") 講解美團(tuán)大腦的設(shè)計(jì)、構(gòu)建以及挑戰(zhàn)
講解美團(tuán)大腦的設(shè)計(jì)、構(gòu)建以及挑戰(zhàn)

作為人工智能時(shí)代最重要的知識表示方式之一,知識圖譜能夠打破不同場景下的數(shù)據(jù)隔離,為搜索、推薦、問答、解釋與決策等應(yīng)用提供基礎(chǔ)支撐。
比如美團(tuán)大腦就圍繞吃喝玩樂場景構(gòu)建的生活娛樂領(lǐng)域的超大規(guī)模知識圖譜,為用戶和商家建立起全方位的鏈接,對應(yīng)用場景下的用戶偏好和商家定位進(jìn)行更深度的理解,從而能夠提供更好的智能化服務(wù)。
近日,AI科技大本營邀請到了美團(tuán) AILabNLP 中心負(fù)責(zé)人、大眾點(diǎn)評搜索智能中心負(fù)責(zé)人——王仲遠(yuǎn)博士,為大家講解美團(tuán)大腦的設(shè)計(jì)、構(gòu)建以及挑戰(zhàn),以及美團(tuán)大腦在美團(tuán)點(diǎn)評內(nèi)的具體應(yīng)用。
AI科技大本營將主要內(nèi)容整理如下:
▌知識圖譜的重要性
這些年來人工智能正在快速地改變?nèi)藗兊纳睿覀兛梢钥吹礁骷铱萍脊径技娂娡瞥鋈斯ぶ悄墚a(chǎn)品或者系統(tǒng),比如說在 2016 年的時(shí)候,谷歌推出的 AlphaGo ,一問世便橫掃圍棋界,完勝人類的冠軍。又比如說亞馬遜推出的 Amazon Go 無人超市,用戶只需下載一個(gè) App,直接走進(jìn)這家超市,拿走商品,無需排隊(duì)結(jié)賬便可離開,這是人工智能時(shí)代的新零售體驗(yàn)。
又比如說老牌的科技公司微軟推出的 Skype Translator,它能夠幫助不同國家、不同地區(qū)的人進(jìn)行實(shí)時(shí)的語音交流。再比如說世界上最大的科技公司蘋果推出的 Siri 智能助理,讓每一個(gè)用蘋果手機(jī)的用戶都能夠非常便捷地完成各項(xiàng)的任務(wù)。所有這些人工智能產(chǎn)品的出現(xiàn)都依賴于背后各個(gè)領(lǐng)域突飛猛進(jìn)的進(jìn)展,比如說機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺、語音識別、自然語言處理等等。
作為一家領(lǐng)先的生活服務(wù)電子商務(wù)平臺,美團(tuán)點(diǎn)評在人工智能方面也積極地布局。今年 2 月份,AI 平臺部 NLP 中心正式成立,我們的愿景是用人工智能幫大家吃得更好,生活更好。語言是人類智慧的結(jié)晶,而自然語言處理是人工智能中最為困難的問題之一,其核心是讓機(jī)器像人類一樣理解和使用語言。
我們希望在不遠(yuǎn)的將來,當(dāng)用戶發(fā)表一條評價(jià)的時(shí)候,能夠讓機(jī)器閱讀這條評價(jià),充分理解用戶的喜怒哀樂。當(dāng)用戶進(jìn)入大眾點(diǎn)評的一個(gè)商家頁面時(shí),面對成千上萬條用戶評論,我們希望機(jī)器能夠代替用戶快速地閱讀這些評論,總結(jié)商家的情況,供用戶進(jìn)行參考。未來,當(dāng)用戶有任何餐飲、娛樂方面的決策需求的時(shí)候,我們能夠提供人工智能助理服務(wù),幫助用戶快速決策。
所有這一切都依賴于人工智能背后兩大技術(shù)驅(qū)動力:深度學(xué)習(xí)和知識圖譜。我將這兩個(gè)技術(shù)做了一個(gè)簡單的比較。
我們將深度學(xué)習(xí)歸納為隱性的模型,它通常是面向某一個(gè)具體任務(wù),比如說下圍棋、識別貓、人臉識別、語音識別等等,通常而言它需要海量的訓(xùn)練數(shù)據(jù),以及非常強(qiáng)大的計(jì)算機(jī),同時(shí)它也有非常多的局限性,比如說難以進(jìn)行任務(wù)上的遷移,同時(shí)可解釋性比較差。
另一方面,知識圖譜是人工智能的另外一大技術(shù)驅(qū)動力,它能夠廣泛地適用于不同的任務(wù),相比深度學(xué)習(xí),知識圖譜的可解釋性非常強(qiáng),類似于人類的思考。
我們可以通過上面的例子來觀察深度學(xué)習(xí)技術(shù)和人類是如何識別貓的,以及它們的過程有哪些區(qū)別。
2012 年,Google X 實(shí)驗(yàn)室宣布使用深度學(xué)習(xí)技術(shù),讓機(jī)器成功識別了圖片中的貓。它們使用了 1000 臺服務(wù)器,16000 個(gè)處理器,連接成一個(gè) 10 億節(jié)點(diǎn)的人工智能大腦。這個(gè)系統(tǒng)閱讀了 1000 萬張從 YouTube 上抽取的圖片,最終成功識別出這個(gè)圖片里有沒有貓。
我們再來看看人類是如何做的。對于一個(gè) 3 歲的小朋友,我們只需要給他看幾張貓的圖片,他就能夠識別出不同圖片中的貓,而這背后其實(shí)就是大腦對于這些知識的推理。
