 讓我們一起回顧 2018 年 Google 的研究工作!
讓我們一起回顧 2018 年 Google 的研究工作!
文 / Jeff Dean,高級研究員,Google AI 團隊負責人
2018 年對 Google 的研究團隊來說是令人興奮的一年,我們在很多方面推動了技術的發展,包括基礎計算機科學研究成果和出版物。我們的研究成果應用于 Google 新興領域(如醫療保健和機器人技術),加上我們對開源軟件的貢獻以及與 Google 產品團隊的緊密合作,都旨在提供有用的工具和服務。下面,我們著重介紹我們在 2018 年的一些努力,以及我們對未來的展望。如需更全面的了解,請參閱2018 年出版物(https://ai.google/research/pubs/?year=2018)
道德原則與 AI
近幾年,我們可以看到 AI 的重大進展以及對我們的產品和億萬用戶的日常生活的積極影響。對于身在其中的我們,希望 AI 是造福世界的力量,它的應用應該合乎道德原則,也應該對社會有益。2018年,我們發布了《Google AI 原則》( Google AI Principles ),提出一系列負責任的 AI 實踐,并概述了實施的技術建議。總之,它們為我們評估自己的 AI 發展提供了一個框架,我們希望其他組織也可以使用這些原則來幫助塑造自己的思維。值得注意的是,由于這一領域的發展非常迅速,一些原則的最佳實踐,如 “ 避免制造或加強不公平的偏見 ” 或 “ 對人類負責 ”,也在不斷變化和改進。這些研究反過來會促進我們產品進步,使其具備更多的包容性和更少的偏見,例如我們在Google 翻譯中減少性別偏見的工作,并允許探索和發布更具包容性的圖像數據集和模型,使計算機視覺能夠適應全球文化的多樣性。
此外,這些工作使我們能夠基于機器學習速成課程與更廣泛的研究團體分享最佳實踐(https://developers.google.com/machine-learning/crash-course/)。AI 讓社會更美好
AI 對于許多社會領域的影響的潛力非常明顯。
洪水預測就是 AI 幫助解決現實世界的問題的實例。通過與 Google 多個部門的合作,這項研究旨在準確并及時地提供關于洪水可能范圍以及細粒度信息,使那些在洪水易發地區的人們能夠盡可能地保護他們生命和財產。
另一示例是我們在地震余震預測方面的工作,它展示了機器學習模型可以比傳統的基于物理的模型更準確地預測余震的位置。更重要的是,由于機器學習模型的設計是可解釋的,科學家們對于余震的行為已經有了新的發現,不僅能夠得到更準確的預測,而且對余震的理解也達到了更高的水平。
我們還看到大量的外部研究者,與 Google 的研究人員和工程師合作,使用 TensorFlow 等開源軟件解決廣泛的科學和社會問題,例如使用卷積神經網絡識別座頭鯨,檢測新的系外行星,識別病變的木薯植物等等。
為了促進這一領域的創意活動,我們與 Google.org 合作成立了Google AI for Social Impact Challenge,個人和組織可以從總計 2,500 萬美元的資金中獲得資助,以及 Google 研究科學家的指導和建議。
輔助技術
我們的許多研究,都集中在使用機器學習和計算機科學來幫助我們的用戶更快速有效地完成任務。我們通常與不同的產品團隊協作,并將研究成果應用于不同的產品特性和設置中。示例之一就是Google Duplex,一個需要自然語言研究和對話理解、語音識別、文本到語音、用戶理解和有效的UI設計的系統。這些系統能夠讓用戶可以說 “Can you book me a haircut at 4 PM today? ”,虛擬代理將通過電話代表您進行交互,以處理必要的細節。
其他的示例如 Gmail 的 Smart Compose 工具,使用預測模型來提供郵件撰寫的建議,從而使電子郵件撰寫過程更快更容易;以及 Sound Search,一種基于正在播放功能的技術,能夠讓用戶快速、準確地搜索到正在播放的歌曲。另外,Android 中的 Smart Linkify 展示了我們如何利用設備上的機器學習模型,通過理解您選擇的文本類型使手機屏幕上顯示的各種文本更有用(例如,知道某些內容是地址,從而給我們提供地圖等鏈接的快捷方式)。
我們研究的一個重點是幫助像 Google 智能助理這樣的產品可以支持更多語言,并且可以更好地理解語義相似性,即使使用了非常不同的表達方式代表相同的概念或想法。
量子計算
量子計算,這是一種新興的計算范式,我們可以利用量子計算來解決經典計算機無法解決的挑戰性問題。近幾年里,我們一直積極致力于這一領域的研究,該領域正在展示至少一個問題上的尖端能力 ( 所謂的量子霸權 ),這將是該領域的一個重大里程碑。
在 2018 年,我們取得了很多令人興奮的新成果,例如開發了一種新的72-qubi 的量子計算設備:Bristlecone,該設備擴大了量子計算機可解決問題的范圍。
研究科學家 Marissa Giustina 在 Santa Barbara 的量子 AI 實驗室安裝 Bristlecone 芯片
同時我們發布了面向量子計算機的開源編程框架 Cirq,并探索了如何將量子計算機應用于神經網絡。最后,我們把在理解量子處理器性能波動方面的經驗和技術以及關于量子計算機作為神經網絡的計算基礎的想法分享給了大家。
2019 年,我們期待在量子計算領域取得更大的成果!
