 數據科學的完整流程幾個組成部分
數據科學的完整流程幾個組成部分

數據科學的完整流程一般包含以下幾個組成部分:
數據收集
數據清洗
數據探索和可視化
統計或預測建模
雖然這些組成部分有助于我們理解數據科學的不同階段,但對于編程工作流并無助益。
通常而言,在同一個文件中覆蓋完整的流程將會導致Jupyter Notebook、腳本變成一團亂麻。此外,大多數的數據科學問題都要求我們在數據收集、數據清洗、數據探索、數據可視化和統計/預測建模中切換。
但是還存在更好的方法來組織我們的代碼!在這篇博客中,我將介紹大多數人在做數據科學編程工作的時候切換的兩套思維模式:原型思維模式和生產流思維模式。
JupyteLab:我個人使用JupyteLab來進行整個流程的操作(包括寫原型代碼和生產流代碼)。我建議至少使用JupyteLab來寫原型代碼:
http://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html
借貸俱樂部數據
為了更好地理解原型和生產流兩種思維模式,我們來處理一些真實的數據。我們將使用個人對個人的借貸網站——借貸俱樂部上面的借貸數據。跟銀行不同,借貸俱樂部自身并不借錢,而是為貸款人提供一個市場以貸款給因不同的原因(比如維修、婚禮)需要借款的個人。
借貸俱樂部網站:
https://www.dataquest.io/blog/programming-best-practices-for-data-science/www.lendingclub.com
我們可以使用這個數據來建立一個模型,判斷一個給定的貸款申請是否會成功。這篇博客中,我們不會深入到建立機器學習模型工作流。
借貸俱樂部提供關于成功的貸款(被借貸俱樂部和聯合貸款人通過的貸款)和失敗的貸款(被借貸俱樂部和聯合貸款人拒絕的貸款,款項并沒有轉手)的詳盡歷史數據。打開他們的數據下載頁,選擇2007-2011年,并下載數據:
數據下載頁:
https://www.lendingclub.com/info/download-data.action
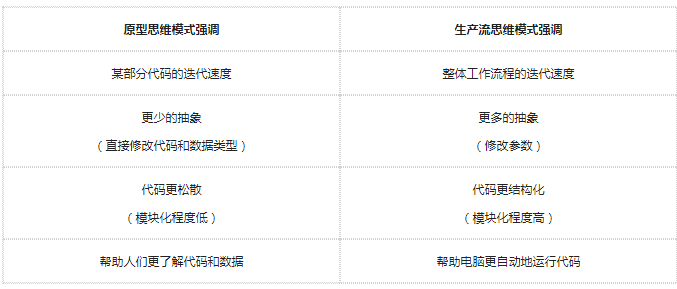
原型思維模式
在原型思維模式中,我們比較關心快速迭代,并嘗試了解數據中包含的特征和事實。創建一個Jupyter Notebook,并增加一個Cell來解釋:
你為了更好地了解借貸俱樂部而做的所有調查
有關你下載的數據集的所有信息
首先,讓我們將csv文件讀入pandas:
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv')
loans_2007.head(2)
我們得到兩部分輸出,首先是一條警告信息:
/home/srinify/anaconda3/envs/dq2/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (0,1,2,3,4,7,13,18,24,25,27,28,29,30,31,32,34,36,37,38,39,40,41,42,43,44,46,47,49,50,51,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,123,124,125,126,127,128,129,130,131,132,133,134,135,136,142,143,144) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
然后是數據框的前5行,這里我們就不展示了(太長了)。
警告信息讓我們了解到如果我們在使用pandas.read_csv()的時候將low_memory參數設為False的話,數據框里的每一列的類型將會被更好地記錄。
第二個輸出的問題就更大了,因為數據框記錄數據的方式存在著問題。JupyterLab有一個內建的終端,所以我們可以打開終端并使用bash命令head來查看原始文件的頭兩行數據。
head -2 LoanStats3a.csv
原始的csv文件第二行包含了我們所期望的列名,看起來像是第一行數據導致了數據框的格式問題:
Notes offered by Prospectus
https://www.lendingclub.com/info/prospectus.action
增加一個Cell來說明你的觀察,并增加一個code cell來處理觀察到的問題。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv', skiprows=1, low_memory=False)
在借貸俱樂部下載頁查看數據字典以了解哪些列沒有包含對特征有用的信息。Desc和url列很明顯就沒有太大的用處。
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
然后就是將超過一半以上都缺失值的列去掉,使用一個cell來探索哪一列符合這個標準,再使用另一個cell來刪除這些列。
loans_2007.isnull().sum()/len(loans_2007)
loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
因為我們使用Jupyter Notebook來記錄我們的想法和代碼,所以實際上我們是依賴于環境(通過IPython內核)來記錄狀態的變化。這讓我們能夠自由地移動cell,重復運行同一段代碼,等等。
通常而言,原型思維模式專注于:
可理解性
使用Markdown cell來記錄我們的觀察和假設
使用一小段代碼來進行真實的邏輯操作
使用大量的可視化和計數
抽象最小化
大部分的代碼都不在函數中(更為面向對象)
