") 機(jī)器人如何獲得能夠有效泛化到各種現(xiàn)實(shí)世界物體和環(huán)境的技能?
機(jī)器人如何獲得能夠有效泛化到各種現(xiàn)實(shí)世界物體和環(huán)境的技能?
盡管設(shè)計(jì)一套能夠在受控環(huán)境中有效執(zhí)行重復(fù)任務(wù)的機(jī)器人系統(tǒng)(例如,在裝配線(xiàn)上組裝產(chǎn)品)十分平常,但設(shè)計(jì)一種能夠觀察周?chē)h(huán)境和確定最佳行動(dòng)方案,同時(shí)對(duì)意外結(jié)果做出反應(yīng)的機(jī)器人卻非常困難。
不過(guò),有兩種工具可以幫助機(jī)器人從經(jīng)驗(yàn)中獲得這些技能:深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。前者非常適合處理非結(jié)構(gòu)化的現(xiàn)實(shí)世界場(chǎng)景,而后者可以實(shí)現(xiàn)更長(zhǎng)期的推理,同時(shí)展現(xiàn)出更復(fù)雜、更強(qiáng)大的順序決策能力。如果將這兩種技術(shù)結(jié)合,將有可能讓機(jī)器人不斷地從經(jīng)驗(yàn)中學(xué)習(xí),使它們能夠通過(guò)數(shù)據(jù)而非人為設(shè)計(jì)來(lái)掌握基本的感覺(jué)運(yùn)動(dòng)技能。
設(shè)計(jì)用于機(jī)器人學(xué)習(xí)的強(qiáng)化學(xué)習(xí)算法本身提出了一系列挑戰(zhàn):現(xiàn)實(shí)世界的物體具有各種各樣的視覺(jué)和物理屬性,接觸力的細(xì)微差別都可能會(huì)使物體運(yùn)動(dòng)難以預(yù)測(cè),并且相關(guān)物體可能會(huì)受到遮擋。此外,機(jī)器人傳感器本身具有噪聲,這也增加了復(fù)雜性。所有這些因素綜合到一起,使得學(xué)習(xí)一個(gè)通用解異常困難,除非訓(xùn)練數(shù)據(jù)足夠多樣化,然而,收集這樣的數(shù)據(jù)又十分耗時(shí)。
這就促使人們?nèi)ヌ剿饕环N能夠有效重用過(guò)往經(jīng)驗(yàn)的學(xué)習(xí)算法,類(lèi)似于我們之前一項(xiàng)關(guān)于抓取的研究,這項(xiàng)研究就受益于大數(shù)據(jù)集。不過(guò),這項(xiàng)研究無(wú)法推斷動(dòng)作的長(zhǎng)期后果,而這一點(diǎn)對(duì)學(xué)習(xí)如何抓取十分重要。例如,如果多個(gè)物體聚集在一起,那么將其中一個(gè)分開(kāi)(稱(chēng)為“分割”)將使得抓取更容易,即使這樣做與成功抓取并無(wú)直接關(guān)聯(lián)。
分割示例
為了提高效率,我們需要采用脫策強(qiáng)化學(xué)習(xí),這種算法可以從數(shù)小時(shí)、數(shù)天或數(shù)周前收集的數(shù)據(jù)中學(xué)習(xí)。為了設(shè)計(jì)這樣一種可以利用從歷史互動(dòng)中獲得的大量不同經(jīng)驗(yàn)的脫策強(qiáng)化學(xué)習(xí)算法,我們將大規(guī)模分布式優(yōu)化與一個(gè)新的擬合深度 Q 學(xué)習(xí)算法(我們稱(chēng)之為 QT-Opt)相結(jié)合。arXiv 上提供了預(yù)印本。
