") 基于DensePose的姿勢轉(zhuǎn)換系統(tǒng),僅根據(jù)一張輸入圖像和目標(biāo)姿勢
基于DensePose的姿勢轉(zhuǎn)換系統(tǒng),僅根據(jù)一張輸入圖像和目標(biāo)姿勢

DensePose團隊在ECCV 2018發(fā)表又一杰作:密集人體姿態(tài)轉(zhuǎn)換!這是一個基于DensePose的姿勢轉(zhuǎn)換系統(tǒng),僅根據(jù)一張輸入圖像和目標(biāo)姿勢,生成數(shù)字人物的動畫效果。
DensePose是Facebook研究員Natalia Neverova、Iasonas Kokkinos和法國INRIA的R?za Alp Guler開發(fā)的一個令人驚嘆的人體實時姿勢識別系統(tǒng),它在2D圖像和人體3D模型之間建立映射,最終實現(xiàn)密集人群的實時姿態(tài)識別。
具體來說,DensePose利用深度學(xué)習(xí)將2D RPG圖像坐標(biāo)映射到3D人體表面,把一個人分割成許多UV貼圖(UV坐標(biāo)),然后處理密集坐標(biāo),實現(xiàn)動態(tài)人物的精確定位和姿態(tài)估計。
DensePose模型以及數(shù)據(jù)集已經(jīng)開源,傳送門:
http://densepose.org/
最近,該團隊更進一步,發(fā)布了基于DensePose的一個姿勢轉(zhuǎn)換系統(tǒng):Dense Pose Transfer,僅根據(jù)一張輸入圖像和目標(biāo)姿勢,創(chuàng)造出“數(shù)字化身”的動畫效果。
在這項工作中,研究者希望僅依賴基于表面(surface-based)的對象表示(object representations),類似于在圖形引擎中使用的對象表示,來獲得對圖像合成過程的更強把握。
研究者關(guān)注的重點是人體。模型建立在最近的SMPL模型和DensePose系統(tǒng)的基礎(chǔ)上,將這兩個系統(tǒng)結(jié)合在一起,從而能夠用完整的表面模型來說明一個人的圖像。
具體而言,這項技術(shù)是通過surface-based的神經(jīng)合成,渲染同一個人的不同姿勢,從而執(zhí)行圖像生成。目標(biāo)姿勢(target pose)是通過一個“pose donor”的圖像表示的,也就是指導(dǎo)圖像合成的另一個人。DensePose系統(tǒng)用于將新的照片與公共表面坐標(biāo)相關(guān)聯(lián),并復(fù)制預(yù)測的外觀。
我們在DeepFashion和MVC數(shù)據(jù)集進行了實驗,結(jié)果表明我們可以獲得比最新技術(shù)更好的定量結(jié)果。
除了姿勢轉(zhuǎn)換的特定問題外,所提出的神經(jīng)合成與surface-based的表示相結(jié)合的方法也有希望解決虛擬現(xiàn)實和增強現(xiàn)實的更廣泛問題:由于surface-based的表示,合成的過程更加透明,也更容易與物理世界連接。未來,姿勢轉(zhuǎn)換任務(wù)可能對數(shù)據(jù)集增強、訓(xùn)練偽造檢測器等應(yīng)用很有用。
Dense Pose Transfer
研究人員以一種高效的、自下而上的方式,將每個人體像素與其在人體參數(shù)化的坐標(biāo)關(guān)聯(lián)起來,開發(fā)了圍繞DensePose估計系統(tǒng)進行姿勢轉(zhuǎn)換的方法。
我們以兩種互補的方式利用DensePose輸出,對應(yīng)于預(yù)測模塊和變形模塊(warping module),如圖1所示。
圖1:pose transfer pipeline的概覽:給定輸入圖像和目標(biāo)姿勢,使用DensePose來執(zhí)行生成過程。
變形模塊使用DensePose表面對應(yīng)和圖像修復(fù)(inpainting)來生成人物的新視圖,而預(yù)測模塊是一個通用的黑盒生成模型,以輸入和目標(biāo)的DensePose輸出作為條件。
這兩個模塊具有互補的優(yōu)點:預(yù)測模塊成功地利用密集條件輸出來為熟悉的姿勢生成合理的圖像;但它不能推廣的新的姿勢,或轉(zhuǎn)換紋理細(xì)節(jié)。
