") 移動端人像分割開發(fā)
移動端人像分割開發(fā)

整理 | 包包
個人對移動端神經(jīng)網(wǎng)絡開發(fā)一直饒有興致。去年騰訊開源了NCNN框架之后,一直都在關注。近期嘗試將分割網(wǎng)絡移植到NCNN,能夠在手機端實現(xiàn)一些有趣的應用,本文就幾個技術話題作相關介紹。
神經(jīng)網(wǎng)絡選擇
目前做segmentation常用的一些神經(jīng)網(wǎng)絡網(wǎng)絡有如下幾個可以選擇:
在移動端做人像分割有兩大優(yōu)勢,首先是隱私,其次是可以做到實時,能夠創(chuàng)造更多玩法。因為UNET模型比較簡單,干脆就從這個入手。下面是UNET網(wǎng)絡結構:
首先我采用了基于keras的版本: https://github.com/TianzhongSong/Person-Segmentation-Keras,訓了一個基本模型,大小為39M, iphone X上15秒處理一幀。明顯這個速度太慢,需要進行改造。
移動端Inference框架
經(jīng)過調研,粗略比較了幾個神經(jīng)網(wǎng)絡框架:
其中使用難易程度,主要跟我個人習慣有關。NCNN框架比較好,代碼不多,而且兼容iOS和安卓(臺式機以及嵌入式環(huán)境同樣支持),同時底層計算采用匯編做了優(yōu)化。NCNN只實現(xiàn)神經(jīng)網(wǎng)絡的forward部分,沒有反向傳播,所以訓練仍舊依賴其他開源框架,現(xiàn)在幾大框架都遵守ONNX協(xié)議,理論上各種框架模型之間互相轉換并不存在什么問題,工具也都是開源的。
不過keras沒辦法直接轉成ncnn模型,研究過通過onnx模型做中間跳板,采用了一些開源的轉換工具,也是一堆問題。NCNN支持幾個神經(jīng)網(wǎng)絡訓練框架:caffe/mxnet/pytorch,在ncnn的github有一篇issue里nihui推薦采用MXNET,因此MXNET也成為了我的首選。其他框架往NCNN轉換工具:
NCNN轉換Tensorflow模型有問題; Caffe沒有Pytorch和MXNET好用; 最終在MXNet和Pytorch之間選擇了MXNet。
人像數(shù)據(jù)集
https://github.com/lemondan/HumanParsing-Dataset
https://github.com/ZhaoJ9014/Multi-Human-Parsing_MHP
COCO人像數(shù)據(jù)集 – 加入后效果質的飛躍
ADE20K
網(wǎng)上找了上面幾個數(shù)據(jù)集,抽取出人像部分,采用基本的flip/crop/rotate操作做了擴充,得到228423張訓練樣本,另外湊了9064張驗證樣本。
模型轉換(MXNET->NCNN)
MXNET的UNET版本并沒有現(xiàn)成可用的合適版本。參照其他版本的UNET,自己coding完成一個版本。代碼請參考: https://github.com/xuduo35/unet_mxnet2ncnn。
在這個基礎上訓練完成,用來測試ncnn轉換基本可用。這里提一下轉換過程遇到的一些問題和解決方案。
一個是調用ncnn extract函數(shù)會crash,經(jīng)過調查,發(fā)現(xiàn)mxnet2ncnn工具也有bug,blob個數(shù)算錯,其次是input層one_blob_only標志我的理解應該是false,不知道什么原因轉換過來的模型這邊是true,導致forward_layer函數(shù)里面bottoms變量訪問異常。后來一層層extract出來打印輸出的channel/width/height調查后又發(fā)現(xiàn),自己代碼里unet.py里的name為pool5寫成了pool4,前面的crash跟這個致命錯誤有關系也有直接關聯(lián)。
第二個問題是轉成ncnn后的預測結果死活不對。只能一層層去檢查,寫了幾個簡單的工具可以打印中間隱藏層的結果(代碼: https://github.com/xuduo35/unet_mxnet2ncnn/check.py)。在這個基礎之上,發(fā)現(xiàn)是第一次反卷積就出了問題(mxnet神經(jīng)網(wǎng)絡trans_conv6的輸出)。結果完全不一致,按個人理解,反卷積算法會出問題的可能性基本為0,所以把mxnet這一層的權重值打印了出來。再在mxnet2ncnn的代碼里把對應的參數(shù)打印,最后發(fā)現(xiàn)是num_group出了問題,簡單處理就是把mxnet2ncnn.cpp里的反卷積num_group固定為1,終于解決問題。得到正確的輸出結果:
中間還遇到一些ncnn和mxnet之間圖像格式之類的轉換問題,特別是浮點數(shù)的處理,就不啰嗦了。另外,調試過程發(fā)現(xiàn),ncnn的中間層輸出和mxnet的輸出不是完全一致,可能是有一些參數(shù)或者運算細節(jié)問題,不影響最后mask結果,暫時忽略。
幾個問題
到目前為止還存在幾個問題,1. 模型比較大;2. 單幀處理需要15秒左右的時間(Mac Pro筆記本,ncnn沒有使用openmp的情況);3. 得到的mask結果不是特別理想。針對這三個問題,對網(wǎng)絡結構進行調整。
1. 模型比較大
采取將網(wǎng)絡卷積核數(shù)量減少4倍的方式,模型大小下降到2M,粗略用圖片測試,效果也還可以。同時把之前用0值填充圖片的方式,改成用邊界值填充,因為測試的時候發(fā)現(xiàn)之前的方式總在填充的邊界往往會出現(xiàn)檢測錯誤。
2. 單幀處理需要15秒左右的時間
按照第一步處理之后,基本上一張圖片只要1秒鐘就處理完成,。在手機上由于NCNN做了優(yōu)化,經(jīng)過測試速度是Mac Pro的好幾倍。
3. 得到的mask結果不是特別理想
在權衡模型大小和準確率的基礎上修改UNET網(wǎng)絡結構,具體不再贅述。
最終結果
-
移動端
+關注
關注
0文章
42瀏覽量
4595
發(fā)布評論請先 登錄

