何將這些語言進行轉換是機器翻譯要解決的重要問題(三種語言形態詳細內容見文末)。
1990年以后,特別是互聯網出現以后,人們得到了大量的可讀文本、機讀文本,所以更傾向于使用數據進行機器翻譯。這段時期分兩個階段:
第一階段是使用傳統統計方法來(從1990年到2013年),需要且依賴于人寫特征;
第二種階段是采用深度學習方法(從2013年至今)。這一階段不需要人寫特征就寫規則,再后來只需要寫框架即可。
越往后發展,人類參與程度越精煉。現在主流方法是數據驅動的方法。
到了2016年,機器翻譯在商業界基本采用都采用了機器學習。其核心思想就是用一個非常復雜的核心網絡,做非線性函數,把源語言投射到目標語言。所以怎么設計這樣的一個函數,便成了是非常關鍵的問題。
5月30日,由北京智源人工智能研究院主辦的智源論壇第4期——《知識與認知圖譜》在清華大學順利舉辦。
清華大學計算機系長聘副教授、博士生導師 劉洋
會中,清華大學計算機系長聘副教授、博士生導師、智能技術與系統實驗室主任劉洋老師做了《基于深度學習的機器翻譯》精彩報告。
針對上述機器翻譯現狀,劉洋老師認為,這種基于神經網絡、深度學習的方法面臨三個挑戰:
第一是知識整合(Knowledge incorporation)。如何將先驗知識整合到神經機器翻譯(NMT)中?
第二是解釋性。如何解釋和理解NMT?
