 OpenAI發布的史上最強NLP似乎成了負面新
OpenAI發布的史上最強NLP似乎成了負面新
前幾日,OpenAI發布史上最強“通用”NLP模型,但號稱過于強大怕被濫用而沒有開源,遭到網友猛懟、炮轟。而做為創始人之一的馬斯克,雖然早已離開董事會,礙于輿論,不得不站出來做出澄清:我早已退出。
OpenAI發布的史上最強NLP似乎成了負面新聞。
原因是,OpenAI并沒有公布GPT-2模型及代碼,只是象征性的公布了一個僅含117M參數的樣本模型及代碼,給到的理由:因為這個模型能力太強大了!他們目前還有點hold不住它。一旦開源后被壞人拿到,將會貽害無窮。
之后有網友氣不過跑到馬斯克推特底下,叫罵OpenAI干脆改名CloseAI。
然而,馬斯克卻連發數文,澄清與OpenAI的關系:我早已退出。

馬斯克表示,已經有一年多的時間沒有和OpenAI密切合作了,并且也沒有管理層和董事會的監督。
而后有網友追問:“一直不知道你為何離開OpenAI,可否給予詳細的解釋說明?”
馬斯克便又在推特上補充道:
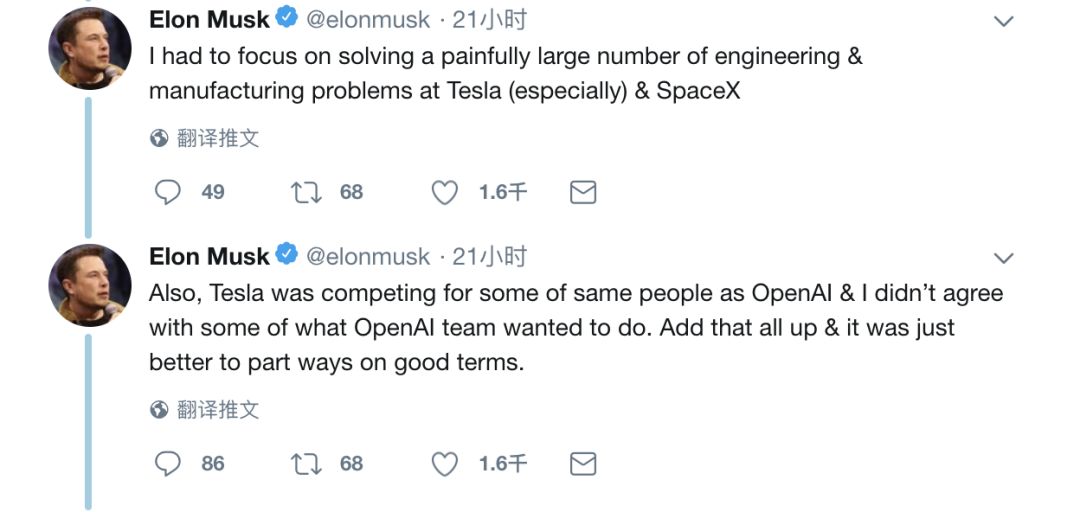
我必須集中精力解決大量讓人頭疼的工程和制造問題,尤其是在特斯拉和SpaceX方面。
此外,特斯拉與OpenAI在人才爭奪方面也有一些交集,我并不同意其團隊想要做的一些事情。綜上所述,希望最好是友好分手。
曾是人工智能的反對者,卻創立高端AI公司
2015年12月,馬斯克與Y Combinator總裁Sam Altman共同創立這個非營利組織研究機構,以研究人工智能的道德和安全問題。
然而,在親手創辦兩年多后,伊隆·馬斯克退出了OpenAI董事會。
雖然馬斯克于去年2月離開了該組織,但卻一直被認為是OpenAI主要資助者之一。

