 一個可以生成欺騙性補丁的系統模型,人們能夠使自己在行人檢測器中獲得“隱身”的效果
一個可以生成欺騙性補丁的系統模型,人們能夠使自己在行人檢測器中獲得“隱身”的效果
【導語】本文介紹了一個可以生成欺騙性補丁的系統模型,通過將該補丁放置在固定位置,人們能夠使自己在行人檢測器中獲得“隱身”的效果。作者對比了三個不同的生成補丁的方法,并在實際場景中進行了評估,發現基于最小化目標分數的方法產生的補丁表現最優。
在過去幾年中,機器學習中的對抗攻擊方向吸引了越來越多的研究者。僅需要對卷積神經網絡的輸入進行細微的改變,模型就會被擾動,然后輸出完全不同的結果。一種攻擊方式是通過輕微改變輸入圖像的像素值來欺騙分類器,使其輸出錯誤的類。其他的方法則是試圖學習一個“補丁” (patches),這個補丁可以應用于某個對象去欺騙檢測器和分類器。其中的一些方法的確成功地欺騙了分類器和檢測器,這種欺騙性攻擊在現實生活中也是可行的。但是,現有方法都是針對幾乎沒有類內變化的目標(例如停止標志)。對于此類目標,常用的方法為使用對象的已知結構在其上生成一個對抗性補丁。
在本文中,作者提出了一種方法,它可以針對具有許多類內變化的目標生成對抗補丁,比如人。本文的目標是生成能夠成功地將行人隱藏在行人檢測器中的補丁。例如,入侵者可以通過在他們的身體前方拿著一塊小紙板,繞過監視系統。
從本文的實驗結果可以看到,該系統能夠顯著降低行人檢測器的準確性。當使用攝像頭時,其方法在現實生活場景中也能很好地運行。該文章是第一篇對類內變化較多的目標進行攻擊的研究。
圖1:論文算法創建的一個能夠成功躲避行人檢測器的對抗補丁。 左:成功檢測到沒有補丁的人。 右:持有補丁的人未被檢測到。
卷積神經網絡(CNNs)的興起在計算機視覺領域取得了巨大成功。 CNN在圖像數據中進行端到端的學習在各種計算機視覺任務中都獲得最佳結果。由于這些網絡結構的深度,神經網絡能夠從網絡底部(數據進入的地方)學習到非常基本的過濾器特征,并在網絡頂部學習出非常抽象的高級特征。典型的CNN結構往往包含數百萬個學習參數。雖然這種方法可以得到非常精確的模型,但模型的可解釋性卻大大降低。人們很難準確理解網絡將人的圖像分類為人的原因。通過對很多人類圖像的學習,神經網絡能夠了解了一個人看起來是什么樣子的。我們可以通過比較模型的輸出與人類注釋的圖像,來評估模型對行人檢測的效果。然而,以這種方式評估模型僅告訴我們檢測器在某個測試集上的執行情況。并且,測試集通常不包含誘導模型進行錯誤判斷的樣例,也不包含專門欺騙模型的樣例。對于不太可能發生攻擊的應用程序(例如老年人的跌倒檢測),這個問題無可厚非,但在安全系統中可能會帶來問題。安全系統的人員檢測模型中的漏洞可能被用于繞過建筑物中的監視攝像機。
該文章對人類檢測系統遭受攻擊的風險進行了探討。作者創造了一個小的(40厘米×40厘米)對抗性補丁(adverserial patch),用于使人躲過目標檢測器的檢測。演示如圖1所示。
工作簡述
已有的基于CNN的對抗攻擊主要針對分類任務、面部識別和物體探測。對于分類任務的攻擊,Szegedy等人的研究較為成功,他們通過給圖像進行輕微的像素調整,使得模型將圖像歸為錯誤的分類,而這種像素調整對于人眼來說是無法分辨的。在關于面部識別攻擊的研究中,Sharif等人使用印刷的眼鏡圖像騙過了人臉識別系統。
現有的物體檢測模型主要包括FCN和Faster-RCNN兩種,一些研究嘗試對上述兩種模型進行欺騙和攻擊。Chen等人利用交通標志中的停止標志,嘗試對Faster-RCNN這一物體探測模型進行欺騙,并獲得了成功。但是,已有的工作主要是針對沒有類內變化的目標。對適用于類間變化大的類的目標攻擊方法的探討是較少的。
