") 通過(guò)強(qiáng)化學(xué)習(xí)策略進(jìn)行特征選擇
通過(guò)強(qiáng)化學(xué)習(xí)策略進(jìn)行特征選擇
來(lái)源:DeepHub IMBA
特征選擇是構(gòu)建機(jī)器學(xué)習(xí)模型過(guò)程中的決定性步驟。為模型和我們想要完成的任務(wù)選擇好的特征,可以提高性能。
如果我們處理的是高維數(shù)據(jù)集,那么選擇特征就顯得尤為重要。它使模型能夠更快更好地學(xué)習(xí)。我們的想法是找到最優(yōu)數(shù)量的特征和最有意義的特征。
在本文中,我們將介紹并實(shí)現(xiàn)一種新的通過(guò)強(qiáng)化學(xué)習(xí)策略的特征選擇。我們先討論強(qiáng)化學(xué)習(xí),尤其是馬爾可夫決策過(guò)程。它是數(shù)據(jù)科學(xué)領(lǐng)域的一種非常新的方法,尤其適用于特征選擇。然后介紹它的實(shí)現(xiàn)以及如何安裝和使用python庫(kù)(FSRLearning)。最后再使用一個(gè)簡(jiǎn)單的示例來(lái)演示這一過(guò)程。
強(qiáng)化學(xué)習(xí):特征選擇的馬爾可夫決策問(wèn)題
強(qiáng)化學(xué)習(xí)(RL)技術(shù)可以非常有效地解決像游戲解決這樣的問(wèn)題。而強(qiáng)化學(xué)習(xí)的概念是基于馬爾可夫決策過(guò)程(MDP)。這里的重點(diǎn)不是要深入定義而是要大致了解它是如何運(yùn)作的,以及它如何對(duì)我們的問(wèn)題有用。
強(qiáng)化學(xué)習(xí)背后的想法是,代理從一個(gè)未知的環(huán)境開(kāi)始。采取行動(dòng)來(lái)完成任務(wù)。在代理在當(dāng)前狀態(tài)和他之前選擇的行為的作用下,會(huì)更傾向于選擇一些行為。在每到達(dá)一個(gè)新?tīng)顟B(tài)并采取行動(dòng)時(shí),代理都會(huì)獲得獎(jiǎng)勵(lì)。以下是我們需要為特征選擇而定義的主要參數(shù):狀態(tài)、行動(dòng)、獎(jiǎng)勵(lì)、如何選擇行動(dòng)首先,狀態(tài)是數(shù)據(jù)集中存在的特征的子集。例如,如果數(shù)據(jù)集有三個(gè)特征(年齡,性別,身高)加上一個(gè)標(biāo)簽,則可能的狀態(tài)如下:
[] --> Empty set
[Age], [Gender], [Height] --> 1-feature set
[Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set
[Age, Gender, Height] --> All-feature set
在一個(gè)狀態(tài)中,特征的順序并不重要,我們必須把它看作一個(gè)集合,而不是一個(gè)特征列表。
對(duì)于動(dòng)作,我們可以從一個(gè)子集轉(zhuǎn)到任何一個(gè)尚未探索的特性的子集。在特征選擇問(wèn)題中,動(dòng)作就是是選擇當(dāng)前狀態(tài)下尚未探索的特征,并將其添加到下一個(gè)狀態(tài)。以下是一些可能的動(dòng)作:
[Age] -> [Age, Gender]
[Gender, Height] -> [Age, Gender, Height]
下面是一個(gè)不可能動(dòng)作的例子:
[Age] -> [Age, Gender, Height]
[Age, Gender] -> [Age]
[Gender] -> [Gender, Gender]
我們已經(jīng)定義了狀態(tài)和動(dòng)作,還沒(méi)有定義獎(jiǎng)勵(lì)。獎(jiǎng)勵(lì)是一個(gè)實(shí)數(shù),用于評(píng)估狀態(tài)的質(zhì)量。
在特征選擇問(wèn)題中,一個(gè)可能的獎(jiǎng)勵(lì)是通過(guò)添加新特征而提高相同模型的準(zhǔn)確率指標(biāo)。下面是一個(gè)如何計(jì)算獎(jiǎng)勵(lì)的例子:
[Age] --> Accuracy = 0.65
[Age, Gender] --> Accuracy = 0.76
Reward(Gender) = 0.76 - 0.65 = 0.11
對(duì)于我們首次訪問(wèn)的每個(gè)狀態(tài),都會(huì)使用一組特征來(lái)訓(xùn)練一個(gè)分類器(模型)。這個(gè)值存儲(chǔ)在該狀態(tài)和對(duì)應(yīng)的分類器中,訓(xùn)練分類器的過(guò)程是費(fèi)時(shí)費(fèi)力的,所以我們只訓(xùn)練一次。因?yàn)榉诸惼鞑粫?huì)考慮特征的順序,所以我們可以將這個(gè)問(wèn)題視為圖而不是樹。在這個(gè)例子中,選擇“性別”作為模型的新特征的操作的獎(jiǎng)勵(lì)是當(dāng)前狀態(tài)和下一個(gè)狀態(tài)之間的準(zhǔn)確率差值。
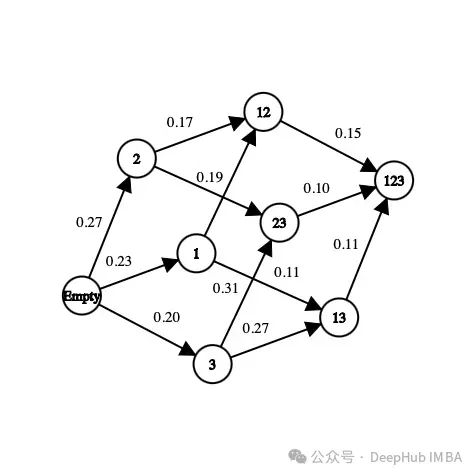
在上圖中,每個(gè)特征都被映射為一個(gè)數(shù)字(“年齡”為1,“性別”為2,“身高”為3)。我們?nèi)绾螐漠?dāng)前狀態(tài)中選擇下一個(gè)狀態(tài)或者我們?nèi)绾翁剿鳝h(huán)境呢?
我們必須找到最優(yōu)的方法,因?yàn)槿绻覀冊(cè)谝粋€(gè)有10個(gè)特征的問(wèn)題中探索所有可能的特征集,那么狀態(tài)的數(shù)量將是
10! + 2 = 3 628 802
這里的+2是因?yàn)榭紤]一個(gè)空狀態(tài)和一個(gè)包含所有可能特征的狀態(tài)。我們不可能在每個(gè)狀態(tài)下都訓(xùn)練一個(gè)模型,這是不可能完成的,而且這只是有10個(gè)特征,如果有100個(gè)特征那基本上就是無(wú)解了。
但是在強(qiáng)化學(xué)習(xí)方法中,我們不需要在所有的狀態(tài)下都去訓(xùn)練一個(gè)模型,我們要為這個(gè)問(wèn)題確定一些停止條件,比如從當(dāng)前狀態(tài)隨機(jī)選擇下一個(gè)動(dòng)作,概率為epsilon(介于0和1之間,通常在0.2左右),否則選擇使函數(shù)最大化的動(dòng)作。對(duì)于特征選擇是每個(gè)特征對(duì)模型精度帶來(lái)的獎(jiǎng)勵(lì)的平均值。
