 自動駕駛汽車的端到端學習
自動駕駛汽車的端到端學習

研究人員將使用udacity提供的模擬器,模擬車前部配有3個攝像頭,可記錄視頻以及與中央攝像頭對應的轉向角。
行為克隆的本質是克隆了驅動程序的行為。本文的實驗思路是根據駕駛員駕駛的訓練數據訓練卷積神經網絡(CNN)以模擬駕駛員。
NVIDIA曾發布了一篇題為End to End Learning for Self-DrivingCars 的文章,他們訓練CNN將原始像素從單個前置攝像頭直接映射到轉向命令。實驗結果令人非常震驚,汽車學會了在有或沒有車道標記的地方道路上或者在具有最少量訓練數據的高速公路上行駛。本次實驗,研究人員將使用udacity提供的模擬器,模擬車前部配有3個攝像頭,可記錄視頻以及與中央攝像頭對應的轉向角。
收集數據
模擬器有2個通道:第一個通道非常容易,曲線較小且很少,第二個通道很難,有許多曲線和陡峭的山坡。
研究人員將使用來自兩個軌道的訓練數據:
1.研究人員將駕駛兩條車道,將車保持在車道的中心位置。研究人員每人開車2圈。
2.研究人員將在兩條車道上各開一圈,并試圖漂移到兩側,或試圖轉向車道的中心。這將為研究人員提供模型校正的訓練數據。
圖分別為左、中、右視角
捕獲的數據包含左圖像,中心圖像和右圖像的路徑,轉向角度,油門,中斷和速度值。

注意:研究人員將使用所有左,中,右圖像。研究人員將通過一些調整來矯正left_image的轉向角度。同樣,研究人員將通過一些調整來矯正right_image的轉向角度。
數據不平衡
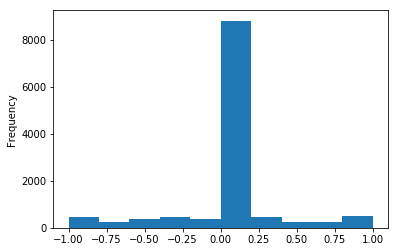
圖轉向角直方圖
上面的直方圖顯示了訓練數據的不平衡。左轉彎的數據多于右轉彎的數據。研究人員將通過隨機翻轉訓練圖像并將轉向角度調整為steering_angle來補償這一點。
此外,大多數轉向角集中在0-0.25左右,研究人員沒有太多的數據來獲得更大的轉向角。研究人員將通過一些像素水平和垂直地隨機移動圖像并相應地調整轉向角來補償這一點。
數據擴充
研究人員使用以下增補:
1.隨機翻轉一些圖像并將轉向角度調整為steering_angle
2.通過一些像素水平和垂直地隨機移動圖像,并使用小的調整因子調整轉向角度。
3.路上有樹木,柱子等陰影。因此,研究人員將為訓練圖像添加一些陰影。4.研究人員會隨機調整圖像的亮度。
以上這些是標準的OpenCV調整,代碼可以在GitHub存儲庫中找到。(詳見文末鏈接)
應用增強后,下面是一些訓練圖像的輸出。

