") 無標(biāo)簽數(shù)據(jù)如何提升人臉識別性能
無標(biāo)簽數(shù)據(jù)如何提升人臉識別性能
隨著模型越來越深,標(biāo)注數(shù)據(jù)越來越難增加,人臉識別可能遇到瓶頸。本文來自MMLab香港中文大學(xué)-商湯科技聯(lián)合實驗室,提出一種有監(jiān)督的Metric用于人臉聚類,來部分解決無標(biāo)注數(shù)據(jù)內(nèi)部結(jié)構(gòu)復(fù)雜、依賴特定Metric、缺乏Outlier控制,以及時間復(fù)雜度等問題。
人臉識別也許是最成功也最先到達(dá)瓶頸的深度學(xué)習(xí)應(yīng)用。在Go Deeper, MoreData,Higher Performance的思想指導(dǎo)下,模型更深了,數(shù)據(jù)卻越來越難增加。目前在人臉的公開數(shù)據(jù)集標(biāo)到了百萬級別,人臉識別百萬里挑一的正確率達(dá)到99.9%(MegaFace Benchmark)之后,發(fā)現(xiàn)再也標(biāo)不動了。標(biāo)注員能標(biāo)出來的數(shù)據(jù)永遠(yuǎn)是簡單樣本,而人臉識別模型是個“深淵”,當(dāng)你凝視“深淵”的時候,“深淵”并不想看到你。
“深淵”想看到這樣的數(shù)據(jù),并且明確被告知不是同一個人:
以及這樣的數(shù)據(jù),并且明確被告知是同一個人:
在把標(biāo)注員弄瘋之前,不如先讓模型自己去猜一猜,說不定就猜對了呢?這其實就是半監(jiān)督學(xué)習(xí)的思路。利用已有的模型對無標(biāo)簽數(shù)據(jù)做某種預(yù)測,將預(yù)測結(jié)果用來幫助模型訓(xùn)練。這種自我增強(qiáng)(Self-Enhanced)的學(xué)習(xí)方式,雖然看起來有漂移(Drift)的風(fēng)險,但實際用起來還挺好用 [5]。對于閉集(Close-Set)的問題,也就是所有數(shù)據(jù)都屬于一個已知的類別集合(例如ImageNet, CIFAR等),只需要模型能通過各種方法,例如標(biāo)簽傳播(labelPropagation)等,預(yù)測出無標(biāo)簽數(shù)據(jù)的標(biāo)簽,再把它們加入訓(xùn)練即可。
然而問題來了,人臉識別是一個開集(Open-Set)的問題。
例如,人臉比對(Verification)、人臉鑒定(Identification)等任務(wù)中,測試樣本的身份(Identity)通常沒有在訓(xùn)練樣本中出現(xiàn)過,測試過程通常是提取人臉特征進(jìn)行比對,而非直接通過網(wǎng)絡(luò)推理得到標(biāo)簽。同樣,對于無標(biāo)注數(shù)據(jù),在采集的過程中,人臉的身份也是未知的。可能有標(biāo)注的數(shù)據(jù)的人臉屬于10萬個人,而新來的無標(biāo)注數(shù)據(jù)屬于另外10萬個人,這樣一來就無法通過預(yù)測標(biāo)簽的方式把這些數(shù)據(jù)利用起來。而聚類不同于半監(jiān)督學(xué)習(xí),只需要知道樣本的特征描述(Feature)和樣本之間的相似度度量標(biāo)準(zhǔn)(Metric)就可以做聚類。聚完類之后再給每個類分配新的標(biāo)簽,同樣可以用來幫助提升人臉模型。
人臉聚類方法