自然語言理解
非常開心,Google 的自然語言研究在 2018 年取得了令人振奮的成果,其中包含了基礎研究和以產品為中心的合作。我們改進了在 2017 年提出的Transformer架構,并研發了一個新的并行版本模型,稱為通用變換器,該版本在翻譯和語言推理等自然語言任務中表現出了強大的優勢。
同時,我們還發布了BERT,這是第一個深度雙向、無監督的語言表示模型。BERT在 11 個自然語言任務上與之前的最先進的結果對比,有了明顯的改進。現在,只利用純文本語料庫就可以進行預訓練,然后可以使用遷移學習對各種自然語言任務進行微調。
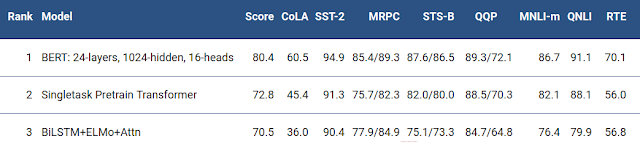
在挑戰性很強的 GLUE 基準測試中,BERT 將最優結果提高了 7.6%
除了與各種研究團隊合作以實現 Smart Compose 和 Duplex(之前討論過)之外,我們還努力使 Google 智能助理能夠更好地處理多語言用例,目標是使其能自然地與所有用戶進行交流。
感知研究
感知研究一直在為圖像捕獲、壓縮、處理、創造性表達和增強現實提供更強大的工具,并且解決了計算機理解圖像、聲音、音樂和視頻這一難題。
在過去的這一年里年,我們的技術優化了 Google Photos 中用戶最關心的內容組織的能力,例如人和寵物。
Google Lens 幫你了解周圍的世界
讓用戶通過 Google Lens 和Google Assistant來了解自然世界,實時回答問題的同時,還能在 Google 圖像中使用 Google Lens 做更多事情。Google AI 使命的一個關鍵方面是讓其他人能夠從我們的技術中受益,今年我們在改進 Google API 的功能和構建模塊方面取得了很大的進展。示例中包括利用 ML Kit 在 Cloud ML API 和面部相關設備構建塊中實現視覺和視頻的改進以及一些新功能。
2018 年,我們對學術研究的貢獻包括基于 3D 場景理解的深度學習技術,例如 stereo magnification。并且我們正在推進能更好地理解圖像和視頻的研究,使用戶能夠在 Google 產品中查找,組織,增強和改進圖像和視頻,例如照片,YouTube,搜索等。
多模態感知成為一個越來越重要的研究課題。我們在音頻領域提出了一種無監督學習方法并應用于語義音頻表示,其中對包含表達性的類人語音合成有明顯改進。
我們用Looking to Listen將輸入視頻中的視覺和聽覺線索結合起來,用來隔離和加強視頻中所需的揚聲器聲音。該技術可以支持一系列應用,從語音增強和視頻識別,視頻會議到改進的助聽器,尤其是在多人講話的情況下。
在有限的計算平臺上實現感知變得日益重要。我們發布了MobileNetV2,它將為下一代移動視覺應用提供支持。我們的 MobileNets 廣泛應用于學術界和工業界。MorphNet 為學習深層網絡結構提供一種有效的學習方法。在計算資源限制的情況下,在圖像和音頻模型上實現全面的性能改進。最近的研究也表明,有關自動生成移動網絡架構,并獲得更高的性能是可能的。
計算攝影
在過去幾年中,質量和多功能性的改進一直是手機相機備受關注的方面。原因之一是手機中使用的物理傳感器的改進,但最主要的原因是計算攝影這一科學領域的進步。我們發布了最新研究技術,并通過與 Google Android 團隊和消費硬件團隊的緊密合作,將這項研究實施在最新的 Pixel 和 Android 手機及其他設備。
