 微軟亞洲研究院自然語言計算組全新力作
微軟亞洲研究院自然語言計算組全新力作
自然語言理解是AI皇冠上的明珠。在大數據、深度學習和云計算推動下,自然語言理解的各個領域都孕育著無窮的機會。這份書單介紹了兩本來自微軟亞洲研究院自然語言計算組的全新力作:《智能問答》和《機器翻譯》,分別對智能問答和機器翻譯這兩個具有廣泛應用場景的研究領域進行了系統性的介紹。
作為全球知名的研發機構,微軟亞洲研究院在自然語言處理方面一直有著獨特優勢。最近出版的《智能問答》和《機器翻譯》兩本技術著作凝結了微軟亞洲研究院在自然語言處理上的最新成果,獲得了業內諸多專家的好評和推薦。
本期書單向各位讀者重點介紹這兩本書。
推薦專家及推薦理由
自然語言處理是中文信息處理的重要技術,我很高興地看到,中國的自然語言處理在最近二十年取得了長足的進步。最新的深度學習進一步推動了本領域的發展。《智能問答》和《機器翻譯》兩本書詳細地介紹了最新的理論、方法和技術,是難得的技術參考書。
——李生
哈爾濱工業大學教授,原中國中文信息學會理事長
早在1991年,當比爾·蓋茨創建微軟研究院時,就提出過一個愿景:讓計算機能看會聽,并可理解人類的想法。從那時開始,自然語言處理和計算機視覺、語音和圖像識別等一直就是重要的研發方向。這兩本書體現了微軟亞洲研究院在自然語言處理方面的卓越進展。
——洪小文
微軟全球資深副總裁、微軟亞太研發集團主席、微軟亞洲研究院院長
兩本書分別系統地介紹了兩個領域的關鍵技術,深入淺出,理論與實踐完美結合,對有志于進入本領域學習的人士大有幫助。懂語言者得天下!
——沈向洋
微軟全球執行副總裁、微軟人工智能及研究事業部負責人
微軟是繼IBM深度問答系統問世以來率先從事開放式智能問答系統研究的著名團隊之一,而微軟亞洲研究院的機器翻譯團隊也是該領域全球最著名的團隊之一。《智能問答》和《機器翻譯》兩本書的作者就分別來自于這兩個團隊,我對他們的學術造詣深信不疑,并對他們在研究中做出的貢獻充滿自豪。
《智能問答》一書深入地介紹了不同類型的智能問答系統,對于其底層的深度學習理論和知識圖譜、語義表示做了深入淺出的闡述。《機器翻譯》一書深入地介紹了近三十年來得到階躍式發展的統計機器翻譯和神經機器翻譯的理論、方法和工具。鑒于兩本書的理論高度和實踐深度,它不僅可以作為大學本科和研究生的教科書使用,也定將會成為相關科研工作者和企業開發人員案頭常備的專業參考書。
——黃昌寧
國際著名NLP專家、清華大學NLP團隊和MSRA自然語言處理團隊創始人
第一本書:《智能問答》
內容簡介
作為搜索引擎和智能語音助手的核心功能,智能問答(Question Answering)近年來受到學術界和工業界的一致關注和深入研究,各種問答數據集和方法層出不窮。《智能問答》一書簡要回顧了該研究領域的發展歷史和背景知識,并在此基礎上系統介紹了包括知識圖譜問答、表格問答、文本問答、社區問答和問題生成在內的五個典型的問答任務。
全書共分為十個章節:第一章概述智能問答的歷史沿革、任務分類和問答測評等基本問題;第二章介紹了智能問答研究中幾種常用的統計學習和深度學習模型;第三章介紹了自然語言處理任務的基礎——實體鏈接,并詳細闡述了長文本實體鏈接的典型方法及其在智能問答系統中的應用;第四章對智能問答最重要的組成部分,自然語言中實體間的關系進行了講解,并介紹了四種不同的關系分類方法;第五章至第八章針對四類不同的智能問答任務,分別介紹了它們不同的解答方法;除此之外,本書的第九章還介紹了問題生成任務,解釋其如何從數據和模型訓練兩個角度進一步提升智能問答系統的性能;最后,第十章對全書內容加以總結。
