") 微控制器的性能分析技術(shù)的介紹與了解
微控制器的性能分析技術(shù)的介紹與了解

基準(zhǔn)測(cè)試讓您比較處理器,但仍有很多變化。理解和運(yùn)行標(biāo)準(zhǔn)基準(zhǔn)可以讓設(shè)計(jì)人員更好地了解和控制他們的應(yīng)用程序。
比較微處理器從未如此簡單。即使比較通常具有相同基本架構(gòu)的所有變體的處理器的臺(tái)式計(jì)算機(jī)或膝上型計(jì)算機(jī)也可能令人沮喪,因?yàn)榕c“更差”的數(shù)字相比,具有更快數(shù)字的計(jì)算機(jī)可能運(yùn)行緩慢。在嵌入式世界中,事情變得更加艱難,其中處理器和配置的數(shù)量實(shí)際上是無限的。
基準(zhǔn)測(cè)試是解決這一難題的常用方法。多年來,Dhrystone基準(zhǔn)(Whetstone基準(zhǔn)測(cè)試中的一個(gè)游戲,其中包括Dhrystone省略的浮點(diǎn)運(yùn)算)是城里唯一的游戲。但是,它有許多重大問題。其中最主要的是它不反映任何實(shí)際計(jì)算,它只是試圖模仿各種操作的統(tǒng)計(jì)頻率。此外,編譯器通常可以在編譯時(shí)執(zhí)行大部分計(jì)算,這意味著在運(yùn)行基準(zhǔn)測(cè)試時(shí)不必完成工作。
對(duì)基準(zhǔn)測(cè)試的真正考驗(yàn)是,在詳細(xì)查看結(jié)果(特別是那些最初看起來很奇怪的結(jié)果)時(shí),您可以合理化為什么結(jié)果看起來像他們一樣。理想的基準(zhǔn)測(cè)試將提供純粹反映處理器性能的分?jǐn)?shù),與系統(tǒng)的其他部分無關(guān)。不幸的是,這是不可能的,因?yàn)闆]有處理器孤立地運(yùn)行:所有處理器必須與內(nèi)存交互 - 高速緩存,數(shù)據(jù)存儲(chǔ)器和指令存儲(chǔ)器,每個(gè)處理器可能會(huì)或可能不會(huì)以完整的處理器頻率運(yùn)行。此外,這些處理器必須全部運(yùn)行由編譯器生成的代碼,并且不同的編譯器生成不同的代碼。
即使是相同的編譯器也會(huì)根據(jù)編譯代碼時(shí)選擇的優(yōu)化設(shè)置生成不同的代碼。這種差異是無法避免的,但要避免的主要是將實(shí)際的基準(zhǔn)代碼優(yōu)化掉。
盡管結(jié)果可能取決于編譯器和內(nèi)存,但您應(yīng)該只能根據(jù)處理器本身,編譯器(和設(shè)置)以及內(nèi)存速度來解釋任何此類結(jié)果。 Dhrystone基準(zhǔn)測(cè)試的情況并非如此。然而,嵌入式微處理器基準(zhǔn)聯(lián)盟(EEMBC)最近的CoreMark基準(zhǔn)測(cè)試已經(jīng)克服了這些缺陷,并且被證明更加成功。點(diǎn)擊EEMBC在2009年開發(fā)并公開發(fā)布了CoreMark基準(zhǔn)(現(xiàn)已由超過4,100名用戶下載)。它已經(jīng)適用于眾多平臺(tái),包括Android。開發(fā)人員特別注意避免舊基準(zhǔn)測(cè)試的陷阱。通過查看CoreMark基準(zhǔn)測(cè)試的工作原理以及一些示例結(jié)果,我們可以看到它不僅可以成為性能的可靠指標(biāo),還可以幫助確定微控制器和編譯器性能的改進(jìn)位置。
CoreMark基準(zhǔn)程序
CoreMark基準(zhǔn)程序使用三種基本數(shù)據(jù)結(jié)構(gòu)來表示實(shí)際工作。第一個(gè)結(jié)構(gòu)是鏈表,它執(zhí)行指針操作。第二個(gè)是矩陣;矩陣運(yùn)算通常涉及嚴(yán)格優(yōu)化的循環(huán)。最后,狀態(tài)機(jī)需要難以預(yù)測(cè)的分支,并且其結(jié)構(gòu)比用于矩陣運(yùn)算的循環(huán)要少得多。
為了保持盡可能多的嵌入式系統(tǒng)的可訪問性,無論大小,該程序都有2 kb的代碼占用空間。圖1說明了程序的工作原理。前兩個(gè)步驟可能看似微不足道,但它們實(shí)際上非常重要 - 它們是確保編譯器無法預(yù)先計(jì)算任何結(jié)果的步驟。直到運(yùn)行時(shí)才知道要使用的輸入數(shù)據(jù)。
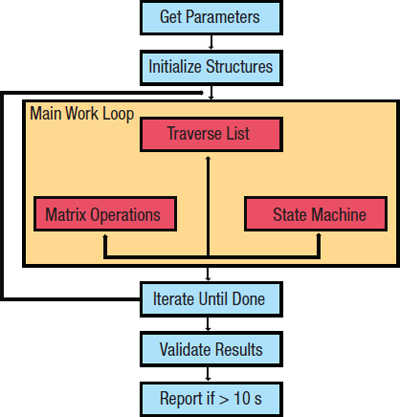