2014 年,我們發布了HDR+技術,利用該技術,攝像機捕捉到一組幀,并在軟件中對齊這些幀,最終將它們與計算軟件合并在一起。最初 HDR+ 的工作是為了使圖片具有比單次曝光更高的動態范圍。通過捕獲大量的幀,然后對這些幀進行計算分析逐漸演變成一種通用的方法,并且在 2018 年使相機中的許多進步得以實現。例如,在 Pixel 2 中開發 Motion Photos,并在 Motion Stills 中實現增強現實模式。
Pixel 2 拍攝的運動照片
Motion Stills 的 AR 模式
2018 年,創造了一種名為Night Sight的新功能,是我們在計算攝影研究方面的主要工作成果之一。讓 Pixel 手機攝像頭能夠 “在黑暗中看到”,贏得了媒體和用戶的贊譽。
左:iPhone XS ( 全分辨率 ) 右:Pixel 3 的夜視能力 ( 全分辨率 )
算法和理論
算法觸及了我們所有的產品,從 Google trips 背后的路徑 ( routing ) 算法到 Google cloud 的一致性哈希 ( consistent hashing ) ,它是 Google 系統的支柱。
2018 年,我們在算法和理論方面進行研究,其中包含了從理論基礎到應用算法,從圖挖掘到隱私保護計算的廣泛領域。在優化方面的工作,涉及從機器學習的持續優化到分布式組合優化的各個領域。我們研究的用于訓練神經網絡的隨機優化算法的收斂性的工作 ( 獲得了 ICLR 2018 最佳論文 ),展示了流行的基于梯度的優化方法 ( 如 ADAM 的一些變體 ) 存在的問題,為新的基于梯度的優化方法提供了堅實的基礎。
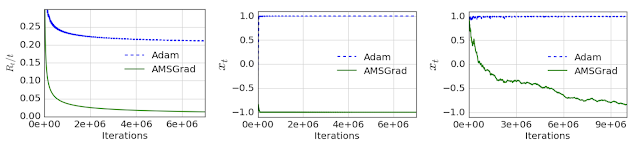
ADAM 和 AMSGRAD 在一個簡單的一維凸問題上的性能比較
在分布式優化中,我們致力于改善組合優化問題中的循環和通信復雜性,例如通過循環壓縮 ( round compression ) 和核心集 ( core-sets ) 解決圖論中的匹配問題,以及亞模最大化 ( submodular maximization ) 和 k 核分解 ( k-core decomposition )。在偏應用的方面,我們在用 sketching 解大規模集合覆蓋,以及在有萬億條邊的圖中做平衡分割 ( balanced partitioning ) 和層級聚類 ( hierarchical clustering ) 等問題上提出了新的算法技巧。我們關于在線配送服務的工作獲得了 WWW'18 的最佳論文提名。最后,我們的開源優化 OR-tools 平臺在 2018 年 Minizinc 約束編程 ( constraint programming ) 競賽中獲得了 4 枚金牌。
在算法選擇論中,我們提出了新的模型并研究了重建和學習混合多項對數成敗比 ( mixture of multinomial logits )。我們還研究了可通過神經網絡學習的函數類,以及如何使用機器學得諭示 ( machine-learned oracles ) 來改進經典的在線算法。
