") 知識(shí)圖會(huì)成為 NLP 的未來(lái)嗎?IJCAI杰出論文背后的思考
知識(shí)圖會(huì)成為 NLP 的未來(lái)嗎?IJCAI杰出論文背后的思考
IJCAI 的評(píng)審歷來(lái)都很?chē)?yán)格,今年投稿數(shù)量更是達(dá)到了 3470 篇,接收論文 710 篇,接收率只有 20.5%(同比 2017 年, 2540 篇投稿,接收 660 篇,約26%的接收率);而來(lái)自國(guó)內(nèi)的論文更是近達(dá)半數(shù)之多,可見(jiàn)國(guó)內(nèi)研究的活躍。與往年不同,今年 IJCAI 沒(méi)有評(píng)選出 Best Paper,但是選出了 7 篇 Distinguished Paper ,其中有 4 篇都是來(lái)自國(guó)內(nèi)的研究成果。
今天 為大家采訪到了本次 IJCAI 大會(huì) Distinguished Paper 《Commonsense Knowledge Aware Conversation Generation with Graph Attention》(具有圖注意力的常識(shí)知識(shí)感知會(huì)話生成系統(tǒng))的第一作者——來(lái)自清華大學(xué)的博士研究生周昊,和大家分享其中更多的故事。
其實(shí)在去年,周昊和所在的課題組就有一項(xiàng)研究成果——Emotional Chatting Machine(情緒聊天機(jī))獲得了國(guó)內(nèi)外的高度關(guān)注,MIT 科技評(píng)論、衛(wèi)報(bào)和 NIVIDIA 就相繼進(jìn)行了追蹤和報(bào)道。
(來(lái)源于 MIT Technology Review)
(此節(jié)選部分內(nèi)容來(lái)源于 MIT Technology Review)
計(jì)算機(jī)無(wú)法衡量對(duì)話內(nèi)容的情感,對(duì)話人的情緒,也就無(wú)法和人進(jìn)行共情。而一個(gè)沒(méi)有情商的聊天機(jī)器人反而會(huì)成為一個(gè)話題終結(jié)者。周昊和他所在的課題組就開(kāi)發(fā)了一個(gè)能夠評(píng)估對(duì)話內(nèi)容情感并作出相應(yīng)回應(yīng)的聊天機(jī)器人,這項(xiàng)工作打開(kāi)了通往具有情感意識(shí)的新一代聊天機(jī)器人的大門(mén)。

他們?cè)谘芯恐兴岢龅那榫w聊天機(jī)(ECM),不僅可以在內(nèi)容上給出適當(dāng)?shù)姆磻?yīng),而且能在情感上給出適當(dāng)?shù)姆磻?yīng)(情緒一致)。這項(xiàng)工作已經(jīng)在 TensorFlow 中實(shí)現(xiàn),我們?cè)谖哪└缴狭岁P(guān)于這項(xiàng)研究工作的論文和 GitHub 訪問(wèn)鏈接。
IJCAI 會(huì)議回來(lái)后, 約到了周昊,請(qǐng)他談了談這次獲獎(jiǎng)的一些感悟、研究成果和心得,在此分享給 的讀者們。
以下為對(duì)話內(nèi)容, 做了不改變?cè)獾恼怼?/p>
今年國(guó)內(nèi)在 ICJAI 會(huì)議上的成果很多,是什么時(shí)候收到通知被評(píng)為 Distinguished Paper的?還記得當(dāng)時(shí)是什么心情嗎?
周昊 我是在開(kāi)幕式的時(shí)候才知道被評(píng)為Distinguished Paper 的,之前沒(méi)有收到任何通知,當(dāng)時(shí)就覺(jué)得比較幸運(yùn)吧,論文能被評(píng)審認(rèn)可。
現(xiàn)在 NLP 領(lǐng)域中還有很多有待突破的問(wèn)題,大家也都很想知道關(guān)于更有價(jià)值的研究方向?你覺(jué)得未來(lái)新的研究方向會(huì)有什么?
周昊 在會(huì)議上聽(tīng)了 LeCun 的演講《 Learning World Models: the Next Step Towards AI》,感覺(jué) World Models 或者 Commonsense Knowledge 在機(jī)器學(xué)習(xí)中的應(yīng)用可能會(huì)成為新的研究方向。
你在這次的研究工作中也是引入了 Commonsense Knowledge (常識(shí)知識(shí)),從提出到實(shí)現(xiàn)的這個(gè)研究過(guò)程,遇到過(guò)什么問(wèn)題嗎?可以和大家分享一下嗎?
周昊 當(dāng)時(shí)最早開(kāi)始想做知識(shí)驅(qū)動(dòng)的對(duì)話生成模型,是因?yàn)閷?duì)話或者語(yǔ)言其實(shí)是一種知識(shí)交流的媒介,而現(xiàn)有的從大規(guī)模語(yǔ)料中學(xué)習(xí)的生成式對(duì)話模型盡管能學(xué)習(xí)到不錯(cuò)的語(yǔ)法知識(shí),但是對(duì)語(yǔ)言背后本質(zhì)的知識(shí)卻缺少建模能力。所以我們?cè)O(shè)計(jì)了這個(gè)引入常識(shí)知識(shí)的對(duì)話模型想利用知識(shí)驅(qū)動(dòng)對(duì)話生成。我們當(dāng)時(shí)的想法是利用知識(shí)推理的一種方式,可以從用戶問(wèn)題的知識(shí)子圖出發(fā),選擇一度鄰域的子圖中概率最大的實(shí)體作為下一個(gè)關(guān)鍵節(jié)點(diǎn),繼續(xù)拓展其一度鄰域的子圖選擇概率最大的實(shí)體,這樣一步步推理下去會(huì)得到一個(gè)推理路徑,作為我們對(duì)話生成的知識(shí)信息,這也是我們?nèi)祟?lèi)進(jìn)行知識(shí)推理的方式。然而在實(shí)際工作中,我們發(fā)現(xiàn)無(wú)論是常識(shí)知識(shí)圖還是對(duì)話語(yǔ)料中都存在許多噪聲,并且數(shù)據(jù)稀疏性也是個(gè)大問(wèn)題。所以我們最后選擇了一度鄰域子圖進(jìn)行數(shù)據(jù)集的過(guò)濾與創(chuàng)建。感興趣的同學(xué)可以繼續(xù)探索知識(shí)推理在對(duì)話中的應(yīng)用。
能用一句話來(lái)介紹一下圖注意力機(jī)制嗎?其本質(zhì)是什么?
周昊 圖注意力機(jī)制是一種層次化的概率模型,通過(guò)不同層次知識(shí)圖的概率計(jì)算,可以提取知識(shí)圖中不同層次的知識(shí),同時(shí)生成知識(shí)的推理路徑。
知識(shí)圖會(huì)成為 NLP 的未來(lái)嗎?
周昊 知識(shí)在nlp中已經(jīng)有了很多應(yīng)用,未來(lái)應(yīng)用會(huì)更廣泛,至于是否會(huì)以知識(shí)圖的方式加入進(jìn)來(lái)取決于技術(shù)和模型的發(fā)展了。
去年你的另外一篇論文關(guān)于 Emotional Chatting Machine 的研究也是獲得了非常高的關(guān)注,MIT科技評(píng)論、衛(wèi)報(bào)和NIVIDIA也進(jìn)行了專(zhuān)門(mén)的報(bào)道,再到今年獲得 Distinguished Paper,有什么研究經(jīng)驗(yàn)可以讓大家借鑒嗎?