【BPI-CanMV-K230D-Zero開發(fā)板體驗】視頻會議場景下的 AI 應用(電子云臺 EPTZ、人像居中 / 追蹤、畫中畫)
HarmonyOS 代碼工坊的指尖開發(fā),讓 APP 開發(fā)所見即所得
【正點原子STM32MP257開發(fā)板試用】基于 DeepLab 模型的圖像分割
labview使用tcp接收下位機數(shù)據(jù),最大也就200Hz,如何提高速率到500Hz?
Arm 公司面向移動端市場的 ?Arm Lumex? 深度解讀
MWC2025亮點放送 探索Arm如何塑造移動端技術未來

BEM在移動端開發(fā)中的應用案例
MediaTek天璣移動平臺賦能騰訊會議端側AI人像分割模型
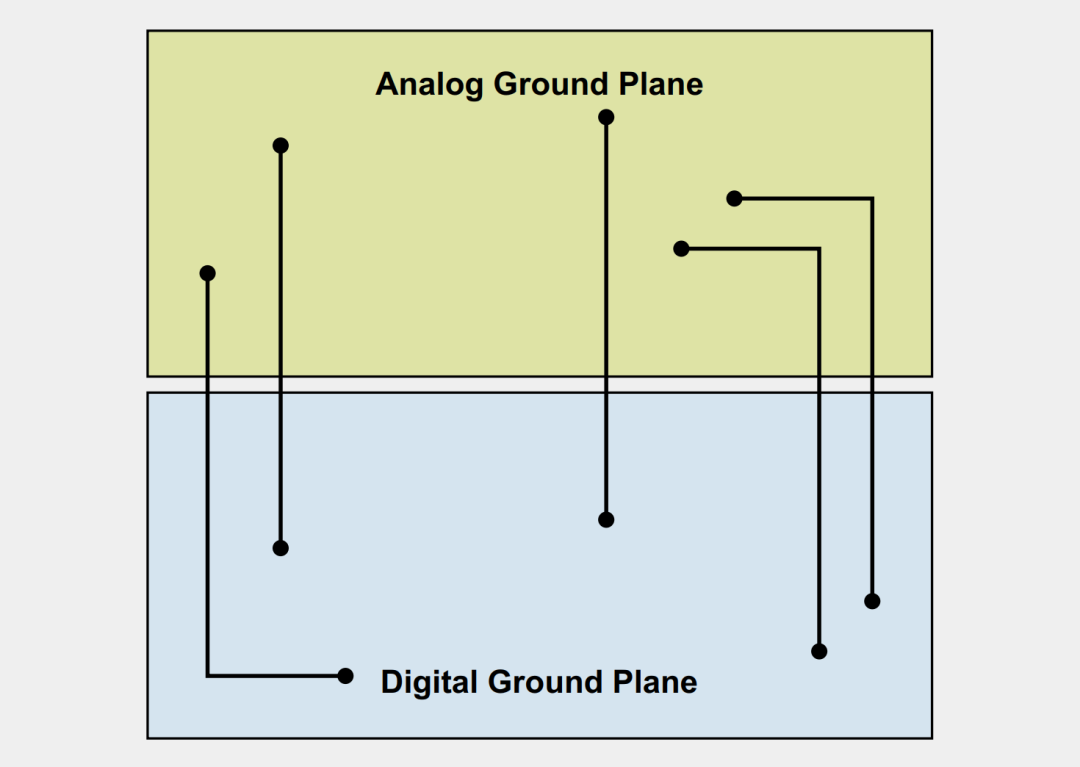
淺談分割接地層的利弊





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論