") 蒙娜麗莎一鍵復(fù)活 三星AI一張圖片就能合成動畫
蒙娜麗莎一鍵復(fù)活 三星AI一張圖片就能合成動畫
還記得哈利?波特第一次來到霍格沃茨看到墻上那些既會動又會說話的掛畫是多么驚訝嗎?如果我們可以將掛畫 “復(fù)活”,和 500 多年前的蒙娜麗莎來場穿越時空的對話會怎樣呢?感謝 AI 技術(shù),把畫 “復(fù)活” 不再是夢!
名畫《蒙娜麗莎的微笑》,會動了!
夢娜麗莎轉(zhuǎn)過頭,嘴里說著話,微微眨了眨眼,臉上帶著溫婉的微笑。
是的,《哈利·波特》世界中”會動的畫“魔法實現(xiàn)了!來自三星AI中心(Samsung AI Center)和莫斯科斯的Skolkovo 科學(xué)技術(shù)研究所的一組研究人員,開發(fā)了一個能將讓JPEG變GIF的AI系統(tǒng)。
《哈利·波特》中守衛(wèi)格蘭芬多學(xué)院休息室的胖夫人畫像
更牛逼的是,該技術(shù)完全無需3D建模,僅需一張圖片就能訓(xùn)練出惟妙惟肖的動畫。研究人員稱這種學(xué)習(xí)方式為“few-shot learning"。當(dāng)然,如果有多幾張照片——8張或32張——創(chuàng)造出來動圖效果就更逼真了。比如:
愛因斯坦給你講物理:
瑪麗蓮夢露和你 flirt:
本周,三星AI實驗室的研究人員發(fā)表了一篇題為 “Few-Shot Adversarial Learning of Realistic Neural Talking Head Models” 的論文,概述了這種技術(shù)。該技術(shù)基于卷積神經(jīng)網(wǎng)絡(luò),其目標(biāo)是獲得一個輸入源圖像,模擬目標(biāo)輸出視頻中某個人的運(yùn)動,從而將初始圖像轉(zhuǎn)換為人物正在說話的短視頻。
論文一發(fā)表馬上引起轟動,畢竟這項技術(shù)創(chuàng)造了巨大的想象空間!
類似這樣的項目有很多,所以這個想法并不特別新穎。但在這篇論文中,最有趣的是,該系統(tǒng)不需要大量的訓(xùn)練示例,而且系統(tǒng)只需要看一次圖片就可以運(yùn)行。這就是為什么它讓《蒙娜麗莎》活起來。
3個神經(jīng)網(wǎng)絡(luò),讓蒙娜麗莎活起來
這項技術(shù)采用“元學(xué)習(xí)”架構(gòu),如下圖所示:
圖2:“讓照片動起來”元學(xué)習(xí)架構(gòu)
具體來說,涉及三個神經(jīng)網(wǎng)絡(luò):
首先,嵌入式網(wǎng)絡(luò)映射輸入圖像中的眼睛、鼻子、嘴巴大小等信息,并將其轉(zhuǎn)換為向量;
其次,生成式網(wǎng)絡(luò)通過繪制人像的面部地標(biāo)(face landmarks)來復(fù)制人在視頻中的面部表情;
第三,鑒別器網(wǎng)絡(luò)將來自輸入圖像的嵌入向量粘貼到目標(biāo)視頻的landmark上,使輸入圖像能夠模擬視頻中的運(yùn)動。
最后,計算“真實性得分”。該分?jǐn)?shù)用于檢查源圖像與目標(biāo)視頻中的姿態(tài)的匹配程度。
元學(xué)習(xí)過程:只需1張輸入圖像
研究人員使用VoxCeleb2數(shù)據(jù)集對這個模型進(jìn)行了預(yù)訓(xùn)練,這是一個包含許多名人頭像的數(shù)據(jù)庫。在這個過程中,前面描述的過程是一樣的,但是這里的源圖像和目標(biāo)圖像只是同一視頻的不同幀。