前處理
本文期望圖像的輸入尺寸為66 * 200 * 3,而來自訓練的圖像尺寸為160 * 320 * 3。此外,紙張期望將輸入圖像從RGB轉換為YUV顏色空間。因此,研究人員將從輸入圖像裁剪上部40像素行和下部20像素行。此外,作為預處理的一部分,研究人員將裁剪的圖像大小調整為66 * 200 * 3大小并將其轉換為YUV色彩空間。
模型
這是本文中描述的PilotNet模型:
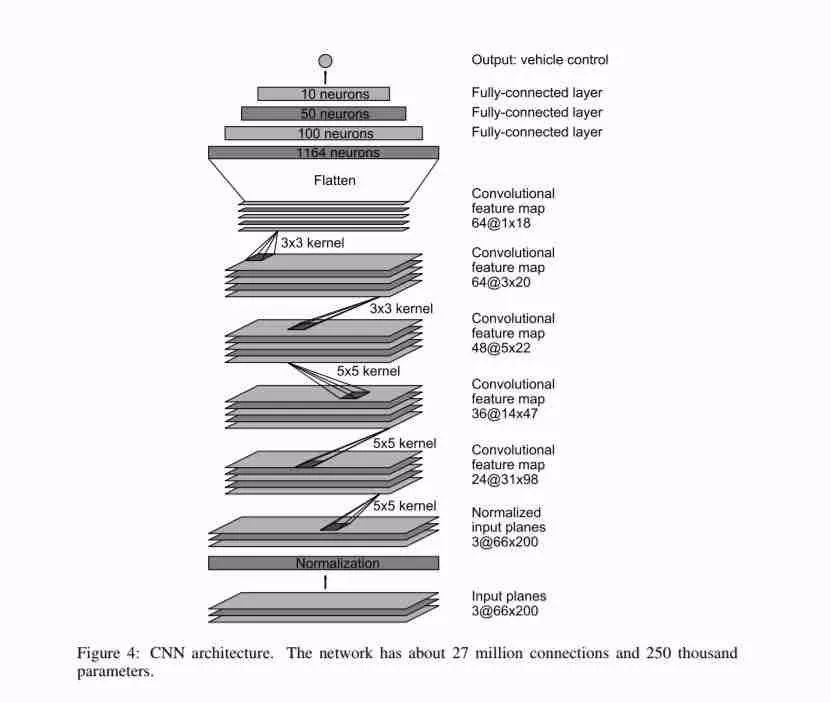
該模型具有以下層:
①標準化層(硬編碼)除以127.5并減去1。
②3個卷積層,24個,36個,48個過濾器,5 * 5內核和2個步幅。
③2個卷積層,64個濾波器,3 * 3內核和步幅1。
④展平層
⑤3個完全連接的層,輸出尺寸為100,50,10
⑥和輸出轉向角的最終輸出層。
研究人員將使用Mean Squared Error(MSE)作為損失函數和優化器,并進行EarlyStopping回調。研究人員試圖訓練它40個epoch,它在36個epoch停止。
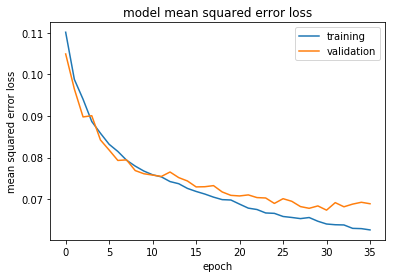
訓練60個epoch的模型,結果如下:
突出的特點:
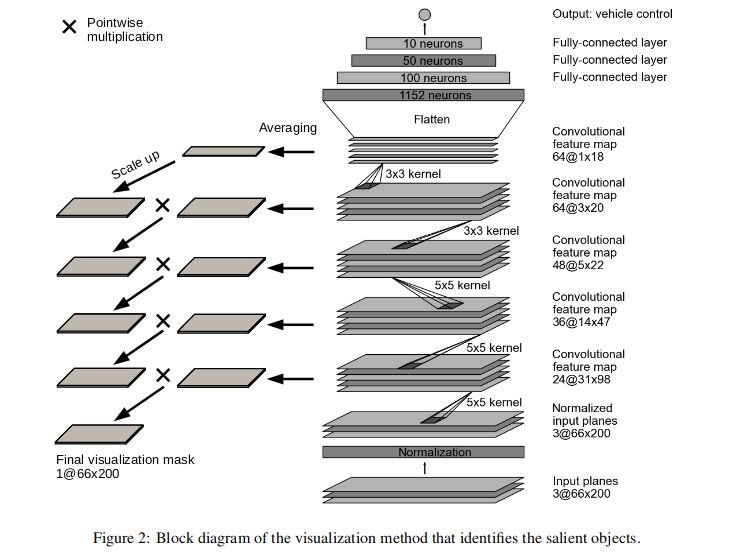
1. 在每個圖層中,對要素圖的激活進行平均。
2.最平均的地圖按比例放大到下面圖層的地圖大小。使用反卷積完成放大。
3.然后將來自較高級別的放大的地圖與來自下層的平均地圖相乘。
4.重復步驟2和3直到達到輸入。