相比之下,變形模塊可以保留高質(zhì)量的細(xì)節(jié)和紋理,允許在一個統(tǒng)一的、規(guī)范的坐標(biāo)系中進行修復(fù),并且可以自由地推廣到各種各樣的身體動作。但是,它是以身體為中心的,而不是以衣服為中心,因此沒有考慮頭發(fā)、衣服和配飾。
將這兩個模塊的輸出輸入到一個混合模塊(blending module)可以得到最好的結(jié)果。這個混合模塊通過在一個端到端可訓(xùn)練的框架中使用重構(gòu)、對抗和感知損失的組合,來融合和完善它們的預(yù)測。
圖2:warping stream上姿勢轉(zhuǎn)換的監(jiān)控信號:通過DensePose驅(qū)動的空間變換網(wǎng)絡(luò),將左側(cè)的輸入圖像扭曲到固有的表面坐標(biāo)。
圖3:Warping模塊的結(jié)果
如圖3所示,在修復(fù)過程(inpainting process),可以觀察到一個均勻的表面,捕捉了皮膚和貼身衣服的外觀,但沒有考慮頭發(fā)、裙子或外衣,因為這些不適合DensePose的表面模型。
實驗和結(jié)果
我們在DeepFashion數(shù)據(jù)集上進行實驗,該數(shù)據(jù)集包含52712個時裝模特圖像,13029件不同姿勢的服裝。我們選擇了12029件衣服進行訓(xùn)練,其余1000件用于測試。
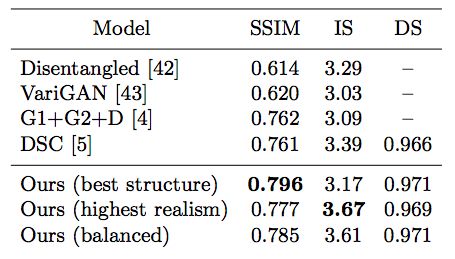
表1:根據(jù)結(jié)構(gòu)相似度(SSIM)、Inception Score(IS)[41]和detection score(DS)指標(biāo),對DeepFashion數(shù)據(jù)集的幾種state-of-the-art方法進行定量比較。
我們首先將我們的框架與最近一些基于關(guān)鍵點的圖像生成或多視圖合成方法進行比較。
表1顯示,我們的pipeline在結(jié)構(gòu)逼真度(structural fidelity)方面有顯著優(yōu)勢。在以IS作為指標(biāo)的感知質(zhì)量方面,我們模型的輸出生成具有更高的質(zhì)量,或可與現(xiàn)有工作相媲美。
定性結(jié)果如圖4所示。
圖4:與最先進的Deformable GAN (DSC)方法的定性比較。
密集人體姿態(tài)轉(zhuǎn)換應(yīng)用
在這項工作中,我們介紹了一個利用密集人體姿態(tài)估計的two-stream姿態(tài)轉(zhuǎn)換架構(gòu)。我們已經(jīng)證明,密集姿勢估計對于數(shù)據(jù)驅(qū)動的人體姿勢估計而言是一種明顯優(yōu)越的調(diào)節(jié)信號,并且通過inpainting的方法在自然的體表參數(shù)化過程中建立姿勢轉(zhuǎn)換。在未來的工作中,我們打算進一步探索這種方法在照片級真實圖像合成,以及處理更多類別方面的潛力。
作者:
R?za Alp Güler,INRIA, CentraleSupélec
Natalia Neverova,F(xiàn)acebook AI Research
Iasonas Kokkinos,F(xiàn)acebook AI Research
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41239 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122783
原文標(biāo)題:【ECCV 2018】Facebook開發(fā)姿態(tài)轉(zhuǎn)換模型,只需一張照片就能讓它跳舞(視頻)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
電腦鼠姿勢矯正
解鎖了這些姿勢!你就可以嘿!嘿!嘿!
請問UCOS III環(huán)境下正確的調(diào)試姿勢是怎樣的?
RGB MusicLab能將圖像轉(zhuǎn)換成音樂(每一張圖片都有它
從圖像數(shù)據(jù)中提取非常精準(zhǔn)的姿勢數(shù)據(jù)
圖像遷移最新成果:人體姿勢和舞蹈動作遷移
JD和OPPO的研究人員們提出了一種姿勢引導(dǎo)的時尚圖像生成模型
華為用機姿勢提醒功能詳解,可及時提醒用戶矯正不當(dāng)姿勢

華為新專利可根據(jù)凝視姿勢解鎖設(shè)備





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論