周昊 在研究方面,我比較喜歡發(fā)現(xiàn)一些新的問(wèn)題。大致過(guò)程就像做產(chǎn)品一樣,首先要明確需求(需求最好是重要且容易定義的),然后尋找資源構(gòu)造數(shù)據(jù)(數(shù)據(jù)沒(méi)有必要十分旁大,因?yàn)閿?shù)據(jù)處理,模型訓(xùn)練會(huì)浪費(fèi)很多時(shí)間,從小數(shù)據(jù)做起驗(yàn)證想法,一步步擴(kuò)展也是不錯(cuò)的思路),接著是從需求出發(fā)設(shè)計(jì)模型(可以將人的先驗(yàn)知識(shí)如任務(wù)的定義、語(yǔ)言學(xué)的資源融入到模型中),最后就是對(duì)比實(shí)驗(yàn)(不同會(huì)議偏好的實(shí)驗(yàn)也不同,比如 AAAI、IJCAI 之類(lèi) AI 的會(huì)議比較偏向能夠解釋說(shuō)明 motivation 的實(shí)驗(yàn),ACL、EMNLP 之類(lèi) NLP 的會(huì)議比較偏向統(tǒng)計(jì)性指標(biāo)、多組 baseline 對(duì)比以及 ablation test 等實(shí)驗(yàn))。通過(guò)實(shí)驗(yàn)結(jié)果的反饋不斷迭代修改整個(gè)流程,最后得到一個(gè)滿意的結(jié)果。
大家都非常關(guān)注也想更多了解關(guān)于清華大學(xué) NLP 的研究,可以給我們的讀者介紹一下清華 NLP 研究課題組嗎?
周昊 清華大學(xué)進(jìn)行 NLP 研究的課題組有很多,研究方向各不相同。我們組(指導(dǎo)老師 朱小燕、黃民烈)主要研究的是交互式人工智能,即通過(guò)對(duì)話、交互體現(xiàn)出來(lái)的智能行為,通常智能系統(tǒng)通過(guò)與用戶或環(huán)境進(jìn)行交互,并在交互中實(shí)現(xiàn)學(xué)習(xí)與建模。我們組的主要研究方向有深度學(xué)習(xí)、強(qiáng)化學(xué)習(xí)、問(wèn)答系統(tǒng)、對(duì)話系統(tǒng)、情感理解、邏輯推理、語(yǔ)言生成等。其他如孫茂松老師組的詩(shī)詞生成,劉洋老師組的機(jī)器翻譯等等。如果有對(duì) NLP 研究感興趣的同學(xué)們歡迎來(lái)各個(gè)課題組交流。
▌ 很感謝今天周昊和我們聊了這么多關(guān)于 NLP 領(lǐng)域的研究,自己的研究心得還有關(guān)于清華 NLP 課題組的分享。最后我們?cè)谥荜坏闹笇?dǎo)意見(jiàn)下對(duì)他的獲獎(jiǎng)?wù)撐倪M(jìn)行了解讀,希望可以給大家的研究與學(xué)習(xí)帶來(lái)靈感,有所收獲。(譯者 | 王天宇;編輯 | Jane)

摘要
常識(shí)知識(shí)對(duì)于自然語(yǔ)言處理來(lái)說(shuō)至關(guān)重要。在本文中,我們提出了一種新的開(kāi)放域?qū)υ挼纳赡P停源藖?lái)展現(xiàn)大規(guī)模的常識(shí)知識(shí)庫(kù)是如何提升語(yǔ)言理解與生成的。若輸入一個(gè)問(wèn)題,模型會(huì)從知識(shí)庫(kù)中檢索相關(guān)的知識(shí)圖,然后基于靜態(tài)圖注意力機(jī)制對(duì)其進(jìn)行編碼,圖注意力機(jī)制有助于提升語(yǔ)義信息,從而幫助系統(tǒng)更好地理解問(wèn)題。接下來(lái),在語(yǔ)句的生成過(guò)程中,模型會(huì)逐個(gè)讀取檢索到的知識(shí)圖以及每個(gè)圖中的知識(shí)三元組,并通過(guò)動(dòng)態(tài)的圖注意力機(jī)制來(lái)優(yōu)化語(yǔ)句的生成。我們首次嘗試了在對(duì)話生成中使用大規(guī)模的常識(shí)知識(shí)庫(kù)。此外,現(xiàn)有的模型都是將知識(shí)三元組分開(kāi)使用的,而我們的模型將每個(gè)知識(shí)圖作為完整的個(gè)體,從而獲得結(jié)構(gòu)更清晰,語(yǔ)義也更連貫的編碼信息。實(shí)驗(yàn)顯示,與當(dāng)前的最高水平相比,我們提出的模型所生成的對(duì)話更為合理,信息量也更大。
簡(jiǎn)介
在許多自然語(yǔ)言處理工作中,尤其在處理常識(shí)知識(shí)和客觀現(xiàn)象時(shí),語(yǔ)義的理解顯得尤為重要,毋庸置疑,它是一個(gè)成功的對(duì)話系統(tǒng)的關(guān)鍵要素,因?yàn)閷?duì)話互動(dòng)是一個(gè)基于“語(yǔ)義”的過(guò)程。在開(kāi)放域?qū)υ捪到y(tǒng)中,常識(shí)知識(shí)對(duì)于建立有效的互動(dòng)是很重要的,這是因?yàn)樯鐣?huì)共享的常識(shí)知識(shí)是大眾樂(lè)于了解并在談話中使用的信息。
最近,在對(duì)話生成方面有很多神經(jīng)模型被提出。但這些模型往往給出比較籠統(tǒng)的回復(fù),大多數(shù)情況下,無(wú)法生成合適且信息豐富的答案,因?yàn)槿舨粚?duì)用戶的輸入信息、背景知識(shí)和對(duì)話內(nèi)容進(jìn)行深度理解,是很難從對(duì)話數(shù)據(jù)中獲取語(yǔ)義交互信息的。當(dāng)一個(gè)模型能夠連接并充分利用大規(guī)模的常識(shí)知識(shí)庫(kù),它才能更好地理解對(duì)話內(nèi)容,并給出更合理的回復(fù)。舉個(gè)例子,假如模型要理解這樣一對(duì)語(yǔ)句,“Don’t order drinks at the restaurant , ask for free water”和“Not in Germany. Water cost more than beer. Bring your own water bottle”,我們需要的常識(shí)知識(shí)可以包括(water,AtLocation,restaurant),(free, RelatedTo, cost)等。