在現有的攻擊算法中,主要包括白盒攻擊和黑盒攻擊兩種。其中,使用黑盒攻擊的攻擊者不了解模型的具體參數和算法,僅通過觀察模型的輸入和輸出進行攻擊。而白盒攻擊的攻擊者對模型結構、參數都較為了解,可以直接對模型進行針對性的攻擊。無論是黑盒攻擊還是白盒攻擊,都可以用于生成針對模型的對抗性樣本,使得樣本對模型具有欺騙性。
方法
這項工作的目標是創建一個能夠生成可打印的對抗補丁的系統,該補丁可用于欺騙行人檢測器。已有研究表明,對現實世界中的物體探測器進行對抗性攻擊是可能的。在這項工作中,作者專注于為人生成對抗性補丁。 本文通過圖像像素的優化過程,嘗試在大型數據集上找到能夠有效降低行人檢測的準確率的補丁。在下面的部分中,作者深入解釋了生成這些對抗補丁的過程。
優化目標主要包含三部分:
不可打印性得分公式,這個表示補丁中的顏色可以進行普通打印的程度

圖像的總變化度,該函數確保優化器支持顏色過渡更加平緩的圖像,并能防止噪聲圖像。如果相鄰像素值的顏色相似,該分數就低,相鄰像素值的顏色差異大,該分數就高。
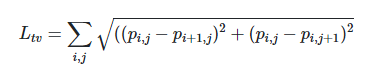
Lobj是圖像中的最大目標分數。該補丁的目標是隱藏圖像中的人,因此,模型的訓練目標是最小化檢測器輸出的物體或類別分數。
總損失函數由上面三部分內容構成。在計算時引入了縮放因子alpha和beta。模式使用的優化算法為Adam優化。針對Lobj的計算,可以參考圖2.
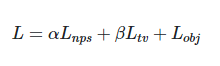
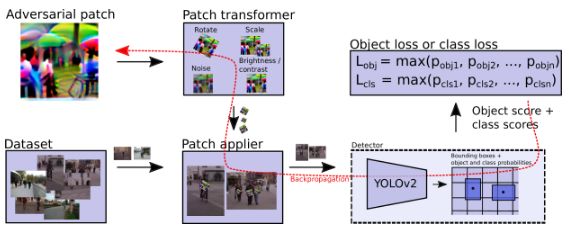
圖2:獲取目標損失的概述
最小化檢測器的輸出概率
為了讓檢測器不能檢測出人,作者嘗試了三種不同的方法:一是僅最小化人這一類別的分類概率,二是僅最小化目標分數,三是結合著兩者同時進行。通過第一種方法學到的補丁在視覺上類似于泰迪熊,由于補丁使得人類圖像看起來類似于另一分類,其結果很難遷移到不包含該分類的模型中。另一種最小化目標分數的方法則不存在這種問題。
訓練數據
與之前為交通標志生成對抗補丁的研究相比,為人創建對抗補丁更有挑戰性:
人的外表變化很大:衣服,膚色,身材,姿勢......與始終具有相同八角形狀且通常是紅色的停車標志不同。
人可以出現在許多不同的背景中。 而停車標志大多出現在街道一側的相同環境中。
當人是朝向或者背對攝像頭時,人的外觀會有所不同。
在人身上放置補丁沒有一致的位置。而在停止標志上,可以很容易地計算出補丁的確切位置。
為應對上述挑戰,作者沒有像已有研究那樣人工修改目標對象的單個圖像并進行不同的變換,二是使用了很多人的真實圖像進行訓練。在模型的訓練中,具體步驟如下:首先在圖像數據集上運行目標人物檢測器。探測器會根據人在圖像中出現的位置顯示人的邊界框。然后,作者將經過多種變換的補丁應用于圖像中,補丁與邊界狂的相對位置是固定不變的。之后,作者將得到的圖像與其他圖像一起批量送入檢測器,并基于仍然被檢測到人的圖像計算損失函數。最后,在整個模型中進行反向傳播,使用優化器進一步更改補丁中的像素,以便能更好的欺騙檢測器。
上述方法的一個優勢為,模型可使用的數據集不僅限于已標注的數據集。目標檢測器可以對任何視頻或圖像集合生成邊界框,這使得系統可以進行更有針對性的攻擊。當模型從定位的環境中獲得數據時,可以簡單地使用該素材生成特定于該場景的補丁。
模型的測試使用了Inria 數據集的圖像。這些圖像主要是行人的全身圖像,更適用于監控攝像頭的應用。另外,MS COCO 和Pascal VOC 也是兩個關于行人的數據集,但它們包含太多種類的人(例如一只手被注釋為人),很難固定補丁的放置位置,因此沒有使用。
使補丁具有更高的魯棒性