第三是魯棒性。如何使NMT對噪聲具有魯棒性?
對此,劉洋老師分別從上述三方面介紹了其研究重點與突破。
機器翻譯三大挑戰:知識整合
如何將知識加入到一些應用系統中是非常熱門的一個話題。
劉洋老師表示,數據、知識和模型對于整個人工智能是非常要的,研究人員建立一個數學模型,從數據中學習參數,也是某種程度上只是的表示,用同樣的模型解決現實的問題。
而有的時候數據量是不夠的,例如愛斯基摩語和維語,幾乎是沒有數據可言。像這樣冷門小領域語言的翻譯,由于數據的稀缺,翻譯任務會變得非常棘手。因此可以考慮往里面加入知識。
雖然神經機器翻譯近年來取得了很大的進展,但是如何將多個重疊的、任意先驗的知識資源整合起來仍然是一個挑戰。針對這個問題,劉洋老師及其團隊展開了研究。

arXiv地址:
https://arxiv.org/pdf/1811.01100.pdf
在這項工作中,建議使用后驗正則化來提供一個將先驗知識整合到神經機器翻譯中的通用框架。將先驗知識來源表示為一個對數線性模型的特征,該模型指導神經翻譯模型的學習過程。漢英翻譯實驗表明,該方法取得了顯著的改進。
劉洋老師表示,希望能夠提供一種通用的框架,所有的知識都能往里加。因此這項工作把人類的知識表示成一個空間這是一個符號空間。
然后把深度學習的數字表示另外一個空間,嘗試把這兩個空間關聯起來,再通過人類的知識主導這個知識,把傳統知識都壓縮里面,讓它知道深度學習的過程,就能夠提供更好的通用框架。