在此之前,有些研究已經(jīng)在對(duì)話生成中引入了外部知識(shí)。這些模型所用到的知識(shí)是非結(jié)構(gòu)化的文本或特定領(lǐng)域的知識(shí)三元組,但存在兩個(gè)問(wèn)題,第一,它們高度依賴非結(jié)構(gòu)化文本的質(zhì)量,受限于小規(guī)模的、領(lǐng)域特定的知識(shí)庫(kù)。第二,它們通常將知識(shí)三元組分開(kāi)使用,而不是將其作為每個(gè)圖的完整個(gè)體。因此,這類(lèi)模型不能基于互相關(guān)聯(lián)的實(shí)體和它們之間的關(guān)系來(lái)給出圖的語(yǔ)義信息。
為解決這兩個(gè)問(wèn)題,我們提出了常識(shí)知識(shí)感知對(duì)話模型(Commonsense Knowledge Aware Conversational Model, CCM),以優(yōu)化語(yǔ)言理解和開(kāi)放域?qū)υ捪到y(tǒng)的對(duì)話生成。我們使用大規(guī)模的常識(shí)知識(shí)來(lái)幫助理解問(wèn)題的背景信息,從而基于此類(lèi)知識(shí)來(lái)優(yōu)化生成的答案。該模型為每個(gè)提出的問(wèn)題檢索相應(yīng)的知識(shí)圖,然后基于這些圖給出富有信息量又合適的回復(fù),如圖1所示。為了優(yōu)化圖檢索的過(guò)程,我們?cè)O(shè)計(jì)了兩種新的圖注意力機(jī)制。靜態(tài)圖注意力機(jī)制對(duì)檢索到的圖進(jìn)行編碼,來(lái)提升問(wèn)題的語(yǔ)義,幫助系統(tǒng)充分理解問(wèn)題。動(dòng)態(tài)圖注意機(jī)制會(huì)讀取每個(gè)知識(shí)圖及其中的三元組,然后利用圖和三元組的語(yǔ)義信息來(lái)生成更合理的回復(fù)。
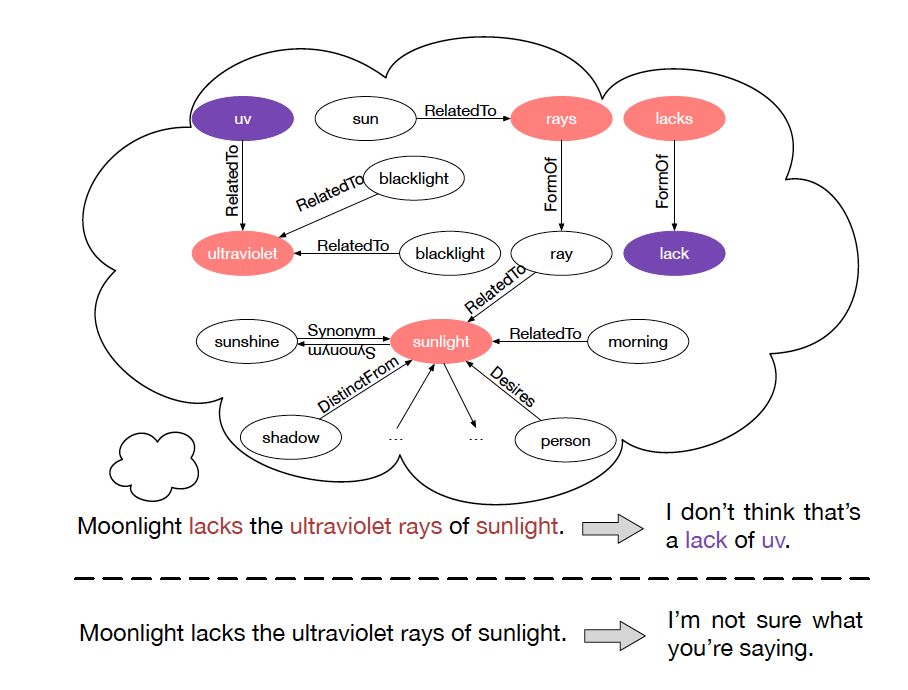
圖 1 兩種模型的對(duì)比。第一行回復(fù)由我們的模型(引入常識(shí)知識(shí))生成,
第二行回復(fù)由 Seq2Seq 模型(未引入常識(shí)知識(shí))生成。
總地來(lái)說(shuō),本文主要做出了以下突破
該項(xiàng)目是首次在對(duì)話生成神經(jīng)系統(tǒng)中,嘗試使用大規(guī)模常識(shí)知識(shí)。有了這些知識(shí)的支撐,我們的模型能夠更好地理解對(duì)話,從而給出更合適、信息量更大的回復(fù)。
代替過(guò)去將知識(shí)三元組分開(kāi)使用的方法,我們?cè)O(shè)計(jì)了靜態(tài)和動(dòng)態(tài)圖注意力機(jī)制,把知識(shí)三元組看作一個(gè)圖,基于與其相鄰實(shí)體和它們之間的關(guān)系,我們可以更好地解讀所研究實(shí)體的語(yǔ)義。
常識(shí)對(duì)話模型
▌2.1 背景 Encoder - Decoder 模型
首先,我們介紹一下基于 seq2seq 的 Encoder-Decoder 模型。編碼器表示一個(gè)問(wèn)題序列???
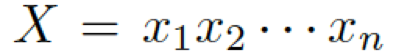
?,其隱藏層可表示為???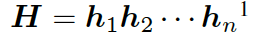 ?,可以簡(jiǎn)單寫(xiě)作如下形式 ??
?,可以簡(jiǎn)單寫(xiě)作如下形式 ??
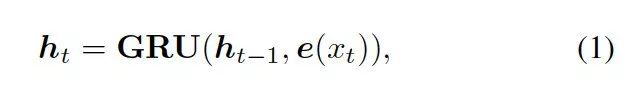
?
這里的???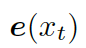 ?是????
?是????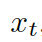 ?的詞嵌入結(jié)果,GRU (Gated Recurrent Unit) 是門(mén)控循環(huán)單元。
?的詞嵌入結(jié)果,GRU (Gated Recurrent Unit) 是門(mén)控循環(huán)單元。
解碼器將上下文向量???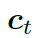 ?和?
?和?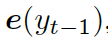 ???的詞嵌入結(jié)果作為輸入,同時(shí)使用另一個(gè) GRU(門(mén)控循環(huán)單元)來(lái)更新其狀態(tài)?
???的詞嵌入結(jié)果作為輸入,同時(shí)使用另一個(gè) GRU(門(mén)控循環(huán)單元)來(lái)更新其狀態(tài)?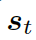 ???
???
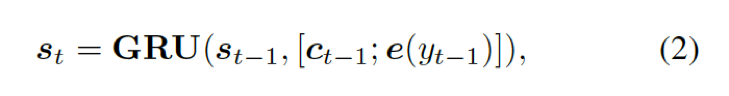
?
這里的?
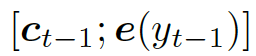
???結(jié)合兩個(gè)向量,共同作為 GRU 網(wǎng)絡(luò)的輸入。上下文向量?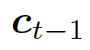 ???是?H?的詞嵌入結(jié)果,也就是編碼器隱藏狀態(tài)的權(quán)重和
???是?H?的詞嵌入結(jié)果,也就是編碼器隱藏狀態(tài)的權(quán)重和
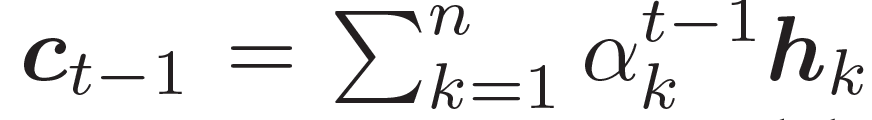
??,?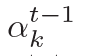 估量了狀態(tài)?
