 OpenAI發布Neural MMO—一個強化學習的大型多智能體游戲環境
OpenAI發布Neural MMO—一個強化學習的大型多智能體游戲環境
今日凌晨,OpenAI發布Neural MMO—一個強化學習的大型多智能體游戲環境。這一平臺可以在持久性和開放式任務中支持大量可變數量的智能體。
一直以來,人工智能研究者都希望讓智能體(agent)學會合作競爭,一些研究者也認為這是實現通用人工智能(AGI)的必要條件。
17年7月份,OpenAI、麥吉爾大學和 UC Berkeley 聯合提出了一種“用于合作-競爭混合環境的多智能體 actor-critic”,可用于多智能體環境中的中心化學習(centralized learning)和去中心化執行(decentralized execution),讓智能體可以學會彼此合作和競爭。
論文地址:
https://arxiv.org/pdf/1706.02275.pdf
之后,OpenAI也一直沒有放棄對多智能體學習環境的探索。
今日凌晨,OpenAI宣稱發布Neural MMO——一個強化學習的大型多智能體游戲環境。這一多智能體的環境可以探索更兼容和高效的整體環境,力求在復雜度和智能體人數上獲取難得的平衡。
近年來,多重代理設置已成為深度強化學習研究的一個有效平臺。盡管進展頗豐,但其仍存在兩個主要挑戰:當前環境要么復雜但過于受限,要么開放但過于簡單。
其中,持久性和規模化將是探討的關鍵屬性,但研究者們還需要更好的基準測試環境,在存在大量人口規模和持久性的情況下量化學習進度。這一游戲類型(MMO:大型多人在線游戲)模擬了在持續和廣泛環境中可變數量玩家進行競爭的大型生態系統。
為了應對這些挑戰,OpenAI構建了神經MMO以滿足以下標準:
持久性:在沒有環境重置的情況下,代理可以在其他學習代理存在的情況下同時學習。策略必須具有遠見思維,并適應其他代理行為的潛在快速變化。
比例:環境支持大量且可變數量的實體。實驗考慮了100個并發服務器中每個服務器128個并發代理且長達100M的生命周期。
效率:進入的計算障礙很低。可以在單個桌面CPU上培訓有效的策略。
擴展:與現有MMO類似,Neural MMO旨在更新內容。目前的核心功能包括基于拼接單元塊(tile-based)的地形的程序生成,食物和水覓食系統以及戰略戰斗系統。未來有機會進行開源驅動的擴展。
OpenAI在博客中詳細介紹了這一新環境。
環境
玩家(代理)可以加入任何可用的服務器(環境),每個都會包含一個可配置大小、且自動生成的基于圖塊的游戲地圖。一些障礙塊,例如森林和草,是可穿越的;其他的如水和實心巖石,則不能穿越。
代理在環境邊緣的隨機位置產生。他們需要獲得食物和水,并避免其他代理的戰斗傷害,以維持自己的生存。踩在森林地塊上或出現在水資源地塊的旁邊會分別填充一部分代理的食物和水供應。然而,森林的食物供應有限,隨著時間的推移會緩慢再生。這意味著代理必須競爭食品塊,同時定期補充水源。玩家還可以使用三種戰斗風格參與戰斗,分別為混戰,游獵及魔法。
輸入:代理觀察以其當前位置為中心的方形區域。這包括地塊類型和占用代理的選擇屬性(健康,食物,水和位置)。