在這項工作中,使用以下特性來編碼知識源。
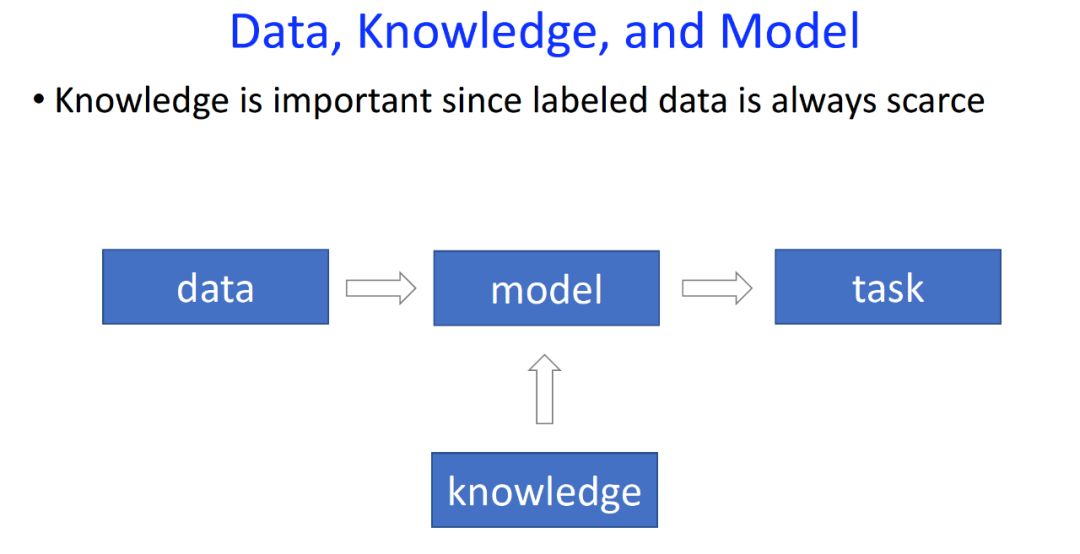
雙語詞典(bilingual dictionary):
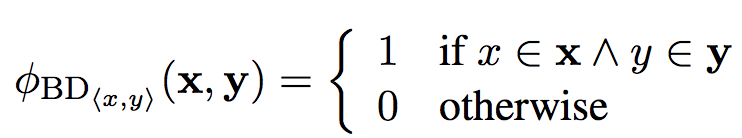
詞表(phrase table):
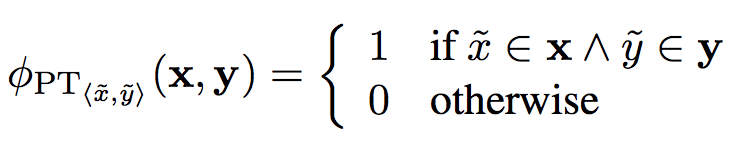
coverage penalty:
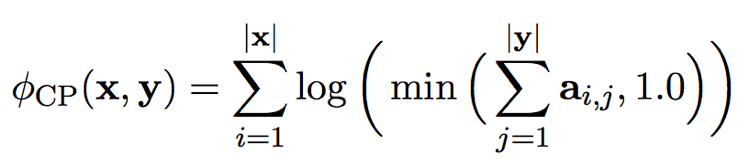
長度比(length ratio):
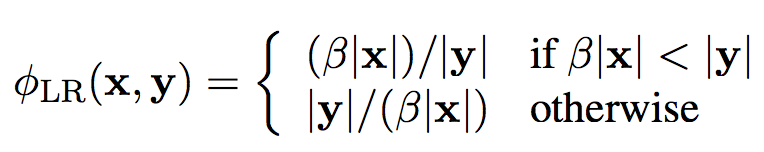
這項工作與RNNsearch、CPR和PostReg做了比較,性能對比結果如下:
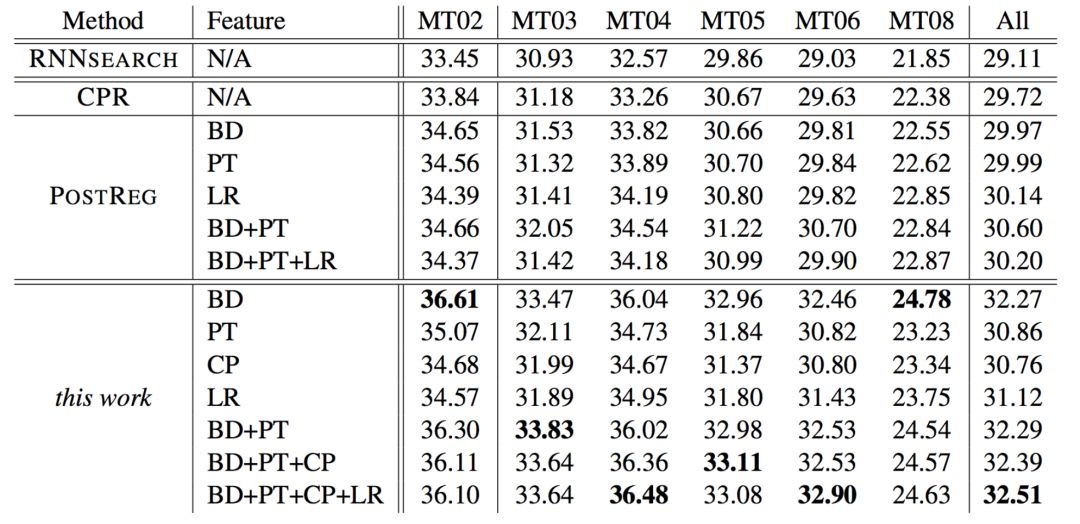
與RNNsearch、CPR和PostReg的比較
機器翻譯三大挑戰:可解釋/可視化
第二個問題就是可解釋或者可視化的問題。
目前,在機器翻譯領域,神經機器翻譯因為其較好的性能,已經取代統計機器翻譯,成為實際上的主流方法。
大多數的神經機器翻譯都是基于attention機制的encoder-decoder模型,然而這種模型在內部傳遞的是浮點數,類似于“黑箱”,難以理解和調試。