估量了狀態(tài)? ???和隱藏狀態(tài)?
???和隱藏狀態(tài)? ???中間的相關(guān)度。
???中間的相關(guān)度。
從輸出的可能性分布中抽取樣本,解碼器會(huì)產(chǎn)生一個(gè) token,可能性的計(jì)算如下
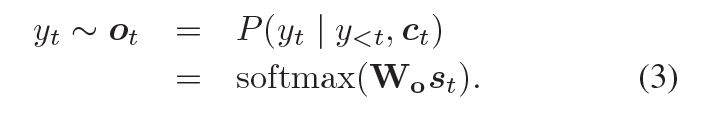
?
此處?
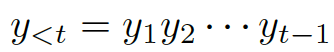
???,這些詞便生成了。
譯者注 Seq2Seq 模型與經(jīng)典模型有所不同的是,經(jīng)典的 N vs N 循環(huán)神經(jīng)網(wǎng)絡(luò)要求序列要等長(zhǎng),但我們?cè)谧鰧?duì)話生成時(shí),問(wèn)題和回復(fù)長(zhǎng)度往往不同。因此 Encoder-Decoder 結(jié)構(gòu)通過(guò) Encoder 將輸入數(shù)據(jù)編碼成一個(gè)上下文向量,再通過(guò) Decoder 對(duì)這個(gè)上下文向量進(jìn)行解碼,這里的 Encoder 和 Decoder 都是 RNN 網(wǎng)絡(luò)實(shí)現(xiàn)的。
▌2.2 任務(wù)定義與概述
我們的問(wèn)題描述如下 給定一個(gè)問(wèn)題
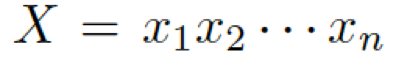
??和一些常識(shí)知識(shí)的圖???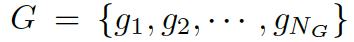 ?,目標(biāo)是生成合理的回復(fù)?
?,目標(biāo)是生成合理的回復(fù)?
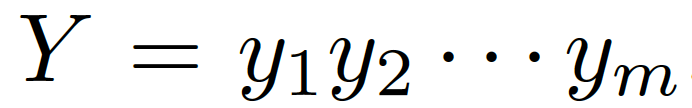
???。本質(zhì)上來(lái)看,該模型估計(jì)了概率 ???
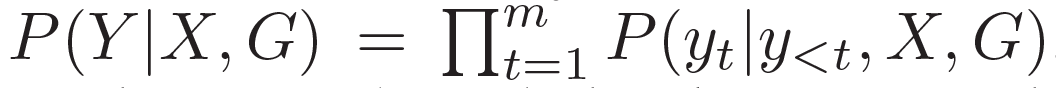
。基于問(wèn)題從知識(shí)庫(kù)中檢索圖,每個(gè)單詞對(duì)應(yīng)G中的一個(gè)圖。每個(gè)圖包含一個(gè)三元組的集合?
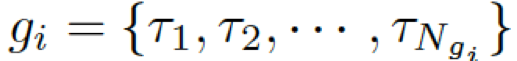
???,每個(gè)三元組(頭實(shí)體、關(guān)系、尾實(shí)體)可表示為???
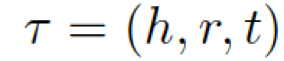
?。
為了把知識(shí)庫(kù)與非結(jié)構(gòu)化的對(duì)話本文相關(guān)聯(lián),我們采用了 MLP 模型 一個(gè)知識(shí)三元組???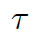 ?可以表示為 k= (h,r,t) =MLP(TransE(h,r,t)),這里的h/r/t是經(jīng)過(guò) TransE 模型分別轉(zhuǎn)化處理過(guò)的h / r / t.
?可以表示為 k= (h,r,t) =MLP(TransE(h,r,t)),這里的h/r/t是經(jīng)過(guò) TransE 模型分別轉(zhuǎn)化處理過(guò)的h / r / t.
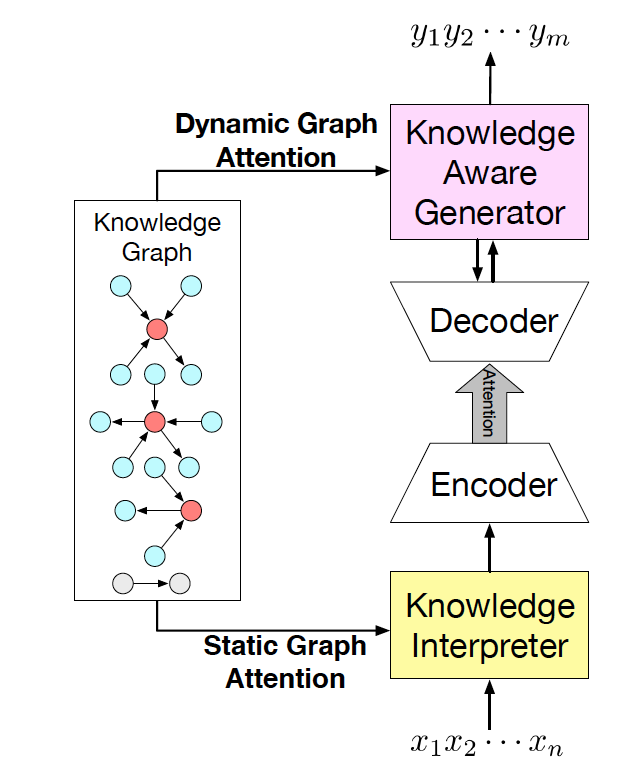
圖 2 CCM 結(jié)構(gòu)圖
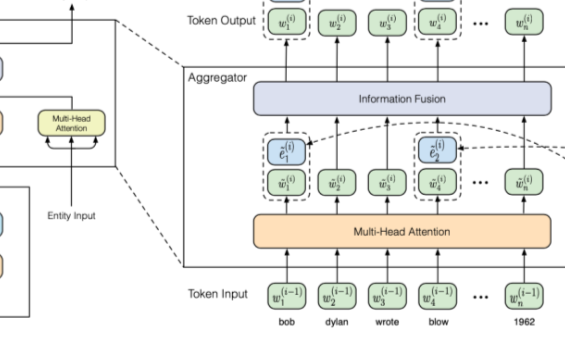
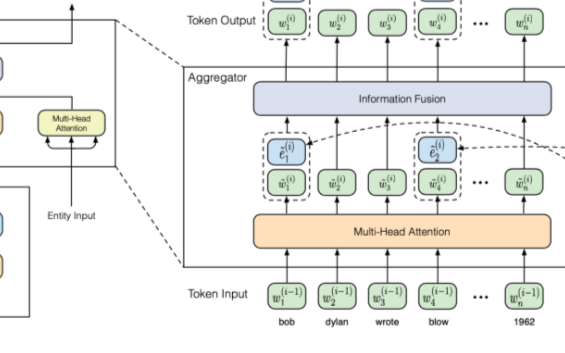
我們的常識(shí)對(duì)話模型(Commonsense Conversational Model, CCM)的概覽如圖 2 所示。知識(shí)解析器 (Knowledge Interpreter) 將問(wèn)題?