本文的目標是針對必須在現實世界中使用的補丁。這意味著首先需要將這些布丁打印出來,然后由攝像機對其進行拍攝。在進行上述處理時,很多因素都會影響補丁的外觀:光線可能會發生變化,補丁可能會稍微旋轉,補丁相對于人的大小會發生變化,相機可能會稍微增加噪點或模糊補丁,視角可能不同......為了盡可能地考慮這一點,在將補丁應用到圖像之前,作者對補丁進行一些轉換。作者主要進行了以下隨機轉換,用于數據增強:
將補丁單向旋轉20度
隨機放大和縮小補丁
在補丁上添加隨機噪聲
隨機改變補丁的亮度和對比度
需要強調的是,在對補丁進行隨機更改的過程中,必須保證可以上述操作進行反向傳播。
實驗結果
在本節中,作者對補丁的有效性進行了評估。評估使用的數據集是Inria數據集的測試集,對補丁的評估過程與訓練過程相同,并且包含了對補丁的隨機轉換。在實驗中,作者試圖使一些有可能把人隱藏起來的參數達到其最小值。作為對照,作者還將結果與包含隨機噪聲的補丁進行了比較,該補丁的評估方式與隨機補丁的評估完全相同。圖3顯示了不同補丁的結果。 OBJ-CLS的目標是最小化目標得分和類得分的乘積,在OBJ中僅最小化目標得分,在CLS中僅最小化類得分。NOISE是用于對比的包含隨機噪聲的補丁,CLEAN是沒有應用補丁的試驗基線。 從這條PR曲線,我們可以清楚地看到生成的補丁(OBJ-CLS,OBJ和CLS)與隨機生成的補丁的效果對比。我們還可以看到,與使用類分數相比,最小化目標分數(OBJ)帶來的影響最大(即具有最低的平均準確度(AP))。

圖3:與隨機噪聲補丁(NOISE)和原始圖像(CLEAN)相比,不同方法下(OBJ-CLS,OBJ和CLS)的PR曲線。
作者對于在現實情況中補丁的的效果也進行了檢驗,在大多數情況下補丁都能成功欺騙行人檢測器。由于在模型的訓練中,補丁相對于邊界框的位置使固定的,因此補丁放置的位置會對模型效果產生一定影響。
結論
在本文中,作者提出了一個可生成行人檢測器對抗補丁的系統,該系統生成的補丁可以打印出來并在現實世界中使用。作者在實驗中對比了不同的補丁生成方法,并發現最小化目標損失能產生最有效的補丁。
從文中對打印出來的補丁在真實世界中的測試實驗中可以發現,該系統產生的補丁非常適用于欺騙行人檢測器,這表明使用類似檢測器的安全系統可能易受到這種攻擊。
作者還提到,如果將這種技術與衣服結合起來,就可以設計出一種T恤印花,讓穿上這種衣服的人能成功的躲避使用YOLO檢測器的智能攝像頭。
在未來,作者希望在以下方面進一步探討此問題。一是通過對輸入數據進行更多(仿射)變換或使用模擬數據,進一步提高補丁生成系統的魯棒性。 二是嘗試提高模型的遷移能力。該系統產生的補丁尚不能很好地遷移到完全不同的模型結構中,作者希望在未來通過使用多種結構的模型進行訓練,來提高遷移能力。
-
檢測器
+關注
關注
1文章
888瀏覽量
48470 -
神經網絡
+關注
關注
42文章
4810瀏覽量
102972 -
圖像
+關注
關注
2文章
1094瀏覽量
41068
原文標題:小樣,加張圖你就不認識我了?“補丁”模型騙你沒商量!| 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用OpenVINO?模型的OpenCV進行人臉檢測,檢測到多張人臉時,伺服電機和步入器電機都發生移動是為什么?
快速部署!米爾全志T527開發板的OpenCV行人檢測方案指南
基于稀疏編碼的遷移學習及其在行人檢測中的應用
基于邊緣計算的全球定位系統欺騙檢測方法

使用2×4 MIMO-OFDM系統模型下的K-Best算法設計的K-Best檢測器
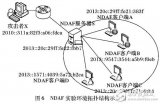
基于網絡欺騙的操作系統抗識別模型NDAF





 工商網監
工商網監
評論