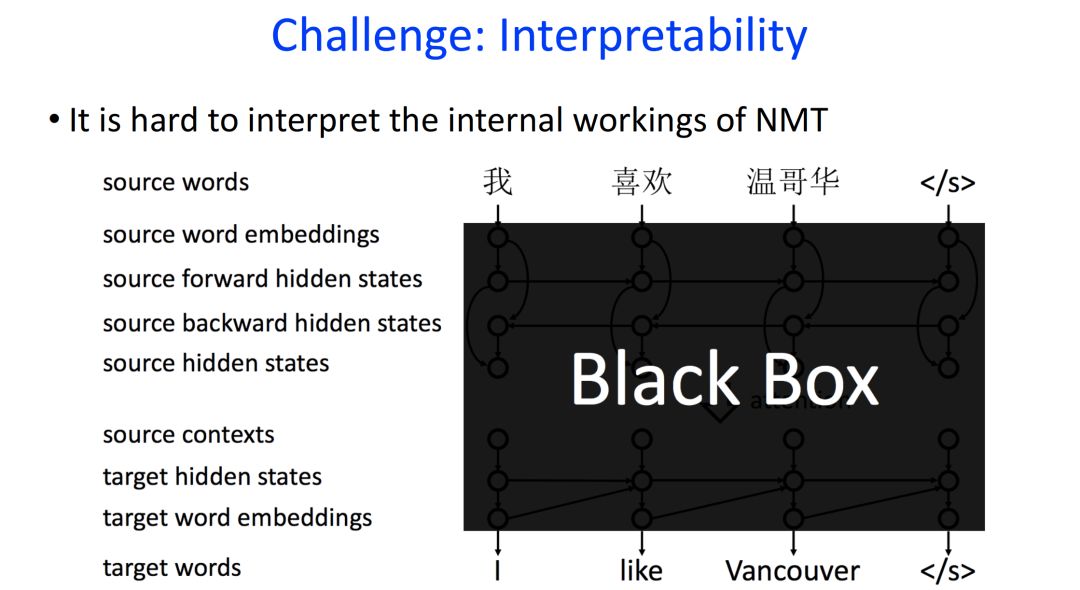
模型如“黑箱”,難以理解和調試
當輸入一個句子和輸出一個句子時,并不知道其生成過程;當出現錯誤時,也不知道是什么原因導致的。
所以研究人員迫切希望能夠打開這個黑盒子,知道內部信息怎么傳遞的,到底什么原因形成這樣一個錯誤。
針對這個問題,劉洋老師及其團隊針對這個問題進行了相應工作。

論文地址:
https://aclweb.org/anthology/P17-1106
這項工作主要的貢獻包括:
利用層級相關性傳播算法可視化分析神經機器翻譯;
能夠計算任意隱狀態和任意contextual words的相關性,同時不要求神經網絡中的函數必須可求偏導,不同于之前只有encoder和decoder隱層之間的對應信息;
能夠針對機器翻譯中出錯的例子,進行分析。
最近關于解釋和可視化神經模型的工作集中在計算輸入層上的單元對輸出層的最終決策的貢獻。 例如,在圖像分類中,理解單個像素對分類器預測的貢獻是重要的。
而在這項工作中,團隊感興趣的是計算源和目標詞對基于注意力的encoder-decoder框架中的內部信息的貢獻。
如下圖所示,第三個目標詞“York”的生成取決于源上下文(即源句“zai niuyue ”)和目標上下文(即部分翻譯“in New”)。