2011 年的時(shí)候,Science 上有一篇非常出名的論文,叫 How to Grow a Mind。這篇論文的作者來自于 MIT、CMU、UC Berkeley、Stanford 等美國牛校的教授。在這篇論文里,最重要的一個(gè)結(jié)論就是,如果我們的思維能夠跳出給定的數(shù)據(jù),那么必須有 another source of information 來 make up the difference。
這里的知識語言是什么?對于人類來講,其實(shí)就是我們從小到大接受的學(xué)校教育,報(bào)紙上、電視上看到的信息,通過社交媒體,通過與其他人交流,不斷積累起來的知識。
這些年來,不管是學(xué)術(shù)界還是工業(yè)界都紛紛構(gòu)建知識圖譜,有面向全領(lǐng)域的知識圖譜,也有面向垂直領(lǐng)域的知識圖譜。其實(shí)早在文藝復(fù)興時(shí)期,培根就提出了“知識就是力量”,在當(dāng)今人工智能時(shí)代,各大科技公司更是紛紛提出知識圖譜就是人工智能的基礎(chǔ)。
全球的互聯(lián)網(wǎng)公司都在積極布局知識圖譜。早在 2010 年微軟就開始構(gòu)建知識圖譜,包括 Satori 和 Probase。2012 年,Google 正式發(fā)布了 Google Knowledge Graph。到目前為止,整個(gè) Google Knowledge Graph 的規(guī)模在 700 億左右。目前微軟和 Google 擁有全世界最大的通用知識圖譜,F(xiàn)acebook 擁有全世界最大的社交知識圖譜,而阿里巴巴和亞馬遜則構(gòu)建了商品知識圖譜。
如果按照人類理解問題和回答問題這一過程來進(jìn)行區(qū)分,我們可以將知識圖譜分成兩類。我們來看這樣一個(gè)例子,如果用戶看到這樣一個(gè)問題,“Who was the U.S. President when the Angels won the World Series?”我想所有的用戶都能夠理解這個(gè)問題,也就是當(dāng) Angels 隊(duì)贏了 World Series 的時(shí)候,誰是美國的總統(tǒng)?
這是一個(gè)問題理解的過程,它所需要的知識通常我們叫它 common sense knowledge(常識性知識)。另外一方面,我想很多網(wǎng)友們應(yīng)該回答不出這個(gè)問題,因?yàn)樗枰硗庖粋€(gè)百科全書式的知識。
因此,我們將知識圖譜分成兩大類,一類叫Common Sense Knowledge Graph(常識知識圖譜),另外一類叫Encyclopedia Knowledge Graph(百科全書知識圖譜)。這兩類知識圖譜有很明顯的區(qū)別。針對 Common Sense Knowledge Graph,通常而言我們會挖掘這些詞之間的 linguistic knowledge;對于 Encyclopedia Knowledge Graph,我們通常會在乎它的 Entities,和這些 Entities 之間的 Facts。
對于 Common Sense Knowledge Graph,一般而言我們比較在乎的 relation 包括 isA relation,isPropertyOf relation。對于 Encyclopedia Knowledge Graph,通常我們會預(yù)定義一些謂詞,比如說DayOfbirth,LocatedIn,SpouseOf。
對于Common Sense Knowledge Graph 通常帶有一定概率,但是 Encyclopedia Knowledge Graph 通常非黑即白,那么構(gòu)建這種知識圖譜的時(shí)候我們在乎的是 Precision(準(zhǔn)確率)。
Common Sense Knowledge Graph 比較有代表性的工作包括 WordNet、KnowItAll、NELL,以及 Microsoft Concept Graph。而 Encyclopedia Knowledge Graph 則有 Freepase、Yago、Google Knowledge Graph,以及正在構(gòu)建中的“美團(tuán)大腦”。
在今天的課程中,我會跟大家介紹兩個(gè)代表性工作,分別是 Common Sense Knowledge Graph:Probase,以及我們正在做的美團(tuán)大腦,它是一個(gè) Encyclopedia Knowledge Graph。
▌常識性知識圖譜(Common Sense Knowledge Graph)
Microsoft Concept Graph 于 2016 年 11 月正式發(fā)布,但是它早在 2010 年就已經(jīng)開始進(jìn)行研究,是一個(gè)非常大的圖譜。在這個(gè)圖譜里面有上百萬個(gè) Nodes(節(jié)點(diǎn)),這些 Nodes 有Concepts(概念),比如說 Spanish Artists(西班牙藝術(shù)家);有 Entities(實(shí)體),比如說 Picasso(畢加索);有 Attributes(屬性),比如 Birthday(生日);有 Verbs(動詞),有 Adjectives(形容詞),比如說 Eat、Sweet。也有很多很多的邊,最重要的邊,是這種 isA 邊,比如說 Picasso,還有 isPropertyOf邊。對于其他的 relation,我們會統(tǒng)稱為 Co-occurance 。