輸出:代理為下一個游戲單位時間(timestep)輸出操作選項。該操作由一個動作和一個攻擊組成。
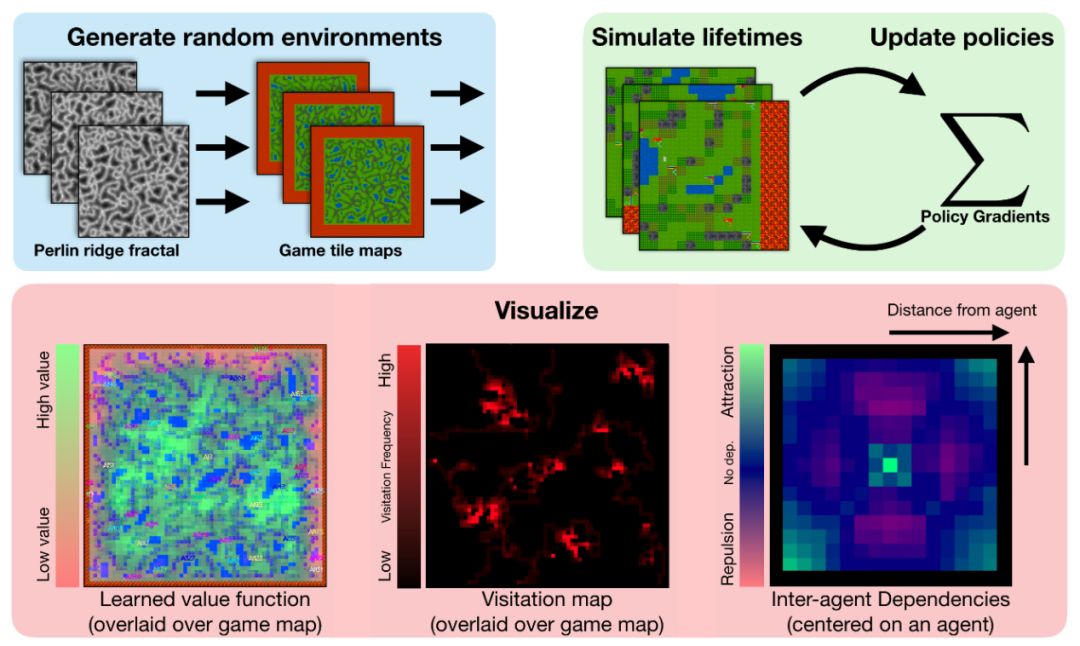
模型
作為一個簡單的基準,我們使用vanilla策略梯度訓練一個小型,完全連接的架構,并把值函數基準和獎勵折扣作為唯一的增強功能。在這個模型中,獎勵策略并不針對實現特定目標,而是針對其生命周期(軌跡長度)進行優化:他們在其生命周期的每個單位時間上獲得獎勵1。我們通過計算所有代理的最大值來將可變長度觀測值(例如周圍代理列表)轉換為單個長度向量(OpenAI Five也使用了這個技巧)。基于PyTorch和Ray,源版本包括我們完整分布式培訓的實現。
訓練中最大種群數量在(16,32,64,128)之間變化。為了提高效率,在測試時,將在一對實驗中學到的特定群進行合并,并在一個固定的范圍內進行評估。只對作戰策略進行評估,因為直接量化作戰策略比較困難。通常來說,在更大的分布范圍內進行訓練效果會更好。
代理的策略是從多個種群中簡單抽樣——不同種群中的代理共享體系結構,但只有相同種群中的代理共享權重。初步實驗表明,隨著多智能體相互作用的增加,智能體的能力也隨之增加。增加并發智能體的最大數量將放大探索行為;增加種群的數量將放大生態位形成——也就是說,種群在地圖的不同部分擴散和覓食的趨勢。
在評估跨多臺服務器的玩家能力方面,并沒有統一的標準。然而,有時,MMO服務器會進行合并。我們通過合并在不同服務器中訓練的玩家基地來實現“錦標賽”風格的評估。這使得我們可以直接比較在不同實驗環境中學到的策略。改變了測試時間范圍,發現在較大環境下訓練的代理一直優于在較小環境中訓練的代理。
評估結果
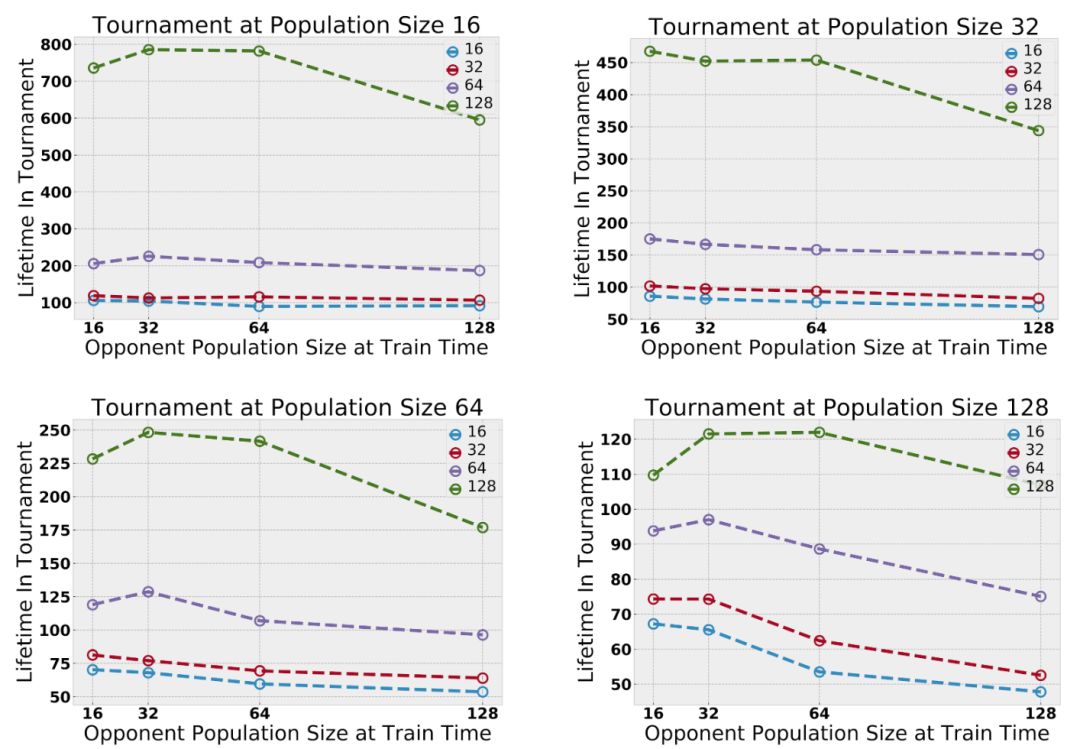
訓練中最大種群數量在(16,32,64,128)之間變化。為了提高效率,在測試時,將在一對實驗中學到的特定群進行合并,并在一個固定的范圍內進行評估。只對作戰策略進行評估,因為直接量化作戰策略比較困難。通常來說,在更大的分布范圍內進行訓練效果會更好。
代理的策略是從多個種群中簡單抽樣——不同種群中的代理共享體系結構,但只有相同種群中的代理共享權重。初步實驗表明,隨著多智能體相互作用的增加,智能體的能力也隨之增加。增加并發智能體的最大數量將放大探索行為;增加種群的數量將放大生態位形成——也就是說,種群在地圖的不同部分擴散和覓食的趨勢。
服務器合并條件下的錦標賽:多代理放大了競爭行為
在跨多臺服務器隊玩家能力的能力進行評估時,我們并沒有統一的標準。然而,有時MMO服務器會進行合并。我們通過合并在不同服務器中訓練的玩家基地來實現“錦標賽”風格的評估。這使得我們可以直接比較在不同實驗環境中學到的策略。改變了測試時間范圍后,我們發現,在較大環境下訓練的代理一直優于在較小環境中訓練的代理。
種群規模的增加放大了探索行為
種群規模放大了探索行為:代理表現出分散開來的特征以避免競爭。最后幾幀顯示學習值函數疊加。有關其他參數,請參閱論文:
https://s3-us-west-2.amazonaws.com/openai-assets/neural-mmo/neural-mmo-arxiv.pdf