了解具有強大隱私保障的機器學習技巧對我們 Google 非常重要。在這種背景下,我們開發了兩種新的方法來分析如何通過迭代和改組 ( shuffling ) 來增強差分隱私 ( differential privacy )。我們還應用了差分隱私的技巧設計對博弈魯棒的激勵察覺學習 ( incentive-aware learning ) 方法。這種學習技術在在線市場設計中具有應用。我們在市場算法 ( market algorithm ) 領域的新研究還包括幫助廣告客戶測試廣告競價的激勵兼容性 ( incentive compatibility ) 以及優化應用內的廣告刷新。我們還推動了重復拍賣 ( repeated auction ) 下最先進的動態機制 ( dynamic mechanism ) 的邊界,并提出了對缺少未來預期、預測含噪、以及異質買方行為魯棒的動態拍賣機制 ( dynamic auction ),并將我們的結果擴展到動態雙向拍賣 ( dynamic double auction )。最后,在在線優化和在線學習的背景下,我們提出了新的針對含有流量高峰的隨機輸入的在線分配算法,以及新的對腐敗數據 ( corrupted data ) 魯棒的 bandit 算法。
軟件系統
Google 在軟件系統方面的大部分研究依然與構建機器學習模型有關,尤其是與TensorFlow有關。例如,我們發表的 TensorFlow 1.0 動態控制流的設計和實現。
在一些新研究中,我們使用了一個稱為 Mesh TensorFlow 的系統,讓使用模型并行性來指定大規模分布式計算變得更加簡單。例如,我們使用 TensorFlow 發布了TF-Ranking 庫,這是一個專為 Learning-to-Rank 打造的可擴展的 TensorFlow 庫。
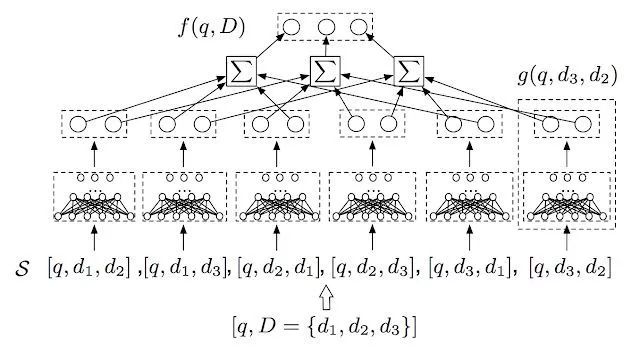
TF - Ranking庫
我們發布了一個加速器支持的 NumPy 變體 -JAX,它支持自動將 Python 函數區分為任意順序。盡管 JAX 不是 TensorFlow 的一部分,但它利用了一些相同的底層軟件基礎架構 ( 例如 XLA ),并且它的一些思想和算法可以為 TensorFlow 項目提供幫助。最后,我們繼續研究機器學習的安全性和隱私性,如 CleverHans 和 TensorFlow Privacy。
對我們來說,將機器學習應用于軟件系統也是一個非常重要的研究方向。例如,我們繼續利用分層模型將計算部署到設備上,并有助于學習內存訪問模式。探索如何利用學習的索引來替代數據庫系統和存儲系統中的傳統索引結構。正如我們 2018 年寫的那樣,我們認為在計算機系統中使用機器學習方面仍然還是停留在表面問題上,有待進一步探索。
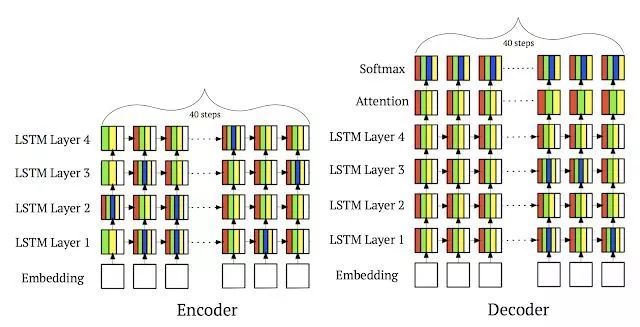
在一個 NMT 模型 ( 4 層 ) 中 Hierarchical Planner 的放置
2018 年,感謝 Google Project Zero 團隊與外部的合作,我們了解到 Spectre 和 Meltdown,是現代計算機處理器中嚴重安全漏洞的新類別。這些漏洞將使計算機架構研究人員相當忙碌。在我們繼續努力模擬 CPU 行為時,我們的編譯器研究團隊將測量機器指令延遲和端口壓力的工具集成到 LLVM 中,從而可以做出更好的編譯決策。
我們的云產品和機器學習模型推理主要取決于為計算,存儲和網絡提供大規模、可靠、高效的技術基礎架構的能力。過去一年的一些研究亮點包括 Google 軟件定義網絡 WAN 的發展,這是一個獨立的聯合查詢處理平臺,可以在許多存儲系統中對基于不同文件格式存儲的數據執行 SQL 查詢(BigTable,Spanner, Google Spreadsheets 等)以及我們廣泛使用代碼審查的報告,調查 Google 代碼審查背后的動機,當前實踐以及開發人員的滿意度和挑戰。
