 NVIDIA驅動的現代超級計算機如何突破速度極限并推動科學發展
NVIDIA驅動的現代超級計算機如何突破速度極限并推動科學發展

現代高性能計算不僅使得更快的計算成為可能,它正驅動著 AI 系統解鎖更多領域的科學突破。
高性能計算經歷了多次迭代,每一次都源于對技術的創造性再利用。例如,早期的超級計算機使用現成的組件制造。后來,研究人員用個人電腦構建了強大的集群,甚至改造游戲顯卡,把它們用于科學研究。
當今的高性能計算系統專為高速計算而設計,其中許多都采用了 NVIDIA 加速計算技術。在 ISC 2025 大會上揭曉的最新全球最快超級計算機 TOP500 榜單顯示,NVIDIA 為該榜單中 77% 的系統提供動力。
與此同時,像 Tensor Core 這樣的創新功能為矩陣乘法等常見運算提供了更快的計算能力,而混合精度等技術的普及則大幅提升了性能和能效,推動了氣候科學和醫學等領域的飛躍式發展。
NVIDIA 為 TOP500 中名列前茅的系統提供動力
NVIDIA 在超算領域繼續處于領先地位,為最新 TOP500 榜單中的 381 個系統提供動力,包括新進躋身前十的于利希超算中心的 JUPITER 超級計算機(排名第 4)。
TOP500 前 100 名系統中,目前有 83 個采用了加速計算,僅 17 個只使用了 CPU。
此外,在 Green500 全球最節能 FP64 超級計算機榜單上,前兩名均采用了 NVIDIA GH200 Grace Hopper 超級芯片,前十名中有九個系統均由 NVIDIA 加速。
Tensor Core 在科學領域的應用
AI 性能的提升不僅源于浮點運算量的增加,也越來越多地根植于硬件與軟件的融合,例如對于 Tensor Core 的使用。
Tensor Core 是 NVIDIA GPU 內的先進組件,專為加速矩陣運算(AI 和深度學習的核心計算)而設計。通過更高效地處理復雜計算,Tensor Core 加速了模型訓練和推理等過程。
Tensor Core 加速了常見的矩陣運算,尤其是當組織轉向 FP8 等更低精度進行模型訓練時。隨著精度每降低一級,吞吐量就會提高近一倍,同時還能保持準確。目前,只有模擬工作負載中的某些運算可以利用 Tensor Core。這些運算通常占總運行時間的一小部分,而且很少對整體性能產生重大影響。
隨著 GPU 上越來越多的物理空間被用于為 AI 構建的低精度 Tensor Core,高性能計算社區迎來了把這些硬件重新用于推進科學發現的機會。
為此,NVIDIA 正投資開發新方法,以便將 Tensor Core 用于更廣泛的科學模擬相關場景。
RIKEN 研究所計算科學中心的 Yuki Uchino 和芝浦工業大學教授 Katsuhisa Ozaki 發表了一篇論文,其中展示了如何利用 Tensor Core 中的整數矩陣乘法加速器和一種名為 Ozaki scheme 的算法,使 GPU 中的整數單元能夠實現包括 FP64 在內的任意精度。
受此方案啟發,NVIDIA 正在開發相關庫,以利用更多 GPU Tensor Core 來加速高精度張量和矩陣計算,聚焦于提升準確度、性能和能效。
使用這些庫已展現出一些驚人的優勢:在一個硅模擬中,把大約 1000 個原子暴露在紫外線下,使用這些庫的速度比使用 FP64 硬件快 1.8 倍,而二者輸出相同結果,這節省了時間和能源。
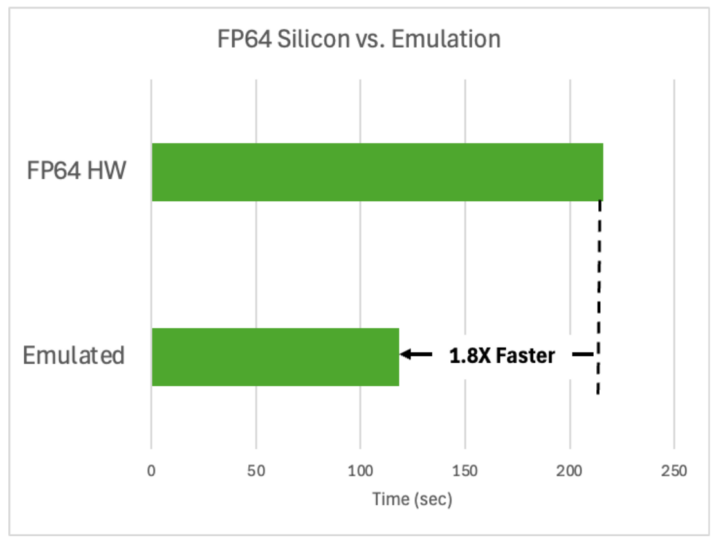
圖 1. 使用原生 FP64 硅和仿真技術對 998 個硅原子
進行 BerkeleyGW 模擬的性能比較
借助這些新的庫,BerkeleyGW 等常見的高性能計算模擬將很快能夠利用低精度 Tensor Core,實現性能和能效的飛躍。
AI 超級計算推動科學進步
盡管 TOP500 榜單凸顯了當今超級計算機非凡的高精度運算速度,但并未體現出它們在通過混合精度和 AI 推動科學發現方面的巨大影響力。