這是我們在微軟亞洲研究院期間對 Common Sense Knowledge Graph 的 Research Roadmap(研究路線圖)。當(dāng)我們構(gòu)建出 Common Sense Knowledge Graph 之后,重要的是在上面構(gòu)建各種各樣的模型。我們提出了一些模型叫 Conceptualization(概念化模型),它能夠支持 Term Similarity、Short Text Similarity 以及 Head-Modifier Detection,最終支持各種應(yīng)用,比如NER,文本標(biāo)注,Ads,Query Recommendation,Text Understanding。
到底什么是 short text understanding?常識怎么用在 text understanding 里?下面我們可以看一些具體的例子。
當(dāng)大家看到上面中間的文本的時(shí),我想所有人都能夠認(rèn)出這應(yīng)該是一個(gè)日期,但是大家沒辦法知道這個(gè)日期代表什么樣的含義。但如果我再多給一些上下文信息,比如 Picasso、Spanish,大家對這個(gè)日期就會有一些常識性的推理。我們會猜測這個(gè)日期很可能是 Picasso 的出生日期,或者是去世日期,這就是常識。
比如說當(dāng)我們給定 China 和 India 這兩個(gè) entity 的時(shí)候,我們的大腦就會做出一些常識性的推理,我們會認(rèn)為這兩個(gè) entity 在描述 country。如果再多給一個(gè) entity:Brazil,這時(shí)候我們通常會想到 emerging market。如果再加上 Russia,通常大家可能就會想的是金磚四國或者金磚五國。所有這一切就是常識性的推理。
再比如當(dāng)我們看到 engineer 和 apple 的時(shí)候,我們會對 apple 做一些推理,認(rèn)為它就是一個(gè) IT company,但是如果再多給一些上下文信息,在這個(gè)句子里面由于 eating 的出現(xiàn),我相信大家的大腦也會一樣地做出常識推理,認(rèn)為這個(gè) apple 不再是代表 company,而是代表 fruit。
所以這就是我們提出來的 Conceptualization Model,它是一個(gè) explicit representation。我們希望它能夠?qū)?text,尤其是 short text,映射到 millions concepts,這樣的 representation 能夠比較容易讓用戶進(jìn)行理解,同時(shí)能夠應(yīng)用到不同場景當(dāng)中。
在這一頁的 PPT 里面,我們展示了 Conceptualization 的結(jié)果。當(dāng)輸入是 pear 和 apple 的時(shí)候,那么我們會將這個(gè) apple 映射到 fruit。但是如果是 ipad apple 的時(shí)候,我們會將它映射到 company,同時(shí)大家注意這并不是唯一的結(jié)果,我們實(shí)際上是會被映射到一個(gè) concept vector。這個(gè) concept vector 有多大?它是百萬級維度的 vector,同時(shí)也是一個(gè)非常sparse的一個(gè) vector。
通過這樣的一個(gè) Conceptualization Model,我們能夠解決什么樣的文本理解問題?我們可以看這樣一個(gè)例子。比如說給定一個(gè)非常短的一個(gè)文本,Python,它只是一個(gè) single instance,那么我們會希望將它映射到至少兩大類的 concept 上,一種可能是 programming language,另外一種是 snake。當(dāng)它有一些 context,比如說 Python tutorial 的時(shí)候,那么這個(gè)時(shí)候 Python 指的應(yīng)該是 programming language。另外如果當(dāng)它有其他的 adjective、verb,比如 dangerous 的時(shí)候,這時(shí)候我們就會將 Python 理解為 snake。
同時(shí)如果在一個(gè)文本里面包含了多個(gè)的 entity,比如說 DNN Tool,Python,那么我們希望能夠檢測出在這個(gè)文本里面哪一個(gè)是比較重要的 entity,哪一個(gè)是用來做限制的 entity。
下面我將簡單地介紹一下具體是怎么去做的。當(dāng)我們在 Google 里搜一個(gè) single instance 的時(shí)候,通常在右側(cè)會出現(xiàn)這個(gè) Knowledge Panel。對于 Microsoft 這樣一個(gè) instance,我們可以看到這個(gè)紅色框所框出來的 concept,Microsoft 指向的是 technology company,這背后是怎么去做的?
