 谷歌 | AI再突破,Efficientnets有望成為計算機視覺任務的新基礎!
谷歌 | AI再突破,Efficientnets有望成為計算機視覺任務的新基礎!

谷歌人工智能研究部門的科學家認為Efficientnets通過寬度、深度、分辨率三個維度的復合擴展,展現出比現行的CNN更高的精度和效率,將成為未來計算機視覺任務的新基礎。
卷積神經網絡(CNN)作為人工神經網絡的一種,是當下語音分析和圖像識別領域的研究熱點。
它的人工神經元可以響應一部分覆蓋范圍內的周圍單元,所以對于大型圖像處理有出色表現,但是如果要某一點上提高準確性,就需要進行較為繁瑣的優化調整。
針對這一現象,谷歌人工智能研究部門的科學家正在研究一種“更結構化”的方式,用以“縮放”CNN,期望獲得更好的精度和效率。
最近,他們在Arxiv.org上發表的一篇論文(EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks)并附帶了一篇博客文章中對其進行描述。他們聲稱,這個被稱為“Efficientnets”的AI系統,超過了最先進的精度,并且提升了10倍的效率。
這篇論文的作者工程師Mingxing Tan 和谷歌人工智能首席科學家Quocv.le都來自谷歌大腦。
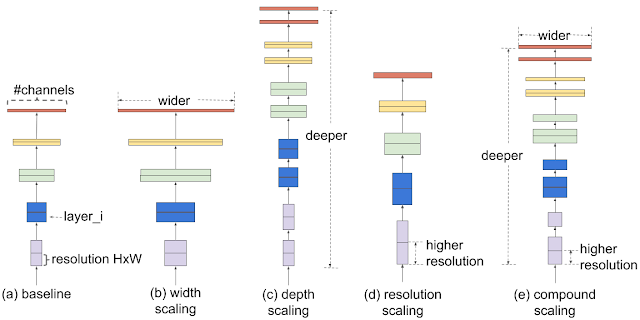
他們認為,模型縮放的傳統做法是任意增加CNN的深度或寬度,或者使用更大的輸入圖像分辨率進行訓練和評估。區別于傳統方法,他們采用了一組固定的縮放系數來均勻縮放每個尺寸。
圖中最右側就是他們的方案,在寬度、深度、分辨率三個維度進行復合擴展。單一調整一個維度能夠獲得精度提升,但是隨著參數調的越大,精度增益越平滑,改進將會不明顯。而聯合調整就能夠獲得相對更好的精度增益曲線。
那么,它是如何做到的呢?
首先,在固定的資源約束下,通過進行柵欄搜索,識別基線網絡不同維度之間的關系。例如,增加兩倍的FLOPS。這決定了每一個維度適當的縮放系數,將應用于基線網絡縮放至需要的模型尺寸或者計算預算。為了進一步提高性能,科研人員提出了一種新的基線網絡,即MBConv,可以為EfficientNets模型體系提供種子。
在測試的過程中,Efficientnets展現出比現行的CNN更高的精度和效率,將參數大小和FLOPS減少了一個數量級。
其中,Efficientnet-B7比CNNgpipe小8.4倍,快6.1倍,分別在imagenet中上達到了Top-1(84.4%)和Top-5(97.1%)的精度。與resnet-50相比,EfficientNet-B4使top-1精度從ResNet-50的76.3%提高至82.6%。
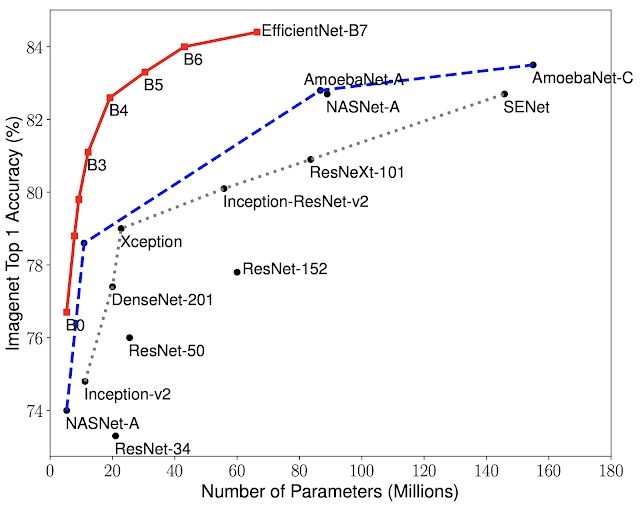
EfficientNets在其他數據集的表現也很好。在5/8的廣泛使用的轉移學習數據集中,EfficientNets都達到了最先進的精度,并且減少了21個參數。例如,CIFAR-100(91.7%)和Flowers(98.8%),這也表明EfficientNets有很好地轉移。
兩位作者表示,通過對模型效率的顯著改進,EfficientNets有可能成為未來計算機視覺活動的新基礎。他們開源了所有EfficientNet模型,希望這些模型可以使機器學習社區受益。
-
谷歌
+關注
關注
27文章
6232瀏覽量
108304 -
AI
+關注
關注
88文章
35320瀏覽量
280789 -
計算機視覺
+關注
關注
9文章
1709瀏覽量
46819
原文標題:谷歌AI再突破,Efficientnets有望成為計算機視覺任務的新基礎!
文章出處:【微信號:Aiobservation,微信公眾號:人工智能觀察】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動化計算機的功能與用途

NVIDIA驅動的現代超級計算機如何突破速度極限并推動科學發展
NVIDIA技術賦能歐洲最快超級計算機JUPITER
一文帶你了解工業計算機尺寸

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

英飛凌邊緣AI平臺通過Ultralytics YOLO模型增加對計算機視覺的支持
Arm KleidiCV與OpenCV集成助力移動端計算機視覺性能優化
工業中使用哪種計算機?

量子計算機與普通計算機工作原理的區別
工業計算機類型介紹

【小白入門必看】一文讀懂深度學習計算機視覺技術及學習路線






 工商網監
工商網監
評論