精彩章節節選
3.2.2 基于無監督學習的方法
為了減少實體鏈接系統對標注數據的需求,可以將無監督學習方法用于候選實體排序任務。常用的方法包括基于向量空間模型的方法和基于信息檢索的方法。
基于向量空間模型的方法首先將實體提及m和m對應的某個候選實體e_i分別轉化為向量表示。然后,通過計算這兩個向量表示之間的距離對不同候選實體進行排序。實體提及和候選實體的不同向量表示生成方法對應了不同的工作。
基于信息檢索的方法將每個知識圖譜實體對應的維基百科文檔作為該實體的表示,并基于該類文檔對全部知識圖譜實體建立索引。給定輸入文本中的一個實體提及m,該類方法首先從輸入文本中找到包含m的全部句子集合,并通過去停用詞等過濾操作生成一個查詢語句。然后,使用該查詢語句從知識圖譜實體對應的索引中查找得到相關性最高的知識圖譜實體,作為m的實體鏈接結果。
無監督學習方法通常適用于長文本實體鏈接任務,這是由于短文本無法很好地生成實體提及對應的向量表示或查詢語句。
5.3 基于答案排序的方法
絕大多數基于語義分析的知識圖譜問答需要帶有語義標注的問題集合作為訓練數據。這類數據需要花費的時間和成本很高,而且要求標注人員對語義表示有一定程度的理解。使用答案作為弱監督訓練語義分析模型,能夠在一定程度上緩解數據標注難度高、開銷大和標注量有限等問題,但按照答案選擇出來的正例語義分析候選存在一定的噪音,這在一定程度上也會對語義分析模型的質量造成影響。
基于答案排序(Answer Ranking)的知識圖譜問答將該任務看成一個信息檢索任務:即給定輸入問題Q和知識圖譜KB,通過對KB中實體進行打分和排序,選擇得分最高的實體或實體集合作為答案輸出。
具體來說,該類知識圖譜問答方法主要包含下述四個模塊:
1.問題實體識別。問題實體是指問題Q中提到的知識庫實體,例如在Who founded Microsoft這個問題中,Microsoft在知識圖譜中對應的實體是該問題的問題實體。每個問題可能對應多個問題實體,該類實體的識別通常采用實體鏈接技術完成。
2.答案候選檢索。根據識別出來的一個問題實體,從知識圖譜中查找與之滿足特定約束條件的知識庫實體集合,作為該問題的答案候選。最常用的約束條件是:在知識圖譜中,與問題實體最多通過兩個謂詞相連的知識庫實體。該做法假設問題對應的答案實體和問題實體在知識圖譜中的距離通常不會很遠。
3.答案候選表示。由于每個答案候選無法直接與輸入問題進行比較,該模塊基于答案候選所在的知識圖譜上下文,生成答案候選對應的向量表示。這樣,輸入問題和答案候選之間的相關度計算就轉化為輸入問題和答案候選對應向量表示之間的相關度計算。具體方法的不同主要體現就在如何生成答案的向量表示上。
4.答案候選排序。使用排序模型對不同答案候選進行打分和排序,并返回得分最高的答案候選集合作為輸出結果。
圖5-5給出基于答案排序的知識圖譜問答方法的工作流程示意圖,按照對答案候選的不同表示方法,本章將介紹五種具體的方法,包括特征工程方法、問題生成方法、子圖匹配方法、向量表示方法和記憶網絡方法。
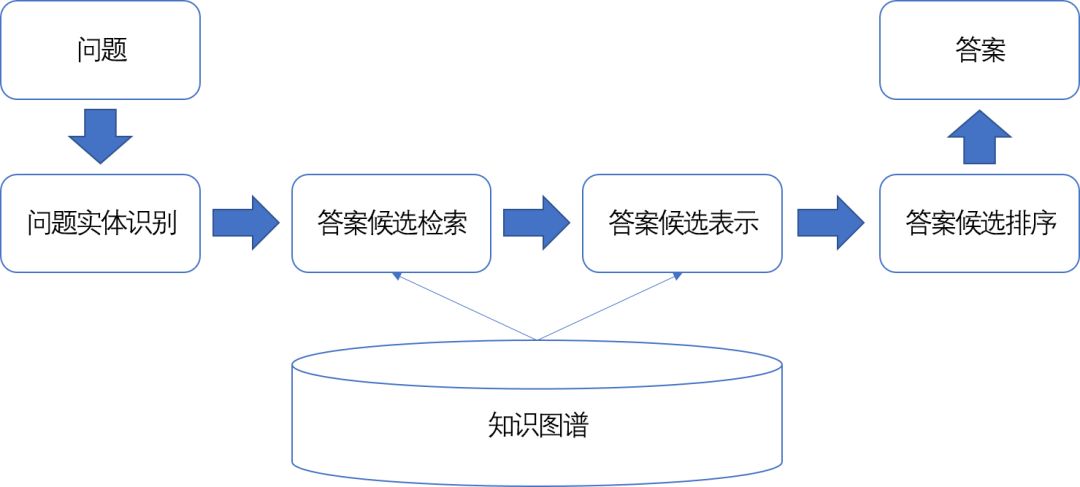
圖5-5:基于答案排序的知識圖譜問答流程圖
作者介紹
