") 各種知識圖譜精化方法,為國內(nèi)同行介紹本領(lǐng)域的最新研究成果
各種知識圖譜精化方法,為國內(nèi)同行介紹本領(lǐng)域的最新研究成果
摘要:
知識圖譜是一種在移動互聯(lián)網(wǎng)大時代下產(chǎn)生的新型知識表示方法,而精化是知識圖譜應(yīng)用研究的主要內(nèi)容之一,其主要任務(wù)是知識圖譜補全和錯誤檢測等,在信息檢索、機器人、智能問答等領(lǐng)域有著重要的應(yīng)用前景。因此,對知識圖譜精化進行研究具有十分重要的意義。對當(dāng)前知識圖譜精化方法進行了較為全面、深入的總結(jié),并對知識圖譜未來的主要研究方向進行了展望。
?
0 引言
隨著鏈接開放數(shù)據(jù)源(如DBpedia)的出現(xiàn)以及谷歌在2012年提出知識圖譜的概念,全球掀起了研究知識圖譜的熱潮,涌現(xiàn)出了大量的知識圖譜構(gòu)建技術(shù)[1-5],并構(gòu)建了各種知識圖譜,這些知識圖譜要么是開放的,要么是公司私有的,如Freebase[2]、維基數(shù)據(jù)(Wikidata)[3]、DBpedia[4]、YAGO[5]等,但無論采用哪種技術(shù),構(gòu)造出來的知識圖譜都不完美[6]。隨著研究的深入,越來越多的研究者開始關(guān)注知識圖譜的覆蓋率和正確率。而提高知識圖譜的覆蓋率和正確率是知識圖譜精化的主要目的,對知識圖譜進行精化具有十分重要的意義。
近年來,該領(lǐng)域的研究進展非常迅速,涌現(xiàn)出了一大批研究成果,已經(jīng)研發(fā)出了多種知識圖譜精化方法,這些方法主要集中在討論知識圖譜補全[7-28]和知識圖譜錯誤探測[29-34]兩個方面,這也是本文從這兩個方面進行綜述的原因。
本文的貢獻是:(1)討論各種知識圖譜精化方法;(2)為國內(nèi)同行介紹本領(lǐng)域的最新研究成果,了解該領(lǐng)域的研究進展,從而推動我國在該領(lǐng)域的發(fā)展。
1 知識圖譜精化相關(guān)概念
1.1 知識圖譜的概念
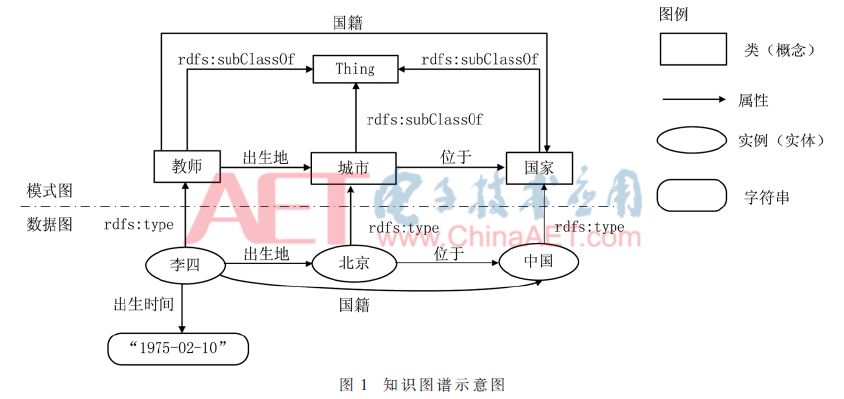
“知識圖譜”是一種描述真實世界客觀存在的實體、概念及它們之間關(guān)聯(lián)關(guān)系的語義網(wǎng)絡(luò)。可以利用知識圖譜開發(fā)語義檢索和自動問答等應(yīng)用[1]。知識圖譜的結(jié)構(gòu)如圖1所示。可見,知識圖譜是一個有向圖,由模式(schema)圖和數(shù)據(jù)圖構(gòu)成。其中,模式圖描述類之間的關(guān)系;數(shù)據(jù)圖描述實體之間的關(guān)系。圖1描述的知識(事實)如下:
(1)李四是一個教師
(2)北京是一個城市
(3)中國是一個國家
(4)李四的出生地為北京
(5)北京位于中國
(6)李四的國籍是中國
1.2 知識圖譜構(gòu)建與知識圖譜精化
知識圖譜構(gòu)建是使用各種技術(shù)從無到有構(gòu)造知識圖譜,而知識圖譜精化是使用各種技術(shù)對知識圖譜進行完善。可見,要構(gòu)建一個完美的知識圖譜,需要經(jīng)過多個精化步驟。因此,知識圖譜構(gòu)建和知識圖譜精化是相輔相成、不可分割的。另外,本文將關(guān)系、文字和類型稱為精化目標(biāo)。
2 常用的知識圖譜補全方法
知識圖譜補全的目的是利用已有信息,預(yù)測丟失的實體、類型和實體間的關(guān)系,從而提高知識圖譜的覆蓋率。它是知識圖譜精化的主要任務(wù)之一,其對應(yīng)的精化目標(biāo)包括實體、類型和實體間的關(guān)系。但根據(jù)已有文獻,發(fā)現(xiàn)目前該方面的研究主要集中在對類型和實體間的關(guān)系進行精化。