QT-Opt 是一種分布式 Q 學(xué)習(xí)算法,支持連續(xù)動(dòng)作空間,非常適合解決機(jī)器人問(wèn)題。為了使用 QT-Opt,我們首先使用已收集的數(shù)據(jù)以完全離線(xiàn)的方式訓(xùn)練模型。此過(guò)程不需要運(yùn)行真正的機(jī)器人,因而更易于擴(kuò)展。然后,我們?cè)谡嬲臋C(jī)器人上部署并微調(diào)該模型,使用新收集的數(shù)據(jù)進(jìn)一步訓(xùn)練模型。通過(guò)運(yùn)行 QT-Opt,我們得以積累更多的離線(xiàn)數(shù)據(jù),這使得我們能夠訓(xùn)練出更好的模型,而這反過(guò)來(lái)又有利于收集更好的數(shù)據(jù),從而形成一個(gè)良性循環(huán)。
為了將這種方法應(yīng)用于機(jī)器人抓取,我們使用了 7 個(gè)現(xiàn)實(shí)世界的機(jī)器人,在 4 個(gè)月的時(shí)間里,機(jī)器人總共運(yùn)行了 800 個(gè)小時(shí)。為了引導(dǎo)收集過(guò)程,我們首先使用手動(dòng)設(shè)計(jì)的策略,成功率為 15-30%。在表現(xiàn)提升后,數(shù)據(jù)收集轉(zhuǎn)向?qū)W到的模型。策略利用相機(jī)圖像并返回手臂和抓手的移動(dòng)方式。離線(xiàn)數(shù)據(jù)包含對(duì) 1000 多種不同物體的抓取。
使用的一些訓(xùn)練物體
通過(guò)過(guò)去的研究,我們已經(jīng)發(fā)現(xiàn)在機(jī)器人之間共享經(jīng)驗(yàn)可以加快學(xué)習(xí)速度。我們將此訓(xùn)練和數(shù)據(jù)收集過(guò)程擴(kuò)展到 10 個(gè) GPU、7 個(gè)機(jī)器人和多個(gè) CPU,因此得以收集和處理包含超過(guò) 580,000 次抓取嘗試的大型數(shù)據(jù)集。在這個(gè)過(guò)程的最后,我們成功訓(xùn)練了一種抓取策略,此策略在現(xiàn)實(shí)世界機(jī)器人上運(yùn)行并且可以泛化到訓(xùn)練時(shí)未見(jiàn)過(guò)的各種具有挑戰(zhàn)性的物體。
七個(gè)機(jī)器人正在收集抓取數(shù)據(jù)
從量化角度來(lái)看,在關(guān)于以前未見(jiàn)過(guò)物體的 700 次抓取試驗(yàn)中,QT-Opt 方法的抓取成功率達(dá)到 96%。先前基于監(jiān)督式學(xué)習(xí)的抓取方法的成功率為 78%,相比之下,新方法將錯(cuò)誤率降低了五倍以上。
評(píng)估時(shí)使用的物體
為了使任務(wù)具有挑戰(zhàn)性,我們?cè)黾恿宋矬w尺寸、
紋理和形狀的多樣性
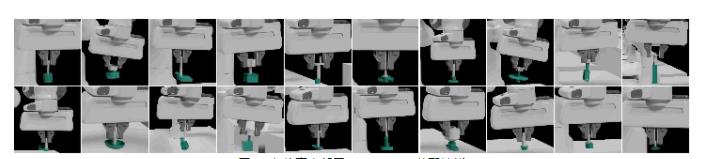
值得注意的是,策略展現(xiàn)出了標(biāo)準(zhǔn)機(jī)器人抓取系統(tǒng)中少見(jiàn)的各種閉環(huán)、反應(yīng)性行為:
? 當(dāng)面對(duì)一組無(wú)法一起拾起的聯(lián)鎖塊時(shí),策略先將一個(gè)塊與其他塊分開(kāi),然后再將它拾起。
? 當(dāng)面對(duì)難以抓取的物體時(shí),策略會(huì)推算出它應(yīng)該調(diào)整抓手位置并重新抓取,直到抓牢為止。
? 當(dāng)在一堆物體中抓取時(shí),策略會(huì)探測(cè)不同的物體,直到抓手緊緊握住一個(gè)物體時(shí)才會(huì)將它拾起。
? 當(dāng)我們故意將物體從抓手上弄掉以擾亂機(jī)器人時(shí)(訓(xùn)練期間未經(jīng)歷過(guò)這種情況),它會(huì)自動(dòng)重新調(diào)整抓手位置,進(jìn)行另一次嘗試。