在自然世界中,動物之間的競爭可以激勵它們分散開來以避免沖突。我們觀察到,隨著并發代理數量的增加,映射覆蓋率增加。代理學習探索僅僅是因為其他代理的存在提供了這樣做的自然動機。物種數量的增加擴大了生態位形成的幾率。
物種數量的增加擴大了生態位的形成。
物種數量(種群數量)放大了生態位的形成。上圖中訪問地圖覆蓋了游戲地圖;不同的顏色對應不同的物種。訓練單一物種傾向于產生單一的深度探索路徑。訓練八個物種則會導致許多較淺的探索路徑:種群擴散以避免物種之間的競爭。
鑒于環境足夠大且資源豐富,我們發現不同的代理群在地圖上呈現分散的特點,以避免隨著數量的增加與其他代理產生競爭。由于代理不能與自己種群中的其他代理競爭(即與他們共享權重的代理),他們傾向于尋找包含足夠資源來維持其種群數量的地圖區域。在DeepMind的并發多代理研究中也獨立地觀察到類似的效果。
并發多代理研究:
https://arxiv.org/abs/1812.07019
其他見解
每個方形圖顯示位于中心的代理對其周圍代理的存在的響應。我們在初始化和訓練早期展示覓食地圖;額外的依賴圖對應于覓食和戰斗的不同表述。
我們通過將代理固定在假設的地圖中心來對代理進行可視化。對于該代理可見的每個位置,我們將顯示在該位置有第二個代理時的值函數。
我們發現代理商在覓食和戰斗環境中,可以學習依賴于其他代理的策略。代理學習“插眼(bull’s eye)”行為時,在幾分鐘的訓練后就能更有效地開始覓食。當代理學習環境的戰斗力學時,他們開始適當地評估有效的接觸范圍和接近角度。
下一步
Neural MMO解決了之前基于游戲環境的兩個主要限制,但仍有許多尚未解決。這種Neural MMO在環境復雜性和人口規模之間盡力尋求平衡。OpenAI在設計這個環境時考慮了開源擴展,并為研究社區提供了基礎。
-
人工智能
+關注
關注
1804文章
48677瀏覽量
246354 -
智能體
+關注
關注
1文章
262瀏覽量
10953 -
強化學習
+關注
關注
4文章
269瀏覽量
11514
原文標題:OpenAI發布Neural MMO :大型多智能體游戲環境
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「零基礎開發AI Agent」閱讀體驗】操作實戰,開發一個編程助手智能體
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

詳解RAD端到端強化學習后訓練范式

OpenAI發布深度研究智能體功能
OpenAI將發布更智能GPT模型及AI智能體工具
OpenAI 發了一個支持 ESP32 的 Realtime API SDK
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊


螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
如何使用 PyTorch 進行強化學習
谷歌AlphaChip強化學習工具發布,聯發科天璣芯片率先采用
通過強化學習策略進行特征選擇





 工商網監
工商網監
評論