 揭秘字節跳動AILab為何吸引最優秀90后
揭秘字節跳動AILab為何吸引最優秀90后
AI Lab在一個公司應當是什么樣的角色?字節跳動副總裁、人工智能實驗室主任馬維英表示:AI Lab不僅是公司內部的AI研究所,也是AI技術提供商與服務商,應當注重與高校和政府的合作,并強調人才培養的重要性。
AI Lab應當是公司的“廠牌”。
字節跳動實現建設全球創作與交流平臺的愿景,以及取得當前全球化進展,都離不開人工智能技術提供的關鍵支撐。字節跳動一向重視人工智能技術的發展,而其AI Lab,最開始是因NLP領域科學家李磊的加入而出名,隨后馬維英、李航等大佬也陸續入伙。
與此同時,今日頭條母公司字節跳動,推出抖音、火山小視頻等一些列風靡全球的產品,估值上升、用戶增長。
而這一切背后提供支撐的人工智能實驗室卻鮮少露面,這一年來字節跳動的AI Lab究竟都做了什么呢?作為亞研院前常務副院長的馬維英,所帶隊的字節跳動AI Lab又有何不同呢?
11月11日,字節跳動舉辦了2018 AI OPENDAY沙龍。活動展示了字節跳動AI Lab在計算機視覺、自然語言處理、語音和視頻處理、機器學習等領域中取得的一些列成果。
而后字節跳動副總裁、人工智能實驗室主任馬維英,針對此次沙龍活動做了主題演講,慢慢揭開了字節跳動AI Lab神秘的面紗。
馬維英談AI Lab吸引優秀人才的秘籍:五大AI戰略資源是關鍵
相似于人才培養:給予自由,讓興趣成為自驅的動力
馬維英表示,之前在微軟亞洲研究院時特別欣賞其培養人才的一個方式,就是當新人剛入職時,不會立刻讓他們選擇具體研究方向,而是會給予他們足夠多的自由和空間,激勵他們尋求自己最為感興趣的一個領域。
在這個方面,字節跳動也是如此的。馬維英很感謝微軟給他的成長空間,因此到了字節跳動之后,他也在新的團隊延續了這樣的氛圍。字節跳動AI lab特別喜歡自己有想法、能夠自驅、愿意不斷去學習且更加無所畏懼的研究人員;而不是害怕失敗,著重于眼前利益的人。
區別于數據與場景:微軟研究院專注于技術轉移,字節跳動AI Lab鼓勵研究員直接參與到產品研發,利用豐富的應用場景、大量的數據和用戶反饋推進科研和技術創新
除了基礎研究這方面,微軟做的更多的是技術轉移。與微軟不同的是,字節跳動擁有豐富的應用場景。大量的數據和反饋對AI Lab的工作是有幫助的。就像在象牙塔里搞研究,有時反而解決不了問題。只有解決真實的應用場景問題,才是所謂的Real Impact。
正如最近一位UC Berkeley的教授所述,要做“Use Inspired”的研究。而在字節跳動,非常幸運一點就是,人類所有的數據都在信息和內容里。
再具體一點可總結為一句話:字節跳動擁有做AI最重要的五個戰略資源。
大數據:最好這家公司能夠擁有全世界最大的數據資源,擁有數據才是“王道”;
應用場景:在字節跳動,研究人員每天都能夠從公司的應場景中找到問題,并想要去解決;