段楠博士,微軟亞洲研究院自然語言計算組主管研究員,主要從事包括智能問答、語義理解、對話系統和網絡搜索等在內的自然語言處理基礎研究,在ACL、EMNLP、COLING、AAAI、IJCAI、CVPR、KDD等國際會議中發表論文40余篇,發明專項6項,其多項研究成果已成功應用到微軟核心人工智能產品中,包括必應搜索、Cortana語音助手和微軟小冰等。
周明博士,微軟亞洲研究院副院長,國際計算語言學協會(ACL)會長,中國計算機學會理事、中文信息技術專委會主任、中國中文信息學會常務理事、中國五所頂尖大學的博士生導師。周明博士1991年獲哈爾濱工業大學博士學位。1991-1993年清華大學博士后,隨后留校任副教授。1996-1999訪問日本高電社公司領導中日機器翻譯研究。1999年,周明博士加入微軟亞洲研究院。長期擔任微軟亞洲研究院的自然語言處理的負責人。他是2018首都勞動獎章獲得者。
第二本書:《機器翻譯》
內容簡介:
《機器翻譯》一書以簡明易懂的語言對機器翻譯技術給予了全面介紹,兼顧經典的統計機器翻譯以及目前飛速發展的神經機器翻譯技術。同時,此書注重理論和實踐結合。讀者在深入淺出地理解理論體系后,可以借助實例和本書所介紹的工具快速入門,掌握機器翻譯的訓練和解碼的主要技術。
本書分為七章:第一章回顧機器翻譯發展的歷史并介紹機器翻譯技術的各種應用;第二章介紹如何獲取用于機器翻譯模型訓練的單語和雙語數據的方法以及機器翻譯自動評價方法;第三章介紹統計機器翻譯系統的基礎架構、建模方法和基本模型以及模型的參數訓練方法;第四章介紹典型的統計機器翻譯系統模型,包括基于短語的、基于形式文法的和基于句法的統計機器翻譯模型系統;第五章介紹深度學習的基礎知識,包括感知機、詞語嵌入模型、卷積神經網絡和循環神經網絡;第六章系統介紹神經機器翻譯,包括神經聯合模型和基于序列映射的神經機器翻譯模型以及注意力機制。除此之外,還介紹了基于卷積神經網絡的編碼器和解碼器的神經機器翻譯模型以及完全基于注意力網絡的模型;第七章進一步深入討論了神經機器翻譯在模型改進、模型訓練、翻譯解碼等方面的前沿進展。
精彩章節節選
6.6 完全基于注意力網絡的神經翻譯模型
在前邊我們提到,注意力網絡通過將源語言句子的隱含狀態和目標語言句子的隱含狀態直接鏈接,從而縮短了源語言詞的信息到生成對應目標語言詞的傳遞路徑,顯著得提高了翻譯質量。基于循環神經網絡的編碼器和解碼器,每個詞的隱含狀態都依賴于前一個詞的信息,所以編碼的狀態是順序生成的。這用編碼的順序生成嚴重影響了模型的并行能力。
另一方面,盡管基于門的循環神經單元可以解決梯度消失或者爆炸的問題,然而相距太遠的詞的信息仍然不能保證被考慮進來。盡管卷積神經網絡可以提高并行化的能力,然而只能考慮一定窗口內的歷史信息。為了同時解決這些問題,可以將兩個額外的注意力網絡引入編碼器和解碼器的內部,分別用于解決源語言句子和目標語言句子內部詞語之間的依賴關系。基于這樣的考慮, Vaswani 等人提出了完全基于注意力網絡的神經翻譯模型(Transformer),在本節中將對該方法進行詳細的介紹。
6.6.1 基于注意力網絡的編碼器和解碼器
如圖 6-22 所示,編碼器由 N 個同構的網絡層堆疊而成,每一個網絡層包含兩個子網絡層:
第一個子網絡層稱為分組自注意力網絡,用于將同層的源語言句子里的其它詞的信息通過自注意力網絡考慮進來以生成當前當前詞的上下文向量;
第二個子網絡層是一個全聯通的前饋神經網絡,該網絡的作用是將自注意力網絡生成的源語言句子內的上下文向量同當前詞的信息進行整合,從而生成考慮了整個句子上下文的當前時刻的隱含狀態。
