") 第一個(gè)支持圖神經(jīng)網(wǎng)絡(luò)的并行處理框架出現(xiàn)了
第一個(gè)支持圖神經(jīng)網(wǎng)絡(luò)的并行處理框架出現(xiàn)了

第一個(gè)支持圖神經(jīng)網(wǎng)絡(luò)的并行處理框架出現(xiàn)了!北京大學(xué)、微軟亞洲研究院的研究人員近日發(fā)表論文,提出NGra,這是第一個(gè)支持大規(guī)模GNN的系統(tǒng)。
GNN(圖神經(jīng)網(wǎng)絡(luò))代表了一種新興的計(jì)算模型,這自然地產(chǎn)生了對在大型graph上應(yīng)用神經(jīng)網(wǎng)絡(luò)模型的需求。
但是,由于GNN固有的復(fù)雜性,這些模型超出了現(xiàn)有深度學(xué)習(xí)框架的設(shè)計(jì)范圍。此外,這些模型不容易在并行硬件(如GPU)上有效地加速。
近日,北京大學(xué)、微軟亞洲研究院的多位研究人員在arXiv上發(fā)布了一篇新論文,提出了解決這些問題的有效方案。
論文題為Towards Efficient Large-Scale Graph Neural Network Computing:
論文地址:https://arxiv.org/pdf/1810.08403.pdf
作者表示:“我們提出NGra,這是第一個(gè)基于圖形的深度神經(jīng)網(wǎng)絡(luò)并行處理框架。”
NGra描述了一種新的SAGA-NN模型,用于將深度神經(jīng)網(wǎng)絡(luò)表示為頂點(diǎn)程序(vertex programs) ,其中每一層都在明確定義的圖形操作階段(Scatter,ApplyEdge,Gather,ApplyVertex)。
這個(gè)模型不僅允許直觀地表示GNN,而且還可以方便地映射到高效的數(shù)據(jù)流表示。NGra通過GPU核心或多GPU的自動(dòng)圖分區(qū)和基于chunk的流處理透明地解決了可擴(kuò)展性挑戰(zhàn),仔細(xì)考慮了數(shù)據(jù)局部性、數(shù)據(jù)移動(dòng)以及并行處理和數(shù)據(jù)移動(dòng)的重疊。
NGra通過在GPU上進(jìn)行高度優(yōu)化的Scatter / Gather操作進(jìn)一步提高了效率,盡管它具有稀疏性。我們的評估表明,NGra可以擴(kuò)展到現(xiàn)有框架無法直接處理的大型實(shí)際圖形,而在TensorFlow的multiple-baseline設(shè)計(jì)上,即使在小規(guī)模上也可以實(shí)現(xiàn)約4倍的加速。
第一個(gè)支持大規(guī)模GNN的系統(tǒng)
NGra是第一個(gè)支持大規(guī)模GNN(圖神經(jīng)網(wǎng)絡(luò))的系統(tǒng),這是一個(gè)在GPU上可擴(kuò)展、高效的并行處理引擎。
NGra自然地將數(shù)據(jù)流(dataflow)與頂點(diǎn)程序抽象(vertex-program abstraction)結(jié)合在一個(gè)新模型中,我們將其命名為SAGA-NN(Scatter-ApplyEdge-Gather-ApplyVertex with Neural Networks)。
雖然SAGA可以被認(rèn)為是GAS(Gather-Apply-Scatter)模型的變體,但SAGA-NN模型中的用戶定義函數(shù)允許用戶通過使用數(shù)據(jù)流抽象來表示對vertex或edge數(shù)據(jù)(被視為tensors)的神經(jīng)網(wǎng)絡(luò)計(jì)算,而不是專為傳統(tǒng)圖形處理而設(shè)計(jì)(例如PageRank、 connected component和最短路徑等算法)
與DNN一樣,高效地使用GPU對于GNN的性能至關(guān)重要,而且由于要處理的是大型圖形結(jié)構(gòu),這一點(diǎn)更為重要。為了實(shí)現(xiàn)超出GPU物理限制的可擴(kuò)展性,NGra將圖形(頂點(diǎn)和邊緣數(shù)據(jù))透明地劃分為塊(chunk),并將SAGA-NN模型中表示的GNN算法轉(zhuǎn)換為具有chunk粒度的運(yùn)算符的dataflow graph,從而在單個(gè)GPU或多個(gè)GPU上啟用基于chunk的并行流處理。
