 基于硬件在環的無人駕駛仿真平臺
基于硬件在環的無人駕駛仿真平臺
第29屆IEEE國際智能車大會(IEEE IV 2018)于6月30日在江蘇常熟順利落幕,本屆大會 的Best Student Paper Awards(最佳學生論文獎)分別頒給了來自西安交通大學、加州大學伯克利分校、中山大學的三篇論文。
本屆IV大會共收到了來自34個國家的603篇論文,其中確認接收的論文346篇,在所有接收的論文里,Automated Vehicles, Vision Sensing and Perception, and Autonomous / Intelligent Robotic Vehicles成為本屆論文最熱的關鍵詞。
IV會議共設有“BestPaperAwards”、 “BestStudentPaperAwards” 、 “ BestWorkshop / Special Session Paper Awards ” 、 “Best Poster Paper Awards ” 和 “BestApplication Paper Awards”五大獎項。本文主要介紹獲得Best Student PaperAwards(最佳學生論文獎)的三篇論文,與之前BestPaper Awards論文不同,這三篇論文的第一作者都是在校學生。
IEEE IV 2018 Best Student Paper Awards
First Prize
在最佳學生論文中,獲得一等獎的是來自西安交通大學的論文基于硬件在環的無人駕駛仿真平臺(Autonomous Vehicle Testing and Validation Platform: Integrated Simulation System with Hardware in the Loop)。該論文的作者為YU Chen,Shitao Chen等都來自鄭南寧院士團隊。以下是論文簡述:
隨著自動駕駛的發展,離線測試和仿真是目前用于多種交通場景中無人駕駛車輛性能驗證的一種低成本,低風險且高效率的方法。在我們的工作中因考慮到現今不同仿真平臺的不足,我們提出了一種新型的,基于硬件在環系統的仿真平臺。該平臺支持車輛動力學仿真,各種傳感器仿真以及多種復雜交通場景構建。通過硬件在環的測試與驗證方式我們能夠有效地利用仿真環境來規避路測所帶來的潛在風險并驗證無人車多模塊算法安全性。同時通過與真車中完全相同的硬件層溝通仿真環境與現實場景,我們能夠準確有效地完成已驗證的算法從仿真環境到真實場景的遷移。
1.仿真平臺開發的目的
為了保證無人駕駛車輛開發的安全性,有效性和可持續性,必須進行廣泛的開發和測試。然而傳統的無人駕駛路測昂貴耗時,具有風險性且只能夠在有限交通場景下進行試驗。此外,一些特殊場景,如極端天氣,傳感器故障,道路部分路段損毀等也不能夠進行反復的測試和復現。而無人駕仿真系統則為這個難題提供了一種安全有效的解決途徑。借助仿真環境中對車輛動力學控制,多傳感器仿真,多交通場景模擬,我們可以極大地提高開發效率,驗證無人駕駛環境感知,車輛定位,路徑規劃以及決策控制等多模塊算法的有效性。