官博地址:
https://blog.openai.com/openai-supporters/
OpenAI在去年2月20日發布的官方博客中也提到:“馬斯克將離開OpenAI董事會,但仍將繼續為該組織提供捐贈和建議。隨著特斯拉將更加關注人工智能,這將消除馬斯克未來潛在的沖突。”
值得注意的是,馬斯克一直是人工智能最大的批評者之一。2014年在麻省理工學院演講時,他將人工智能描述為“存在的最大威脅”,甚至稱之為“召喚惡魔”。
他還認為人工智能甚至可以導致第三次世界大戰。他補充稱,大國之間都不會故意發動核戰爭,但人工智能將是最有可能的、先發制人的取勝之道。
OpenAI稱模型使用15億參數,訓練一小時相當于燒掉一臺iPhone Xs Max(512G)
馬斯克之所以被@出來說明一個問題:Elon離開OpenAI的消息,還有很多人不知道,或者知道他已經離開了董事會卻不知為何,導致他又特意出來發推澄清一下,順便又蹭了一下OpenAI最近的熱點。
OpenAI近日宣稱他們研究出一個GPT-2的NLP模型,號稱“史上最強通用NLP模型”,因為它是:
踩在15億參數的身體上:爬取了Reddit上點贊超過三票的鏈接的文本內容,大約用到1000萬篇文章,數據體量超過了40G,相當于35000本《白鯨記》。(注:小說約有21萬單詞,是電影《加勒比海盜》的重要故事參考來源之一。動漫《海賊王》里四皇之一的白胡子海賊團的旗艦就是以故事主角大白鯨的名字Moby Dick命名)。
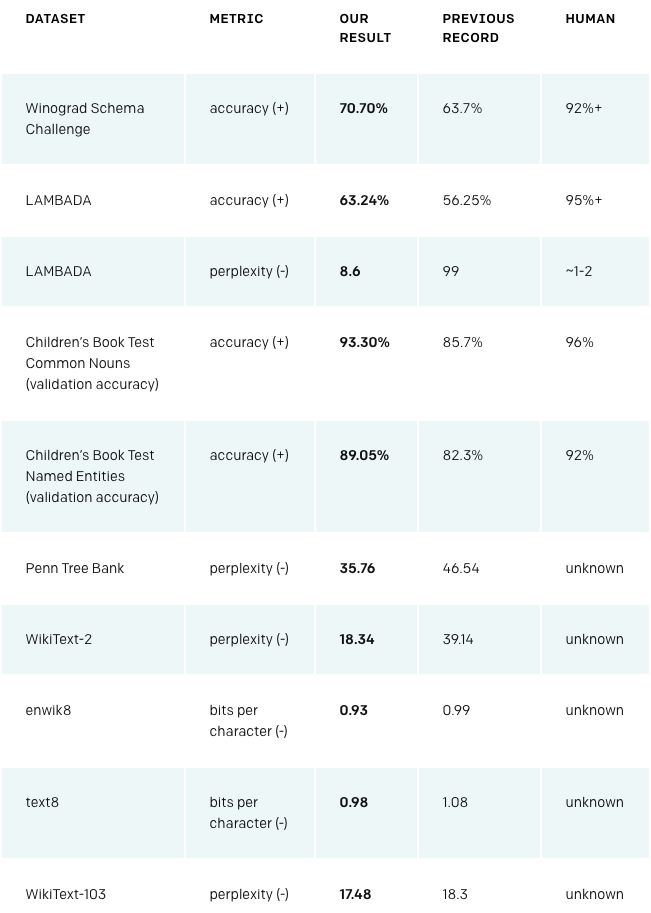
無需預訓練的“zero-shot”:在更通用的數據集基礎上,使用自注意力模塊遷移學習,不針對任何特定任務的數據進行訓練,只是作為最終測試對數據進行評估,在Winograd Schema、LAMBADA以及其他語言建模任務上實現了state-of-the-art 的結果。
最終結果:8個數據集中油7個刷新當前最佳紀錄。
下表顯示了最先進的zero-shot結果。(+)表示該項分數越高越好。(-)表示分數越低越好。
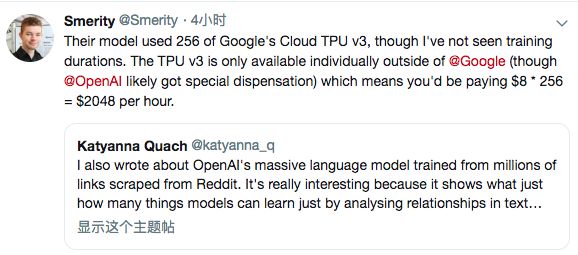
雖然OpenAI沒有在論文中提及具體的計算力及訓練時間,但通過公布的數據推測,他們的模型使用了256個谷歌云TPU v3。
TPU v3在Google之外只提供單獨使用版本(排除OpenAI可能得到了特別的許可),很可能GPT-2訓練時所需的成本將高達8 * 256 = 2048美元/小時,相當于一小時燒掉一臺512G的iPhone Xs Max。
然而,OpenAI并沒有公布GPT-2模型及代碼,只是象征性的公布了一個僅含117M參數的樣本模型及代碼,相當于他們宣稱使用的數據量的0.29%。(有興趣的讀者可以去 https://github.com/openai/gpt-2 查看)
OpenAI給出的理由是:因為這個模型能力太強大了!他們目前還有點hold不住它。一旦開源后被壞人拿到,將會貽害無窮。有點中國武俠小說里,絕世武功秘籍的意思。
面臨著實驗重現的危機,網友吐槽:不公開代碼和訓練集就干脆別發表!
于是開發者和學者們不干了,紛紛質疑OpenAI這種做法顯得心口不一。甚至盛產吐槽大神的Reddit上,有人建議OpenAI干脆改名CloseAI的言論,獲得了數百網友的點贊。
OpenAI干脆改名“CloseAI”算了!