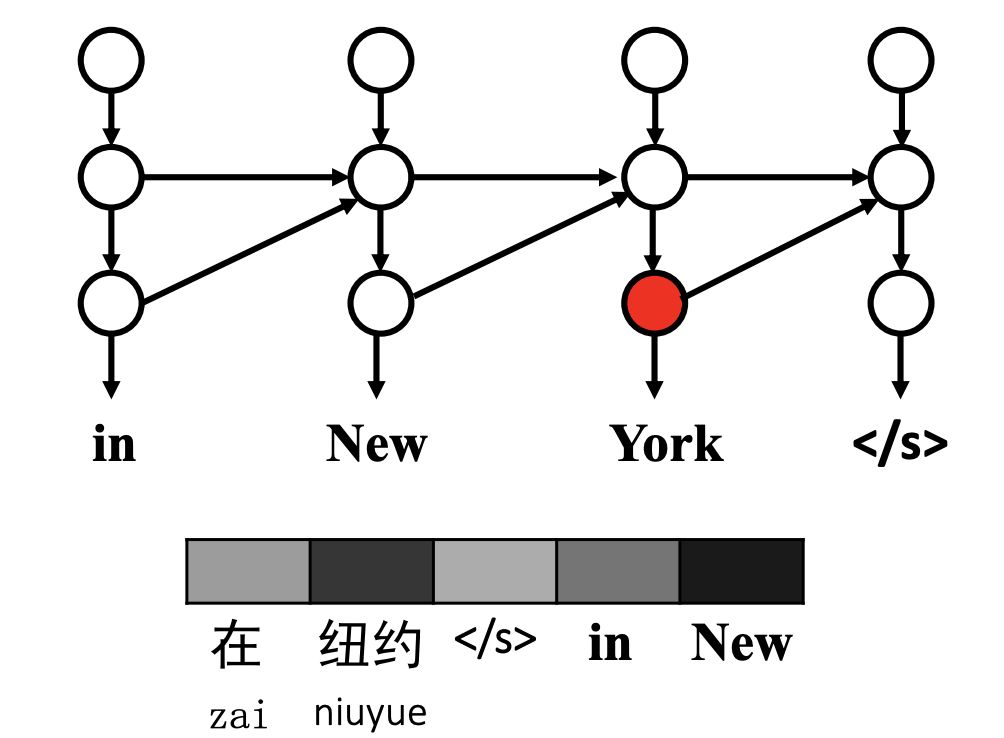
從直觀上看,源詞“niuyue”和目標詞“New”與“York”的關聯性更強,應該比其他詞獲得更高的關聯性。問題是如何量化和可視化隱藏狀態和上下文詞向量之間的相關性。
研究人員使用逐層相關傳播(layer-wise relevance propagation,LRP)來計算神經元水平相關性。 使用下圖所示的簡單前饋網絡來說明LRP的核心思想。
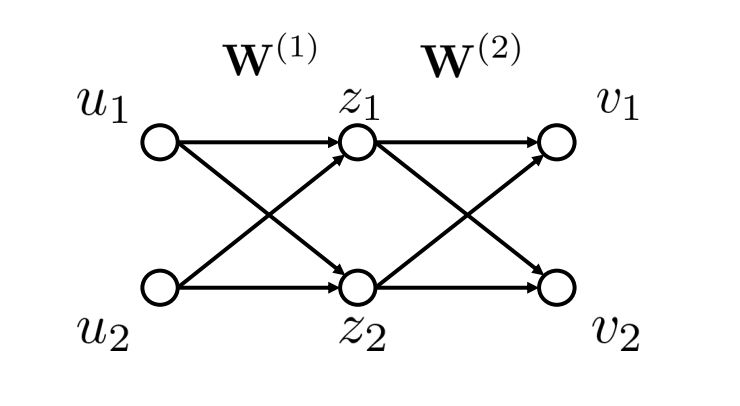
如果要計算 v1和u1之間的相關性,首先計算v1 和z1、z2之間的相關性,再將 v1和z1、 z2的相關性傳遞到u1,從而求得v1和u1之間的相關性。

對神經機器翻譯的LRP算法
通過這樣一種技術,能夠對于機器翻譯中所有的模型都進行可視化的分析。
劉洋老師表示,LRP能夠為Transformer生成相關矩陣。它本身是沒有辦法進行分析的,用了這個技術就可以把輸入、輸出以及內部的關聯性用可視化的方式呈現出來,這樣可以更好分析運作機制。
團隊用在機器翻譯的錯誤分析上,分析了漏詞、重復翻譯、形成無關詞,還有否定的反轉。
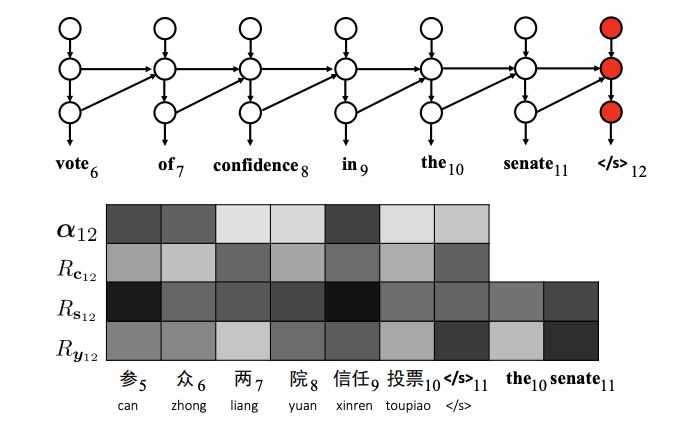
分析翻譯錯誤:詞的省略。第6個源詞“zhong”沒有被正確翻譯。