因此,這個系統(tǒng)不是讓一幅畫去模仿視頻中的另一個人,而是有一個可以與之比較的ground truth。通過持續(xù)訓(xùn)練,直到生成的幀與訓(xùn)練視頻中的真實幀十分相似為止。
預(yù)訓(xùn)練階段允許模型在只有很少示例的輸入上工作。哪怕只有一張圖片可用時,結(jié)果也不會太糟,但當(dāng)有更多圖片可用時,結(jié)果會更加真實。
實驗和結(jié)果
研究人員使用2個數(shù)據(jù)集分別進(jìn)行定量和定性評估:VoxCeleb1數(shù)據(jù)集用于與基準(zhǔn)模型進(jìn)行比較,VoxCeleb2用于展示他們所提出方法的效果。
研究人員在三種不同的設(shè)置中將他們的模型與基準(zhǔn)模型進(jìn)行了比較,使用fine-tuning集中的1幀、8幀和32幀。
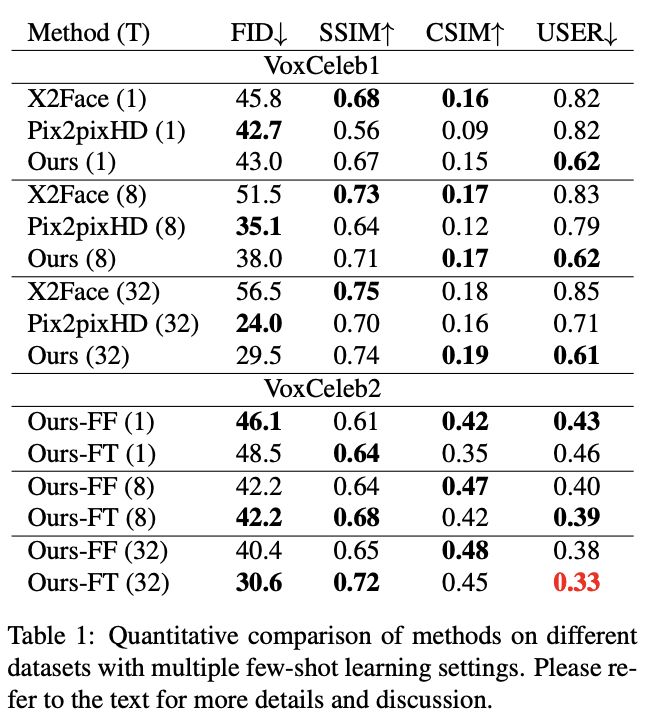
表1:few-shot learning設(shè)置下不同方法的定量比較
結(jié)果如表1上半部分所示,基線模型在兩個相似性度量上始終優(yōu)于我們的方法。
不過,這些指標(biāo)不能完全代表人類的感知,因為這兩種方法都會產(chǎn)生恐怖谷偽影,從圖3的定性比較和用戶研究結(jié)果可以看出。
另一方面,余弦相似度與視覺質(zhì)量有更好的相關(guān)性,但仍然傾向于模糊、不太真實的圖像,這也可以通過表1-Top與圖3中的比較結(jié)果看出。
圖3:使用1張、8張和32張訓(xùn)練圖像時的三個示例。系統(tǒng)采用一個源圖像(第1列),并嘗試將該圖像映射到ground truth幀中的相同位置(第2列)。研究人員將他們的結(jié)果與X2Face、PixtopixHD模型進(jìn)行了比較。
大規(guī)模的結(jié)果。
隨后,我們擴(kuò)展可用的數(shù)據(jù),并在更大的VoxCeleb2數(shù)據(jù)集中訓(xùn)練我們的方法。
下面是2個變體模型的結(jié)果:
圖4:在VoxCeleb2數(shù)據(jù)集中的最佳模型的結(jié)果。
同樣,訓(xùn)練幀的數(shù)量是T(左邊的數(shù)字),第1列是示例訓(xùn)練幀。第2列是ground truth圖像,后3列分別是我們的FF feed-forward 模型及微調(diào)前后的結(jié)果。雖然 feed-forward變體的學(xué)習(xí)更快速,但fine-tuning 最終提供了更好的真實感和保真度。
最后,我們展示了的照片和繪畫的結(jié)果。
圖5:讓靜態(tài)照片“活”起來
-
三星電子
+關(guān)注
關(guān)注
34文章
15885瀏覽量
182132 -
AI
+關(guān)注
關(guān)注
87文章
34223瀏覽量
275390
原文標(biāo)題:蒙娜麗莎一鍵“復(fù)活”!三星AI Lab:只需一張圖片就能合成動畫
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
回收三星S21指紋排線 適用于三星系列指紋模組
白光直接照到dmd上,透射一張白色圖片為什么會出現(xiàn)這么多顏色?