運行內容托管等大型 Web 服務需要在動態環境中實現穩定的負載均衡。我們開發了一致性哈希方案,對每臺服務器的最大負載提供了緊的可證明保證,并將其部署到 Google Cloud Pub / Sub 中。基于我們早期版本的論文,Vimeo 的工程師在 haproxy 中實現此功能并開源,并將其用于 Vimeo 的負載均衡項目。結果是戲劇性的:應用這些算法思想幫助他們將緩存帶寬減少了近 8 倍,消除了擴大應用規模的瓶頸。
AutoML
AutoML,也可以稱為元學習(meta-learning),是利用機器學習來部分自動化機器學習的方法。多年來,我們一直致力于在這個領域進行研究,接下來,我們要長期做的是開發一種學習系統,該系統可以利用先前已經解決的其他問題得出的見解和能力,來學習并解決新的問題。
我們對進化算法的使用也非常感興趣。在這個領域,我們開展的早期工作主要是使用強化學習。例如,2018 年我們展示了如何使用進化算法自動發現最先進的神經網絡架構并用于各種視覺任務。
關于強化學習如何應用于神經網絡架構搜索之外的其他問題,我們的探討結果如下:
-
它可以自動生成圖像變換序列,以提高各種圖像模型的準確性
-
尋找新的符號優化表達式,比常用的優化更新規則更有效
我們在 AdaNet 上的工作展示了如何使用具有學習能力的快速靈活的AutoML 算法。
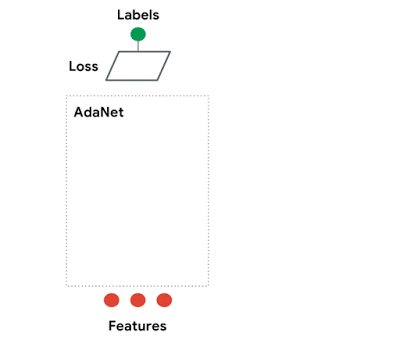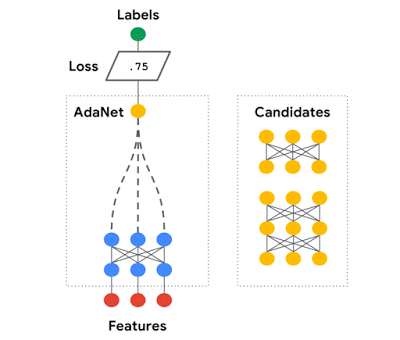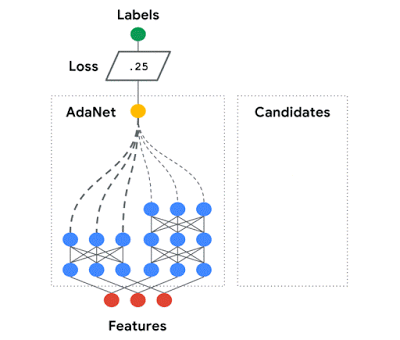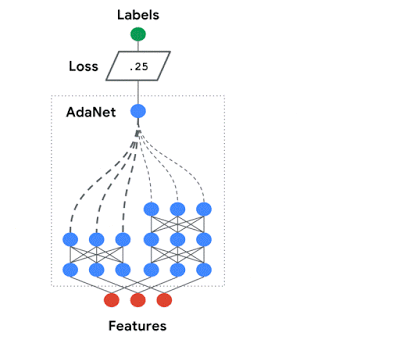
AdaNet 自適應地生成神經網絡的集合。
在每次迭代中,它都度量每個候選者的集成損失,并選擇最佳的一個進行下一次迭代
我們的另一個重點是自動發現計算效率高的神經網絡架構,以便它們可以在諸如移動電話或自動駕駛車輛等環境中運行,這些環境對計算資源或推理時間有嚴格的限制。我們發現,在強化學習架構搜索的獎勵函數中將模型的準確性與其推理計算時間相結合,可以找到高度準確的模型,同時滿足特定的性能約束。我們還探索了使用機器學習來自動壓縮機器學習模型以獲得更少的參數并使用更少的計算資源。
TPU
Tensor Processing Units ( TPU ) 是 Google 開發的機器學習硬件加速器,一直以來它為支持大規模的訓練和推理提供幫助,并且幫助 Google 在許多方面實現了突破性進展,例如前面討論過的BERT,它們還允許世界各地的研究人員能夠基于開放源碼在 Google 的研究基礎上進行構建,并追求自己的新突破。例如,所有人都可以通過 Colab 在 TPU 上免費調優 BERT, TensorFlow Research Cloud 讓成千上萬的研究人員獲益。我們還將 TPU 硬件作為云 TPU 商用。除了在機器學習研究中實現更快的進步之外,TPU 還推動了 Google 的核心產品的重大改進,包括搜索,YouTube,Gmail,Google 智能助理,Google 翻譯等等。我們期待,無論是 Google 內部或著其他地方的機器學習團隊,通過 TPU 實現前所未有的計算規模。
單個 TPU v3 設備 ( 左 ) 和 TPU v3 Pod 的一部分 ( 右 )
開源軟件和數據集
Google為研究和軟件工程社區做出貢獻的兩種主要方式:發布開源軟件和創建新的公共數據集。在這個領域,我們最大的努力之一是TensorFlow!