傳統(tǒng)的人臉聚類一般采用LBP、HOG之類的手動設(shè)計的特征,因為這類特征過于過時,不在我們討論的范疇。而深度學(xué)習(xí)時代的人臉聚類,一般采用卷積神經(jīng)網(wǎng)絡(luò)(CNN)中提取出來的特征 [4]。人臉識別的CNN通常把人臉圖片映射(Embedding)到一個高維的向量,然后使用一個線性分類器,加Softmax激活函數(shù)和交叉熵?fù)p失(Cross Entropy Loss)來訓(xùn)練。
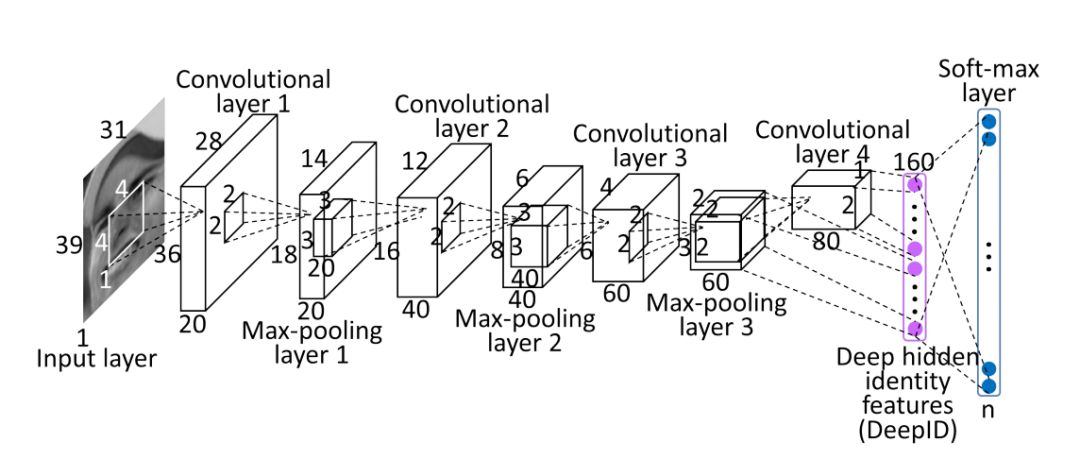
紫色的向量即為人臉特征(圖片來自 [3])
這種方式?jīng)Q定了這些經(jīng)過映射(Embedding)后的人臉在特征空間里分布在不同的錐形(Cone)中(下左圖),因而可以使用余弦相似度(Cosine Similarity)來度量相似度。或者如果對人臉特征做二范數(shù)(L2)歸一化,那么人臉特征則會分布在一個球面上(下右圖),這樣可以使用L2距離來度量。
圖示為2維,實際在高維空間(圖片來自 [6])
有了特征和度量標(biāo)準(zhǔn)之后,就可以考慮如何選擇一個聚類算法了。現(xiàn)成的聚類算法包括K-Means,Spectral, DBSCAN, Hierarchical Agglomerative Clustering (HAC), Rank Order等以及它們的變種。利用這些方法聚類之后,將每一類中的樣本分配相同的標(biāo)簽,不同的類分配不同的標(biāo)簽,就可以用來充當(dāng)訓(xùn)練集了。
到此為止,似乎已經(jīng)可以順利地完成這個任務(wù)了。然而
使用20萬張圖提取特征之后來測試一下這些聚類算法,K-Means花了10分鐘,HAC花了5.7小時,DBSCAN花了6.9小時, Spectral花了12小時。若使用60萬張圖片提取的特征來做聚類,K-Means超內(nèi)存了,HAC花了61小時,DBSCAN花了80小時,Spectral跑到天荒地老之后也甩了一句超內(nèi)存。當(dāng)圖片數(shù)量增加到140萬的時候,幾乎所有的聚類算法都掛了。
K-Means, Spectral, HAC等傳統(tǒng)聚類方法的問題主要在于以下方面:
(a) 聚類算法具有較高的時間復(fù)雜度。例如,K-Means是O(NKT),Spectral是O(N^3),HAC是O(N^2)。
(b) 通常認(rèn)為數(shù)據(jù)分布服從某些簡單的假設(shè)。例如,K-Means假設(shè)數(shù)據(jù)類內(nèi)具有球狀的分布 [2],并且每一類具有相同的方差(Ariance),以及不同的類具有相同的先驗概率。然而對于大規(guī)模人臉聚類,無標(biāo)注數(shù)據(jù)通常來源于開放的場景(in-the-wild),數(shù)據(jù)內(nèi)部的結(jié)構(gòu)比較復(fù)雜,難以一致地服從這些假設(shè)。例如,我們期望數(shù)據(jù)長這樣(如下左圖):

(c) 通常使用某種特定的Metric。例如上述提及的Cosine Similarity和L2距離。同樣,對于復(fù)雜的數(shù)據(jù)結(jié)構(gòu),衡量兩個樣本是否屬于同一類,單純靠樣本之間的局部相似度是不夠的,這個metric需要融合更多信息。
(d) 缺乏較好的離群值(Outliers)控制機(jī)制。Outliers來源于人臉識別模型對難樣本的Embedding誤差,以及觀測到的數(shù)據(jù)不完整。盡管部分聚類算法例如DBSCAN理論上對Outliers魯棒,但從其實際表現(xiàn)來講這個問題遠(yuǎn)沒有得到解決。