算力:而字節跳動的Internet Data Center在國內也是比較出眾的;
AI需閉環:其實很多用戶交互相當于遞給了你一份大數據的,提供了更為細粒度的標注數據,而字節跳動每日全球活躍用戶所提供的數據之海量,堪稱一筆財富;
人才:最頂尖聰明的人才是非常關鍵的一點。不僅公司內部要有這樣的人才,最好與之相關的學術界、產業界、社區都是頂級的人才。
在基礎研究方面,字節跳動的AI Lab研究領域包括計算機視覺、自然語言處理、機器學習、語音&音頻處理、數據&知識挖掘、計算機圖像學、系統&網絡、信息安全以及工程&產品。
馬維英表示,字節跳動會在每個領域中,都會招聘最優秀的人才,而在招聘后不會立即確定他們的方向,而是會讓他們摸索自己感興趣的方向,而后再做出選擇。
除了基礎研究,字節跳動AI Lab也非常重視工程落地的能力,因此也倍加關注對這方面的人才招聘。將工程團隊與科研研究人員混搭在一起,做更好的創新,并輸出核心技術,孵化產品,做到真正的AI應用落地。
正因如此,字節跳動吸引了一大批優秀的“新鮮血液”。例如,來自字節跳動AI Lab的一位90后研究人員,不僅論文被Transition of ACL收錄,還被邀請去了墨爾本做現場演講。
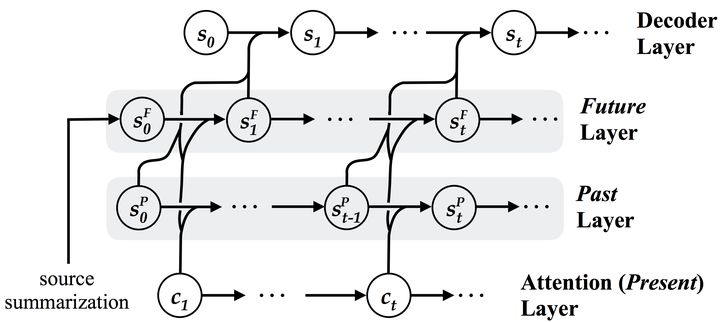
該論文中所提出的模型在中英,德英和英法三個標準數據集上可以顯著地提高基線系統的性能,相比于老一輩的「覆蓋率模型」擁有更好的翻譯質量和對齊質量。
該研究也已成功的應用到了字節跳動旗下多款國際產品中(如TopBuzz、Tik Tok等等),為全球上億的用戶們提供著內容翻譯服務。
馬維英談招聘標準——三個關鍵字:
馬維英老師還透露了他在招聘人才時的標準,總結為三個關鍵字:
數學功底:能夠知曉問題的本質,對模型能夠有透徹的了解,而不是把它當一個黑箱或者工具,簡單的調調參數;
編程能力:有很好的想法,但是無法實現也是不行的;
態度:人際溝通、表達,對工作的態度也是非常重要的。
另外,馬維英老師也非常注重眼神的交流,“大概溝通十分鐘,我就能看出一個人特質。”馬維英老師笑言,這可能是他在招聘中獨有的一種天賦。
字節跳動AI Lab定位:公司內部的研究所和技術服務商
國內外各大巨頭與初創企業紛紛成立人工智能實驗室,而各家企業人工智能實驗室所關注與努力的側重有所不同。
字節跳動人工智能實驗室成立于2016年,依托字節跳動的海量數據,專注于人工智能領域的前沿技術研究,并將研究成果應用于字節跳動的產品中,利用人工智能幫助內容的創作、分發、互動、管理。將人工智能最早大規模應用于信息分發便是字節跳動早期發展的核心。
AI時代下的4種管道連接人和信息,促進交流和創作
這4種主要的方式分別是推薦、搜索、助理與社區/社交。推薦和助理都屬于比較被動的方式,會根據用戶的所好進行內容的分發;搜索在今天也仍然重要,它是一種主動獲取行為;新一代的語音助理能夠讓用戶更加自然地與計算機進行交互,從而達到幫助用戶的目的;最后,類似轉發“朋友圈”這種社交式的信息傳播也是非常重要的。