TensorFlow 發布于 2015 年 11 月。至今,已經成長為一個非常流行的機器學習計算系統。我們在 2018 年慶祝了 TensorFlow 的 3 歲生日。在此期間,TensorFlow 已經擁有超過3,000 萬次的下載量,超過1,700 個貢獻者,總共增加了4.5 萬次提交。
2018 年,TensorFlow 發布了 8 個主要版本,并增加了一些主要功能,如 eager execution。TensorFlow 生態系統在 2018 年也有了大幅增長,例如 TensorFlow Lite、TensorFlow.js 和 TensorFlow Probability 的相繼推出。
我們很高興 TensorFlow 擁有大量的 Github 用戶,成為頂級機器學習和深度學習框架。TensorFlow 團隊還致力于更迅速地解決 Github 問題,并為外部貢獻者提供順暢的途徑。根據 Google Scholar 的數據,在研究中,我們繼續在已發表的論文基礎上為世界上大部分的機器學習和深度學習研究提供支持。僅推出一年,全球超過 15 億的設備支持 TensorFlow Lite。此外,TensorFlow.js 是 JavaScript 的頭號機器框架; 在推出后的九個月里,它在 Github 上有超過 200 萬的內容分發網絡(CDN)點擊量,25 萬下載量和超過 1 萬顆星。
除了繼續開發現有的開源生態系統之外,我們在 2018 年引入了一個新的框架,用于靈活和可重復的強化學習,用于快速理解數據集的特征的新可視化工具 ( 無需編寫任何代碼 ),一個使用 TensorFlow.js 在瀏覽器中進行實時 t-SNE 可視化的庫,以及用于處理電子醫療數據的 FHIR 工具和軟件等。
完整 MNIST 數據集的 tSNE 嵌入的實時演變,該數據集包含 6萬個手寫數字的圖像
公共數據集通常是一個很好的靈感來源,可以在許多領域取得巨大進步,因為它們可以讓更廣泛的社區獲得有趣的數據和問題,以及在各種任務中獲得更好的結果。今年,我們很高興發布Google 數據集搜索,這是一種從所有網絡中查找公共數據集的新工具。多年來,我們還策劃并發布了許多新的,新穎的數據集,包括從數百萬個通用注釋圖像或視頻到用于語音識別的人群源孟加拉數據集到機器人手臂抓取數據集等等。在 2018 年,我們在該列表中添加了更多數據集。
Open Images V4,這是一個包含 1,540 萬個邊界框的數據集,包含 600 個類別的 190 萬張圖像,以及 19,794 個類別的 3,010 萬個經過人工檢查的圖像級標簽。我們還通過使用 crowdsource.google.com 添加了來自世界各地的數萬名用戶提供的 5.5M 生成的注釋,擴展了此數據集以添加來自世界各地的更多人和場景。我們發布了原子視覺動作(AVA)數據集,該數據集提供視頻的視聽注釋,以改善理解人類行為和視頻語音的現狀。我們也宣布更新 YouTube-8M,以及第二屆 YouTube-8M 大型視頻理解挑戰和研討會。雖然不是數據集發布,但我們探索了一些技術,這些技術可以使用 Fluid Annotation 更快地創建可視化數據集,Fluid Annotation是一種探索性的機器學習驅動接口,可以更快地進行圖像注釋。
COCO 數據集圖像上的 Fluid Annotation 界面
機器人技術