NGra engine的效率在很大程度上取決于NGra如何管理和調(diào)度并行流處理,以及在GPU上關(guān)鍵圖形傳播運(yùn)算符Scatter和Gather的實(shí)現(xiàn)。
NGra非常注重?cái)?shù)據(jù)局部性,以最大限度地減少GPU內(nèi)存中的數(shù)據(jù)交換,并在GPU內(nèi)存中最大化數(shù)據(jù)塊的重用,同時(shí)將數(shù)據(jù)移動(dòng)和計(jì)算以流的方式重疊。
對于多GPU的情況,它使用 ring-based streaming機(jī)制,通過直接在GPU之間交換數(shù)據(jù)塊來避免主機(jī)內(nèi)存中的冗余數(shù)據(jù)移動(dòng)。
與其他基于GPU的圖形引擎關(guān)注的傳統(tǒng)圖形處理場景不同,在GNN場景中,可變頂點(diǎn)數(shù)據(jù)本身可能無法容納到GPU設(shè)備內(nèi)存中,因?yàn)槊總€(gè)頂點(diǎn)的數(shù)據(jù)可以是特征向量( feature vector)而不是簡單的標(biāo)量(scalar)。因此,我們的方案更傾向于在每個(gè)頂點(diǎn)數(shù)據(jù)訪問中利用并行性,從而提高內(nèi)存訪問效率。
我們通過使用vertex-program abstraction和圖形傳播過程的自定義運(yùn)算符擴(kuò)展TensorFlow,從而實(shí)現(xiàn)NGra。
我們利用單個(gè)服務(wù)器的主機(jī)內(nèi)存和GPU的計(jì)算能力,證明NGra可以擴(kuò)展以支持大型圖形的各種GNN算法,其中許多是現(xiàn)有深度學(xué)習(xí)框架無法直接實(shí)現(xiàn)的。
與小型graph上的TensorFlow相比,它可以支持GPU,NGra可以獲得最多4倍的加速。我們還廣泛評估了NGra的多重優(yōu)化所帶來的改進(jìn),以證明其有效性。
接下來的部分將描述SAGA-NN編程抽象,NGra系統(tǒng)的組件,以及NGra的實(shí)現(xiàn)和評估。
NGra程序抽象
基于圖(graph)的神經(jīng)網(wǎng)絡(luò)(GNN)是根據(jù)圖形結(jié)構(gòu)定義的一類通用神經(jīng)網(wǎng)絡(luò)架構(gòu)。
圖中的每個(gè)頂點(diǎn)或邊可以與張量數(shù)據(jù)(通常是vector)相關(guān)聯(lián),作為其特征或嵌入。GNN可以堆疊在多個(gè)層中,迭代傳播過程在同一個(gè)圖上逐層進(jìn)行。
在圖的每個(gè)層中,頂點(diǎn)或邊緣要素沿邊緣變換和傳播,并在目標(biāo)頂點(diǎn)聚合,以生成下一層的新要素。轉(zhuǎn)換可以是任意的DNN計(jì)算。
圖還可以包含每個(gè)頂點(diǎn),每個(gè)邊緣或整個(gè)圖形的標(biāo)簽,用于計(jì)算頂層的損失函數(shù)。然后從底層到頂層執(zhí)行前饋計(jì)算(feedforward computation)和反向傳播。
圖1描述了一個(gè)2層的GNN的前饋計(jì)算。
圖1
我們使用Gated Graph ConvNet(G-GCN)算法作為一個(gè)具體示例。 Graph ConvNet概括了卷積運(yùn)算的概念,通常應(yīng)用于圖像數(shù)據(jù)集,用于處理任意圖形(例如knowledge graph)。Gated Graph ConvNet進(jìn)一步結(jié)合了門控機(jī)制,因此模型可以了解哪些邊對學(xué)習(xí)目標(biāo)更重要。
G-GCN每一層的前饋計(jì)算如圖2所示:
圖2:SAGA-NN模型中,Gated Graph ConvNet的layer,其中?指矩陣乘法。
NGra系統(tǒng)的組成
NGra提供dataflow和vertex program abstractions的組合作為用戶界面。
NGra主要包括:
一個(gè)前端,它將SAGA-NN模型中實(shí)現(xiàn)的算法轉(zhuǎn)換為塊粒度數(shù)據(jù)流圖(chunk-granularity dataflow graph),使GPU中大型圖的GNN計(jì)算成為可能;
一個(gè)優(yōu)化層,它產(chǎn)生用于最小化主機(jī)和GPU設(shè)備存儲(chǔ)器之間的數(shù)據(jù)移動(dòng)的調(diào)度策略,并識(shí)別融合操作和刪除冗余計(jì)算;