圖1:CoreMark基準(zhǔn)測(cè)試過程。
大部分基準(zhǔn)工作負(fù)載發(fā)生在主工作循環(huán)中。掃描其中一個(gè)數(shù)據(jù)結(jié)構(gòu),即鏈表。每個(gè)條目的值確定是否要執(zhí)行矩陣操作或狀態(tài)機(jī)操作。重復(fù)該決策操作步驟直到列表用盡。此時(shí),單個(gè)迭代完成。重復(fù)工作循環(huán)直到至少10秒鐘。實(shí)施10秒要求以確保足夠的數(shù)據(jù)以提供有意義的結(jié)果。如果運(yùn)行時(shí)間小于此值,那么基準(zhǔn)程序?qū)⒉粫?huì)報(bào)告結(jié)果。但是,如果用戶在模擬器上運(yùn)行基準(zhǔn)測(cè)試,則可以修改此時(shí)間要求。
主要工作完成后,使用公共循環(huán)冗余校驗(yàn)(CRC)功能;它可以作為一種自我檢查,以確保在執(zhí)行過程中(偶然或其他方面)沒有出錯(cuò)。假設(shè)一切都結(jié)束,程序?qū)?bào)告CoreMark結(jié)果。此數(shù)字表示每秒執(zhí)行時(shí)間的主工作循環(huán)的迭代次數(shù)。點(diǎn)擊雖然大多數(shù)基準(zhǔn)用戶都是誠實(shí)的,但確保任何基準(zhǔn)測(cè)試方案都有針對(duì)濫用的保護(hù)措施始終是非常重要的。有人可以嘗試篡改結(jié)果的兩種主要方式:編輯代碼(在移植層內(nèi)除外),因?yàn)榇a必須以源代碼形式提供,并且只是偽造結(jié)果。 CRC有助于檢測(cè)代碼損壞時(shí)可能出現(xiàn)的任何問題,并且EEMBC技術(shù)中心的認(rèn)證是最終仲裁者。沒有人需要對(duì)他們的結(jié)果進(jìn)行認(rèn)證,但認(rèn)證增加了顯著的可信度,因?yàn)樗C實(shí)了中立的第三方獲得了相同的數(shù)字。
調(diào)整基準(zhǔn)測(cè)試運(yùn)行
當(dāng)程序查找用于初始化數(shù)據(jù)的用戶參數(shù)時(shí),您不會(huì)顯式提供原始數(shù)據(jù)。這將是太多的工作,它還將通過仔細(xì)選擇初始化數(shù)據(jù)開辟操縱的可能性。相反,程序會(huì)查找必須由用戶設(shè)置的三粒種值。
這些數(shù)字以對(duì)用戶不透明的方式指導(dǎo)數(shù)據(jù)結(jié)構(gòu)中值的初始化。雖然它們充當(dāng)“種子”,但沒有隨機(jī)因素。結(jié)構(gòu)是完全確定的,并且具有相同種子的基準(zhǔn)的多次運(yùn)行將導(dǎo)致相同的執(zhí)行和結(jié)果。
您可能還需要調(diào)整基準(zhǔn)來考慮系統(tǒng)分配內(nèi)存的方式。具有充足資源的系統(tǒng)可以簡單地使用heap和malloc()調(diào)用。這允許在需要時(shí)進(jìn)行每次內(nèi)存分配,并確保所需的內(nèi)存量。然而,這種靈活性需要付出代價(jià),更好的系統(tǒng)需要更快的方式來使用內(nèi)存。
最快的方法是完全預(yù)分配內(nèi)存,但使用不可行的鏈表操作。中間方法是創(chuàng)建許多預(yù)定義的內(nèi)存塊(內(nèi)存池),可以根據(jù)需要進(jìn)行分配。權(quán)衡是你不能選擇每個(gè)塊中有多少內(nèi)存 - 你得到一個(gè)固定大小的塊。移植層允許您使基準(zhǔn)測(cè)試適應(yīng)被評(píng)估系統(tǒng)上使用的內(nèi)存分配方案的類型。并行性是您可以利用的另一個(gè)特性,如果您的系統(tǒng)支持它。您可以為并行操作構(gòu)建CoreMark基準(zhǔn),指定在執(zhí)行期間生成的上下文(線程或進(jìn)程)的數(shù)量。但是,您應(yīng)該避免使用CoreMark來表示處理器的多核性能,因?yàn)橛捎谄湫〕叽纾摶鶞?zhǔn)測(cè)試肯定會(huì)線性擴(kuò)展99.9%。
了解結(jié)果
當(dāng)然,這是您對(duì)基準(zhǔn)測(cè)試結(jié)果所做的事情,可能導(dǎo)致混淆(有意或無意)。出于這個(gè)原因,EEMBC強(qiáng)加了嚴(yán)格的報(bào)告要求。 CoreMark網(wǎng)站http://www.coremark.org提供了報(bào)告結(jié)果的位置,您不能只輸入一個(gè)CoreMark分?jǐn)?shù)。還有一些其他關(guān)鍵變量可能會(huì)影響您的結(jié)果。