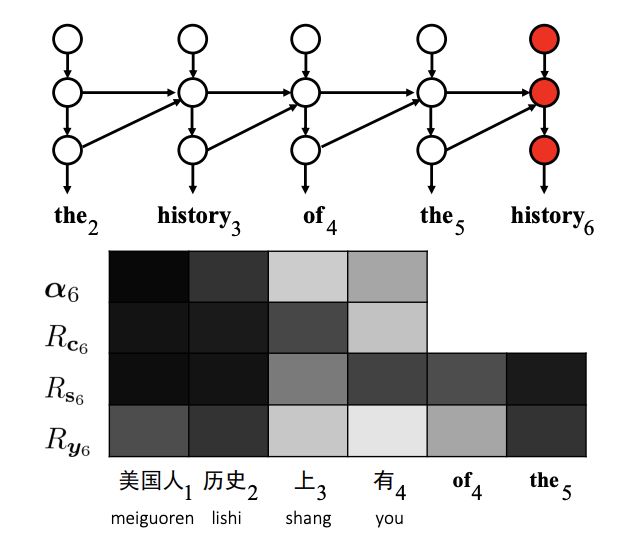
分析翻譯錯誤:單詞重復。目標詞“history”在翻譯中兩次出現錯誤。
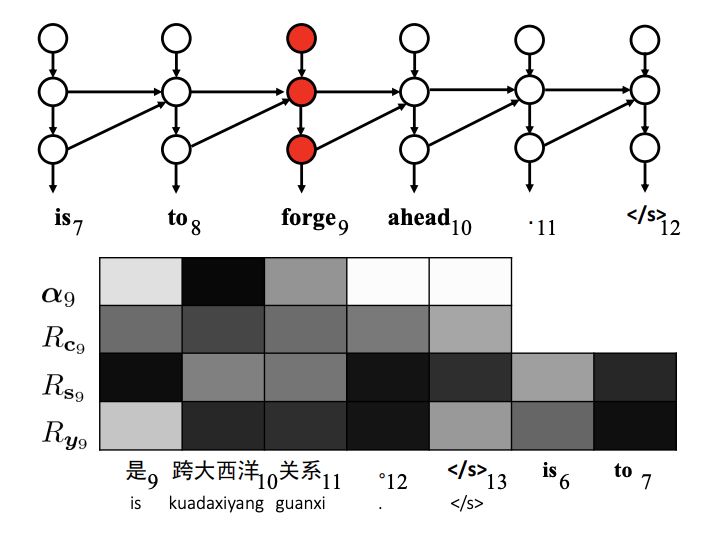
分析翻譯錯誤:不相關的詞。第9個目標詞“forge”與源句完全無關。
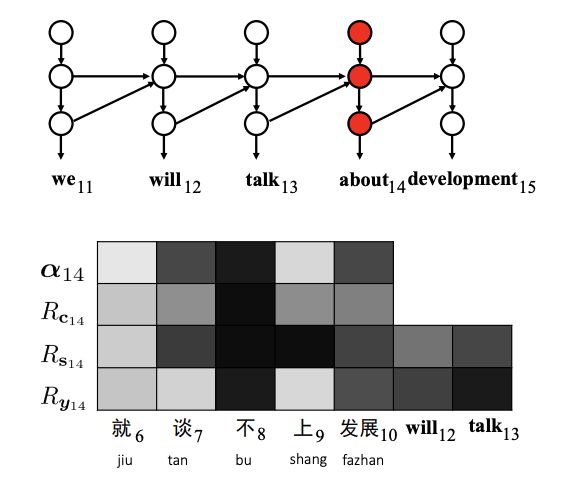
分析翻譯錯誤:否定。第8個否定詞“bu”(not)不翻譯。
機器翻譯三大挑戰:魯棒性
第三個問題就是魯棒性。
有這樣一個例子,假設有一段譯文,輸入的是“《中國電子銀行業務管理新規》將于3月1日起施行”,若是一不小心把“中國”敲成“中方”,后面所有的譯文發生變化,劉洋老師稱之為蝴蝶效應。

這就是現在存在的一個較為現實的問題:輸入中的小擾動會嚴重扭曲中間表示,從而影響神經機器翻譯(NMT)模型的翻譯質量。
這是因為深度學習是一種全局關聯的模型,只要有一點點變化,就會牽一發而動全身,而這是非常糟糕的。
為了解決這個問題,劉洋老師團隊就針對此問題展開了研究。

arXiv地址:
https://arxiv.org/pdf/1805.06130.pdf
在這項研究中,研究人員提出了通過對抗性穩定性訓練來提高NMT模型的魯棒性。