我們可以看到,Microsoft 實(shí)際上會指向非常非常多的 concept,比如說 company,software company,technology leader 等等。我們將它映射到哪一個(gè) concept 上最合適?
如果我們將它映射到 company 這個(gè) concept 上,很顯然它是對的,但是我們卻沒辦法將 Microsoft 和 KFC、BMW 這樣其他類型的產(chǎn)品區(qū)分開來。另外一方面,如果我們將 Microsoft 映射到 largest desktop OS vendor 上,那么這是一個(gè)非常 specific 的一個(gè)concept,這樣也不太好,為什么?因?yàn)檫@個(gè) concept 太 specific,太 detail,它可能只包含了 Microsoft 這樣一個(gè) entity,那么它就失去了 concept 的抽象能力。
所以我們希望將 Microsoft 映射到一個(gè)既不是特別 general(抽象),又不是一個(gè)特別 specific(具體)的 concept 上。在語言學(xué)上,我們將這種映射稱之為 Basic-level,我們將整個(gè)映射過程命名為 Basic-level Conceptualization。
我們提出了一種計(jì)算 Basic-level Conceptualization 的方法,其實(shí)它非常簡單但有非常有效。就是將兩種的typicality做了一些融合,同時(shí)我們也證明了它們跟 PMI 和 Commute Time 之間的一些關(guān)聯(lián)。并且在一個(gè)大規(guī)模的數(shù)據(jù)集上,我們通過 Precision 和 NDCG 對它們進(jìn)行了評價(jià)。最后證明,我們所提出來的scoring方法,它在 NDCG 和 Precision 上都能達(dá)到比較好的結(jié)果。最重要的是,它在理論上是能夠?qū)?Basic-Level 進(jìn)行很好的解釋。

下面我們來看一下當(dāng) instance 有了一些 context 之后,我們應(yīng)該怎么去進(jìn)行處理。我們通過一個(gè)例子來簡單地解釋一下這背后最主要的思想。
比如說 ipad,apple,其中 ipad 基本上是沒有歧異的,它會映射到 device、product。但是對于 apple 而言,它可能會映射到至少兩類的 concept 上,比如說 fruit,company。那么我們怎么用 ipad 對 apple 做消歧呢?
方法其實(shí)也挺直觀的。我們會通過大量的統(tǒng)計(jì)去發(fā)現(xiàn)像 ipad 這樣的 entity,通常會跟company、product 共同出現(xiàn)。比如說 ipad 有可能會跟三星共同出現(xiàn),有可能會跟 google 共同出現(xiàn),那么我們就發(fā)現(xiàn)它會經(jīng)常跟 brand,company,product共同出現(xiàn)。于是我們就利用新挖掘出來的 knowledge 對 apple 做消歧,這就是背后最主要的思想。