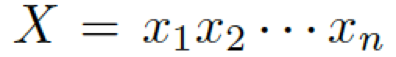
?和檢索得到的知識(shí)圖???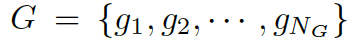 ?作為輸入,通過(guò)把單詞向量和與其對(duì)應(yīng)的知識(shí)圖向量相結(jié)合,來(lái)獲得對(duì)每個(gè)單詞的知識(shí)感知。通過(guò)靜態(tài)圖注意力機(jī)制,知識(shí)圖向量包含了問(wèn)題?X中對(duì)應(yīng)每個(gè)單詞的知識(shí)圖。基于我們的動(dòng)態(tài)圖注意力機(jī)制,知識(shí)感知生成器 (Knowledge Aware Generator) 生成了回復(fù)???
?作為輸入,通過(guò)把單詞向量和與其對(duì)應(yīng)的知識(shí)圖向量相結(jié)合,來(lái)獲得對(duì)每個(gè)單詞的知識(shí)感知。通過(guò)靜態(tài)圖注意力機(jī)制,知識(shí)圖向量包含了問(wèn)題?X中對(duì)應(yīng)每個(gè)單詞的知識(shí)圖。基于我們的動(dòng)態(tài)圖注意力機(jī)制,知識(shí)感知生成器 (Knowledge Aware Generator) 生成了回復(fù)???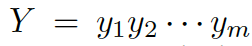 ?。在每個(gè)解碼環(huán)節(jié),它讀取檢索到的圖和每個(gè)圖中的實(shí)體,然后在詞匯表中生成通用詞匯,或在知識(shí)圖中生成實(shí)體。
?。在每個(gè)解碼環(huán)節(jié),它讀取檢索到的圖和每個(gè)圖中的實(shí)體,然后在詞匯表中生成通用詞匯,或在知識(shí)圖中生成實(shí)體。
▌2.3 知識(shí)解析器
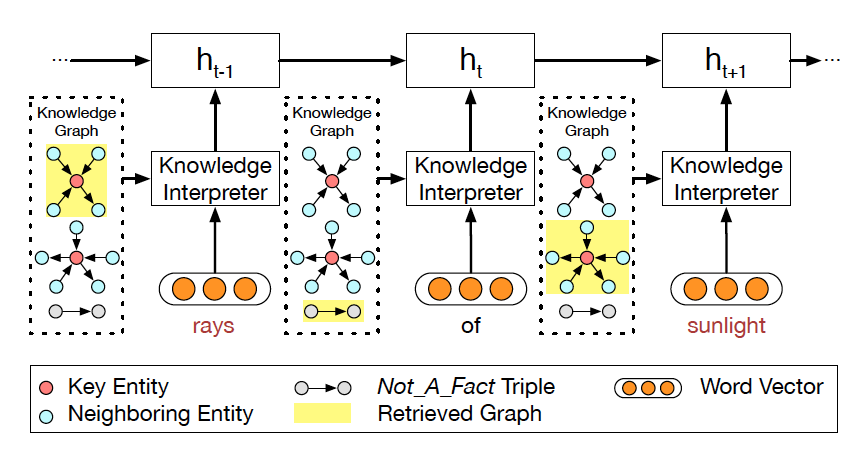
圖 3 知識(shí)解析器把單詞向量和圖向量相結(jié)合。
在該例子中,單詞 rays 對(duì)應(yīng)第一個(gè)圖,sunlight 對(duì)應(yīng)第二個(gè)圖。
每個(gè)圖都用圖向量表示。關(guān)鍵實(shí)體 (Key Entity) 表示當(dāng)前問(wèn)題中的實(shí)體。
知識(shí)解析器 (Knowledge Interpreter) 旨在優(yōu)化問(wèn)題理解這一環(huán)節(jié)。它通過(guò)引入每個(gè)單詞對(duì)應(yīng)的圖向量,來(lái)增強(qiáng)單詞的語(yǔ)義,如圖 3 所示。知識(shí)解析器把問(wèn)題中的每個(gè)單詞 xt 作為關(guān)鍵實(shí)體,從整個(gè)常識(shí)知識(shí)庫(kù)中檢索圖????
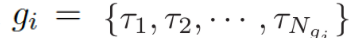 (圖中黃色部分)。每個(gè)檢索到的圖包含一個(gè)關(guān)鍵實(shí)體(圖中紅色圓點(diǎn)),與其相鄰的實(shí)體(圖中藍(lán)色圓點(diǎn))以及實(shí)體之間的關(guān)系。對(duì)一些常用詞匯(如 of)來(lái)說(shuō),常識(shí)知識(shí)圖中沒(méi)有與其匹配的圖,這類(lèi)詞匯用一個(gè)帶有特殊標(biāo)志 Not_A_Fact(圖中灰色圓點(diǎn))的圖來(lái)表示。接下來(lái),知識(shí)解析器會(huì)基于靜態(tài)圖注意力機(jī)制,來(lái)計(jì)算檢索到的圖的圖向量?
(圖中黃色部分)。每個(gè)檢索到的圖包含一個(gè)關(guān)鍵實(shí)體(圖中紅色圓點(diǎn)),與其相鄰的實(shí)體(圖中藍(lán)色圓點(diǎn))以及實(shí)體之間的關(guān)系。對(duì)一些常用詞匯(如 of)來(lái)說(shuō),常識(shí)知識(shí)圖中沒(méi)有與其匹配的圖,這類(lèi)詞匯用一個(gè)帶有特殊標(biāo)志 Not_A_Fact(圖中灰色圓點(diǎn))的圖來(lái)表示。接下來(lái),知識(shí)解析器會(huì)基于靜態(tài)圖注意力機(jī)制,來(lái)計(jì)算檢索到的圖的圖向量?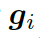 ???。把單詞向量?
???。把單詞向量?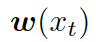 ???和知識(shí)圖向量????
???和知識(shí)圖向量????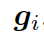 相結(jié)合,就得到了向量???
相結(jié)合,就得到了向量???
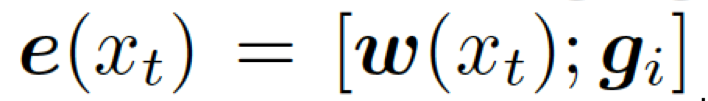
?,然后把它喂給編碼器中的 GRU(門(mén)控循環(huán)單元,見(jiàn)圖 1)。
靜態(tài)圖注意力
靜態(tài)圖注意力機(jī)制的設(shè)計(jì)旨在為檢索到的知識(shí)圖提供一個(gè)表現(xiàn)形式,我們?cè)O(shè)計(jì)的機(jī)制不僅考慮到圖中的所有節(jié)點(diǎn),也同時(shí)考慮節(jié)點(diǎn)之間的關(guān)系,因此編碼的語(yǔ)義信息更加結(jié)構(gòu)化。
靜態(tài)圖注意力機(jī)制會(huì)為每個(gè)圖生成一個(gè)靜態(tài)的表現(xiàn)形式,因而有助于加強(qiáng)問(wèn)題中每個(gè)單詞的語(yǔ)義。
形式上,靜態(tài)圖注意力把圖??中的知識(shí)三元組向量???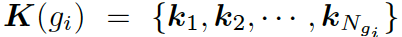 ?作為輸入,來(lái)生成如下的圖向量
?作為輸入,來(lái)生成如下的圖向量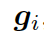
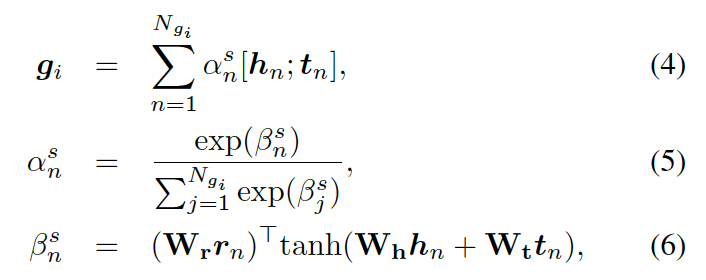
?