本節(jié)根據(jù)知識圖譜補全使用的數(shù)據(jù)源,將知識圖譜補全方法分為知識圖譜內(nèi)部補全和知識圖譜外部補全兩大類。其中,知識圖譜內(nèi)部補全方法是指僅使用知識圖譜本身預(yù)測丟失信息的方法總稱,知識圖譜外部補全方法是指除使用知識圖譜本身以外,還使用其他數(shù)據(jù)源(如文本語料)來預(yù)測丟失信息的方法總稱。下面將從這兩個方面對知識圖譜錯誤探測進行綜述。
2.1 知識圖譜內(nèi)部補全方法
為了揭示內(nèi)部補全方法因精化目標(biāo)的不同而不同,本小節(jié)將根據(jù)精化目標(biāo)的不同,把內(nèi)部補全方法分成實體類型內(nèi)部補全和關(guān)系內(nèi)部預(yù)測兩類進行綜述。
2.1.1 實體類型內(nèi)部補全
實體類型內(nèi)部補全就是利用知識圖譜本身已有的實體、實體類型和實體關(guān)系預(yù)測丟失的實體類型。
在機器學(xué)習(xí)領(lǐng)域,常用多分類方法對實體類型進行補全。其中,PAULHEIM H等人[7-8]提出了一種基于條件概率的補全算法SDType,這種算法的思想是通過實體所具有的關(guān)系預(yù)測實體類型。SDType算法的評價矩陣是正確率(precision)、召回率和新增類型數(shù)目。但這種算法的缺點是假設(shè)關(guān)系之間是相互獨立的,而現(xiàn)實世界中這種假設(shè)在很多情況下是不成立的,并且該算法沒有用類型的層次結(jié)構(gòu)。利用SDType算法,已經(jīng)為知識圖譜DBpedia新增了3.4億條類型語句。KROMPA?覻 D等人[9]利用張量分解預(yù)測實體類型,這種方法的思想是把知識圖譜表示成一個實體-實體-關(guān)系的三維張量,然后通過張量分解的方法實現(xiàn)類型補全。該方法的評價矩陣是正確率、召回率和正確率-召回率曲線。張香玲等人[10]提出了一種由謂詞和謂詞及謂詞和類型的相互作用補全實體類型的模型,在該模型中,為了解決類型語義漂移,使用PMI技術(shù)設(shè)計一個有效的謂詞-類型推理圖及基于圖上的隨機游走算法。該模型的評價矩陣是正確率和召回率。SLEEMAN J等人[11]將主題模型用在關(guān)系預(yù)測中,這種方法的思想是首先將實體表示成文檔,應(yīng)用LDA抽取文檔的主題,然后通過分析主題和實體類型的共現(xiàn)關(guān)系,根據(jù)分析結(jié)果,將實體類型指派給主題對應(yīng)的實體。該方法的評價矩陣是正確率和召回率。
在數(shù)據(jù)挖掘領(lǐng)域,利用關(guān)聯(lián)規(guī)則預(yù)測知識圖譜丟失的信息。PAULHEIM H等人[12]基于數(shù)據(jù)冗余信息使用關(guān)聯(lián)規(guī)則來預(yù)測DBpedia中丟失的類型。這種方法的評價矩陣為正確率和增加的類型數(shù)。
2.1.2 關(guān)系內(nèi)部預(yù)測
按照相同的思路,在機器學(xué)習(xí)領(lǐng)域,也把預(yù)測關(guān)系的存在與否看成是一個二分類問題。其中,SOCHER R等人[13]提出一種通過訓(xùn)練張量神經(jīng)網(wǎng)絡(luò)預(yù)測新關(guān)系的方法。例如:如果一個人出生在德國,那么該方法就能根據(jù)這個關(guān)系預(yù)測他的國籍是德國。這種方法的評價矩陣是精確率(accuracy),已被用于Freebase和WordNet中。BAIER S等人[14]也提出了類似的方法,但他們在預(yù)測過程增加了模式知識,以提高關(guān)系預(yù)測的性能。不同的是該方法的評價矩陣是正確率-召回率曲線面積和ROC曲線面積。類似地,ZHAO Y等人[15]通過將關(guān)系嵌入到一個低維空間中來預(yù)測Freebase中關(guān)系的存在,這種方法的評價矩陣是正確率。