新一代AI驅動信息平臺,使得交流與創作方式更加智能
人工智能基礎設施、平臺與服務,基于大數據、人工智能學習數據流的語義表示,對信息進行分析、處理、挖掘、理解和組織,使得內容能夠在分發、搜索、互動、過濾和運營方面變得更加智能,做到人工智能輔助消費與生產。
所以,人工智能實驗室所肩負的使命是艱巨而又重要的。
AI Lab賦能產品、服務人類
短視頻已然成為一個內容形態的爆發點。特別是計算機視覺、智能語音賦予了每位用戶更強的創作能力。
抖音是字節跳動風靡全球的產品。這個產品背后有非常多的 AI 技術。比如,抖音是一個開放共享的平臺,內容審核方面的挑戰是非常大的。字節跳動一直用人工智能輔助審核,過濾理解這些視頻內容,進行版權識別。
目前平臺上,每天有龐大數量的短視頻內容被創作出來。而機器學習模型上線之后,也在持續不斷迭代完善。
在視頻內容領域也希望能夠做出更好的搜索。視頻的搜索需要對視頻的內容有更好的理解,包括動作的理解、物體的檢測跟蹤,還有視頻里的環境識別。也希望針對每一個視頻,AI都能理解它的情感和情緒。
連接人跟信息是一個人類社會的基礎設施。在這個設施的運作過程中,能夠利用大數據、豐富應用的場景、大量的活躍用戶,去不斷完善和迭代,進一步賦能。而技術的進步最終是服務于人類的。
截至2018年10月24日,頭條尋人共彈窗52824尋人啟事,找到7401
字節跳動將人工智能結合產品功能積極服務于公益,兩年半時間成功尋回7254名走失者的“頭條尋人”,這是一個典型的運用人工智能促進信息效率,進而服務公益的產品機制:結合智能推薦和地理推送技術,以走失者走失地為圓心,根據走失者行走速度等信息進行數據分析和計算,預估出可能的走失范圍,在此范圍內推送尋人信息,實現每條尋人信息的精準地理范圍覆蓋和人群觸達,從而大大提高尋人成功率。
9月底上線、目前已成功尋回30名走失者的“抖音尋人”和“頭條尋人”工作原理一致,只是推送的尋人信息變成了短視頻形式,運用自動生成視頻技術,一條文字版的尋人信息,不到10秒鐘,即可自動生成為一條抖音尋人視頻。
馬維英對字節跳動AI Lab的定義為:公司內部的AI技術提供商和服務商,于未來將成為公司對外輸出AI能力的重要部門。
AI實力全方位展示:問鼎CVPR、NIPS、NAACL等頂會,榮獲吳文俊人工智能科學技術獎
一個人工智能實驗室的成功,少不了頂尖“智腦”的相聚與思想的碰撞。而字節跳動AI Lab可謂是群賢畢至,包括大家熟知的馬維英、李航、李磊等。
除了擁有大量優秀的科學領軍人物之外,2018年字節跳動AI Lab團隊建設和成長方面也是收獲頗豐。AI Lab團隊總人數由去年的65人增長至150人,計算機視覺、自然語言、機器學習、系統&網絡的團隊人數比去年增加一倍之多,而語音&音頻、安全以及美國AI Lab的團隊人數更是飛速增長。