5.具有輸入圖像大小的最后一個掩模被標準化為0.0到1.0的范圍。
以下是可視化圖,顯示輸入圖像的哪些區域對網絡的輸出貢獻最大。
在應用上述方法之后,下面是顯著的特征結果:
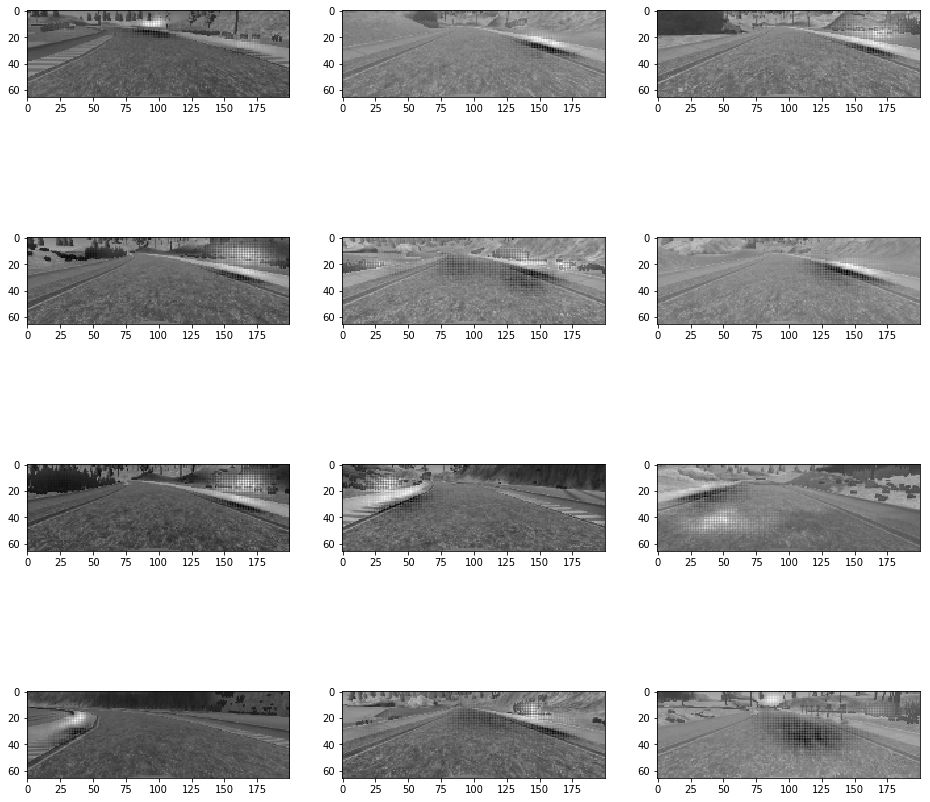
圖突出的車道標記
結論
PilotNet是一個非常強大的網絡,從駕駛員學習輸出正確的轉向角度。對顯著物體的檢查表明,PilotNet學習了對人類“有意義”的特征,同時忽略了與駕駛無關的攝像機圖像中的結構。此功能源自數據,無需手工標記。
-
攝像頭
+關注
關注
61文章
4965瀏覽量
97980 -
自動駕駛
+關注
關注
788文章
14265瀏覽量
170153
原文標題:行為克隆 | 自動駕駛汽車的端到端學習
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
端到端數據標注方案在自動駕駛領域的應用優勢
自動駕駛中基于規則的決策和端到端大模型有何區別?
東風汽車推出端到端自動駕駛開源數據集
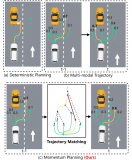
動量感知規劃的端到端自動駕駛框架MomAD解析
DiffusionDrive首次在端到端自動駕駛中引入擴散模型

端到端自動駕駛技術研究與分析
從車企實踐看自動駕駛端到端解決方案

Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
Mobileye端到端自動駕駛解決方案的深度解析







 工商網監
工商網監
評論