最大的是使用的編譯器和編譯基準(zhǔn)時(shí)設(shè)置的選項(xiàng)。您必須在提交結(jié)果時(shí)報(bào)告該信息。
第二個(gè)主要影響因素是分配內(nèi)存的方式 - 如果它不是堆(malloc),您必須報(bào)告所采用的方法。
第三個(gè)因素,在相關(guān)時(shí),是并行化。您必須報(bào)告創(chuàng)建的上下文的數(shù)量。
還有另一種方法可以報(bào)告結(jié)果。您可以將時(shí)鐘頻率標(biāo)準(zhǔn)化,而不是指定原始CoreMark值,以便專注于架構(gòu)效率。這是一個(gè)CoreMark/MHz值,用于衡量每百萬個(gè)時(shí)鐘周期的迭代次數(shù)。如果報(bào)告此編號(hào),則還必須報(bào)告相對(duì)于處理器時(shí)鐘速度的內(nèi)存速度。如果可以相對(duì)于處理器頻率配置高速緩存頻率,則還必須報(bào)告該配置。
查看某些特定結(jié)果可以幫助顯示各種所需報(bào)告元素如何與不同的基準(zhǔn)分?jǐn)?shù)相關(guān)聯(lián),以及在報(bào)告結(jié)果時(shí)識(shí)別這些元素的重要性。隨后的所有數(shù)字均來自CoreMark網(wǎng)站上公開的結(jié)果列表。
編譯器版本的簡單影響可以在表1的結(jié)果中看到。使用較新的編譯器版本,ADI公司的處理器顯示速度提高了10%,可能表明新編譯器的工作做得更好。 Microchip示例顯示了兩個(gè)更遠(yuǎn)的GNU C編譯器(gcc)版本之間的差異。對(duì)于兩個(gè)恩智浦處理器,所有編譯器都是同一版本的微妙變體,從而最大限度地減少了差異。
ProcessorCompilerCoreMark/MHz模擬器件BF536gcc 4.1.21.01gcc 4.3.31.12Microchip PIC32MX36F512Lgcc 3.4.4 MPLAB C32 v1.00-200710241.90gcc 4.3.2(Sourcery G ++ Lite 4.3-81)2.30NXP LPC1114Keil ARMcc v4.0.0.5241.06gcc 4.3 .3(紅色代碼)0.98NXP LPC1768ARM CC 4.01.75Keil ARMCC v4.0.0.5241.76表1:不同編譯器對(duì)CoreMark結(jié)果的影響。即使使用相同的編譯器,不同的設(shè)置當(dāng)然會(huì)產(chǎn)生不同的結(jié)果因?yàn)榫幾g器試圖以不同方式優(yōu)化程序。表2顯示了一些示例結(jié)果。
ProcessorCompilerSettingsCoreMark/MHzMicrochip
PIC24JF64GA004gcc 4.0.3 dsPIC030,Microchip v3_20-Os -mpa1.01-031.12Microchip
PIC24HJ128GP202gcc 4.0.3 dsPIC030,Microchip v3.12-031.86-mpa1.29Microchip
PIC32MX36F512Lgcc 4.4.4 MPLAB C32 v1.00-20071024-021.71-031.90表2:更改編譯器設(shè)置會(huì)產(chǎn)生不同的CoreMark結(jié)果。
第一個(gè)例子(PIC24JF64GA004),針對(duì)較小的代碼尺寸進(jìn)行優(yōu)化需要降低約10%的基準(zhǔn)性能。在第二種情況下,差異更為顯著,在設(shè)置過程抽象優(yōu)化標(biāo)志(-mpa)時(shí)運(yùn)行速度降低30%。最后一個(gè)處理器上的編譯器設(shè)置之間的差異也反映了優(yōu)化量的差異,從-O3設(shè)置提供的更高速度優(yōu)化中獲益大約10%。
內(nèi)存的影響可以在表3中看到。在第一種情況下,當(dāng)時(shí)鐘頻率超過閃存可以處理的頻率時(shí),會(huì)引入等待狀態(tài),從而降低CoreMark/MHz數(shù)量。類似地,在第二種情況下,DRAM無法跟上50 MHz以上的處理器,因此存儲(chǔ)器和處理器之間的時(shí)鐘頻率比降至1:2,從而降低了CoreMark/MHz數(shù)量。