我們會花時間來探索數據并且寫下我們采取哪些步驟來清洗數據,然后就切換到工作流模式,并且將代碼寫得更強壯一些。
生產流模式
在生產流模式,我們會專注于寫代碼來統一處理更多的情況。比如,我們想要可以清洗來自借貸俱樂部的所有數據集的代碼,那么最好的辦法就是概括我們的代碼,并且將它轉化為數據管道。數據管道是采用函數式編程
的原則來設計的,數據在函數中被修改,并在不同的函數之間傳遞:
函數式編程教程:
https://www.dataquest.io/blog/introduction-functional-programming-python/
這里是數據管道的第一個版本,使用一個單獨的函數來封裝數據清洗代碼。
import pandas as pd
def import_clean(file_list):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
half_count = len(loans)/2
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'])
在上面的代碼中,我們將之前的代碼抽象為一個函數。函數的輸入是一個文件名的列表,輸出是一個數據框的列表。
普遍來說,生產流思維模式專注于:
適合的抽象程度
代碼應該被泛化以匹配的類似的數據源
代碼不應該太過泛化以至于難以理解
管道穩定性
可依賴程度應該和代碼運行的頻率相匹配(每天?每周?每月?)
在不同的思維模式中切換
假設我們在運行函數處理所有來自借貸俱樂部的數據集的時候報錯了,部分潛在的原因如下:
不同的文件當中列名存在差異
超過50%缺失值的列存在差異
數據框讀入文件時,列的類型存在差異
在這種情況下,我們就要切換回原型模式并且探索更多。如果我們確定我們的數據管道需要更為彈性化并且能夠處理數據特定的變體時,我們可以將我們的探索和管道的邏輯再結合到一起。
以下是我們調整函數以適應不同的刪除閾值的示例:
import pandas as pd
def import_clean(file_list, threshold=0.5):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
threshold_count = len(loans)*threshold
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'], threshold=0.7)
默認值是0.5,如果需要的話,我們也可以改為0.7。
這是一些將管道改得更為彈性的方式,按推薦程度降序排列:
使用可選參數、位置參數和必需參數
在函數中使用if / then語句以及使用布爾輸入值作為函數的輸入
使用新的數據結構(字典,列表等)來表示特定數據集的自定義操作
這個管道可以擴展到數據科學工作流程的所有階段。這是一些偽代碼,可以總攬它的結構。
import pandas as pd
def import_clean(file_list, threshold=0.5):
## Code
def visualize(df_list):
# Find the most important features and generate pairwise scatter plots
# Display visualizations and write to file.
plt.savefig("scatter_plots.png")
def combine(df_list):
# Combine dataframes and generate train and test sets
# Drop features all dataframes don't share
# Return both train and test dataframes
return train,test
def train(train_df):
# Train model
return model
def validate(train_df, test-df):
# K-fold cross validation
# Return metrics dictionary
return metrics_dict
frames = import_clean(['LoanStats3a.csv', 'LoanStats2012.csv'], threshold=0.7)
visualize(frames)
train_df, test_df = combine(frames)
model = train(train_df)
metrics = test(train_df, test_df)
print(metrics)
下一步
如果你對加深理解和練習感興趣的話,我推薦:
了解如何將你的管道轉化為作為一個模塊或者從命令行中單獨運行的腳本:
https://docs.python.org/3/library/main.html
了解如何使用Luigi來構建更復雜的、能夠在云上面運行的管道
https://marcobonzanini.com/2015/10/24/building-data-pipelines-with-python-and-luigi/
了解更多有關數據工程的信息:
https://www.dataquest.io/blog/tag/data-engineering/
-
數據收集
+關注
關注
0文章
73瀏覽量
11453 -
數據科學
+關注
關注
0文章
168瀏覽量
10487
原文標題:2 種數據科學編程中的思維模式,了解一下
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論