目前應用于無人駕駛仿真領域仿真器多種多樣,被廣泛使用的主要有TORCS, PRESCAN, CarSim, Carla等。然而這些仿真器也并不能真正意義上全面地實現對無人車性能測試的多方面的要求。涉及到的問題有車輛模型和駕駛場景的逼真度,算法測試的準確度,仿真流程的有效性以及仿真器自身是否對大多數開發者們友好開放等。
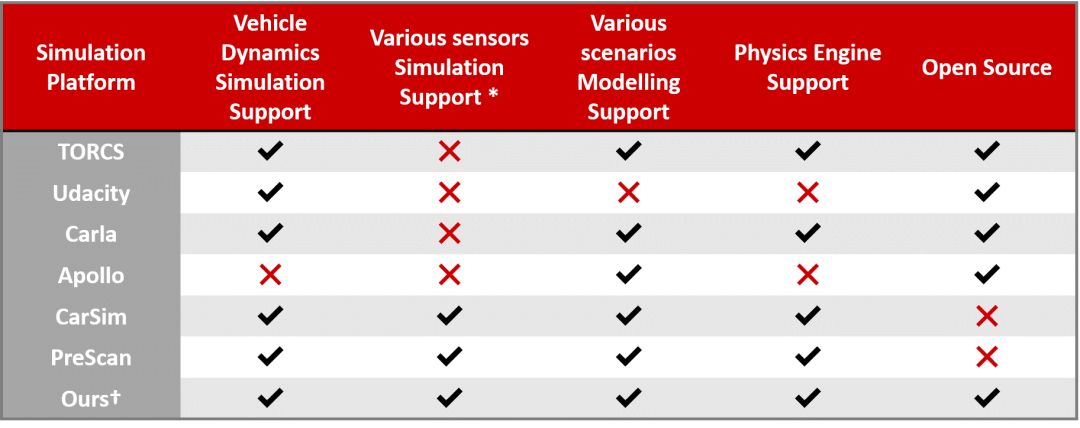
圖1 多仿真器對比表
實際上現在大多數的開源仿真器都是特別適用于無人駕駛仿真的單一或者幾個特定的模塊,并不能被應用于所用駕駛場景中。一些商業化的仿真器的功能更為全面但價格也比較昂貴。因而在我們的工作中我們的目的就是構建一個全面的,對開發者友好的仿真平臺。
此外,采用硬件在環系統進行仿真是我們平臺進行開發驗證的核心。在硬件在環的仿真方法中,我們將待進行測試的控制單元硬件連接到虛擬的仿真環境中來測試核心算法的可行性和控制器的有效性。這樣不僅能夠快速有效地評估算法的性能,同時也能夠極大的提升測試安全性和算法安全性。一方面基于硬件在環的仿真避免了實際道路測試可能導致的風險,另一方面我們能夠在模擬的仿真環境中進行各種特殊駕駛場景的測試從而訓練算法,不斷提高其魯棒性,最終保證對仿真車輛安全駕駛的模擬。
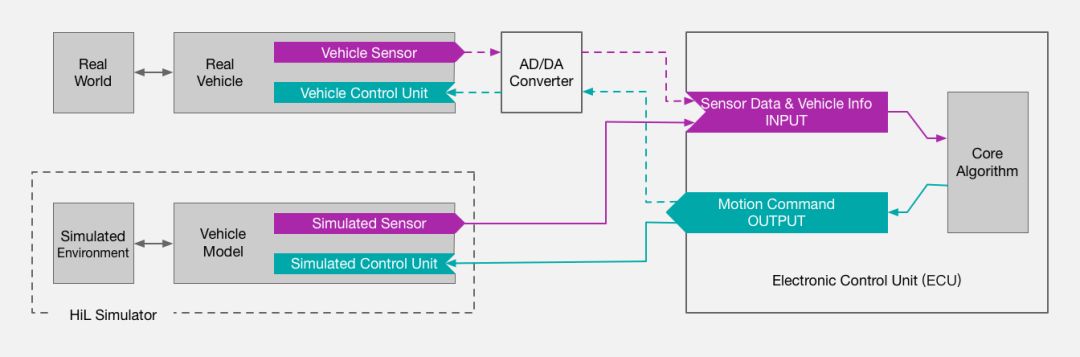
圖2 硬件在環仿真系統示意圖
2.仿真方法介紹
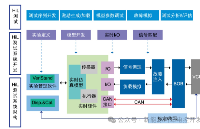
圖3 仿真框架示意圖
仿真平臺包含仿真層和硬件層兩大模塊。其中仿真層包括了仿真車輛模型設計,多仿真傳感器模擬以及多虛擬交通場景構建。硬件控制層與仿真層相連接構成閉環測試系統,用于全面測試和驗證硬件和算法。仿真傳感器信息以及車身狀態由仿真層輸入到算法進行相關計算后輸出結果到硬件控制單元生成相應的控制指令,如剎車,油門、轉向指令等,再傳入到仿真層對車輛進行相應控制。
首先對于仿真層中車輛動力學的模型設計,我們使用3D建模軟件先進行車輛建模,設定相關的必要參數,如重量、慣性、摩擦系數、扭矩等;考慮到實際車輛的安全性,仿真車輛的最大速度,前輪最大轉角,最大扭矩和最大胎壓等參數也需要具體設定;另外為了實現車輛橫向與縱向的平穩動力學控制,我們采用了Ackermann轉向幾何模型來保證車輛的安全轉向。
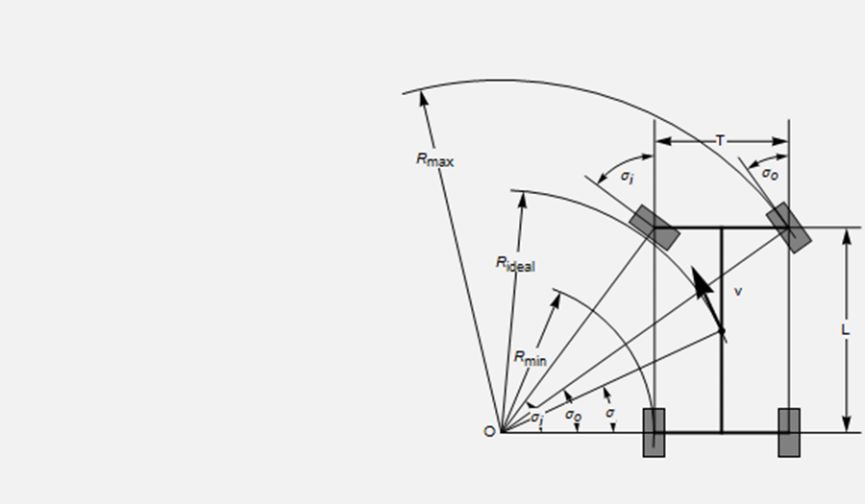
圖4 Ackermann模型
其次對于多種無人駕駛所需的傳感器的仿真,我們的平臺支持對雙目/單目相機,多線激光雷達(16/32/64),超聲波雷達,GPS以及慣性測量單元IMU的仿真模型以及實際功能模擬。傳感器能夠被簡單快速地添加,移動或者移除。我們也可選擇是否連接到傳感器或者隨時更新其配置參數,如探測范圍,信息更新頻率,噪聲程度等。