一組有效的傳播操作內(nèi)核,支持基于流的處理,以將GPU中的數(shù)據(jù)移動(dòng)和計(jì)算重疊;
dataflow execution runtime。NGra主要利用現(xiàn)有的基于數(shù)據(jù)流的深度學(xué)習(xí)框架來處理dataflow execution runtime。
圖3:SAGA-NN Stages for each layer of GN
NGra的優(yōu)化
圖4描述了ApplyEdge階段中矩陣乘法運(yùn)算:
圖4
圖5顯示了優(yōu)化的dataflow graph,其中矩陣乘法移入ApplyVertex stage:
圖
圖7是多GPU的架構(gòu)
圖7:多GPU架構(gòu)
NGra的評估
我們在TensorFlow (v1.7) 上實(shí)現(xiàn)NGra,使用大約2,900行C++代碼和3000行Python代碼。NGra通過前端擴(kuò)展TensorFlow,將SAGA-NN程序轉(zhuǎn)換為chunk-granularity dataflow graph,幾個(gè)scatter/gather 運(yùn)算符,以實(shí)現(xiàn)高效的圖傳播,以及ring-based的流調(diào)度方案。
以下是評估結(jié)果。評估證明了NGra的高效和可擴(kuò)展性,以及與state-of-the-art的系統(tǒng)TensorFlow的比較。
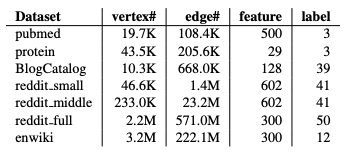
表1:數(shù)據(jù)集 (K: thousand, M: million)
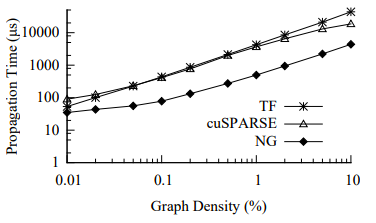
圖13:TensorFlow(TF),cuSPARSE和NGra(NG) 在不同密度graphs上的傳播內(nèi)核時(shí)間
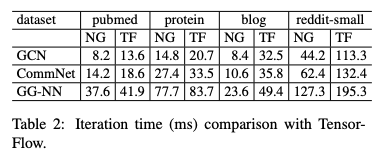
表2:與TensorFlow的迭代時(shí)間比較(ms)
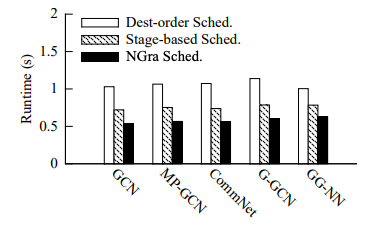
圖14:不同應(yīng)用程序的Streaming scheduling策略比較。(Data: reddit middle)
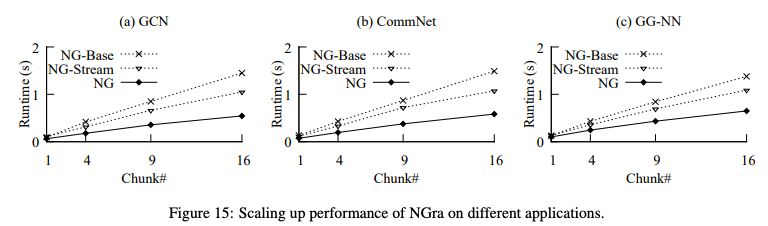
圖15:NGra在不同應(yīng)用程序的擴(kuò)展性能
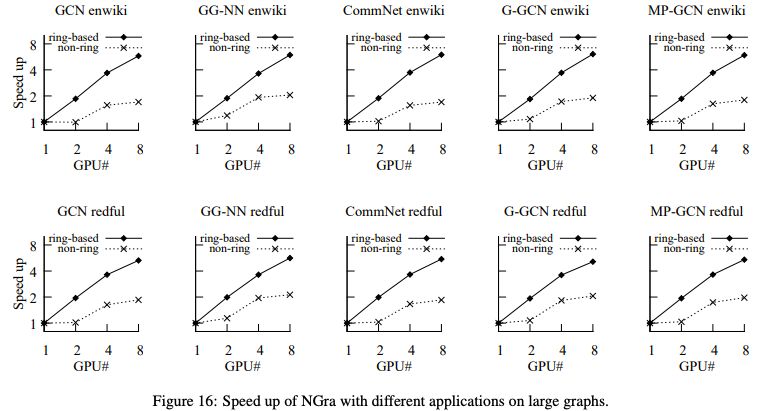
圖16:在大型圖上使用不同應(yīng)用程序加速NGra
結(jié)論
GNN代表了一種新興的計(jì)算模型,這自然地產(chǎn)生了對在大型graph上應(yīng)用神經(jīng)網(wǎng)絡(luò)模型的需求。由于GNN訓(xùn)練固有的復(fù)雜性,支持高效的、可擴(kuò)展的并行計(jì)算是很困難的。
NGra是第一個(gè)支持GNN的并行處理框架,它使用新的編程抽象,然后將其映射和優(yōu)化為數(shù)據(jù)流,進(jìn)而在GPU上高效執(zhí)行。
-
微軟
+關(guān)注
關(guān)注
4文章
6685瀏覽量
105728 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103556 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122783
原文標(biāo)題:北大、微軟亞洲研究院:高效的大規(guī)模圖神經(jīng)網(wǎng)絡(luò)計(jì)算
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)RAS在異步電機(jī)轉(zhuǎn)速估計(jì)中的仿真研究
神經(jīng)網(wǎng)絡(luò)壓縮框架 (NNCF) 中的過濾器修剪統(tǒng)計(jì)數(shù)據(jù)怎么查看?
BP神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的比較
BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
BP神經(jīng)網(wǎng)絡(luò)的基本原理
人工神經(jīng)網(wǎng)絡(luò)的原理和多種神經(jīng)網(wǎng)絡(luò)架構(gòu)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論