這里的貪心算法包含兩個(gè)步驟:
1、以概率為epsilon,我們?cè)诋?dāng)前狀態(tài)的可能鄰居中隨機(jī)選擇下一個(gè)狀態(tài)
2、選擇下一個(gè)狀態(tài),使添加到當(dāng)前狀態(tài)的特征對(duì)模型的精度貢獻(xiàn)最大。為了減少時(shí)間復(fù)雜度,可以初始化了一個(gè)包含每個(gè)特征值的列表。每當(dāng)選擇一個(gè)特性時(shí),此列表就會(huì)更新。使用以下公式,更新是非常理想的:
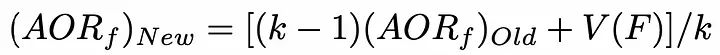
AORf:特征“f”帶來(lái)的獎(jiǎng)勵(lì)的平均值
K:f被選中的次數(shù)
V(F):特征集合F的狀態(tài)值(為了簡(jiǎn)單描述,本文不詳細(xì)介紹)
所以我們就找出哪個(gè)特征給模型帶來(lái)了最高的準(zhǔn)確性。這就是為什么我們需要瀏覽不同的狀態(tài),在在許多不同的環(huán)境中評(píng)估模型特征的最全局準(zhǔn)確值。
因?yàn)槟繕?biāo)是最小化算法訪問(wèn)的狀態(tài)數(shù),所以我們?cè)L問(wèn)的未訪問(wèn)過(guò)的狀態(tài)越少,需要用不同特征集訓(xùn)練的模型數(shù)量就越少。因?yàn)閺臅r(shí)間和計(jì)算能力的角度來(lái)看,訓(xùn)練模型以獲得精度是最昂貴方法,我們要盡量減少訓(xùn)練的次數(shù)。
最后在任何情況下,算法都會(huì)停止在最終狀態(tài)(包含所有特征的集合)而我們希望避免達(dá)到這種狀態(tài),因?yàn)橛盟鼇?lái)訓(xùn)練模型是最昂貴的。
上面就是我們針對(duì)于特征選擇的強(qiáng)化學(xué)習(xí)描述,下面我們將詳細(xì)介紹在python中的實(shí)現(xiàn)。
用于特征選擇與強(qiáng)化學(xué)習(xí)的python庫(kù)
有一個(gè)python庫(kù)可以讓我們直接解決這個(gè)問(wèn)題。但是首先我們先準(zhǔn)備數(shù)據(jù)
我們直接使用UCI機(jī)器學(xué)習(xí)庫(kù)中的數(shù)據(jù):
#Get the pandas DataFrame from the csv file (15 features, 690 rows)
australian_data = pd.read_csv('australian_data.csv', header=None)
#DataFrame with the features
X = australian_data.drop(14, axis=1)
#DataFrame with the labels
y = australian_data[14]
然后安裝我們用到的庫(kù)
pip install FSRLearning
直接導(dǎo)入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL類就可以創(chuàng)建一個(gè)特性選擇器。我們需要以下的參數(shù)