圖5 多傳感器模擬示意圖
最后對于多種虛擬駕駛環境的構建,主要有兩種方法。第一種是使用模型庫中提供的一些仿真模型,或者自行根據需求利用3D建模軟件構建仿真模型,再對單個的仿真模型進行整合從而構建出預期的仿真場景。另一種方法是使用OpenStreetMap來直接通過地圖來導出大場景模型再進行后期精細化操作。OpenStreetMap是一個強大的地圖編輯平臺,某一局部區域甚至是某一城市的實際地圖都能夠被在線導出成可編輯的文件,從而方便實現對某一固定實際場景仿真,同時也很大程度上節約了場景構建的時間。
圖6 利用OSM獲得場景模型示意圖
3.實驗與驗證
論文中提出的硬件在環仿真平臺可以被用來驗證無人駕駛車輛環境感知,路徑規劃以及運動控制等重要模塊的算法有效性。我們分別對與這些模塊緊密相關的路徑跟隨算法、自動泊車算法以及基于多智能體(multi-agent)的車輛跟隨算法進行了測試與驗證。

圖7 仿真驗證模塊示意圖
首先對于仿真車輛的路徑跟隨算法, 其需要根據給定的行駛路徑計算出符合車輛動力學的剎車,油門,轉向指令來實現平穩的路徑跟隨過程。
然后對于自動泊車算法,我們構建了一個虛擬的停車場環境方便場景模擬。目標車輛需要在行進過程中依據傳感器信息找到距離自己最近的可用停車位,并選用合適的停車方式來規劃出停車路徑并實現平穩泊車。
最后對于基于多智能體系統的車輛跟隨算法, 論文中假設每一輛車為一個智能體,其與周圍車輛以及駕駛環境進行實時交互。這樣的多智能體系統可以用來進行V2V以及V2I等方面的開發。論文中我們進行了車輛跟隨算法的驗證。通過基于增強學習的訓練過程,跟隨車輛能夠始終與前車保持一定安全距離,穩定地實現跟車換道等行為。
4.總結
論文中我們提出了一種新型的基于硬件在環的無人車仿真與測試平臺。其能夠很好的實現對車輛動力學模型,多種傳感器以及不同駕駛場景的模擬。同時硬件在環的仿真方法在降低測試成本和時間的條件下,也保證了測試的安全性和驗證了算法的安全性。
Second Prize

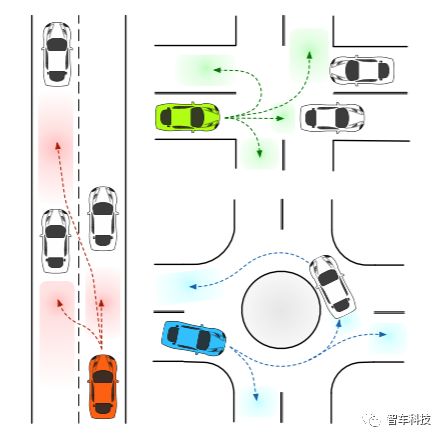
預測車輛在不同駕駛場景下的插入區域(彩色區域)
獲得最佳學生論文二等獎的是來自美國加州大學伯克利分校機械工程系的Yeping Hu博士,他在論文中分享了他們在車輛語義意圖和運動的概率預測方面的研究論文。研究涵蓋城市自動駕駛的決策,運動規劃和運動預測。目前正在開展一項BDD項目:“基于深度神經網絡學習的隨機政策的城市自主駕駛運動預測”。目前大多數研究僅通過考慮特定場景來確定駕駛意圖的數量。然而,不同的駕駛環境通常包含各種可能的駕駛操縱。因此,需要一種能夠適應不同流量場景的意圖預測方法。在Yeping Hu博士的論文中提出了一種基于語義的意圖和運動預測(SIMP)方法,可以通過使用語義定義的車輛行為來適應任何駕駛場景。它利用基于深度神經網絡的概率框架來估計周圍車輛的意圖,最終位置和相應的時間信息。