同樣地,在數(shù)據(jù)挖掘領(lǐng)域,將關(guān)聯(lián)規(guī)則挖掘也用于預(yù)測關(guān)系。其中,KIM J等人[16]提出了一種利用關(guān)聯(lián)規(guī)則預(yù)測DBpdia中實體關(guān)系的方法。這種方法只能預(yù)測來自于維基百科分類中的實體關(guān)系,其評價矩陣是正確率和增加的關(guān)系數(shù)目。KOLTHOFF C等人[17]利用關(guān)聯(lián)規(guī)則挖掘思想查找意義豐富的關(guān)系鏈來預(yù)測關(guān)系,該方法的評價矩陣是正確率和召回率。
2.2 知識圖譜外部補全方法
與知識圖譜外部補全方法類似,為了揭示外部補全方法因精化目標(biāo)的不同而不同,本小節(jié)將根據(jù)精化目標(biāo)的不同,把外部補全方法分成實體類型外部補全和關(guān)系外部預(yù)測兩類進行綜述。
2.2.1 實體類型外部補全
實體類型外部補全就是利用知識圖譜本身和外部數(shù)據(jù)來預(yù)測丟失的實體類型。根據(jù)已有文獻分析,實體類型外部補全方法的研究主要集中在機器學(xué)習(xí)和自然語言處理領(lǐng)域。
在機器學(xué)習(xí)領(lǐng)域,主要將外部數(shù)據(jù)表示成實體特征進行分類。因為維基百科頁之間的鏈接沒有約束,所以維基百科網(wǎng)頁之間的鏈接比知識圖譜中相應(yīng)實體的鏈接要多。因此,NUZZOLESE A G等人[18]利用維基百科鏈接圖和KNN分類算法來預(yù)測知識圖譜中的實體類型。如果一個知識圖譜包含到維基百科的鏈接,那么就以相關(guān)頁的分類為基礎(chǔ),將維基百科網(wǎng)頁之間的鏈接表示成特征向量,這種方法的評價矩陣是正確率和召回率。APRIOSIO A P等人[19]將DBpedia各種語言版本中的實體類型作為特征來預(yù)測丟失的類型,該方法使用不同距離公式的K-NN分類器,綜合應(yīng)用這些不同的距離公式,得到了最好的結(jié)果。這種方法的評價矩陣是正確率和召回率。SLEEMAN J等人[20]將支持向量機用于DBpedia和Freebase中的實體類型預(yù)測。為了提高覆蓋率和正確率,作者利用知識圖譜間的內(nèi)部鏈接和其他知識圖譜的屬性對知識圖譜實例進行分類,這種方法的評價矩陣為正確率和召回率。
在自然語言處理領(lǐng)域,KLIEGR T[21]等人使用了不同語言的摘要來進行實體類型預(yù)測,從而大大提高知識圖譜的覆蓋率和正確率,這種方法的評價矩陣是正確率和召回率。
2.2.2 關(guān)系外部預(yù)測
關(guān)系外部預(yù)測就是利用知識圖譜本身和外部數(shù)據(jù)來預(yù)測丟失的實體關(guān)系。
一部分研究者利用遠程監(jiān)督法和自然語言處理方法對大規(guī)模文本語料庫進行處理以預(yù)測實體關(guān)系,其思路為:首先,通過命名實體識別將知識圖譜中的實體鏈接到語料庫(如維基百科)中;然后,以知識圖譜已有的關(guān)系為基礎(chǔ),找到與關(guān)系對應(yīng)的文本模式,例如,“author”關(guān)系對應(yīng)的文本模式為“Y’s book X”;最后,利用已找到的文本模式去發(fā)現(xiàn)語料庫中的新關(guān)系。其中,APROSIO A P等人[22]將遠程監(jiān)督法用于預(yù)測DBpedia中的關(guān)系,該方法將維基百科作為語料庫,并且將正確率和召回率作為評價矩陣。GERBER D等人[23]也提出了類似的方法,并開發(fā)了一個RdfLiveNews原型。在該原型中,利用新聞的RSS來解決DBpedia的時效性,即判斷預(yù)測到的新關(guān)系在DBpedia中屬于過時的關(guān)系還是丟失的關(guān)系。這種方法使用的評價矩陣是正確率、召回率和精確率。