ProcessorClock
SpeedMemory NotesCoreMark/MHzCoreMarkTI OMAP 3530500Code in FLASH2.4212106002.191314TI Stellaris LM3S9B96 Cortex M3501:1內(nèi)存/CPU時(shí)鐘不可能超過50 Mhz1.9296801.60128表4:更改緩存大小對(duì)CoreMark結(jié)果的影響。 》然而,在這兩種情況下,時(shí)鐘頻率的增加都大于運(yùn)行效率的降低,因此原始CoreMark數(shù)量仍然隨著時(shí)鐘頻率的增加而增加;它只是沒有像頻率那樣增加。點(diǎn)擊最后,緩存大小的影響可以在表4中看到。這里,代碼適合第一個(gè)配置的2 kb緩存,但它完全填充緩存。堆棧上的所有函數(shù)參數(shù)都不適合,因此會(huì)有一些緩存未命中。在第二種情況下,緩存具有兩倍的容量,這意味著它不會(huì)遇到與第一個(gè)示例中相同的緩存未命中,從而為其提供更好的分?jǐn)?shù)。
ProcessorCompilerCoreMark/MHzAnalog器件BF536gcc 4.1.21.01表3:內(nèi)存設(shè)置對(duì)CoreMark結(jié)果的影響。
請(qǐng)注意,與第一種情況的三級(jí)流水線相比,第二種情況有五級(jí)流水線。由于狀態(tài)機(jī)示例的廣泛分支,較長的管道應(yīng)該導(dǎo)致性能下降。當(dāng)分支被錯(cuò)誤預(yù)測(cè)時(shí),較長的管道需要更長的時(shí)間來重新填充。因此,較高的CoreMark分?jǐn)?shù)表明較大的緩存超過了這種降級(jí)。
所有這些例子中的得分都證明了兩個(gè)事實(shí)。首先,單個(gè)數(shù)字(在本例中為CoreMark/MHz)可以準(zhǔn)確地表示底層微控制器架構(gòu)的性能;后面的例子清楚地表明了這一點(diǎn)。其次,背景是重要的。編譯器可以影響它生成的代碼執(zhí)行的程度。這幾乎應(yīng)該是顯而易見的 - 人們花費(fèi)大量時(shí)間來開發(fā)和改進(jìn)編譯器以改進(jìn)他們創(chuàng)建的結(jié)果,但“好”結(jié)果取決于您的目標(biāo)是快速代碼還是小代碼。更快的代碼將運(yùn)行得更快,更小的代碼將不會(huì)運(yùn)行(除非它實(shí)際上有助于優(yōu)化內(nèi)存或緩存利用率)。但是,這些例子顯示的最重要的事情是結(jié)果之間的差異有合理的解釋。它們不是由一些實(shí)際的基準(zhǔn)測(cè)試代碼引起的,這些代碼可能有利于一個(gè)微控制器架構(gòu)而不是另一個(gè),或者是編譯器直接丟棄代碼。從這個(gè)意義上講,CoreMark基準(zhǔn)測(cè)試是公平和平衡的,可以真實(shí)地反映編譯器和體系結(jié)構(gòu),而且只能反映編譯器和體系結(jié)構(gòu)。
-
微控制器
+關(guān)注
關(guān)注
48文章
7936瀏覽量
154270 -
處理器
+關(guān)注
關(guān)注
68文章
19863瀏覽量
234402 -
編譯器
+關(guān)注
關(guān)注
1文章
1659瀏覽量
50089
發(fā)布評(píng)論請(qǐng)先 登錄
LPC微控制器產(chǎn)品族譜
STM32微控制器
AT32微控制器硬件設(shè)計(jì)指南及抗EMC設(shè)計(jì)要點(diǎn)
微控制器的開發(fā)方案


基于MAXQ3120微控制器的性能特點(diǎn)與應(yīng)用分析
如何使用微控制器測(cè)量電容
微控制器到底是什么?微控制器有怎么樣的應(yīng)用
什么是微控制器?如何編程微控制器?

STM32微控制器的技術(shù)特點(diǎn)和性能指標(biāo)
【微控制器基礎(chǔ)】—— 從歷史切入,了解微控制器的五個(gè)要素(下)
【微控制器基礎(chǔ)】——從歷史切入,了解微控制器的五個(gè)要素(上)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論