 了解一下GBDT和LR的融合方案
了解一下GBDT和LR的融合方案
寫在前面的話
GBDT和LR的融合在廣告點擊率預估中算是發展比較早的算法,為什么會在這里寫這么一篇呢?本來想嘗試寫一下阿里的深度興趣網絡(Deep Interest Network),發現阿里之前還有一個算法MLR,然后去查找相關的資料,里面提及了樹模型也就是GBDT+LR方案的缺點,恰好之前也不太清楚GBDT+LR到底是怎么做的,所以今天我們先來了解一下GBDT和LR的融合方案。
在CTR預估問題的發展初期,使用最多的方法就是邏輯回歸(LR),LR使用了Sigmoid變換將函數值映射到0~1區間,映射后的函數值就是CTR的預估值。
LR屬于線性模型,容易并行化,可以輕松處理上億條數據,但是學習能力十分有限,需要大量的特征工程來增加模型的學習能力。但大量的特征工程耗時耗力同時并不一定會帶來效果提升。因此,如何自動發現有效的特征、特征組合,彌補人工經驗不足,縮短LR特征實驗周期,是亟需解決的問題。
FM模型通過隱變量的方式,發現兩兩特征之間的組合關系,但這種特征組合僅限于兩兩特征之間,后來發展出來了使用深度神經網絡去挖掘更高層次的特征組合關系。但其實在使用神經網絡之前,GBDT也是一種經常用來發現特征組合的有效思路。
Facebook 2014年的文章介紹了通過GBDT解決LR的特征組合問題,隨后Kaggle競賽也有實踐此思路,GBDT與LR融合開始引起了業界關注。
在介紹這個模型之前,我們先來介紹兩個問題:
1)為什么要使用集成的決策樹模型,而不是單棵的決策樹模型:一棵樹的表達能力很弱,不足以表達多個有區分性的特征組合,多棵樹的表達能力更強一些。可以更好的發現有效的特征和特征組合
2)為什么建樹采用GBDT而非RF:RF也是多棵樹,但從效果上有實踐證明不如GBDT。且GBDT前面的樹,特征分裂主要體現對多數樣本有區分度的特征;后面的樹,主要體現的是經過前N顆樹,殘差仍然較大的少數樣本。優先選用在整體上有區分度的特征,再選用針對少數樣本有區分度的特征,思路更加合理,這應該也是用GBDT的原因。
了解了為什么要用GBDT,我們就來看看到底二者是怎么融合的吧!
GBDT和LR的融合方案,FaceBook的paper中有個例子:

圖中共有兩棵樹,x為一條輸入樣本,遍歷兩棵樹后,x樣本分別落到兩顆樹的葉子節點上,每個葉子節點對應LR一維特征,那么通過遍歷樹,就得到了該樣本對應的所有LR特征。構造的新特征向量是取值0/1的。舉例來說:上圖有兩棵樹,左樹有三個葉子節點,右樹有兩個葉子節點,最終的特征即為五維的向量。對于輸入x,假設他落在左樹第一個節點,編碼[1,0,0],落在右樹第二個節點則編碼[0,1],所以整體的編碼為[1,0,0,0,1],這類編碼作為特征,輸入到LR中進行分類。
這個方案還是很簡單的吧,在繼續介紹下去之前,我們先介紹一下代碼實踐部分。
本文介紹的代碼只是一個簡單的Demo,實際中大家需要根據自己的需要進行參照或者修改。
github地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/GBDT%2BLR-Demo
訓練GBDT模型本文使用lightgbm包來訓練我們的GBDT模型,訓練共100棵樹,每棵樹有64個葉子結點。
df_train=pd.read_csv('data/train.csv')df_test=pd.read_csv('data/test.csv')NUMERIC_COLS=["ps_reg_01","ps_reg_02","ps_reg_03","ps_car_12","ps_car_13","ps_car_14","ps_car_15",]print(df_test.head(10))y_train=df_train['target']#traininglabely_test=df_test['target']#testinglabelX_train=df_train[NUMERIC_COLS]#trainingdatasetX_test=df_test[NUMERIC_COLS]#testingdataset#createdatasetforlightgbmlgb_train=lgb.Dataset(X_train,y_train)lgb_eval=lgb.Dataset(X_test,y_test,reference=lgb_train)params={'task':'train','boosting_type':'gbdt','objective':'binary','metric':{'binary_logloss'},'num_leaves':64,'num_trees':100,'learning_rate':0.01,'feature_fraction':0.9,'bagging_fraction':0.8,'bagging_freq':5,'verbose':0}#numberofleaves,willbeusedinfeaturetransformationnum_leaf=64print('Starttraining...')#traingbm=lgb.train(params,lgb_train,num_boost_round=100,valid_sets=lgb_train)print('Savemodel...')#savemodeltofilegbm.save_model('model.txt')print('Startpredicting...')#predictandgetdataonleaves,trainingdata
特征轉換
在訓練得到100棵樹之后,我們需要得到的不是GBDT的預測結果,而是每一條訓練數據落在了每棵樹的哪個葉子結點上,因此需要使用下面的語句:
y_pred=gbm.predict(X_train,pred_leaf=True)
打印上面結果的輸出,可以看到shape是(8001,100),即訓練數據量*樹的棵樹
結果為:
print(np.array(y_pred).shape)print(y_pred[0])
然后我們需要將每棵樹的特征進行one-hot處理,如前面所說,假設第一棵樹落在43號葉子結點上,那我們需要建立一個64維的向量,除43維之外全部都是0。因此用于LR訓練的特征維數共num_trees * num_leaves。
print('Writingtransformedtrainingdata')transformed_training_matrix=np.zeros([len(y_pred),len(y_pred[0])*num_leaf],dtype=np.int64)#N*num_tress*num_leafsforiinrange(0,len(y_pred)):temp=np.arange(len(y_pred[0]))*num_leaf+np.array(y_pred[I])transformed_training_matrix[i][temp]+=1
當然,對于測試集也要進行同樣的處理:
y_pred=gbm.predict(X_test,pred_leaf=True)print('Writingtransformedtestingdata')transformed_testing_matrix=np.zeros([len(y_pred),len(y_pred[0])*num_leaf],dtype=np.int64)foriinrange(0,len(y_pred)):temp=np.arange(len(y_pred[0]))*num_leaf+np.array(y_pred[I])transformed_testing_matrix[i][temp]+=1
LR訓練然后我們可以用轉換后的訓練集特征和label訓練我們的LR模型,并對測試集進行測試:
lm=LogisticRegression(penalty='l2',C=0.05)#logesticmodelconstructionlm.fit(transformed_training_matrix,y_train)#fittingthedatay_pred_test=lm.predict_proba(transformed_testing_matrix)#Givetheprobabiltyoneachlabel
我們這里得到的不是簡單的類別,而是每個類別的概率。
效果評價在Facebook的paper中,模型使用NE(Normalized Cross-Entropy),進行評價,計算公式如下:

代碼如下:
NE=(-1)/len(y_pred_test)*sum(((1+y_test)/2*np.log(y_pred_test[:,1])+(1-y_test)/2*np.log(1-y_pred_test[:,1])))print("NormalizedCrossEntropy"+str(NE))
現在的GBDT和LR的融合方案真的適合現在的大多數業務數據么?現在的業務數據是什么?是大量離散特征導致的高維度離散數據。而樹模型對這樣的離散特征,是不能很好處理的,要說為什么,因為這容易導致過擬合。下面的一段話來自知乎:

用蓋坤的話說,GBDT只是對歷史的一個記憶罷了,沒有推廣性,或者說泛化能力。
但這并不是說對于大規模的離散特征,GBDT和LR的方案不再適用,感興趣的話大家可以看一下參考文獻2和3,這里就不再介紹了。
剛才提到了阿里的蓋坤大神,他的團隊在2017年提出了兩個重要的用于CTR預估的模型,MLR和DIN,之后的系列中,我們會講解這兩種模型的理論和實戰!歡迎大家繼續關注!
1、Facebook的paper:http://quinonero.net/Publications/predicting-clicks-facebook.pdf2、http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm3、https://blog.csdn.net/shine19930820/article/details/717136804、https://www.zhihu.com/question/358215665、https://github.com/neal668/LightGBM-GBDT-LR/blob/master/GBFT%2BLR_simple.py
-
神經網絡
+關注
關注
42文章
4809瀏覽量
102831 -
LR
+關注
關注
1文章
8瀏覽量
10160 -
GBDT
+關注
關注
0文章
13瀏覽量
4027
原文標題:推薦系統遇上深度學習(十)--GBDT+LR融合方案實戰
文章出處:【微信號:atleadai,微信公眾號:LeadAI OpenLab】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
USB顯微鏡,不想了解一下嗎?
GBDT算法原理以及實例理解
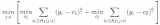
帶你了解一下什么是USB 3.1接口
邏輯回歸與GBDT模型各自的原理及優缺點

GBDT是如何用于分類的
了解一下不同的SAR ADC可用模擬輸入類型資料下載










 工商網監
工商網監
評論