我也做了個超強大的MNIST模型,要不要擔心它被濫用而不公開呢?

更有甚者,比如下面這位Ben Recht,還發了一條Twitter長文進行嘲諷:

今天我要介紹我們的論文“Do ImageNet Classifiers Generalize to ImageNet?”我們嘗試按照原論文描述復現其結果,但發現這樣做實在太難!
……我們完全可以基于一個不能公開的數據集構建一個超大模型,在我們自己的標準ML范式中很難發生過擬合。
但是,測試集上的一個微小改動就會導致分布結果大幅變化,你可以想見把模型和代碼全都公布出來以后會發生什么!
PS 這篇論文還在arxiv等候審核發布,要不是我們的最終版PDF過大,那就是因為arxiv也學著OpenAI的做法,覺得AI/ML研究太過危險而不能公開。
因為人工智能這個蓬勃發展的領域正面臨著實驗重現的危機,AI研究者發現他們很難重現許多關鍵的結果。
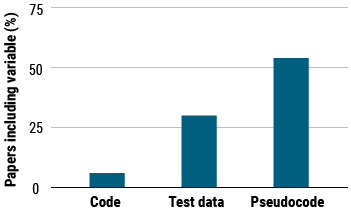
針對主要會議上發表的400篇AI論文的調查顯示,只有6%的論文包含算法的代碼,約30%包含測試數據,54%包含偽代碼。
CREDITS: (GRAPHIC) E. HAND/SCIENCE; (DATA) GUNDERSEN AND KJENSMO, ASSOCIATION FOR THE ADVANCEMENT OF ARTIFICIAL INTELLIGENCE 2018
去年,加拿大蒙特利爾大學的計算機科學家們希望展示一種新的語音識別算法,他們希望將其與一名著名科學家的算法進行比較。
唯一的問題:該benchmark的源代碼沒有發布。研究人員不得不從已公開發表的描述中重現這一算法。
但是他們重現的版本無法與benchmark聲稱的性能相符。蒙特利爾大學實驗室博士生Nan Rosemary Ke說:“我們嘗試了2個月,但都無法接近基準的性能。”
另外一群人更擔心GPT-2會導致假新聞出現井噴。OpenAI也拿DeepFake舉了個例子。
DeepFake由于其強大的圖像生成能力,成了一個“假臉生成器/換臉器”,制造出大量惡意的虛假視頻、音頻和圖像,最終被禁用。
比如這次,不懷好意的人完全可以借助GPT-2,發布有關Elon的假新聞,說他雖然公開宣稱去年就退出OpenAI,但實際上私下還在OpenAI身居要職,恐怕也會有很多人相信。
技術是把雙刃劍,越是強大的技術,一旦被用于壞用途,約可能造成更壞的結果。那么在這場意外掀起的激烈爭論中,你站在哪一邊呢?
-
人工智能
+關注
關注
1804文章
48737瀏覽量
246669 -
馬斯克
+關注
關注
1文章
851瀏覽量
21752 -
nlp
+關注
關注
1文章
490瀏覽量
22492
原文標題:史上最強AI被噴,馬斯克躺槍發推:我早就看不慣OpenAI
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
OpenAI發布o1大模型,數理化水平比肩人類博士,國產云端推理芯片的新藍海?
史上最強財報!小米2024年營收飆漲35%,2025年汽車交付超35萬輛

OpenAI即將發布GPT-4.5與GPT-5
OpenAI提交新商標的申請
OpenAI發布深度研究智能體功能
OpenAI世界最貴大模型:昂貴背后的技術突破
OpenAI發布滿血版ChatGPT Pro
OpenAI啟動12天新品發布盛宴







 工商網監
工商網監
評論