這里的???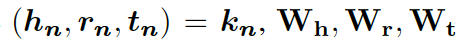 ?分別是頭實(shí)體、關(guān)系、尾實(shí)體的權(quán)重矩陣。注意力的權(quán)重估量了“實(shí)體間關(guān)系”???
?分別是頭實(shí)體、關(guān)系、尾實(shí)體的權(quán)重矩陣。注意力的權(quán)重估量了“實(shí)體間關(guān)系”???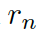 ?和“頭實(shí)體”???
?和“頭實(shí)體”???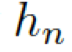 ?以及“尾實(shí)體”????
?以及“尾實(shí)體”????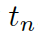 之間的關(guān)聯(lián)度。
之間的關(guān)聯(lián)度。
本質(zhì)上來(lái)說(shuō),圖向量??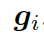 ?
?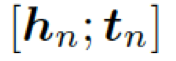 ?的權(quán)重和。
?的權(quán)重和。
▌2.4 知識(shí)感知生成器
??
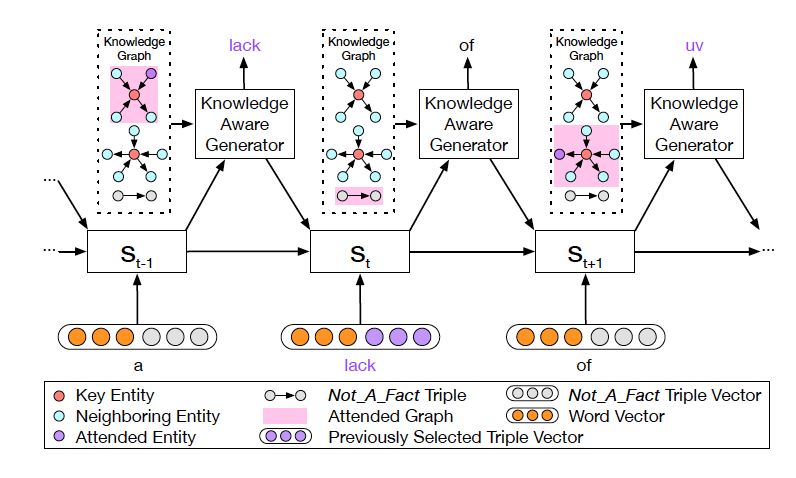
圖 4: 知識(shí)感知生成器動(dòng)態(tài)地處理著圖
知識(shí)感知生成器 (Knowledge Aware Generator) 旨在通過(guò)充分利用檢索到的圖,來(lái)生成相應(yīng)的回復(fù),如圖 4 所示。知識(shí)感知生成器扮演了兩個(gè)角色 1) 讀取所有檢索到的圖,來(lái)獲取一個(gè)圖感知上下文向量,并用這個(gè)向量來(lái)更新解碼器的狀態(tài);2) 自適應(yīng)地從檢索到的圖中,選擇通用詞匯或?qū)嶓w來(lái)生成詞語(yǔ)。形式上來(lái)看,解碼器通過(guò)如下過(guò)程來(lái)更新?tīng)顟B(tài)
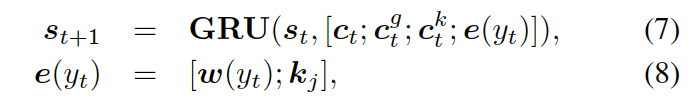
?
這里???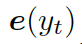 ?是單詞向量???
?是單詞向量???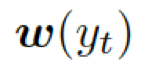 ?和前一個(gè)知識(shí)三元組向量???
?和前一個(gè)知識(shí)三元組向量???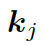 ?的結(jié)合,其來(lái)自上一個(gè)所選單詞????
?的結(jié)合,其來(lái)自上一個(gè)所選單詞????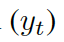 。
。
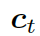 ?是式 2 中的上下文向量,???
?是式 2 中的上下文向量,???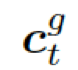 ?和???
?和???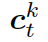 ?分別是作用于知識(shí)圖向量?
?分別是作用于知識(shí)圖向量?
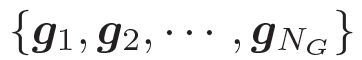
???和知識(shí)三元組向量???
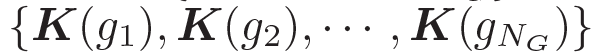
的上下文向量。
動(dòng)態(tài)圖注意力
動(dòng)態(tài)圖注意力機(jī)制是一個(gè)分層的、自上而下的過(guò)程。首先,它讀取所有的知識(shí)圖和每個(gè)圖中的所有三元組,用來(lái)生成最終的回復(fù)。若給定一個(gè)解碼器的狀態(tài)?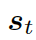 ???, 它首先作用于知識(shí)圖向量????
???, 它首先作用于知識(shí)圖向量????
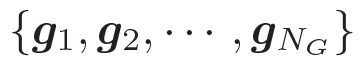
??,以計(jì)算使用每個(gè)圖的概率,如下
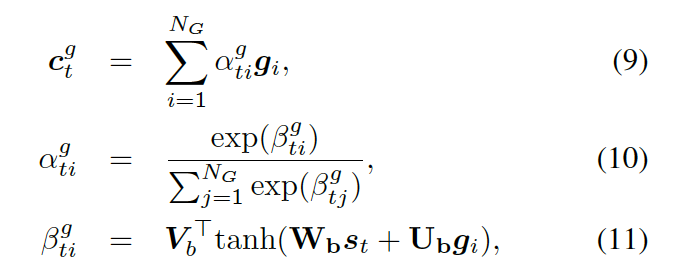
?
這里??
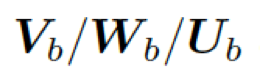
??都是參數(shù),???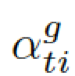 ?是處于第 t 步時(shí)選擇知識(shí)圖???
?是處于第 t 步時(shí)選擇知識(shí)圖???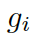 ?的概率。圖的上下文向量???
?的概率。圖的上下文向量???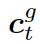 ?是圖向量的權(quán)重和,這個(gè)權(quán)重估量了解碼器的狀態(tài)??
?是圖向量的權(quán)重和,這個(gè)權(quán)重估量了解碼器的狀態(tài)??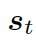
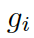
接下來(lái),該模型用每個(gè)圖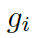 ?
?