過去的一年里,Google 在理解機器學習如何教會機器人在現實世界里行動方面,取得了重大進展,該項研究讓機器人學習抓取未沒見過的物體,并且相關的論文獲得了 CoRL’18 最佳論文。通過結合機器學習和基于采樣的方法 ( ICRA'18 最佳論文 ),我們在學習機器人運動方面取得了進展,例如實現了第一次能夠在真實機器人上成功地在線訓練深度強化學習模型,并且正在尋找新的,理論上的基礎方法,來學習機器人控制的穩定方法。
AI 在其他領域的應用
2018 年,在科學領域中,我們將機器學習應用于解決物理和生物科學中的各種問題。利用機器學習為科學家提供相當于數百或數千名研究助理的數據挖掘,不僅為科學家節省了時間和精力,還讓他們變得更具有創造力和生產力。
我們與德國馬克斯普朗克神經生物學研究所的研究人員合作在Nature Methods 中發表了一篇關于神經細胞高精度自動重建的論文,展示了一種新型的遞歸神經網絡如何提高自動解析連接組數據的準確性。與先前的深度學習技術相比,將連通組學數據提高了一個數量級。
我們的算法在鳴禽大腦中追蹤單個神經突的 3D 過程
將機器學習應用于科學領域的其他示例:
-
通過數據挖掘恒星的光曲線,并尋找新的太陽系外行星
-
短 DNA 序列的起源或功能
-
自動檢測離焦顯微鏡圖像
-
自動將質譜輸出映射到肽鏈
經過預訓練的 TensorFlow 模型可以對 Fiji ( ImageJ ) 細胞顯微鏡圖像斑塊的蒙太奇進行聚焦質量評估
醫療領域的 AI
在近幾年里,我們一直致力于將機器學習應用于醫療領域。這項研究將會影響我們每一個人,同時我們也堅信利用機器學習增強醫療專業人員的直覺和經驗可以產生巨大影響。
在這個領域,我們通常采用與醫療機構合作解決基礎研究問題的方式 ( 例如,利用臨床專家的反饋讓我們的結果更加可靠 ),然后將結果發表在科學和臨床雜志上。當該研究得到臨床和科學驗證時,我們便會進行用戶和 HCI 研究,以便于我們掌握如何在現實臨床環境中進行部署。在 2018 年,我們已經將計算機輔助診斷的廣泛空間擴展到了臨床任務預測。
2016 年底,我們發表過一項研究表明,述及我們如何訓練的用于評估視網膜眼底圖像以檢測糖尿病視網膜病變跡象的模型,其表現與美國醫學委員會認證的眼科醫生相當,甚至略勝一籌。
2018 年,我們進一步證明,利用由視網膜專家標記的圖像進行訓練,模型的表現已經相當于視網膜專家的水平。我們還發現有證據表明,醫生可以與模型協同工作,獲得比二者單獨工作時更高的準確度。借助篩查項目和與Verily的合作,在印度的 Aravind 眼科醫院和泰國衛生部下屬的 Rajavithi 醫院等 10 多個地方部署了這個糖尿病視網膜病變檢測系統。
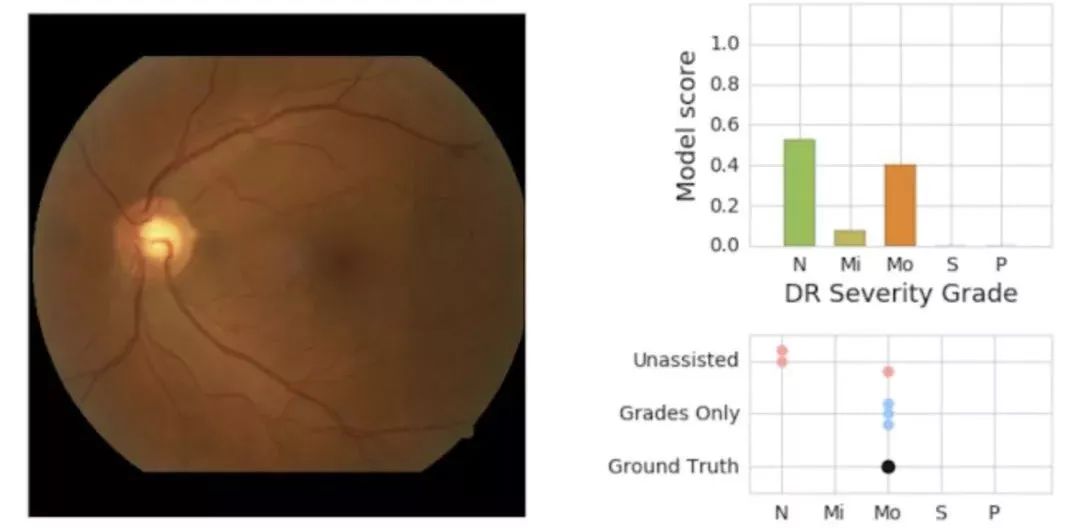
機器學習評估糖尿病視網膜病變
我們還發表了一項關于機器學習模型通過視網膜圖像評估心血管風險的研究,這項研究得到了醫學專家和眼科專家的認可和稱贊。這是一種為新的、非侵入性的生物標志物提供了早期有希望的跡象,并且幫助臨床醫生更好地了解患者的健康狀況。
我們在病理學領域的探索中展示了使用機器學習提高前列腺癌分級的準確度、利用深度學習檢測轉移性乳腺癌,還開發了一個增強現實顯微鏡,通過來自計算機視覺模型的視覺信息幫助病理學家和其他科學家。