一部分研究者利用Web搜索引擎填充知識圖譜[24]。和上述研究類似,這種方法首先找到關(guān)系對應(yīng)的詞匯,然后使用這些詞匯形成搜索語句以填充丟失的關(guān)系值。顯然,該方法使用整個網(wǎng)絡(luò)作為語料庫,并使用信息提取和抽取技術(shù)進行知識圖譜的補全。這種方法使用的評價矩陣是正確率、召回率和排名。
一部分研究者直接從網(wǎng)站的表格中抽取關(guān)系[25-26]。其中,HOGAN A等人[25]提出一種從維基百科表格中抽取關(guān)系的方法。他們認為維基百科表格中共存的兩個實體共享知識圖譜中的一條邊,為了補全這些邊,首先使用已有關(guān)系從表格中抽取出候選實體集,然后對候選實體子集進行標(biāo)注,最后基于已標(biāo)注的候選實體子集,使用分類算法來識別知識圖譜中真正成立的關(guān)系,這種方法使用的評價矩陣是正確率和召回率。RITZE D等人[26]將上述方法擴展到任意的HTML表格中,該方法的不足是不僅要求表的列必須與DBpdedia本體中的屬性匹配,而且要求行也要與DBpdedia中的實體匹配。這種方法使用的評價矩陣是正確率和召回率。
一些研究者認為許多自動構(gòu)建的知識圖譜包含很多到其他知識圖譜的鏈接,可以利用這些鏈接對知識圖譜進行融合。其中, DUTTA A等人[27]提出一種在知識圖譜之間建立概率映射的方法。這種方法首先以類型和屬性的分布概率為基礎(chǔ),創(chuàng)建知識圖譜之間的映射,然后利用該映射得到知識圖譜中丟失的事實,最后,在兩個知識圖譜使用的類型系統(tǒng)之間建立映射。這樣就可以用一個知識圖譜的類型去預(yù)測另一個知識圖譜的類型。該方法利用黃金標(biāo)準(zhǔn)進行評估,其評價矩陣是正確率和召回率。
另外,WANG Q等人[28]利用耦合的路徑排序算法補全知識圖譜。這種方法首先設(shè)計了一個聚類算法自動發(fā)現(xiàn)彼此高度相關(guān)的關(guān)系,然后采用多任務(wù)學(xué)習(xí)策略對這些關(guān)系的預(yù)測進行耦合,這樣是為了能夠利用關(guān)系之間的聯(lián)系和共享隱式數(shù)據(jù)。該方法使用的評價矩陣是平均正確率和平均倒數(shù)排名(Mean Reciprocal Rank)。
3 常用的知識圖譜錯誤探測方法
與知識圖譜補全方法不同,知識圖譜錯誤探測的目的是利用已有信息,識別圖中的錯誤信息, 同樣,本節(jié)也將錯誤探測分成內(nèi)部和外部兩類。
3.1 知識圖譜錯誤內(nèi)部探測方法
目前錯誤內(nèi)部探測方法主要集中在文字值錯誤和鏈接錯誤上,因此本部分只對這兩類方法進行綜述。
3.1.1 文字值錯誤內(nèi)部檢測
異常檢測(Outlier detection)的目的是識別一個數(shù)據(jù)集中與大多數(shù)數(shù)據(jù)偏離的實例,即特征顯著的數(shù)據(jù)。由于異常檢測在許多情況下僅處理數(shù)值型數(shù)據(jù),因此數(shù)值型文字自然成為這些方法處理的對象。其中,WIENAND D等人[29]將不同的單變量異常值檢測方法(如四分位范圍或核密度估計)用于DBpedia中,該方法使用正確率和新增文字數(shù)作為評價矩陣。
為了降低自然異常的影響,F(xiàn)LEISCHHACKER D等人[30]對文獻[29]的方法進行了擴展,將實例集分成更小的子集,從而提高識別的正確率。這種方法還能使用其他知識圖譜預(yù)測交叉檢測異常,是內(nèi)部檢測和外部檢測方法的混合。
3.1.2 知識圖譜鏈接錯誤內(nèi)部檢測
PAULHEIM H[31]指出異常檢測不僅可用于數(shù)值型數(shù)據(jù),還可用于知識圖譜的內(nèi)部鏈接。他首先將鏈接表示成多維特征向量,然后利用標(biāo)準(zhǔn)的異常檢測技術(shù)(如局部異常因素檢測、基于簇的異常檢測)指派異常分數(shù),基于這些異常分數(shù)和所有鏈接的整體分布情況,能夠識別出不合理的鏈接。LI H等人[32]使用概率模型學(xué)習(xí)屬性之間的數(shù)學(xué)關(guān)系(如小于、大于),例如,一個人的出生日期必須在死亡日期之前。如果知識圖譜中有關(guān)系與這些關(guān)系不符,那么就說明該關(guān)系是錯誤的。