feature_number (integer): DataFrame X中的特性數(shù)量
feature_structure (dictionary): 用于圖實(shí)現(xiàn)的字典
eps (float [0;1]): 隨機(jī)選擇下一狀態(tài)的概率,0為貪婪算法,1為隨機(jī)算法
alpha (float [0;1]): 控制更新速率,0表示不更新?tīng)顟B(tài),1表示經(jīng)常更新?tīng)顟B(tài)
gamma (float[0,1]): 下一狀態(tài)觀察的調(diào)節(jié)因子,0為近視行為狀態(tài),1為遠(yuǎn)視行為
nb_iter (int): 遍歷圖的序列數(shù)
starting_state (" empty "或" random "): 如果" empty ",則算法從空狀態(tài)開(kāi)始,如果" random ",則算法從圖中的隨機(jī)狀態(tài)開(kāi)始
所有參數(shù)都可以機(jī)型調(diào)節(jié),但對(duì)于大多數(shù)問(wèn)題來(lái)說(shuō),迭代大約100次就可以了,而epsilon值在0.2左右通常就足夠了。起始狀態(tài)對(duì)于更有效地瀏覽圖形很有用,但它非常依賴于數(shù)據(jù)集,兩個(gè)值都可以測(cè)試。
我們可以用下面的代碼簡(jiǎn)單地初始化選擇器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
與大多數(shù)ML庫(kù)相同,訓(xùn)練算法非常簡(jiǎn)單:
results = fsrl_obj.fit_predict(X, y)
下面是輸出的一個(gè)例子:
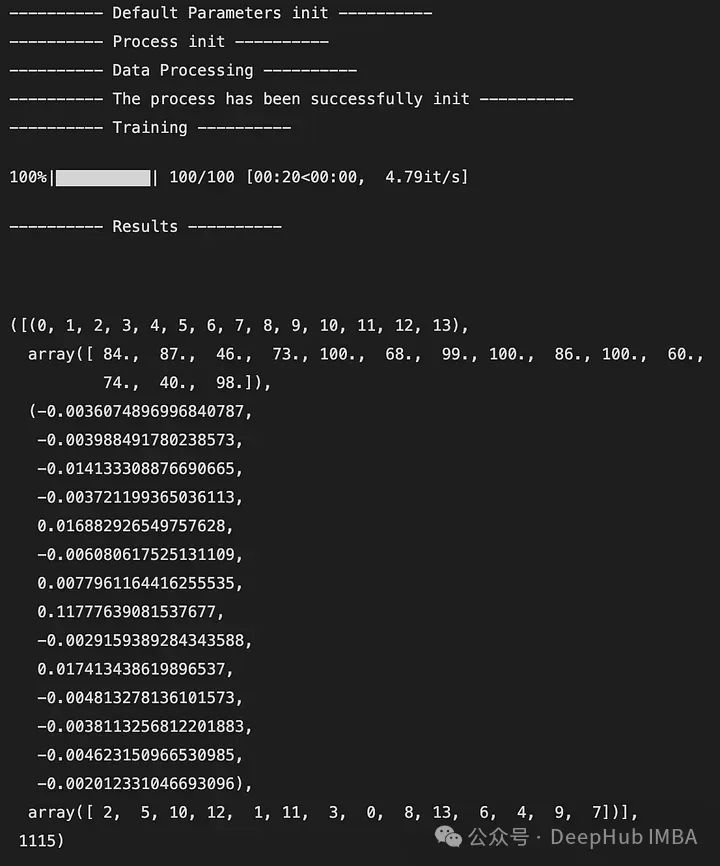
輸出是一個(gè)5元組,如下所示:
DataFrame X中特性的索引(類似于映射)
特征被觀察的次數(shù)
所有迭代后特征帶來(lái)的獎(jiǎng)勵(lì)的平均值
從最不重要到最重要的特征排序(這里2是最不重要的特征,7是最重要的特征)
全局訪問(wèn)的狀態(tài)數(shù)
還可以與Scikit-Learn的RFE選擇器進(jìn)行比較。它將X, y和選擇器的結(jié)果作為輸入。
fsrl_obj.compare_with_benchmark(X, y, results)
輸出是在RFE和FSRLearning的全局度量的每一步選擇之后的結(jié)果。它還輸出模型精度的可視化比較,其中x軸表示所選特征的數(shù)量,y軸表示精度。兩條水平線是每種方法的準(zhǔn)確度中值。
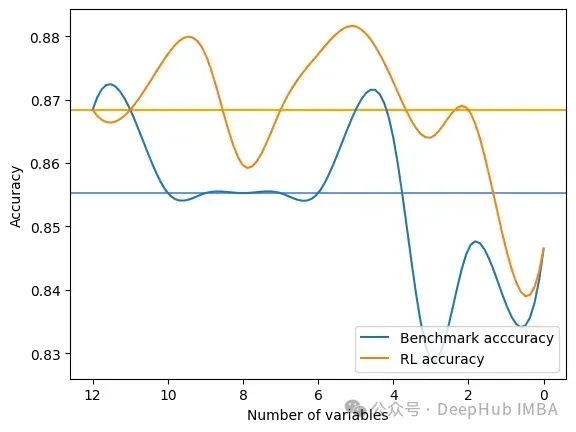
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909
Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579
Probability to get a set of variable with a better metric than RFE : 1.0
Area between the two curves : 0.17105263157894512