除了剛才這樣一個(gè)general context 以外,在很多時(shí)候這些 text 可能還會包含很多一些特殊的類型,比如說verb、adjective。具體而言,我們希望在看到 watch harry potter 時(shí),能夠知道 harry potter 是 movie,當(dāng)我們看到 read harry potter 時(shí),能夠知道 harry potter 是 book。同樣的,harry potter 還有可能是一個(gè)角色名稱或者一個(gè)游戲名稱。
那么我們來看一看應(yīng)該怎樣去解決這樣一件事情。當(dāng)我們看到 watch harry potter 的時(shí)候,我們首先要知道,harry potter 有可能是一本 book,也有可能是一部 movie。我們可以算出的一個(gè)先驗(yàn)概率,這通常要通過大規(guī)模的統(tǒng)計(jì)。同時(shí)我們要知道,watch 它有可能是一個(gè)名詞,同時(shí)它也有可能是一個(gè)動詞,并且我們還需要去挖掘,當(dāng) watch 作為動詞的時(shí)候,它和 movie 有非常緊密的關(guān)聯(lián)。
所以我們本質(zhì)上是要去做一些概率上的推理。在論文中我們就會將條件概率做非常細(xì)粒度的分解,最后做概率計(jì)算。
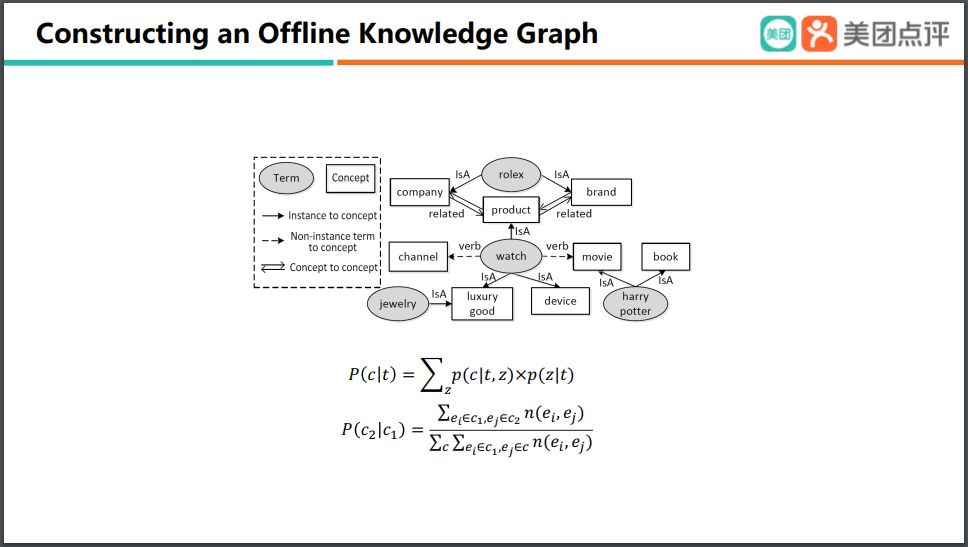
通過概率計(jì)算的方法,我們實(shí)際上就可以構(gòu)建出一個(gè)非常非常大的離線的的知識圖譜,那么我們在這個(gè)上面就可以有很多的 term,以及它們所屬的一些 type,以及不同term之間的一些關(guān)聯(lián)。
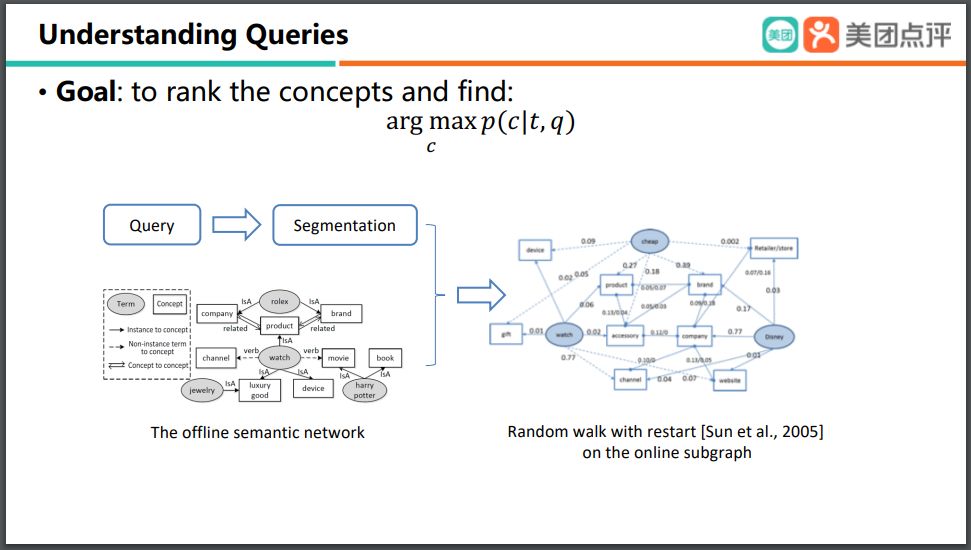
當(dāng)我們用這樣一個(gè)非常大的離線知識圖譜來做 text understanding 的時(shí)候,我們可以首先將這個(gè) text 進(jìn)行分割處理,在分割之后,我們實(shí)際上是可以從這個(gè)非常大的離線知識圖譜截取出它的一個(gè)子圖。最后我們使用了 Random walk with restart 的模型,來對這樣一個(gè)在線的 subgraph 進(jìn)行分類。
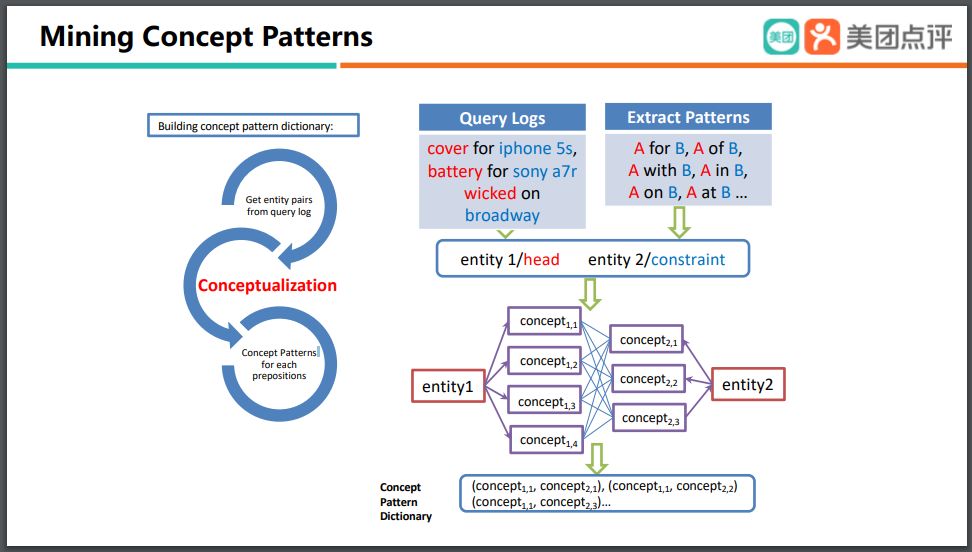
我們再來看,如果一個(gè)文本里包含了 multiple entities,要怎樣處理?我們需要做知識挖掘,怎么做?首先我們可以得到非常多的 query log,然后我們也可以去預(yù)定一些 pattern,通過這種 Pattern 的定義,可以抽取出非常多 entity 之間 head 和 modifier 這樣的 relation,那么在接下來我們可以將這些 entity 映射到 concept 上,之后得到一個(gè) pattern。

在這個(gè)過程之中,我們要將 entity 映射到 concept 上,那么這就是前面所提到的Conceptualization。我們希望之后的映射不能太 general,避免 concept pattern 沖突。