不僅在團隊建設,字節跳動AI Lab在學術和項目成果方面也可謂是碩果累累。
11月11日,在字節跳動舉辦的2018 AI OPENDAY沙龍活動中,展出了AI Lab許多優秀的項目與研究。
Deep Understanding of Live Soccer Matches
已被CVPR 2018接收
項目介紹:基于計算機視覺技術,系統可以對足球比賽視頻進行深度理解和信息挖掘,豐富球迷的觀賽體驗。該系統在2018世界杯期間介入今日頭條客戶端直播間,實時提供精彩時刻剪輯動畫、雙方進攻防守統計、足球運動熱力圖等多種信息;并于賽后為自動寫作機器人Xiaoming Bot提供圖像素材,豐富文章內容。
目標檢測
軌跡跟蹤
生成鳥瞰視角
捕捉精彩瞬間
相關技術:
檢測&語義分割:基于SSD的目標檢測,逐幀輸出球員和足球的位置;基于DeepSORT的多目標跟蹤,使用Kalman Filter對球員和足球的運動進行建模使用度量學習對球員外觀建模。
相機估計&語義分割:檢測球場上的關鍵點,計算單應性變換參數,以此來估計相機的拍攝角度。
號碼識別&球員聚類:使用半監督的空間變換網絡(STN)在檢測框內提取號碼區域進行識別。
精彩時刻檢測:對固定劃窗內的片段進行分類,包含射門、任意球、角球、受傷等多種類別。
統計分析:基于上述多種結構化信息,輸出多種統計指標,包括雙方控球率、足球運動熱力圖及控球區域分布等。
相比于人類作者,小明的效率和產量高,2秒就能成稿,每場比賽賽后發稿,2年內生成12萬粉絲和10億閱讀。過去頭條平臺上許多體育播報是由小明寫的,他每天讀很多內容,綜合網上文字描述理解和圖片例子和視頻理解能夠自動生成一個內容,分發給對某一類信息感興趣的讀者。
xiaomingbot寫作機器人也因此獲得了吳文俊人工智能科學技術獎。
BRITS:BidirectionalRecurrent Imputation for Time Series
NIPS 2018
項目介紹:
時間序列在許多分類、回歸任務中被廣泛用作信號。時間序列中存在許多缺失值,這是普遍存在的。給定多個相關時間序列數據時,該如何填補缺失值并預測其類標簽呢?現有的歸一化方法往往對潛在的數據生成過程有很強的假設,比如狀態空間中的線性動力學。
本文提出了一種新的基于遞歸神經網絡的時間序列數據缺失值估計方法,BRITS算法。該方法直接學習雙向遞歸動力系統的缺失值,沒有任何具體的假設。將賦值作為RNN圖的變量,在反向傳播過程中可以有效地進行更新。
算法優勢:
(a)可以處理時間序列中多個相關缺失值;
(b)推廣到具有非線性動力學的時間序列;
(c)提供數據驅動的估算程序,適用于缺少數據的一般設置。
實驗結果:
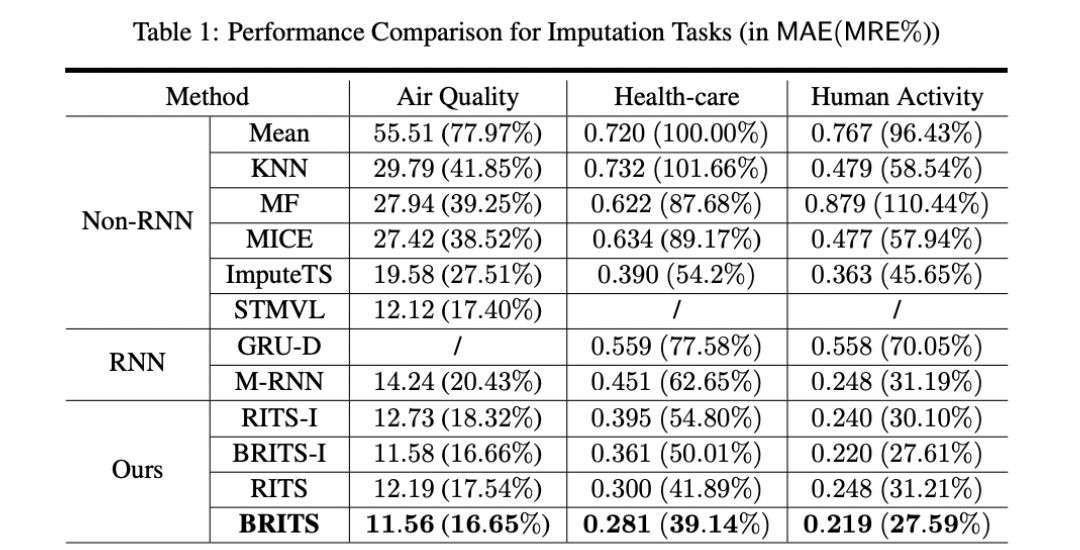