最重要的是,這些行為都并非人為設(shè)計(jì)。這些行為基于 QT-Opt 的自監(jiān)督式訓(xùn)練自動(dòng)出現(xiàn),因?yàn)樗鼈兲岣吡四P偷拈L(zhǎng)期抓取成功率。
學(xué)到的行為示例
在左側(cè)的 GIF 中,策略針對(duì)移動(dòng)的球進(jìn)行更正
在右側(cè)的 GIF 中,策略在多次抓取嘗試后
成功拾起難以抓握的物體
此外,我們發(fā)現(xiàn) QT-Opt 使用較少的訓(xùn)練數(shù)據(jù)達(dá)到了較高的成功率,盡管收斂時(shí)間較長(zhǎng)。這對(duì)機(jī)器人技術(shù)來(lái)說(shuō)尤其令人興奮,因?yàn)椋祟I(lǐng)域的瓶頸通常是收集現(xiàn)實(shí)機(jī)器人數(shù)據(jù),而不是訓(xùn)練時(shí)間。將此策略與其他數(shù)據(jù)效率技術(shù)(例如我們之前關(guān)于抓取領(lǐng)域自適應(yīng)的研究)相結(jié)合,可以在機(jī)器人技術(shù)領(lǐng)域開(kāi)辟一些有趣
總體而言,QT-Opt 算法是一種通用的強(qiáng)化學(xué)習(xí)方法,在現(xiàn)實(shí)世界機(jī)器人上表現(xiàn)非常出色。除獎(jiǎng)勵(lì)定義外,QT-Opt 沒(méi)有任何特定于機(jī)器人抓取的限制。我們認(rèn)為這是向更通用的機(jī)器人學(xué)習(xí)算法邁出的重要一步,并期待看到其他適用的機(jī)器人任務(wù)。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29508瀏覽量
211632 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5555瀏覽量
122498
發(fā)布評(píng)論請(qǐng)先 登錄
詳細(xì)介紹機(jī)場(chǎng)智能指路機(jī)器人的工作原理
【「# ROS 2智能機(jī)器人開(kāi)發(fā)實(shí)踐」閱讀體驗(yàn)】視覺(jué)實(shí)現(xiàn)的基礎(chǔ)算法的應(yīng)用
AgiBot World Colosseo:構(gòu)建通用機(jī)器人智能的規(guī)模化數(shù)據(jù)平臺(tái)

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人的基礎(chǔ)模塊
NVIDIA技術(shù)推動(dòng)機(jī)器人仿真
開(kāi)源項(xiàng)目!能夠精確地行走、跳舞和執(zhí)行復(fù)雜動(dòng)作的機(jī)器人—Tillu
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】1.初步理解具身智能
《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+數(shù)據(jù)在具身人工智能中的價(jià)值
【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+初品的體驗(yàn)
《具身智能機(jī)器人系統(tǒng)》第1-6章閱讀心得之具身智能機(jī)器人系統(tǒng)背景知識(shí)與基礎(chǔ)模塊
通過(guò)多樣的幾何形狀來(lái)訓(xùn)練機(jī)器人從仿真到現(xiàn)實(shí)轉(zhuǎn)換的裝配技能
Al大模型機(jī)器人
NVIDIA發(fā)布幾項(xiàng)新功能來(lái)幫助機(jī)器人專(zhuān)家和工程師打造智能機(jī)器人






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論