3.2 知識圖譜錯誤外部探測
知識圖譜錯誤外部探測就是除了利用知識圖譜本身外,還利用外部的資源來檢測錯誤。外部探測方法主要集中在錯誤關(guān)系探測和錯誤文字值探測兩方面。所以,本小節(jié)將從這兩個方面進行綜述。
3.2.1 錯誤關(guān)系外部檢測
錯誤關(guān)系外部檢測就是除了利用知識圖譜本身外,還利用外部的資源來檢測錯誤的實體間關(guān)系。其中, PAULHEIM H等人認為在知識圖譜構(gòu)造過程中大量的錯誤都是由一個共同的原因(如錯誤的映射或程序錯誤)造成的,因此,只需檢測少量的樣本,就會發(fā)現(xiàn)大量錯誤的語句。于是他們提出了一種識別不一致性的自動化聚類方法[33],該方法只需要給人提供代表性的樣本即可,從而解決了上述的規(guī)模問題。
3.2.2 錯誤文字值外部檢測
文獻[34]提出了一種使用知識圖譜鏈接探測錯誤數(shù)字值的自動方法,作者利用相同資源的鏈接和單個資源中屬性之間的不同匹配函數(shù)來識別錯誤。他們認為如果多個外部資源與知識圖譜中的一個事實發(fā)生沖突,那么就認為該事實是錯的。
4 討論
通過文獻發(fā)現(xiàn),將知識圖譜精化方法分成知識圖譜補全和知識圖譜錯誤探測兩大類是嚴謹?shù)摹R驗槟壳盎静淮嬖谝粋€方法同時解決知識圖譜補全和知識圖譜錯誤探測。唯一的例外是文獻[8],該文獻既能進行知識圖譜補全又能進行知識圖譜錯誤探測。但它實際上是兩個方法,分別是SDType和SDValidate,因為這兩個方法不是一個整體,而是獨立存在的。其中SDType負責(zé)進行補全,SDValidate負責(zé)進行錯誤探測。在知識圖譜精化方面,為什么大量的研究成果都只用在一個方面,這個原因還不太明確。但在客觀世界中,知識圖譜補全和知識圖譜錯誤探測這兩個過程是相輔相成的。除了將補全和錯誤檢測嚴格區(qū)別以外,還發(fā)現(xiàn)多數(shù)方法只能處理一種精化目標(biāo),同時處理多種精化目標(biāo)的方法相當(dāng)少。因此,將每類精化任務(wù)按照精化目標(biāo)進行分類這也是嚴謹?shù)摹?/p>
在知識圖譜補全方面,本文所介紹的方法都是對已有實體的類型或關(guān)系進行補全。經(jīng)文獻分析,目前沒有方法能夠增加新的實體,這種實體集擴展方法屬于NLP領(lǐng)域,但這種方法對于進一步提高知識圖譜覆蓋率非常有用,尤其可以減少長尾實體。可見,研究增加新實體的方法也將是知識圖譜精化的一個新方向。
在知識圖譜錯誤探測方面,所有方法都輸出一個潛在錯誤的語句列表。但據(jù)筆者所知,只有文獻[33]能從錯誤列表中發(fā)現(xiàn)知識圖譜模式的錯誤。因為模式是知識圖譜的一個基礎(chǔ)構(gòu)建,模式的錯誤就會造成實體的關(guān)系錯誤。可見,探測模式錯誤也將是知識圖譜精化的一個新方向。
在評價矩陣方面,發(fā)現(xiàn)大量的方法將正確率和召回率作為主要的評價矩陣,偶爾也有方法使用ROC曲線、精確率或均方根誤差;在評估方法方面,發(fā)現(xiàn)有一半以上的評估方法只使用DBpedia這樣一種知識圖譜,這樣的評估結(jié)果的作用非常有限。因為大多數(shù)的研究只對特定的知識圖譜有用,但知識圖譜根據(jù)特征的不同而不同。因此,對于只用一種知識圖譜評估的方法來說,有以下問題值得研究:(1)能否在不用特征的知識圖譜上有同樣的性能;(2)在精化過程中是否用了知識圖譜本身的特征,如是否隱含地使用DBpedia實體和對應(yīng)的維基百科頁之間的鏈接;(3)是否過度擬合圖譜的特定特征。另外,還發(fā)現(xiàn)只有少數(shù)評價方法對計算性能進行評估。但在大規(guī)模知識圖譜階段,計算性能這個指標(biāo)是一個不可忽視的維度。為了將來有一個可比較的知識圖譜評價方法,需要選一個既在數(shù)量上可比較、也在計算性能上可比較的基準(zhǔn)(benchmark)。目前這樣的研究工作在語義網(wǎng)絡(luò)的其他領(lǐng)域(如模式和實例匹配、推理和問答系統(tǒng))已經(jīng)開展。可見,知識圖譜精化的通用評價方法將是知識圖譜精化的另一個方向。