其基本思想是使NMT模型中的編碼器和解碼器對輸入擾動都具有魯棒性,使它們對原始輸入及其受擾動的對應項具有類似的行為。
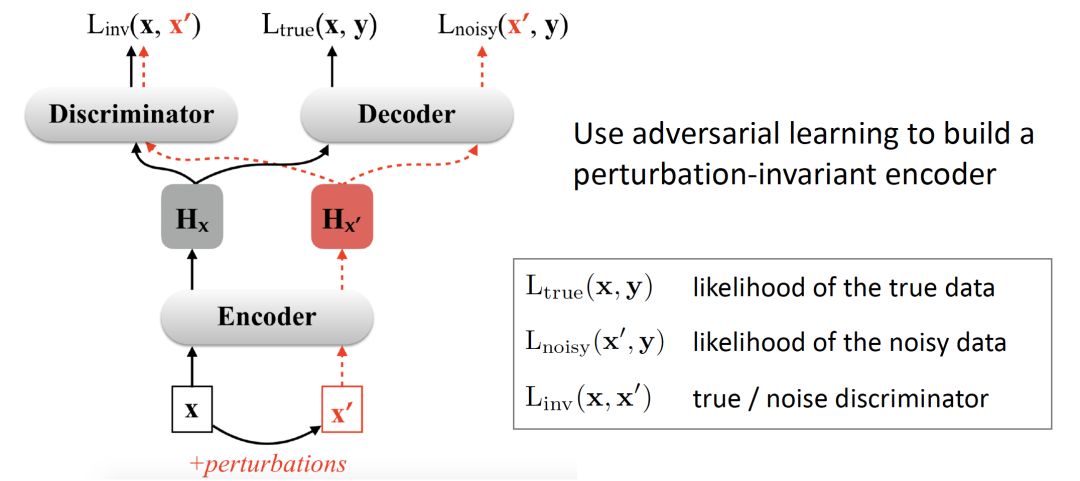
在這項工作中提出了兩種合成噪聲的產生方法。
Lexical level:
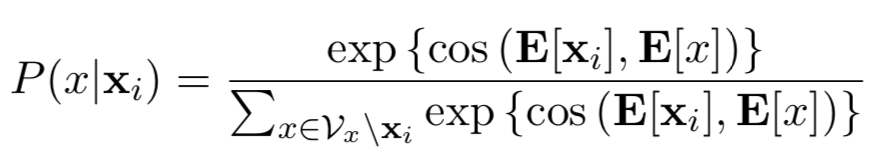
feature level:
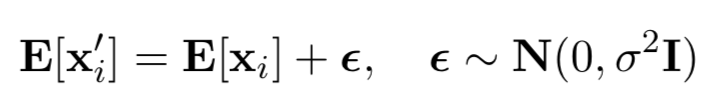
在給定一個源字的情況下,它在向量空間中的鄰居可以選擇為一個有噪聲的字。
損失函數的影響以及主要的實驗結果如下:
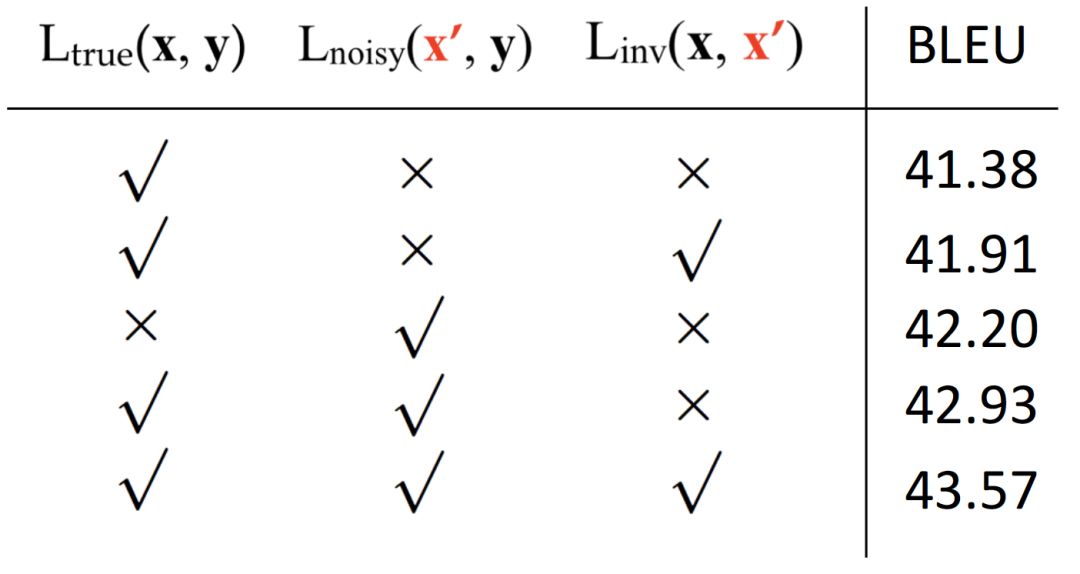
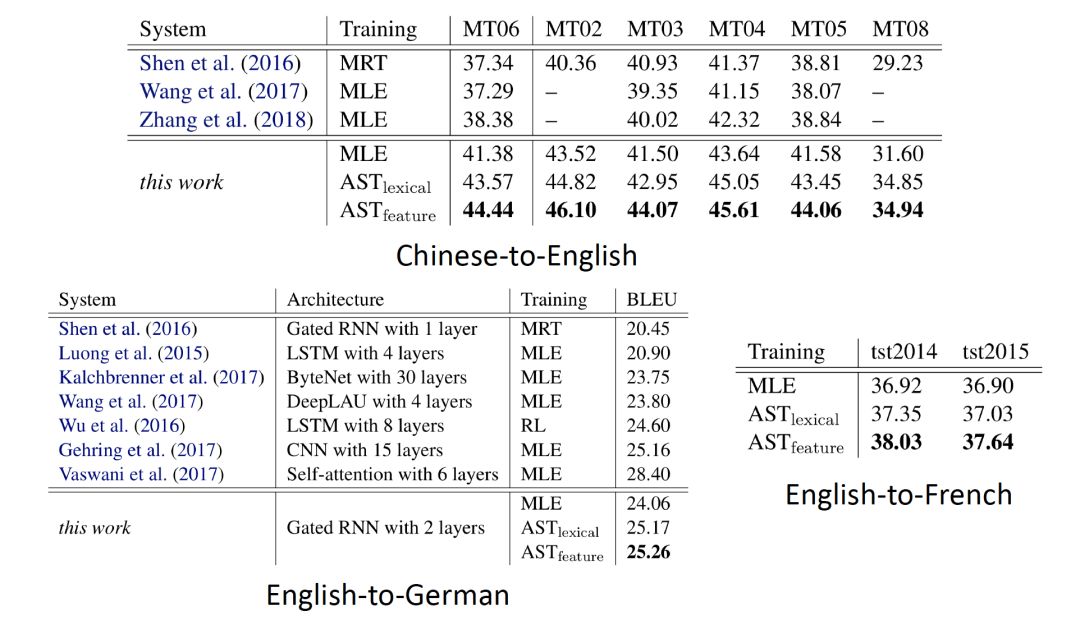
最后,劉洋老師給提供了針對神經機器翻譯的開源工具包,有興趣的讀者可以訪問下方鏈接進行實驗:
開源工具包地址:
http://thumt.thunlp.org/
附:三種語言形態詳細內容
孤立語以中文為代表,它由各自獨立且具有完整意義的單詞,通過單純的疊加構成文句。
黏著語以烏拉爾阿爾泰語系為中心,通過用助詞、助動詞將獨立的單詞連接起來,完成整個文章的陳述。
屈折語指的是歐洲語系,單詞本身隨著人稱、時態、格等發生復雜的形態變化。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103622 -