去年,諾貝爾化學獎和物理學獎被授予使用 AI 的科研人員,包括 Demis Hassabis 和 John Jumper(因在谷歌 DeepMind 的蛋白質結構預測模型 AlphaFold 上的卓越工作而獲獎),以及多倫多大學名譽教授 Geoff Hinton 和普林斯頓大學名譽教授 John Hopfield(因推進神經網絡架構而獲獎)。
高性能計算領域的最高榮譽“戈登·貝爾獎”授予了 KAUST 的 David Keyes 團隊,表彰他們使用混合精度方法來模擬龐大的 ERA5 氣候數據集。該數據集提供了過去 80 年中每小時的大氣、陸地和海浪變量估計值,包含從地表到 80 公里高度的 137 個海拔層。
混合精度是一種結合了多種浮點精度格式的技術。使用較低精度的數據類型可提升性能和能效,讓應用程序能夠使用更少的資源來實現更高的性能。
隨著科學家構建新的 AI 模型以加速科學工作流,混合精度在科學領域的應用日益普及。
在英國,布里斯托大學的 Isambard-AI 系統(由 NVIDIA Grace Hopper 提供動力)使用混合精度來訓練 Nightingale 等模型。
Nightingale 是用于醫療和生物醫學研究的多模態基礎模型,集成了影像、心臟病學和電子健康記錄。與醫療領域的其它大語言模型不同,Nightingale 不僅使用基于文本的推理,還利用影像模式和標準診斷技術,結合海量患者數據來提供醫學見解。Nightingale 的目標是成為其它醫療應用軟件的基礎,包括醫生辦公助手和遠程醫療分診系統。
通過使用混合精度,Isambard-AI 實現了訓練 Nightingale 等多模態大語言模型所需的大規模和準確性,而無需為訓練或推理配置過多的硬件。
邁向高性能計算的下一次迭代
加速計算、先進的張量技術和混合精度方法的結合,正在改變計算科學,也展示了 AI 驅動更多突破的潛力。
隨著 JUPITER 等系統入選 TOP500,越來越多的工作借助 AI 來用于科學研究和創新,如將 Isambard-AI 超級計算機用于科學研究及通過 Ozaki 仿真方法所帶來的諸多創新,這些都推動著 Tensor Core 處理高精度計算的性能不斷提升,一個新時代正在到來。
從某些指標來看,超級計算機將繼續提速,但僅有速度是不夠的。要找到破解重要科學難題的新見解,需要依賴智能、靈活的方法,以在不犧牲科學嚴謹性的前提下加速科學發現,從而滿足科學和高性能計算社區乃至全球的需求。
-
NVIDIA
+關注
關注
14文章
5282瀏覽量
106065 -
超級計算機
+關注
關注
2文章
472瀏覽量
42418 -
英偉達
+關注
關注
22文章
3933瀏覽量
93367 -
高性能計算
+關注
關注
0文章
91瀏覽量
13635
原文標題:NVIDIA 驅動的現代超級計算機如何突破速度極限并推動科學發展
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Blue Lion超級計算機將在NVIDIA Vera Rubin上運行
NVIDIA技術賦能歐洲最快超級計算機JUPITER
NVIDIA助力全球最大量子研究超級計算機
NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

NVIDIA推出個人AI超級計算機Project DIGITS
聯發科與NVIDIA合作 為NVIDIA 個人AI超級計算機設計NVIDIA GB10超級芯片
NVIDIA加速全球大多數超級計算機推動科技進步

NVIDIA助力xAI打造全球最大AI超級計算機
NVIDIA Colossus超級計算機集群突破10萬顆Hopper GPU
NVIDIA 以太網加速 xAI 構建的全球最大 AI 超級計算機






 工商網監
工商網監
評論