Third Prize

最佳學生論文的三等獎來自中山大學數據與計算機科學學院,該論文研究了計算機視覺的內容,同時還是國家自然科學基金項目。以下是論文的主要內容:
計算機視覺因為可以有效且通過易獲得的方式獲取周邊環境的顏色信息而成為了研究廣泛的熱門領域。通過攝像頭來幫助機器人或無人車理解其所處的外部環境也成為至關重要的一步。通過雙目視覺算法可以獲得圖像中像素點的深度信息從而可以對周圍場景進行三維建模。然而,當前所存在的三維空間表達形式存在有明顯的弊端,主要的問題集中在以下兩點:第一大規模的三維場景數據信息量非常大,如何有效的壓縮地圖大小存在一定難度;第二是如何更大程度的保存有效信息并且保障精度。
在本文中,我們關注這些問題并且提出了一種全新的三維空間表達形式并且將其命名為Planecell。通過在深度信息的監督下的平面轉區,我們可以將平面單元投影到三維空間中去。所提出的Planecell表達方式適用于大規模的人造場景中,可以在不丟失像素級別精度的情況下明顯的減少存儲圖像大小,并且可以拓展到更多的三維重建應用當中。通過實驗檢驗,我們的三維空間表達形式相比于點云地圖大小在同等精度下縮小了200倍,并且我們也和當前排名靠前的深度學習雙目匹配算法得到的點云地圖進行了像素級別的精度比較,同樣達到了不錯的結果。
圖1:Planecell方法流程圖
1.方法簡介
如圖一所示,本文所提出方法的輸入是一張色彩圖像和對應的深度圖像。我們使用一種深度監督的超像素分割算法通過在邊界更新方程中加入深度衡量項對左圖進行切割。超像素分割過程使用了爬山法來減少不必要的計算量。同時,我們還在邊界更新方程中加入規則化項來避免超像素邊界的復雜化(復雜的超像素邊界不利于保存和二維-三維轉化)。超像素的分層邊界更新只進行到固定邊長的網格大小,不再進行像素級別的更新。深度圖在本文中使用雙目匹配方法來得到結果。同樣的,較為稀疏的或者是通過其他傳感器得到的深度圖也可以作為我們算法的輸入,因為我們的算法在擬合平面時使用了隨機取樣的方式來避免錯誤點對于結果的負面影響。超像素的邊界會在平面方程擬合結果出來后進行進一步的更新。每一個超像素都是之后進行重建的基本元素。
為了更高效的保存每一個超像素。我們提出一種方法來抓取每一個超像素的角點。因為每一個超像素都是多邊形,所以只需它們的角點就能完整的保存他們的邊界信息。將二維超像素投影到三維空間中后,對于已存在的三維平面,我們通過最小化全局能量方程來聚合關系為共面單元。
2.實驗驗證
我們根據數據集的特性,分別在三個數據集上了測試了我們的算法。三個數據集分別是KITTI Stereo、KITTI Odometry和 Middlebury Stereo 數據集。KITTI Stereo 數據集將用于測試的雙目圖片分為測試集和訓練集,其中訓練集部分包含了通過激光雷達獲得的視差真值。每一組圖片包含前后兩幀的左右圖共四張圖片。