近四年中,Googel 進行了大量的研究工作,圍繞使用電子健康記錄的深度學習來做出臨床相關的預測。2018 年,我們與芝加哥大學、加州大學舊金山分校和斯坦福大學合作,在 Nature Digital Medicine 上發表了一篇論文,展示了將機器學習模型應用于識別電子病歷,并且能夠對各種臨床相關任務做出比當前臨床最佳實踐準確性更高的預測。作為這項工作的一部分,我們開發了一些工具,讓即使在完全不同的任務和完全不同的基礎 EHR 數據集上創建這些模型變得非常簡單。同時還改進了基于深度學習的變量調用 DeepVariant 的準確性、速度和實用性。該團隊在《自然 - 生物技術》雜志上發表了一篇同行評議的論文。
將機器學習應用于歷史收集的數據時,了解過去經歷過人類和結構偏差的人群以及這些偏見如何在數據中編纂是很重要的。機器學習提供了一個檢測和解決偏見的機會。
研究推廣
Google 經常用不同的方式和外部研究社區進行交流,比如教師參與和學生支持。我們非常高興的在本學年招收了數百名本科生、碩士生和博士生作為實習生,同時為北美、歐洲和中東的學生提供多年的博士生獎研金 ( Ph.D. fellowships )。
關于這個獎學金項目,我們還要補充的是 Google AI Residency 項目,這種方式允許想要深入學習研究的人花費一年的時間與Google的研究人員一起工作并接受他們的指導。至今,Google AI Residency 已進入第三個年頭,學員們被安排在 Google 全球的各個團隊中,從事機器學習、感知、算法和優化、語言理解、醫療保健等領域的研究。
每年,我們通過 Google Faculty Research Awards program 支持一些教師和學生進行研究項目。2018 年,我們還繼續在 Google 為特定領域的教師和研究生舉辦研討會,包括在印度班加羅爾辦事處舉辦的 AI / 機器學習 研究與實踐研討會,在我們的蘇黎世辦事處舉辦的算法和優化研討會,在美國桑尼維爾舉辦的機器學習醫療保健應用研討會和在馬薩諸塞州劍橋辦事處舉辦的機器學習公平與偏見研討會。
我們相信,為更廣泛的研究團體做出公開貢獻是支持健康和富有成效的研究生態系統的關鍵部分。除了開源和公開數據集之外,我們的許多研究都在頂級會議和期刊上公開發表,并積極參與、組織和贊助各種不同學科的會議。
新的起點,新的面孔
2018 年,我們很高興地歡迎許多來自各行各業的新人加入我們的研究組織。我們在非洲組建了 AI 研究辦公室。我們擴大了在巴黎、東京和阿姆斯特丹的 AI 研究,并在普林斯頓開設了一個研究實驗室。我們將繼續在全球范圍內聘請有才能的人加入我們。您可以了解更多有關加入我們的信息(https://ai.google/research/join-us/)。
期待 2019 年
本文摘要總結了我們 2018 年的科研的一小部分。回顧 2018 年,我們對所取得成就的深度和廣度感到興奮。
2019 年,我們期待 Google 的研究和產品,能對更廣泛的領域產生更有意義的影響!
-
Google
+關注
關注
5文章
1787瀏覽量
58685
原文標題:讓我們一起回顧 2018 年 Google 的研究工作!
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
上海車展圓滿收官,回顧誠邁科技、智達誠遠精彩時刻!

精彩回顧 | 《電磁兼容仿真技術與電源EMC問題解析》直播圓滿結束!


回顧2024年度潤和軟件與openEuler的精彩瞬間
易飛揚通信2024年度總結:新品迭出,展會風采盡顯






 工商網監
工商網監
評論