但是它也不能太 specific,因?yàn)槿绻?specific,可能就會缺少表達(dá)能力。最壞的情況,它有可能就會退化到 entity level,而 entity 至少都是百萬的規(guī)模,那么整個(gè) concept patterns 就有可能變成百萬乘以百萬的級別,顯然是不可用的。
所以我們就用到了前面介紹的 Basic-level Conceptualization 的方法,將它映射到一個(gè)既不是特別 general,也不是特別 specific 的 concept 上。
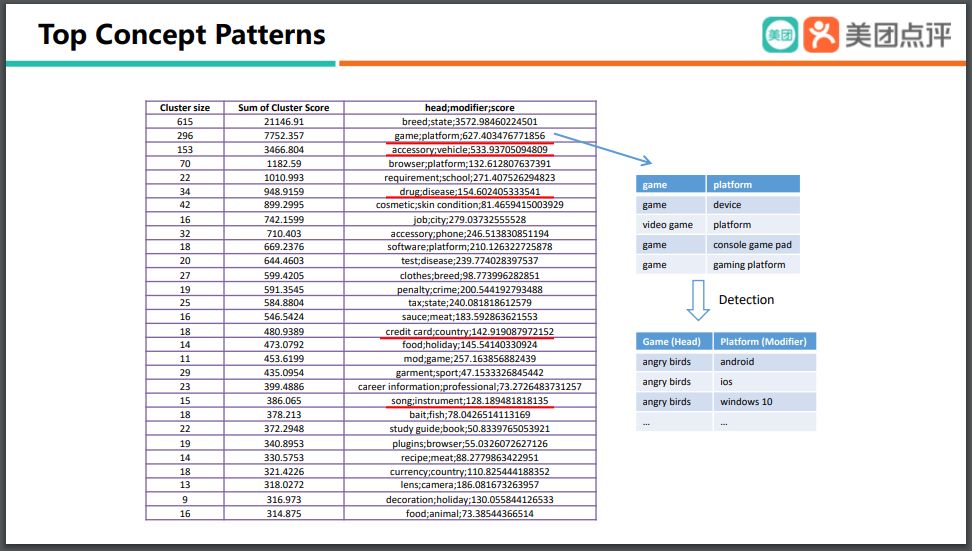
大家可以看一下我們能夠挖掘出來的一些 Top 的 concept patterns,比如說 game 和platform,就是一個(gè) concept 和一個(gè) pattern。它有什么用?舉一個(gè)具體的例子,當(dāng)用戶在搜 angry birds、ios 的時(shí)候,我們就可以知道用戶想找的是 angry birds 這款游戲,而 ios 是用來限制這款游戲的一個(gè) platform。蘋果公司每年都會推出新版本的 ios,那么我們挖掘出這樣的 concept pattern之后,不管蘋果出到 ios 15或者 ios 16,那么我們只需要將它們映射到 platform,那么我們的 concept patterns 就仍然有效,這樣可以很容易地進(jìn)行知識擴(kuò)展。
所以 Common Sense Knowledge Mining 以及 Conceptualization Modeling,可以用在很多很多的應(yīng)用上,它可以用來算 Short text similarity,所以它可以用來做 classification,clustering,也可以用來做廣告的 semantic match,Q/A system,Chatbot 等等。
▌美團(tuán)大腦——百科全書式知識圖譜(Encyclopedia Knowledge Graph)
在介紹完 Common Sense Knowledge Graph 之后,給大家介紹一下 Encyclopedia Knowledge Graph。這是美團(tuán)的知識圖譜項(xiàng)目——美團(tuán)大腦。
美團(tuán)大腦是什么?美團(tuán)大腦是我們正在構(gòu)建中的一個(gè)全球最大的餐飲娛樂知識圖譜。我們希望能夠充分地挖掘關(guān)聯(lián)美團(tuán)點(diǎn)評各個(gè)業(yè)務(wù)場景里的公開數(shù)據(jù),比如說我們有累計(jì) 40 億的用戶評價(jià),超過 10 萬條個(gè)性化標(biāo)簽,遍布全球的 3000 多萬商戶以及超過 1.4 億的店菜,我們還定義了 20 級細(xì)粒度的情感分析。
我們希望能夠充分挖掘出這些元素之間的關(guān)聯(lián),構(gòu)建出一個(gè)知識的大腦,用它來提供更加智能的服務(wù)。
那么下面我簡單地介紹一下美團(tuán)大腦是如何進(jìn)行構(gòu)建的。我們會使用 Language Model(統(tǒng)計(jì)語言模型)、Topic Model(主題生成模型) 以及 Deep Learning Model(深度學(xué)習(xí)模型) 等各種模型,希望能夠做到商家標(biāo)簽的挖掘,菜品標(biāo)簽的挖掘和情感分析的挖掘等等。