有監(jiān)督的Metric
終于可以說說自己的工作了。我們被ECCV2018接收的一篇論文(Consensus-Driven Propagation in Massive Unlabeled Data for FaceRecognition),簡稱CDP [1],嘗試解決上述這些問題中的一部分。我們提出了一種有監(jiān)督的Metric用于人臉聚類,來部分解決無標(biāo)注數(shù)據(jù)內(nèi)部結(jié)構(gòu)復(fù)雜、依賴特定Metric、缺乏Outlier控制的問題,順便還解決了一下時間復(fù)雜度的問題(CDP做到了線性復(fù)雜度),當(dāng)然性能也提升了一大截。
介紹方法之前我們先來介紹一下Affinity Graph。Graph在半監(jiān)督學(xué)習(xí)和聚類上經(jīng)常出現(xiàn)。Affinity Graph的節(jié)點(diǎn)是數(shù)據(jù)樣本,邊代表數(shù)據(jù)之間的相似度。一種常見的Affinity Graph是KNN Graph,即對所有樣本搜索K近鄰之后將樣本與其近鄰連接起來得到。我們的方法CDP基于KNN Graph來構(gòu)建數(shù)據(jù)的結(jié)構(gòu)。
CDP本質(zhì)是學(xué)習(xí)一個Metric,也就是對樣本對(Pairs)進(jìn)行判斷。如下圖,CDP首先使用多個人臉識別模型構(gòu)建成一個委員會(Committee), Committee中每個成員對基礎(chǔ)模型中相連的Pairs提供包括關(guān)系(是否是Neighbor)、相似度、局部結(jié)構(gòu)等信息,然后使用一個多層感知機(jī)(MLP)來整合這些信息并作出預(yù)測(即這個Pair是否是同一個人)。
這個過程可以類比成一個投票的過程,Committee負(fù)責(zé)考察一個候選人(Pair)的各方面信息,將信息匯總給MLP進(jìn)行決定。最后將所有的Positive Pairs組成一個新的Graph稱為Consensus-driven Graph。在此Graph上使用簡單的連通域搜索并動態(tài)剪枝即可快速得到聚類。由于MLP需要使用一部分有標(biāo)簽的數(shù)據(jù)來訓(xùn)練得到,所以CDP是一種基于有監(jiān)督的Metric的聚類方法。
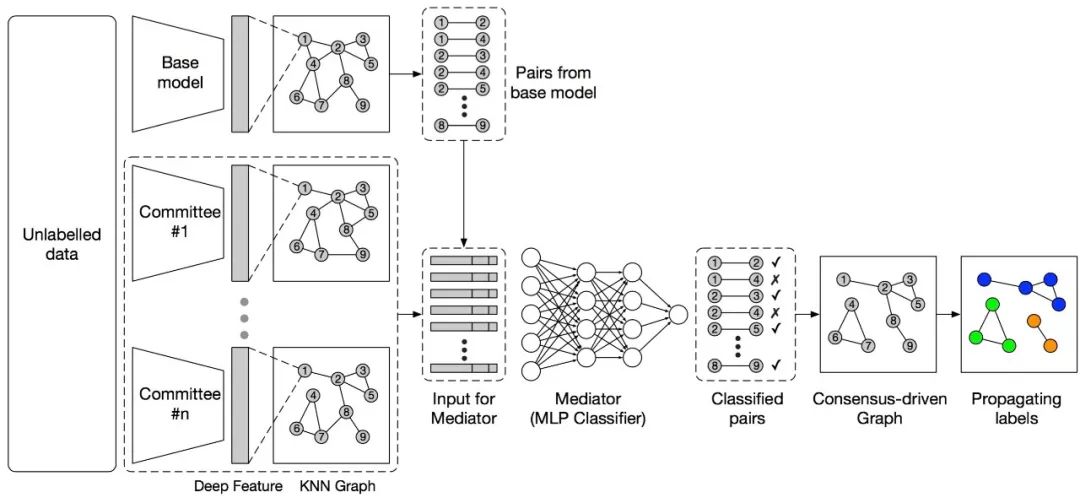
CDP框架
接下來就是激fei動chang人wu心liao的結(jié)果分析了。
在復(fù)雜度上,CDP由于只需要探索局部結(jié)構(gòu),因此除了KNN搜索之外,聚類部分的復(fù)雜度是接近線性的。在20萬數(shù)據(jù)上,不計入KNN搜索(依賴別的庫)的時間的話,CDP單模型的耗時是7.7秒,多模型的耗時是100秒。在140萬數(shù)據(jù)上,CDP單模型的耗時是48秒,多模型的耗時是585秒。試驗結(jié)果上看時間復(fù)雜度甚至低于線性(小于7倍)。
在聚類結(jié)果上,例如對20萬數(shù)據(jù)聚類,即使使用單模型也達(dá)到了89%的fsCore,多模型可以達(dá)到95.8%,強(qiáng)于大部分傳統(tǒng)聚類算法。各種聚類算法運(yùn)行時間和性能測試見GitHub。