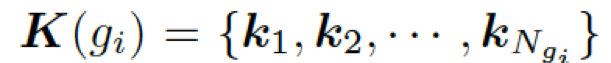
???,來(lái)計(jì)算選擇某個(gè)三元組來(lái)生成答案的概率,過(guò)程如下
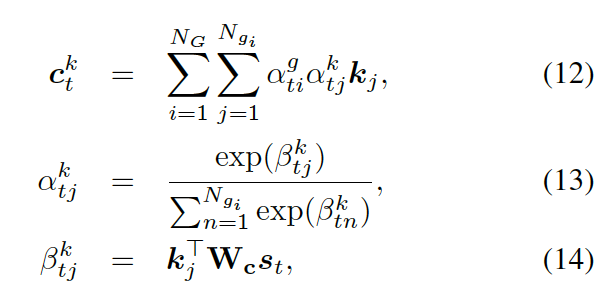
?
這里???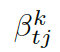 可被看作每個(gè)知識(shí)三元組向量???
可被看作每個(gè)知識(shí)三元組向量???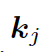 和解碼器狀態(tài)???
和解碼器狀態(tài)???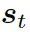 的相似度,
的相似度,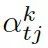
是處于第 t 步時(shí)從圖?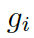 ???的所有三元組中選擇
???的所有三元組中選擇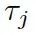 ??的概率。
??的概率。
最后,知識(shí)感知生成器選取通用詞匯或?qū)嶓w詞匯,基于如下概率分布
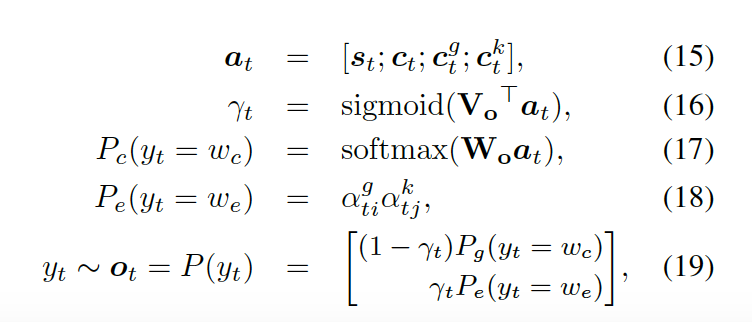
?
這里?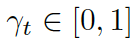 ?是用來(lái)平衡實(shí)體詞匯?
?是用來(lái)平衡實(shí)體詞匯?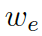 ???和通用詞匯???
???和通用詞匯???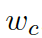 ?之間選擇的標(biāo)量,???
?之間選擇的標(biāo)量,???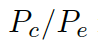 ?分別是通用詞匯和實(shí)體詞匯的概率。最終的概率???
?分別是通用詞匯和實(shí)體詞匯的概率。最終的概率???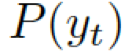 ?由兩種概率結(jié)合所得。
?由兩種概率結(jié)合所得。
譯者注 在語(yǔ)言生成過(guò)程中,引入動(dòng)態(tài)圖注意力機(jī)制,模型可以通過(guò)當(dāng)前解碼器的狀態(tài),注意到最合適的知識(shí)圖以及對(duì)應(yīng)的知識(shí)三元組,再基于此來(lái)選擇合適的常識(shí)與詞匯來(lái)生成回復(fù),從而使對(duì)話的信息量更大,內(nèi)容更加連貫合理。與很多動(dòng)態(tài)優(yōu)化算法相類(lèi)似,狀態(tài)不斷地更新與反饋,隨之自適應(yīng)地調(diào)整下一步?jīng)Q策,在對(duì)話生成系統(tǒng)中引入該機(jī)制有效地改善了生成結(jié)果。
實(shí)驗(yàn)
▌3.1 數(shù)據(jù)集
常識(shí)知識(shí)庫(kù)
我們使用語(yǔ)義網(wǎng)絡(luò) (ConceptNet) 作為常識(shí)知識(shí)庫(kù)。語(yǔ)義網(wǎng)絡(luò)不僅包括客觀事實(shí),如“巴黎是法國(guó)的首都”這樣確鑿的信息,也包括未成文但大家都知道的常識(shí),如“狗是一種寵物”。這一點(diǎn)對(duì)我們的實(shí)驗(yàn)很關(guān)鍵,因?yàn)樵诮㈤_(kāi)放域?qū)υ捪到y(tǒng)過(guò)程中,能識(shí)別常見(jiàn)概念之間是否有未成文但真實(shí)存在的關(guān)聯(lián)是必需的。
常識(shí)對(duì)話數(shù)據(jù)集
我們使用了來(lái)自 reddit 上一問(wèn)一答形式的對(duì)話數(shù)據(jù),數(shù)據(jù)集大小約為 10M。由于我們的目標(biāo)是用常識(shí)知識(shí)優(yōu)化語(yǔ)言理解和生成,所以我們?yōu)V出帶有知識(shí)三元組的原始語(yǔ)料數(shù)據(jù)。若一對(duì)問(wèn)答數(shù)據(jù)與任何三元組(即一個(gè)實(shí)體出現(xiàn)在問(wèn)題中,另一個(gè)在答復(fù)中)都沒(méi)有關(guān)聯(lián),那么這一對(duì)數(shù)據(jù)就會(huì)被剔除掉。具體數(shù)據(jù)概況可見(jiàn)表 1。
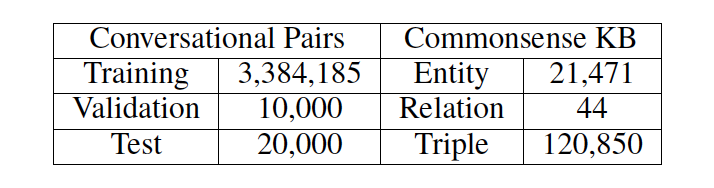
表 1: 數(shù)據(jù)集與知識(shí)庫(kù)概況
▌3.2 實(shí)驗(yàn)細(xì)節(jié)
我們的模型是在 Tensorflow 下運(yùn)行的。編碼器與解碼器均有兩層 GRU 結(jié)構(gòu),每層有 512 個(gè)隱藏單元,它們之間不會(huì)共享參數(shù)。詞嵌入時(shí)的長(zhǎng)度設(shè)置為 300。詞匯表大小限制在 30000。
我們采用了 Adam 優(yōu)化器,學(xué)習(xí)率設(shè)置為 0.0001。具體代碼已共享在 github上,文末附有地址。
▌3.3 對(duì)比模型
我們選取了幾種合適的模型作為標(biāo)準(zhǔn)來(lái)進(jìn)行對(duì)比
Seq2Seq,一種 seq2seq 模型,它被廣泛應(yīng)用于各種開(kāi)放域?qū)υ捪到y(tǒng)中。
MemNet,一個(gè)基于知識(shí)的模型,其中記憶單元用來(lái)存儲(chǔ)知識(shí)三元組經(jīng) TransE 嵌入處理后的數(shù)據(jù)。
CopyNet,一種拷貝網(wǎng)絡(luò)模型,它會(huì)從知識(shí)三元組中拷貝單詞或由詞匯表生成單詞。
▌3.4 自動(dòng)評(píng)估
指標(biāo) 我們采用復(fù)雜度 (perplexity)來(lái)評(píng)估模型生成的內(nèi)容。我們也計(jì)算了每條回復(fù)中的實(shí)體個(gè)數(shù),來(lái)估量模型從常識(shí)知識(shí)庫(kù)中挑選概念的能力,這項(xiàng)指標(biāo)記為 entity score.