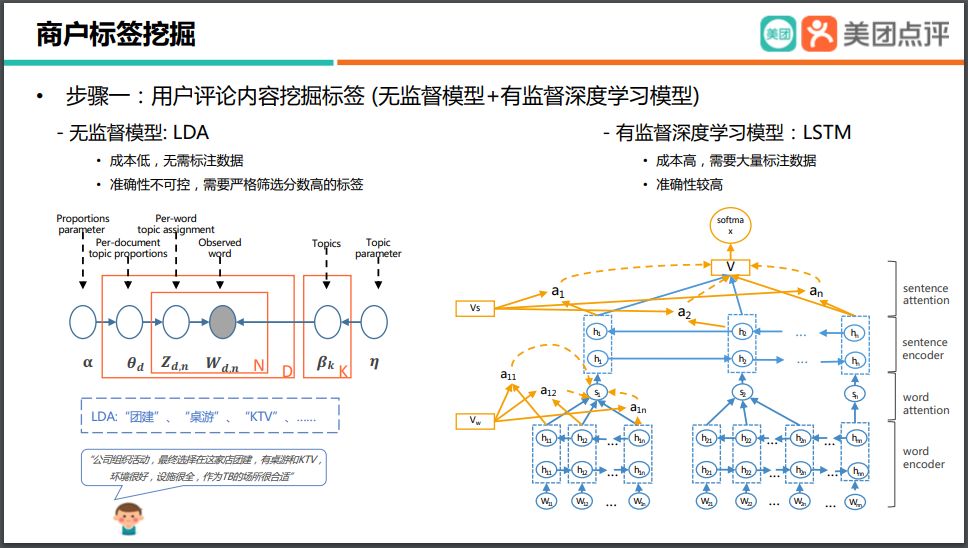
為了挖掘商戶標(biāo)簽,首先我們要讓機(jī)器去閱讀評論。我們使用了無監(jiān)督和有監(jiān)督的深度學(xué)習(xí)模型。
無監(jiān)督模型我們主要用了LDA,它的特點(diǎn)是成本比較低,無需標(biāo)注的數(shù)據(jù)。當(dāng)然,它準(zhǔn)確性會比較不可控,同時(shí)對挖掘出來的標(biāo)簽我們還需要進(jìn)行人工的篩選。至于有監(jiān)督的深度學(xué)習(xí)模型,那么我們用了 LSTM,它的特點(diǎn)是需要比較大量的標(biāo)注數(shù)據(jù)。
通過這兩種模型挖掘出來的標(biāo)簽,我們會再加上知識圖譜里面的一些推理,最終構(gòu)建出商戶的標(biāo)簽。
如果這個(gè)商戶有很多的評價(jià),都是圍繞著寶寶椅、帶娃吃飯、兒童套餐等話題,那么我們就可以得出很多關(guān)于這個(gè)商戶的標(biāo)簽。比如說我們可以知道它是一個(gè)親子餐廳,它的環(huán)境比較別致,它的服務(wù)比較熱情。
下面介紹一下我們?nèi)绾螌Σ似愤M(jìn)行標(biāo)簽的挖掘?我們使用了 Bi-LSTM 以及 CRF 模型。比如說從這個(gè)評論里面我們就可以抽取出這樣的 entity,再通過與其他的一些菜譜網(wǎng)站做一些關(guān)聯(lián),我們就可以得到它的食材、烹飪方法、口味等信息,這樣我們就為每一個(gè)店菜挖掘出了非常豐富的口味標(biāo)簽、食材標(biāo)簽等各種各樣的標(biāo)簽。
下面再簡單介紹一下我們?nèi)绾芜M(jìn)行評論數(shù)據(jù)的情感挖掘。我們用的是 CNN+LSTM 的模型,對于每一個(gè)用戶的評價(jià)我們都能夠分析出他的一些情感的傾向。同時(shí)我們也正在做細(xì)粒度的情感分析,我們希望能夠通過用戶短短的評價(jià),分析出他在不同的維度,比如說交通、環(huán)境、衛(wèi)生、菜品、口味等方面的不同的情感分析的結(jié)果。這種細(xì)粒度的情感分析果,目前在全世界都沒有很好的解決辦法。
下面介紹一下我們的知識圖譜是如何進(jìn)行落地的。目前業(yè)界知識圖譜已經(jīng)有非常多的成熟應(yīng)用,比如搜索、推薦、問答機(jī)器人、智能助理,包括在穿戴設(shè)備、反欺詐、臨床決策上都有非常好的應(yīng)用。同時(shí)業(yè)界也有很多的探索,包括智能的商業(yè)模式、智能的市場洞察、智能的會員體系等等。
如何用知識圖譜來改進(jìn)我們的搜索?如果大家現(xiàn)在打開大眾點(diǎn)評,當(dāng)大家搜索某一個(gè)菜品時(shí),比如說麻辣小龍蝦,其實(shí)我們的機(jī)器是已經(jīng)幫大家提前閱讀了所有的評價(jià),然后分析出提供這道菜品的商家,我們還會用用戶評論的情感分析結(jié)果來改進(jìn)搜索排序。