為提高模型的訓練速度,殘差鏈接(Residual Connection)和層規范化(Layer Normalization)被用于這兩個子網絡層,即圖中的 Add&Norm 層,定義為LayerNorm(x +SubLayer(x)),其中x為子網絡的輸入,SubLayer為該子網絡的處理函數,LayerNorm為層規范化函數。通過對 N 個這樣的網絡層堆疊可以對信息進一步地進行抽象和融合。為了引入殘差網絡,同構網絡中每242個子網絡的輸出,以及詞向量和位置編碼(Positional Encoding)都需要保持同樣的長度。
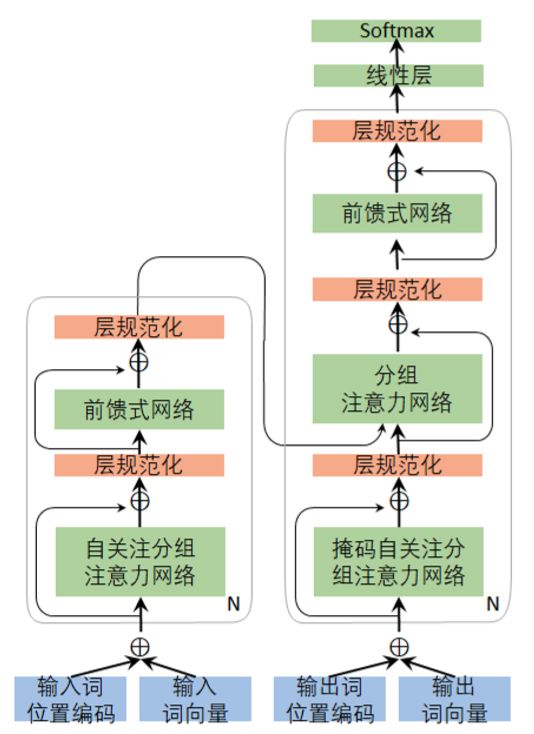
圖 6-22:完全基于注意力網絡的神經翻譯模型
解碼器同樣包含堆疊的N個同構網絡層,每個網絡層包含三個子網絡層:
第一個子網絡層同編碼器的第一個子網絡層類似,是一個分組自注意力網絡,負責將同層的目標語言句子里的其它詞的信息考慮進來生成一個目標語言句子內的上下文向量。不同于編碼器的自注意力網絡,解碼器在解碼的時候只能夠看到已經生成的詞的信息,對于未生成的內容,可以使用掩碼(mask)機制將其屏蔽掉。
第二個子網絡層為分組的注意力網絡,該網絡作用同 6.4 節中原始的注意力網絡層類似,負責將源語言句子的隱含狀態同目標語言的隱含狀態進行比較生成源語言句子的上下文向量。
第三個子網絡層同編碼器的第二個子網絡層類似,是一個全聯通的前饋神經網絡,該網絡的作用是將自注意力網絡生成的目標語言句子內的上下文向量,注意力網絡生成的源語言句子的上下文向量,以及當前詞的信息進行整合,從而更好的預測下一個目標語言測。同編碼器類似,殘差網絡(Residual Connection)和層規范化(Layer Normalization)也被用于解碼器的三個子網絡層。
作者介紹
李沐博士,曾任微軟亞洲研究院自然語言計算組資深研究員。研究領域和興趣包括自然語言處理,大規模數據挖掘,深度學習,機器翻譯等。在國際知名期刊和會議上發表論文70余篇,并對Windows、Office以及必應等多項微軟產品做出過重要貢獻。
劉樹杰博士,微軟研究院自然語言計算組主管研究員,主要研究領域為自然語言處理、機器學習、機器翻譯以及深度神經網絡在自然語言處理中的應用等。
張冬冬博士,微軟亞洲研究院自然語言計算組主管研究員,主要從事機器翻譯的理論研究與系統開發工作,發表學術論文近50篇,是微軟翻譯、必應詞典、Skype Translator等產品的重要貢獻者。
周明博士,微軟亞洲研究院副院長,國際計算語言學協會(ACL)會長,中國計算機學會理事、中文信息技術專委會主任、中國中文信息學會常務理事、中國五所頂尖大學的博士生導師。周明博士1991年獲哈爾濱工業大學博士學位。1991-1993年清華大學博士后,隨后留校任副教授。1996-1999訪問日本高電社公司領導中日機器翻譯研究。1999年,周明博士加入微軟亞洲研究院。長期擔任微軟亞洲研究院的自然語言處理的負責人。他是2018首都勞動獎章獲得者。
-
微軟
+關注
關注
4文章
6673瀏覽量
105366 -
機器翻譯
+關注
關注
0文章
140瀏覽量
15123 -
自然語言
+關注
關注
1文章
291瀏覽量
13604
原文標題:沈向洋力薦,周明、李沐執筆:要了解智能問答和機器翻譯,先看這兩本書!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論