我們的實驗中使用CDP聚類后的數(shù)據(jù)加入人臉識別模型的訓(xùn)練之后,可以讓模型達(dá)到接近全監(jiān)督(使用Ground Truth標(biāo)簽)的結(jié)果。如下圖所示:

在兩個測試集(Benchmark)上,隨著數(shù)據(jù)的增多,用CDP聚類結(jié)果訓(xùn)練的人臉模型性能的增長接近全監(jiān)督模型(所有數(shù)據(jù)都使用Groundtruth標(biāo)注)。有趣的是在IJB-A上我們的結(jié)果超過了全監(jiān)督模型,原因可能是訓(xùn)練集的Ground Truth標(biāo)簽會有一些噪聲(Noise),例如誤標(biāo)注,導(dǎo)致全監(jiān)督模型在IJB-A的某些測試樣例上表現(xiàn)不佳。
下圖是切換不同的CNN模型結(jié)構(gòu)后的結(jié)果:

聚類后的部分結(jié)果如下圖所示:
每一組代表聚完類后屬于同一類
我們發(fā)現(xiàn)CDP還可以用來做數(shù)據(jù)和標(biāo)簽清理(Denoise)。例如一個標(biāo)注好的數(shù)據(jù)集可能有一些標(biāo)錯的樣本,或者非常低質(zhì)量的圖片,可以使用CDP來找到這些圖并舍棄。如下圖:
每一組人臉在原始標(biāo)注中屬于同一個人,左上角數(shù)字是CDP分配的標(biāo)簽,紅框中的樣本為CDP丟棄的樣本,包括:1. 被錯誤標(biāo)注進(jìn)該類,實際是一個孤立點(diǎn)的樣本。2. 低質(zhì)量圖片,包括過度模糊、卡通等。
在這篇工作中我們發(fā)現(xiàn),基于學(xué)習(xí)的Metric能基于更多的有效信息進(jìn)行判斷,會比手動設(shè)計的Metric更擅長解決比較復(fù)雜的數(shù)據(jù)分布。另外,這種類似多模型的投票的方式在魯棒性上帶來了很大提升,這樣可以從無標(biāo)簽數(shù)據(jù)中發(fā)掘出更多的難樣本。
-
人臉識別
+關(guān)注
關(guān)注
76文章
4069瀏覽量
83656 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22630
原文標(biāo)題:人臉聚類那些事兒:利用無標(biāo)簽數(shù)據(jù)提升人臉識別性能
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
CLRC663如何增強(qiáng)對RFID標(biāo)簽ic的識別距離?
安信可AI人臉識別方案
人臉識別技術(shù)的算法原理解析
人臉識別技術(shù)的應(yīng)用場景
無感人臉識別考勤解決方案:如何用科技實現(xiàn)考勤的無感化、智能化

校園人臉識別閘機(jī)通道的應(yīng)用

人臉識別技術(shù)的原理介紹
如何設(shè)計人臉識別的神經(jīng)網(wǎng)絡(luò)
人臉識別模型訓(xùn)練流程
人臉識別模型訓(xùn)練失敗原因有哪些
人臉識別模型訓(xùn)練是什么意思
人臉檢測和人臉識別的區(qū)別是什么
人臉檢測與識別的方法有哪些
人臉識別門禁系統(tǒng)賦能社區(qū)安防
如何挑選理想的人臉識別考勤系統(tǒng)產(chǎn)品?人臉識別設(shè)備的選型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論