此外,我們也將它用在了商圈的個(gè)性化推薦。當(dāng)大家打開大眾點(diǎn)評時(shí),如果你現(xiàn)在位于某一個(gè)商場或者商圈,那么大家很快就能夠看到這個(gè)商場或者商圈的頁面入口。當(dāng)用戶進(jìn)入這個(gè)商場和商戶的頁面時(shí),通過知識圖譜我們就能夠提供千人千面的個(gè)性化排序和個(gè)性化推薦。
在這背后其實(shí)使用了一個(gè)水波的深度學(xué)習(xí)模型,關(guān)于這個(gè)深度學(xué)習(xí)模型更詳細(xì)的介紹,大家可以參見我們在 CIKM 上的一篇論文。
所有的這一切其實(shí)還有很多的技術(shù)突破等待我們的解決。比如整個(gè)美團(tuán)大腦的知識圖譜在百億的量級,是世界上最大的餐飲娛樂知識圖譜。為了支撐這個(gè)知識圖譜,我們需要去研究千億級別的圖存儲和計(jì)算引擎技術(shù)。我們也正在搭建一個(gè)超大規(guī)模的 GPU 集群,來支持海量數(shù)據(jù)的深度學(xué)習(xí)算法。未來當(dāng)所有的這些技術(shù)都 ready 之后,我們希望能夠?yàn)樗杏脩籼峁┲腔鄄蛷d和智能助理的體驗(yàn)。
-
人工智能
+關(guān)注
關(guān)注
1806文章
49014瀏覽量
249432 -
美團(tuán)
+關(guān)注
關(guān)注
0文章
125瀏覽量
10663 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
8005
原文標(biāo)題:美團(tuán)大腦:知識圖譜的建模方法及其應(yīng)用 | 公開課筆記
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
新加坡企業(yè)發(fā)展局代表團(tuán)蒞臨智行者科技考察交流
南柯電子 汽車導(dǎo)航系統(tǒng)EMC整改:從0到1構(gòu)建抗干擾系統(tǒng)的新挑戰(zhàn)
澳門招商投資促進(jìn)局代表團(tuán)到訪智行者科技
廣西陽朔政企代表團(tuán)蒞臨勇藝達(dá)參觀指導(dǎo)
食堂團(tuán)餐消費(fèi)機(jī)“斷網(wǎng)斷電也能用”的工作原理是什么?

印尼媒體團(tuán)走進(jìn)廣汽集團(tuán)
安森美SiC cascode JFET并聯(lián)設(shè)計(jì)的挑戰(zhàn)

美光科技增強(qiáng)型車用LPDDR5X助力應(yīng)對汽車行業(yè)挑戰(zhàn)
上汽乘用車與美團(tuán)達(dá)成戰(zhàn)略合作
工業(yè)智慧大腦互聯(lián)網(wǎng)平臺的功能特點(diǎn)
豐田、Aurora和大陸集團(tuán)加入NVIDIA合作伙伴行列
睿思芯科受邀參加美團(tuán)機(jī)器人研究院學(xué)術(shù)年會圓桌論壇
美團(tuán)無人機(jī)獲迪拜BVLOS商業(yè)運(yùn)營資質(zhì)
構(gòu)建RFID數(shù)字化車場建設(shè):從挑戰(zhàn)到解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論