 谷歌大腦的“世界模型”簡述與啟發
谷歌大腦的“世界模型”簡述與啟發

摘要:我們的視覺看到什么,部分取決于大腦預測未來會看到什么。
我們的視覺看到什么,部分取決于大腦預測未來會看到什么,例如下圖中,如果你預計要看到突出的球體,那也許你就會看到,如果讓機器也具有了這樣的能力,會帶來什么了?
18年谷歌大腦提出“世界模型”(World Models)可以在復雜的環境中通過自我學習產生相應的策略,例如玩賽車游戲。
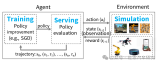
下面是世界模型的整體架構:

整個模型分為3個組件:視覺組件(V),記憶組件(M),控制組件(C)。視覺組件V用來壓縮圖片信息到一個隱變量z上(其實只是一個VAE編碼解碼器):
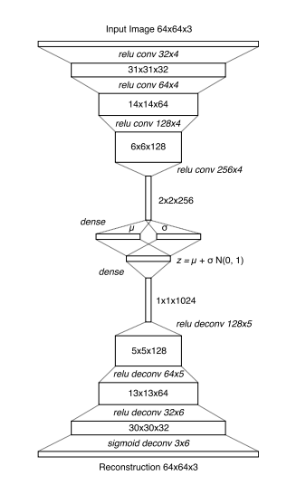
記憶組件M的輸入是一幀幀的游戲圖片(論文中的一幀圖像似乎叫一個rollout),輸出是預測下一幀圖像的可能分布,其實就是比一般LSTM更高級一些的MDN-RNN:
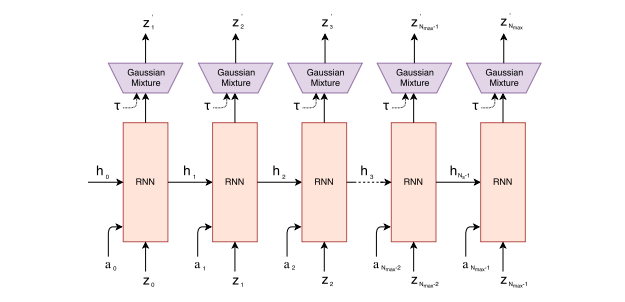
最后控制組件C的目標,就是把前面視覺組件V和記憶組件M的輸出一起作為輸入,并輸出這個時刻智能體agent應該做出的動作(action)。
在所謂的“世界模型”,其中的組件模型幾乎沒有是谷歌大腦自己創新研制的。但世界模型會很大提高強化學習訓練穩定性和成績 從而使其與其他強化學習相比有一些明顯優勢,如下表所示;

世界模型有如下的3個特點
1. 模型拼接得足夠巧妙,這個巧妙的拼接模型做到所謂的世界想象能力,就是模型在學習時,自身對環境假想一個模擬的環境,甚至可以在沒有環境訓練的情況下,自己想象一個環境去訓練。其實就是我們人類鏡像神經元的功能。

2. 抓住了一些“強視覺”游戲的“痛點”。記憶組件M中的RNN是生成序列的能手,所以根據之前游戲圖像再“想象”一些圖像幀應該不成問題(RNN生成一些隱變量z,再根據隱變量z,由視覺組件VAE的decode生成的圖像幀即可)。所以對于“強視覺”的游戲,把RNN的記憶能力用在視覺預測和控制上是個好主意 。
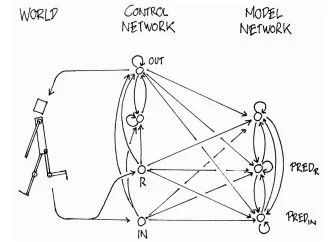
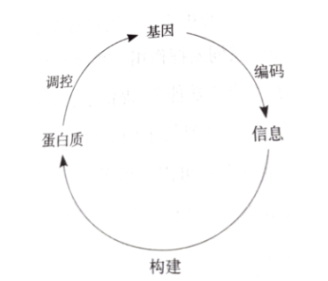
3不同于我們常見的“不可生”智能算法,例如遺傳算法和進化策略只是強調了基因的“變異”與在解空間中進行搜索,神經網絡只是固定網絡結構;而生物界的基因卻可以指導蛋白質構成并且“生長”。如果基因可以構造自身個體,外部環境和個體情況也可以反過來影響基因,而我們的模型都太固定呆板了,模型結構不能隨內部隱變量改進,當然最佳的設計形式也許誰也不知道。而世界模型做到了讓在內部”幻想“的環境中產生的策略轉移到外部世界中。
最后簡單看一下世界模型的訓練過程:
world models代碼基于chainer計算框架,步驟如下:
1. 準備數據集,隨機玩游戲生成訓練幀(rollouts意思應該就是多少幀):
python random_rollouts.py--gameCarRacing-v0 --num_rollouts10000
2. 訓練視覺組件V,即前面提到的VAE:
python vision.py--gameCarRacing-v0 --z_dim32--epoch1
3. 訓練記憶組件M,即前面提到的RNN:
python model.py--gameCarRacing-v0 --z_dim32--hidden_dim256--mixtures5--epoch20
4. 訓練控制組件C,即前面提到的CMA-ES算法(其實就是支持更復雜輸入和更新的ES):
python controller.py--gameCarRacing-v0 --lambda_64--mu0.25--trials16--target_cumulative_reward900--z_dim32--hidden_dim256--mixtures5--temperature1.0--weights_type1[--cluster_mode]
5. 測試訓練結果:
python test.py--gameCarRacing-v0 --z_dim32--hidden_dim256--mixtures5--temperature1.0--weights_type1--rollouts100[--record]
-
谷歌
+關注
關注
27文章
6231瀏覽量
108119 -
機器
+關注
關注
0文章
790瀏覽量
41281 -
智能體
+關注
關注
1文章
304瀏覽量
11078
原文標題:谷歌大腦的“世界模型”簡述與啟發
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動駕駛中常提的世界模型是個啥?
世界模型:多模態融合+因果推理,解鎖AI認知邊界
谷歌 Gemini 2.0 Flash 系列 AI 模型上新
英偉達推出基石世界模型Cosmos,解決智駕與機器人具身智能訓練數據問題
華為、理想、特斯拉、商湯的世界模型是做什么用的

英偉達發布Cosmos世界基礎模型
NVIDIA Cosmos世界基礎模型平臺發布
借助谷歌Gemini和Imagen模型生成高質量圖像

【「大模型啟示錄」閱讀體驗】對本書的初印象
谷歌發布Gemini 2.0 AI模型
OpenAI世界最貴大模型:昂貴背后的技術突破
Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
谷歌計劃12月發布Gemini 2.0模型
什么是大模型?快速了解大模型基本概念






 工商網監
工商網監
評論