5 結(jié)論
多年來,許多研究者提出了各種知識圖譜精化方法,取得了豐碩的研究成果。由此可以預(yù)見,知識圖譜精化研究將是一個有著非常廣闊研究前景的領(lǐng)域。
本文對知識圖譜精化方法進行了綜述。綜述結(jié)果表明,該分類標(biāo)準(zhǔn)是嚴謹?shù)摹VR圖譜精化涉及機器學(xué)習(xí)、統(tǒng)計學(xué)和NLP相關(guān)知識和技術(shù),是一個綜合的研究方向。幾乎沒有一個精化方法能同時提高知識圖譜的完備性和正確率,也沒有方法對多個精化目標(biāo)進行精化,即還沒有一個改善知識圖譜質(zhì)量的整體解決方案。在評價方面,多數(shù)評價方法通常都是在一個特定的知識圖譜上進行評價,這使得難以對它們的性能進行比較。
綜上所述,雖然知識圖譜精化已經(jīng)取得了豐碩的研究成果,并且已成功應(yīng)用于許多領(lǐng)域,但仍然還不成熟,依然有很大的挑戰(zhàn)。將來可從以下幾個方面對知識圖譜精化進行深入的研究:(1)改善知識圖譜質(zhì)量的整體解決方案;(2)知識圖譜擴展性的研究;(3)知識圖譜通用的評價;(4)未知領(lǐng)域知識圖譜的構(gòu)建。隨著大規(guī)模網(wǎng)絡(luò)知識圖譜的出現(xiàn),知識圖譜的擴展和自動化的知識圖譜精化將是該領(lǐng)域未來發(fā)展的趨勢。
-
移動互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
5文章
599瀏覽量
34575 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8492瀏覽量
134125 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7934
原文標(biāo)題:【學(xué)術(shù)論文】知識圖譜精化研究綜述
文章出處:【微信號:ChinaAET,微信公眾號:電子技術(shù)應(yīng)用ChinaAET】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NLPIR系統(tǒng)KGB知識圖譜引擎為數(shù)據(jù)內(nèi)容安全設(shè)崗
NLPIR大數(shù)據(jù)知識圖譜完美展現(xiàn)文本數(shù)據(jù)內(nèi)容
NLPIR在文本信息提取方面的優(yōu)勢介紹
KGB知識圖譜基于傳統(tǒng)知識工程的突破分析
KGB知識圖譜技術(shù)能夠解決哪些行業(yè)痛點?
知識圖譜的三種特性評析
KGB知識圖譜通過智能搜索提升金融行業(yè)分析能力
領(lǐng)域知識圖譜落地實踐中的問題與對策
知識圖譜已經(jīng)取得了哪些學(xué)術(shù)與技術(shù)成果,產(chǎn)業(yè)與應(yīng)用發(fā)生了哪些變化?
知識圖譜劃分的相關(guān)算法及研究

知識圖譜在工程應(yīng)用中的關(guān)鍵技術(shù)、應(yīng)用及案例

數(shù)學(xué)課程知識圖譜構(gòu)建研究應(yīng)用綜述
《無線電工程》—基于知識圖譜的直升機飛行指揮模型研究
知識圖譜:知識圖譜的典型應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論