機器翻譯
+關注
關注
0文章
140瀏覽量
15196 -
深度學習
+關注
關注
73文章
5561瀏覽量
122794
原文標題:清華劉洋《基于深度學習的機器翻譯》,突破知識整合、可解釋和魯棒性三大難關
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
清華大學TOP EE+項目參訪美光上海
從清華大學到鎵未來科技,張大江先生在半導體功率器件十八年的堅守!
清華大學攜手華為打造業內首個園區網絡智能體
2025年開放原子校源行清華大學站成功舉辦
奇瑞汽車攜手清華大學發布“分體式飛行汽車”專利
清華大學鯤鵬昇騰科教創新卓越中心專項合作啟動,引領高校科研和人才培養新模式
清華大學與華為啟動“卓越中心”專項合作
清華大學DeepSeek指南:從入門到精通

OpenHarmony城市技術論壇第12期——合肥站圓滿舉辦

博世與清華大學續簽人工智能研究合作協議
京微齊力受邀參加2024年清華大學工程博士論壇
英諾達與清華大學攜手,共促國產EDA進步
清華新力量,滬上芯征程!清華大學上海校友會半導體專委會2024思瑞浦迎新日

熱烈歡迎清華大學電子工程系學子來武漢六博光電交流實踐!






 工商網監
工商網監
評論