開關(guān)柜一鍵順控在一鍵停電、一鍵送電中的作用
DLP4500能否上傳一組圖片,然后給正向觸發(fā),每次觸發(fā)就投影一張圖片?
用DLP4500燒錄9張8bit位深度的相移圖,3張合成了一張24bit,結(jié)果每一張24bit都重復(fù)投射三次,這是為什么?
DLP4710一張張加載圖片顯示這個速度是否能夠更改?
DLP3010EVM-LC編輯固件時,選擇上電投影的splash,實際上電時總會先投影一張棋盤格圖片再投影設(shè)置的圖片,為什么?
UOS AI:一鍵解鎖未來辦公新姿勢
三星推出AI家電訂閱俱樂部計劃
一鍵斷電開關(guān)的種類有哪些
一鍵斷電開關(guān)的控制原理是什么
一鍵生成屬于自己的AI客服:開啟智能服務(wù)新時代
變電站一鍵順控系統(tǒng)和開關(guān)柜一鍵順控有區(qū)別嗎?
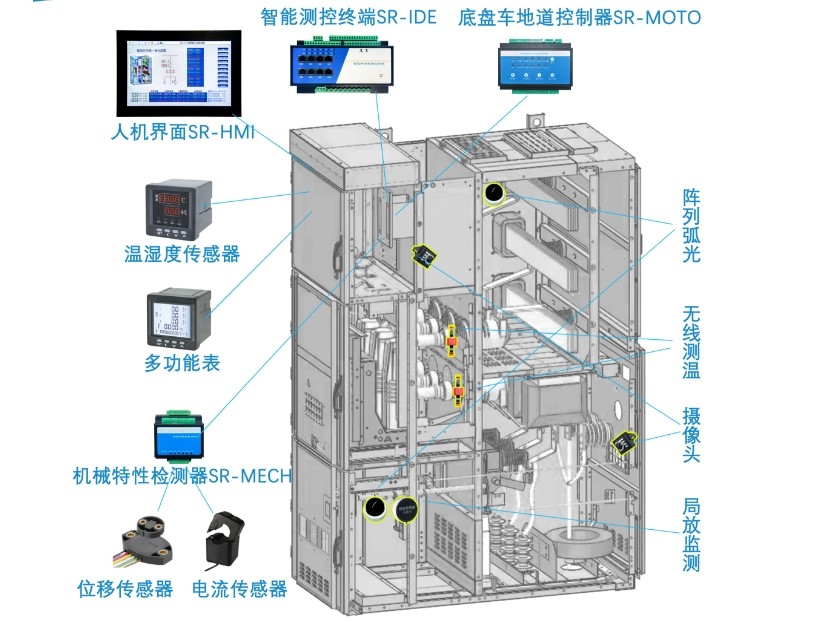
智能開關(guān)柜能如何實現(xiàn)“可視化一鍵順控”?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論