KITTI測試榜單所提供的室外場景是具有挑戰性的,因為每一幅圖片都包含十分明顯的視差變化。我們的算法表現了對于 KITTI 數據集處理的優越性,尤其是對于包含大量幾何結構人造場景的圖像。為了更好的表現我們所提出的三維空間表達方式對于大規模大尺度輸入的處理能力,我們在 KITTI Odometry 上測試了上千張雙目圖片作為輸入的結果。第三個數據集是 Middlebury Stereo 2001 數據集,其中包含了9組室內場景。
我們從結果的精度、速度、內存需求和傳達有用信息的能力等方面對我們的算法進行了評估。我們在精度上對比了最基本的直接將二維像素點投影到三維空間點云的方法。接下來,我們修改了我們算法的輸入視差圖算法(包括密集、半密集和稀疏)來測量我們算法的適應性。我們同樣對比了我們算法與基于體素的三維表達方式的優勢。

表1 測試平臺
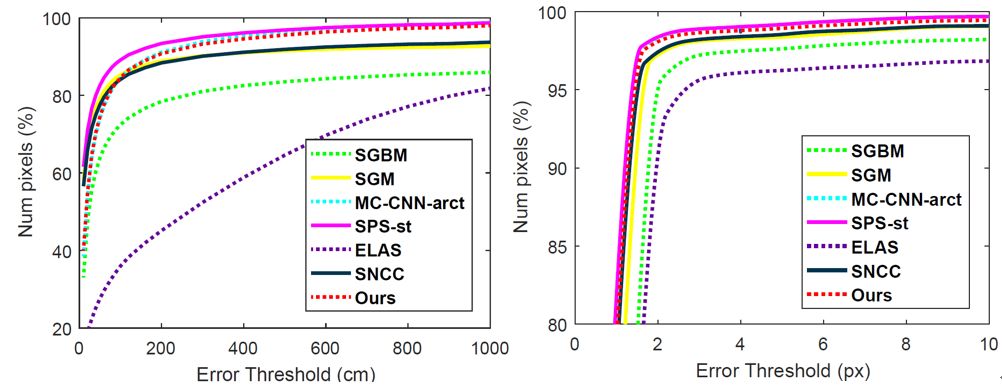
圖2:像素級別精度對比(左:KITTI stereo,右:Middlebury)
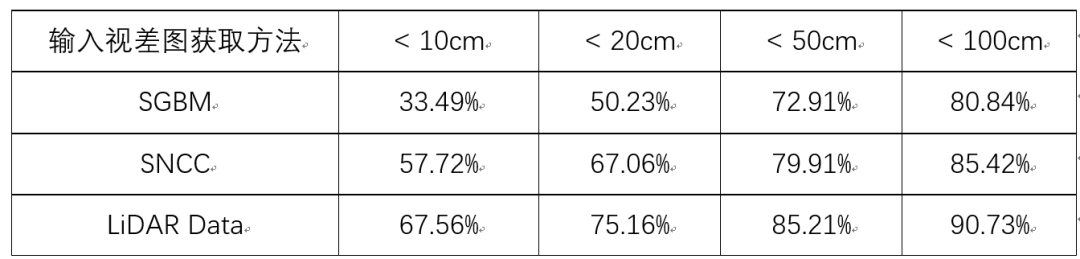
表2:修改視差圖輸入在KITTI數據集上的精度結果
圖3:單幀地圖重建結果(自上而下分別為左圖,點云圖,
voxel地圖和Planecell地圖)
圖4:2000幀的重建結果(89.1MB)
我們在本文中提出了一種新穎的方法,用一種名為 Panecell 的基本平面單元來表示結構三維空間。平面單元以深度感知方式提取,并且如果它們屬于應用所提出的CRF模型的相同表面,則可以進一步聚合。實驗表明,我們的方法考慮了像素級精度,同時有效地表達了相似像素的位置。結果避免了點云映射的冗余,并限制了輸出映射大小以用于進一步的應用。在我們未來的工作中,我們計劃開發更復雜的平面模型,如球體和圓柱體,以適應更多條件。我們還相信,給每個平面單元一個語義標簽可以更有效地擴展對環境的理解。
-
傳感器
+關注
關注
2564文章
52607瀏覽量
763837 -
無人駕駛
+關注
關注
99文章
4152瀏覽量
122901
原文標題:IV 2018 最佳學生論文獎丨西交大“基于硬件在環的無人駕駛仿真平臺”論文獲最佳
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

無人駕駛技術未來在哪里?低速才是突破口

無人駕駛解決方案包含哪些方面?感知、決策與控制
易控智駕發布礦山無人駕駛應用落地成果
DeepSeek眼中的礦山無人駕駛
為什么聊自動駕駛的越來越多,聊無人駕駛的越來越少?
東華軟件:多地無人駕駛項目成功落地
UWB模塊如何助力無人駕駛技術
特斯拉推出無人駕駛Model Y
【干貨分享】硬件在環仿真(HiL)測試
文遠知行無人駕駛掃路機在廣東汕頭落地
5G賦能車聯網,無人駕駛引領未來出行

EasyGo使用筆記丨分布式光伏集群并網控制硬件在環仿真應用







 工商網監
工商網監
評論