結(jié)果 如表 2 所示,CCM 獲得了最低的復(fù)雜度,說(shuō)明 CCM 可以更好地理解用戶的問(wèn)題,從而給出語(yǔ)義上更合理的回復(fù)。而且與其他模型相比,在對(duì)話生成中,CCM 從常識(shí)知識(shí)中選取的實(shí)體最多,這也可以說(shuō)明常識(shí)知識(shí)可以在真正意義上優(yōu)化回復(fù)的生成。
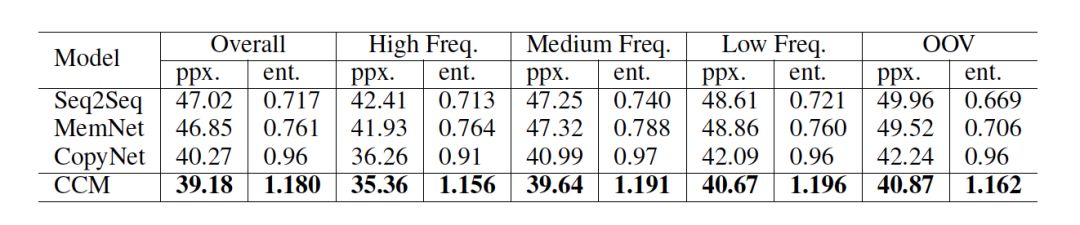
表 2: 基于 perplexity 和 entity score 的模型自動(dòng)評(píng)估
▌3.5 人工評(píng)估
我們借助于眾包服務(wù) Amazon Mechanical Turk,從人工標(biāo)記過(guò)的數(shù)據(jù)中隨機(jī)采集 400 條數(shù)據(jù)。我們基于此來(lái)將 CCM 和另外幾個(gè)模型對(duì)同一問(wèn)題生成的回復(fù)進(jìn)行對(duì)比。我們有三個(gè)對(duì)比模型,總計(jì) 1200 個(gè)問(wèn)答數(shù)據(jù)對(duì)。
指標(biāo) 我們定義了兩項(xiàng)指標(biāo) appropriateness 在內(nèi)容質(zhì)量上進(jìn)行評(píng)估(基于語(yǔ)法、主題和邏輯);informativeness 在知識(shí)層面進(jìn)行評(píng)估(基于生成的答復(fù)是否針對(duì)問(wèn)題提供了新的信息和知識(shí))。
結(jié)果 如表 3 所示,CCM 在兩項(xiàng)指標(biāo)下都比另外幾個(gè)模型表現(xiàn)更為突出。其中 CopyNet 是將知識(shí)三元組分開(kāi)單獨(dú)使用的,這也證明了圖注意力機(jī)制的有效性。
很明顯,在 OOV(out-of-vocabulary)數(shù)據(jù)集的表現(xiàn)上, CCM 比 Seq2Seq 突出得多。這也進(jìn)一步說(shuō)明常識(shí)知識(shí)在理解生僻概念上很有效,而 Seq2Seq 并沒(méi)有這個(gè)能力。對(duì)于 MemNet 和 CopyNet,我們未發(fā)現(xiàn)在這一點(diǎn)上的差別,是因?yàn)檫@兩個(gè)模型都或多或少引入使用了常識(shí)知識(shí)。

表 3: 基于 appropriateness (app.) 和 informativeness (inf.) 的人工評(píng)估
▌3.6 案例研究
如表 4 所示,這是一個(gè)對(duì)話示例。問(wèn)題中的紅色單詞 "breakable" 是知識(shí)庫(kù)里的一個(gè)單詞實(shí)體,同時(shí)對(duì)于所有模型來(lái)說(shuō),也是一個(gè)詞匯表以外的單詞。由于沒(méi)有使用常識(shí)知識(shí),且 "breakable" 是詞匯表之外的單詞,所以 Seq2Seq 模型無(wú)法理解問(wèn)題,從而給出含有OOV的回復(fù)。MemNet 因?yàn)樽x取了記憶中嵌入的三元組,可以生成若干有意義的詞匯,但輸出中仍包含OOV。CopyNet 可以從知識(shí)三元組中讀取和復(fù)制詞匯。然而,CopyNet 生成的實(shí)體單詞個(gè)數(shù)比我們的少(如表 2 所示),這是因?yàn)?CopyNet 將知識(shí)三元組分開(kāi)使用了。相比之下,CCM 將知識(shí)圖作為一個(gè)整體,通過(guò)相連的實(shí)體和它們之間的關(guān)系,與信息關(guān)聯(lián)起來(lái),使解碼更加結(jié)構(gòu)化。通過(guò)這個(gè)簡(jiǎn)單的例子,可以證明相比于其他幾個(gè)模型,CCM 可以生成更為合理、信息也更豐富的回復(fù)。

表 4: 對(duì)于同一問(wèn)題,所有模型生成的回復(fù)
總結(jié)和未來(lái)的工作
在本文中,我們提出了一個(gè)常識(shí)知識(shí)感知對(duì)話模型 (CCM),演示了常識(shí)知識(shí)有助于開(kāi)放域?qū)υ捪到y(tǒng)中語(yǔ)言的理解與生成。自動(dòng)評(píng)估與人工評(píng)估皆證明了,與當(dāng)前最先進(jìn)的模型相比,CCM 能夠生成更合理、信息量更豐富的回復(fù)。圖注意力機(jī)制的表現(xiàn),鼓舞了我們?cè)谖磥?lái)的其他項(xiàng)目中也將使用常識(shí)知識(shí)。
-
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22482 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7929
原文標(biāo)題:對(duì)話清華大學(xué)周昊,詳解IJCAI杰出論文及其背后的故事
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
KGB知識(shí)圖譜基于傳統(tǒng)知識(shí)工程的突破分析
KGB知識(shí)圖譜技術(shù)能夠解決哪些行業(yè)痛點(diǎn)?
知識(shí)圖譜的三種特性評(píng)析
KGB知識(shí)圖譜幫助金融機(jī)構(gòu)進(jìn)行風(fēng)險(xiǎn)預(yù)判
知識(shí)圖譜已經(jīng)取得了哪些學(xué)術(shù)與技術(shù)成果,產(chǎn)業(yè)與應(yīng)用發(fā)生了哪些變化?
KDD2020知識(shí)圖譜相關(guān)論文分享
如何在BERT中引入知識(shí)圖譜中信息
在BERT中引入知識(shí)圖譜中信息的若干方法
一文帶你讀懂知識(shí)圖譜
知識(shí)圖譜劃分的相關(guān)算法及研究

知識(shí)圖譜與訓(xùn)練模型相結(jié)合和命名實(shí)體識(shí)別的研究工作
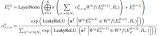
知識(shí)圖譜是NLP的未來(lái)嗎?

知識(shí)圖譜Knowledge Graph構(gòu)建與應(yīng)用
知識(shí)圖譜:知識(shí)圖譜的典型應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論