可以看到RL方法總是為模型提供比RFE更好的特征集。
另一個(gè)有趣的方法是get_plot_ratio_exploration。它繪制了一個(gè)圖,比較一個(gè)精確迭代序列中已經(jīng)訪問(wèn)節(jié)點(diǎn)和訪問(wèn)節(jié)點(diǎn)的數(shù)量。
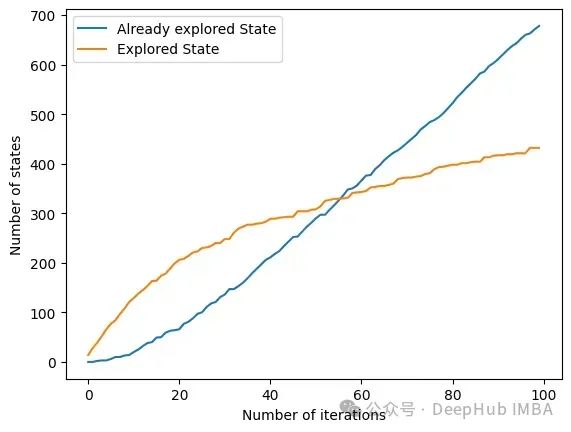
由于設(shè)置了停止條件,算法的時(shí)間復(fù)雜度呈指數(shù)級(jí)降低。即使特征的數(shù)量很大,收斂性也會(huì)很快被發(fā)現(xiàn)。下面的圖表示一定大小的集合被訪問(wèn)的次數(shù)。
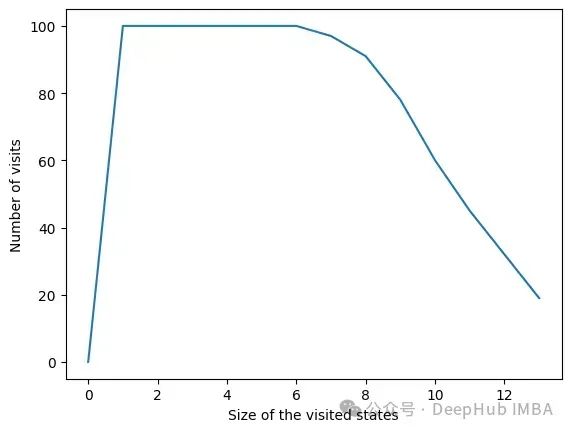
在所有迭代中,算法訪問(wèn)包含6個(gè)或更少變量的狀態(tài)。在6個(gè)變量之外,我們可以看到達(dá)到的狀態(tài)數(shù)量正在減少。這是一個(gè)很好的行為,因?yàn)橛眯〉奶卣骷?xùn)練模型比用大的特征集訓(xùn)練模型要快。
總結(jié)
我們可以看到RL方法對(duì)于最大化模型的度量是非常有效的。它總是很快地收斂到一個(gè)有趣的特性子集。該方法在使用FSRLearning庫(kù)的ML項(xiàng)目中非常容易和快速地實(shí)現(xiàn)。
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246344 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134067 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11514
發(fā)布評(píng)論請(qǐng)先 登錄
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
斯坦福提出基于目標(biāo)的策略強(qiáng)化學(xué)習(xí)方法——SOORL

什么是強(qiáng)化學(xué)習(xí)?純強(qiáng)化學(xué)習(xí)有意義嗎?強(qiáng)化學(xué)習(xí)有什么的致命缺陷?

如何使用深度強(qiáng)化學(xué)習(xí)進(jìn)行機(jī)械臂視覺(jué)抓取控制的優(yōu)化方法概述
對(duì)NAS任務(wù)中強(qiáng)化學(xué)習(xí)的效率進(jìn)行深入思考
深度強(qiáng)化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
強(qiáng)化學(xué)習(xí)在智能對(duì)話上的應(yīng)用介紹
機(jī)器學(xué)習(xí)中的無(wú)模型強(qiáng)化學(xué)習(xí)算法及研究綜述

模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

當(dāng)機(jī)器人遇見(jiàn)強(qiáng)化學(xué)習(xí),會(huì)碰出怎樣的火花?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論