在三個真實世界數據集上評估BRITS模型,包括空氣質量數據集,醫療保健數據和人類活動的本地化數據。實驗表明,該模型在插補和分類/回歸精度方面都優于最先進的方法。
Reinforced Co-Training
NAACL 2018
項目介紹:
Co-Training是一種流行的半監督學習框架,除了少量標記數據外,使用大量的未標記數據。Co-Training方法利用未標記數據上的預測標簽,并基于預測置信度選擇樣本來進行增強訓練。
然而,在現有的協同訓練方法中,樣本的選擇是基于一種預先確定的策略,這種策略忽略了未標記子集和標記子集之間的抽樣偏差,并且無法挖掘數據空間。
本文提出了一種新的方法——強化Co-Training,來選擇高質量的未標記樣本,以便更好地進行Co-Training。更具體地說,該方法使用Q-learning學習一個帶有小標記數據集的數據選擇策略,然后利用這個策略自動訓練聯合訓練分類器。
實驗結果:
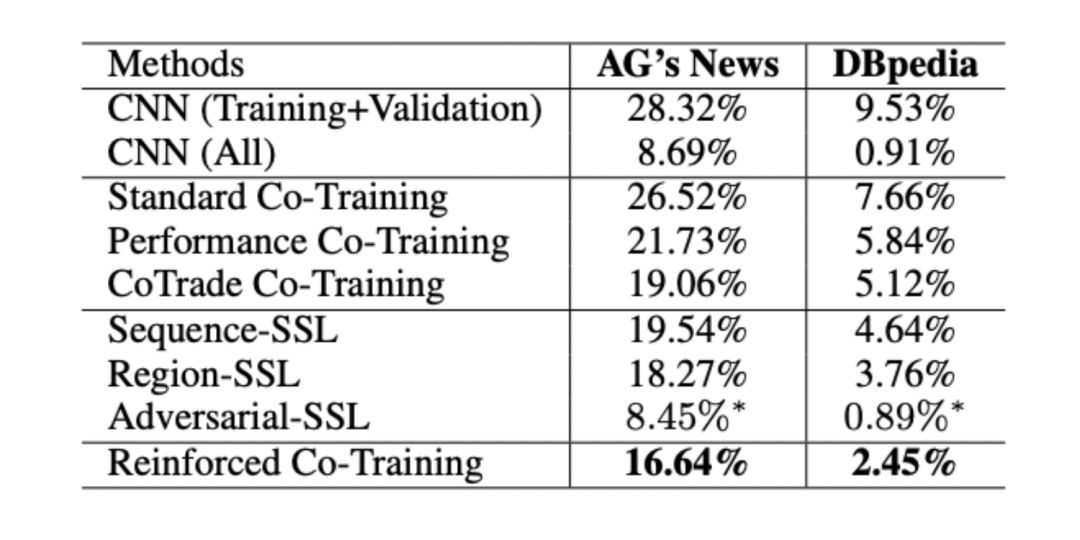
實驗結果表明,本文提出的方法能夠獲得更準確的文本分類結果。
獨木難成林,AI Lab需產學研結合
AI Lab與高校合作
珠穆朗瑪計劃:征集來自計算機科學領域的相關研究提案,為學者的技術研究提供數據、資金等多維度支持。
校企協同,教學人員雙向流動:一線工程師赴校宣講授課,舉辦AI競賽開放海量數據,頭條青年訪問學者。
AI Lab與學術機構合作
2018 Byte Cup:
2018 Byte Cup國際機器學習競賽是一項面向全球的機器學習競賽,旨在促進機器學習的學術研究和具體應用。Byte Cup 2018的主題是自動生成文本標題。
AI Lab與產業合作
字節跳動人工智能實驗室不僅與高校與學術機構有合作,還與產業界有著密切的合作。
2018年人工智能與實體經濟深度融合創新項目公示,字節跳動申報的“基于分布式機器學習平臺的通用人工智能應用解決方案項目”入選;
“面向移動端的低功耗超時AR-VR開放平臺項目”入選2018雙創周“顛覆性創新榜”TOP10;
北京市市長陳寧領銜,北京市科委牽頭,集首都高校、科技專家及領軍科技企業智囊之力,為提高北京市新一代人工智能科技創新能力而集中建設的“北京智源研究院”,字節跳動為智能研究院發起成立單位之一,字節跳動技術戰略研究院院長張宏江出任研究院理事長。
-
人工智能
+關注
關注
1804文章
48737瀏覽量
246678 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46580 -
大數據
+關注
關注
64文章
8952瀏覽量
139525
原文標題:馬維英:AI Lab是公司最能冒險的部門,五大AI戰略資源是鑰匙
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論