") 基于鏡像構(gòu)建關(guān)于θ的函數(shù),過擬合和L2正則化
基于鏡像構(gòu)建關(guān)于θ的函數(shù),過擬合和L2正則化

編者按:如下圖所示,這是一個非常基礎(chǔ)的分類問題:空間中存在兩個高維聚類(兩簇藍(lán)點),它們被一個超平面分離(橙線)。其中兩個白色圓點表示兩個聚類的質(zhì)心,它們到超平面的歐氏距離決定了模型的性能,而橙色虛線正是它們垂直的方向。
在這類線性分類問題中,通過調(diào)整L2正則化的水平,我們能不斷調(diào)整這個垂直方向的角度。但是,你能解釋這是為什么嗎?

許多研究已經(jīng)證實,深層神經(jīng)網(wǎng)絡(luò)容易受對抗樣本影響。通過在圖像中加入一些細(xì)微擾動,分類模型會突然臉盲,開始指貓為狗、指男為女。如下圖所示,這是一個美國演員人臉分類器,輸入一張正常的Steve Carell圖像后,模型認(rèn)為照片是他本人的概率有0.95。但當(dāng)我們往他臉上稍微加了點料,他在模型眼里就成了女演員Zooey Deschanel。
這樣的結(jié)果令人憂心。首先,它挑戰(zhàn)了一個基礎(chǔ)共識,即新數(shù)據(jù)的良好泛化和模型對小擾動的穩(wěn)健性(魯棒性)是相互促進的,上圖讓這個說法站不住腳。其次,它會對現(xiàn)實應(yīng)用構(gòu)成潛在威脅,去年11月,MIT的研究人員曾把擾動添加到3D物品上,成功讓模型把海龜分類成槍支。鑒于這兩個原因,理解這種現(xiàn)象并提高神經(jīng)網(wǎng)絡(luò)的穩(wěn)健性已經(jīng)成為學(xué)界的一個重要研究目標(biāo)。
近年來,一些研究人員已經(jīng)探索了幾種方法,比如描述現(xiàn)象、提供理論分析和設(shè)計更強大的架構(gòu),對抗訓(xùn)練現(xiàn)在也已經(jīng)成了新的正則化技術(shù)。不幸的是,它們都沒能從根本上解決這個問題。面對這一困難,一種可行的思路是從最基礎(chǔ)的線性分類出發(fā),去逐步分解問題的復(fù)雜度。
玩具問題
在線性分類問題中,我們一般認(rèn)為對抗性擾動就是高維空間中的點積。對此,一種非常普遍的說法是:我們可以在高維問題中對輸入進行大量無限小的改變,從而使輸出發(fā)生巨變。但這種說法其實是有問題的。事實上,當(dāng)分類邊界靠近數(shù)據(jù)流形時,對抗樣本依然存在——換句話說,它獨立于圖像空間維度。
建模
讓我們從一個最小的玩具問題開始:一個二維圖像空間,其中每個圖像都是關(guān)于a和b的函數(shù)。
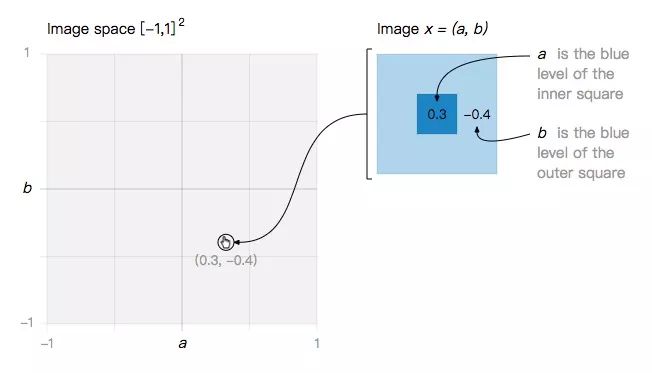
在這個簡單的圖像空間內(nèi),我們定義兩類圖像:

它們可以用無數(shù)個線性分類器進行分類,比如下圖的Lθ:
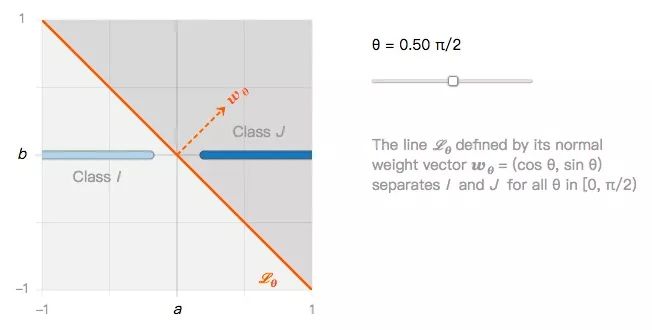
由此我們可以提出第一個問題:如果所有線性分類器都能很好地分類I類圖像和J類圖像,那它們是否也能同樣穩(wěn)健地分類圖像擾動?
投影和鏡像
假設(shè)x是I中的一張圖像,它距離J類圖像的最近距離是它到分類邊界的投影,也就是x到Lθ的垂直距離:

當(dāng)x和xp距離非常近時,我們把xp看做x的一個對抗樣本。聯(lián)系第一個問題,顯然,xp被分類為I的置信度非常低,并不穩(wěn)健。那么有沒有置信度高的對抗樣本呢?在下圖中,我們根據(jù)之前的距離找到了x在J中的鏡像圖像xm:

不難理解,x和xm到分類邊界的距離是一樣的,它們的分類置信度也應(yīng)該相同。
基于鏡像構(gòu)建關(guān)于θ的函數(shù)
讓我們回到之前的玩具問題。有了圖像x和它的鏡像圖像xm,我們可以據(jù)此構(gòu)建一個包含θ的函數(shù)。
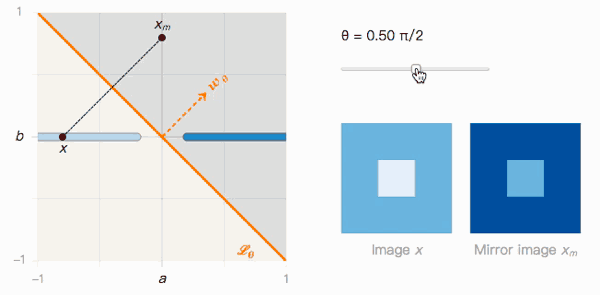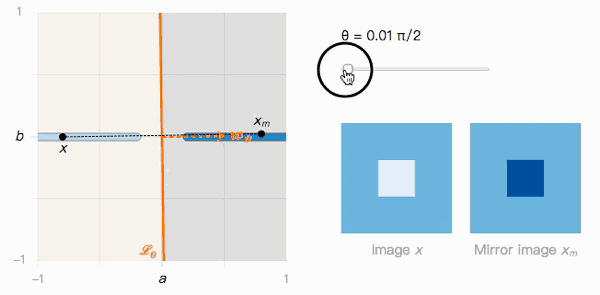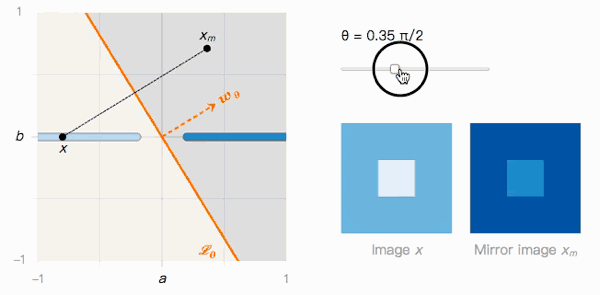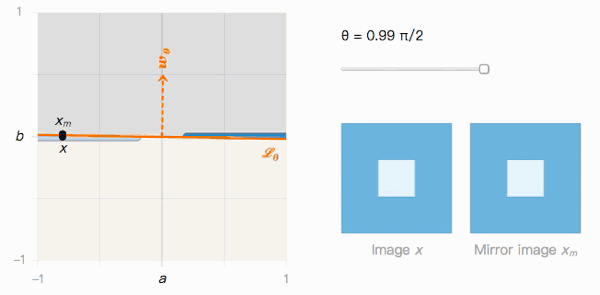
如上圖所示,x到xm的距離取決于分類邊界的夾角θ。我們來觀察一下它的兩個極值:

當(dāng)θ=0時,Lθ沒有受到對抗樣本影響。x被分類為I的置信度很高,xm被分類為J的置信度也很高,我們可以輕松區(qū)分兩者。
當(dāng)θ→π/2時,Lθ很明顯受到對抗樣本影響。x被分類為I的置信度很高,xm被分類為J的置信度也很高,但它們在視覺上幾乎不可區(qū)分。
這就帶來了第二個問題:如果Lθ傾斜的越厲害,對抗樣本存在的幾率就越高,那事實上究竟是什么在影響Lθ?
過擬合和L2正則化
對于這個問題,本文的假設(shè)是標(biāo)準(zhǔn)線性模型,比如SVM、邏輯回歸,是因為過擬合訓(xùn)練集中的噪聲數(shù)據(jù)才導(dǎo)致過度傾斜的。Huan Xu等人在論文Robustness and Regularization of Support Vector Machines中的理論結(jié)果支持了這一假設(shè),認(rèn)為分類器的穩(wěn)健性和正則化有一定關(guān)聯(lián)。
要證明這一點不難,我們來做個實驗:L2正則化是否可以削弱對抗樣本的影響?
設(shè)訓(xùn)練集中存在一個噪聲數(shù)據(jù)點p:
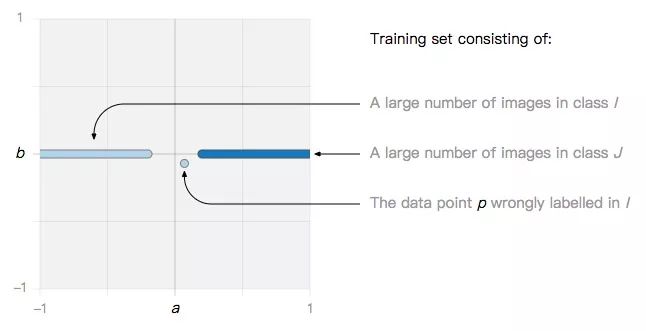
如果我們用的算法是SVM或邏輯回歸,最后可能會觀察到這兩種情況。
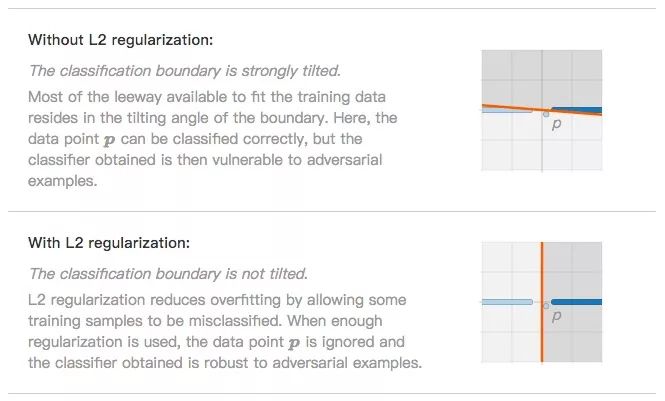
分類邊界嚴(yán)重傾斜(無L2正則化)。為了盡量擬合數(shù)據(jù)點,分類邊界會努力傾斜,讓模型最終能準(zhǔn)確分類p。這時分類器是過擬合的,也更易于受到對抗樣本影響。
分類邊界不傾斜(L2正則化)。L2正則化防止過擬合的思路是允許一小部分?jǐn)?shù)據(jù)被分類錯誤,如噪聲數(shù)據(jù)p。忽略它后,分類器在面對對抗樣本時更穩(wěn)健了。
看到這里,也許有人會有異議:上述數(shù)據(jù)是二維的,它和高維數(shù)據(jù)又有什么關(guān)系?
線性分類中的對抗樣本
之前我們得出了兩個結(jié)論:(1)分類邊界越靠近數(shù)據(jù)流形,越容易出現(xiàn)對抗樣本;(2)L2正則化可以控制邊界的傾斜角度。雖然都是基于二維圖像空間提出的,但對于一般情況,它們實際上都是成立的。
縮放損失函數(shù)
讓我們從最簡單的開始。L2正則化就是在損失函數(shù)后再加一個正則化項,不同于L1把權(quán)重往0靠,L2正則化的權(quán)重向量是不斷下降的,因此它也被稱為權(quán)重衰減。
建模
設(shè)I和J為高維圖像空間Rd中的兩類圖像,C為線性分類器輸出的超平面邊界,它和權(quán)重向量w和偏置項b有關(guān)。x是Rd中的一幅圖,則x到C的原始得分為:
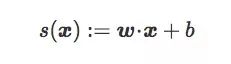
這個原始得分其實是x關(guān)于C的符號距離(signed distance,帶正負(fù)號):
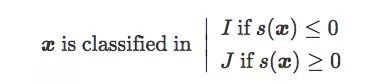
設(shè)存在一個包含n對(x,y)的訓(xùn)練集T,其中x是圖像樣本,當(dāng)x∈I時,y=-1;當(dāng)x∈J時,y=1。下面是T的三種分布:

分類器C的期望風(fēng)險R(w,b),就是對訓(xùn)練集T的平均懲罰:
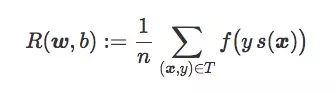
通常情況下,我們訓(xùn)練線性分類器時會用合適的損失函數(shù)f找到權(quán)重向量w和偏置項b,使R(w,b)最小。在一般二元分類問題中,下面是三個值得關(guān)注的損失函數(shù):
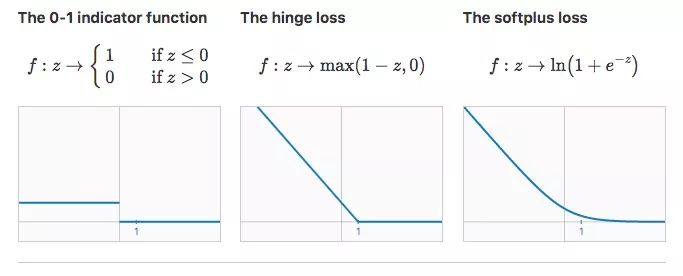
如上圖所示,對于第一個損失函數(shù),分類器的期望風(fēng)險就是它的分類錯誤率。從某種意義上來說,這個損失函數(shù)是最理想的,因為我們只需最小化誤差就能達(dá)成目標(biāo)。但它的缺點是導(dǎo)數(shù)始終為0,我們不能在這個基礎(chǔ)上用梯度下降。
事實上,上述問題現(xiàn)在已經(jīng)被解決了,一些線性回歸模型使用改進版損失函數(shù),比如SVM的hinge loss和邏輯回歸的softplus loss。它們不再繼續(xù)在分類錯誤數(shù)據(jù)上使用固定懲罰項,而是用了一個嚴(yán)格遞減的懲罰項。作為代價,這些損失函數(shù)也會給正確分類的數(shù)據(jù)帶去副作用,但最終能保證找出一個較為準(zhǔn)確的分類邊界。
縮放參數(shù)‖w‖
之前介紹符號距離s(x)時,我們沒有詳細(xì)說明它的縮放參數(shù)w。如果d(x)是x到C的歐氏距離,我們有:
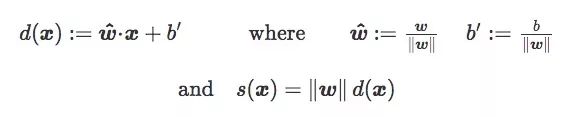
因此,‖w‖也可以被看作損失函數(shù)的縮放參數(shù):

也就是:f‖w‖:z→f(‖w‖×z) 。
可以發(fā)現(xiàn),這個縮放對之前提到的第一個損失函數(shù)沒有影響,但對hinge loss和softplus loss卻影響劇烈。

值得注意的是,對于縮放參數(shù)的極值,后兩個損失函數(shù)變化一致。

更確切地說,兩種損失函數(shù)都滿足:
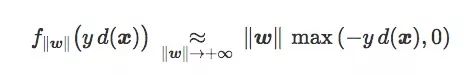
方便起見,我們將錯誤分類的數(shù)據(jù)定義為:

所以期望風(fēng)險可以被改寫成:

這個表達(dá)式包含了一個我們稱之為“誤差距離”的概念:

它是正的,可以解釋為每個訓(xùn)練樣本被C錯誤分類的平均距離(對正確分類數(shù)據(jù)的貢獻(xiàn)為零)。它與訓(xùn)練誤差有關(guān),但不完全等同。
最后,我們可以得到:
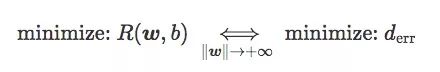
換句話說,當(dāng)‖w‖足夠大時,最小化hinge loss和softplus loss的期望風(fēng)險就等于最小化誤差距離,也就是最小化訓(xùn)練集上的錯誤率。
小結(jié)
綜上所述,通過在損失函數(shù)后加上正則化項,我們能控制‖w‖的值,從而輸出正則化的損失。

一個較小的正則化參數(shù)λ會讓‖w‖失控增大,一個較大的λ會讓‖w‖縮小。
總之,線性分類(SVM和邏輯回歸)中使用的兩個標(biāo)準(zhǔn)模型在兩個目標(biāo)之間取得平衡:它們在正則化參數(shù)低時最小化誤差距離,并且在正則化系數(shù)高時最大化對抗距離。
對抗距離和傾斜角度
看到這里,我們又接觸了一個新詞——“對抗距離”——對抗性擾動的穩(wěn)健性的度量。和之前二維圖像空間的例子一樣,它可以表示為包含單個參數(shù)的函數(shù),這個參數(shù)即分類邊界和最近的質(zhì)心分類器之間的角度。
對于訓(xùn)練集T,如果我們按圖像類別I和J把它分成TI和TJ,我們可以得到:
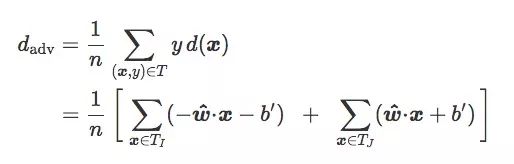
如果TI和TJ是均等的(n=2nI=2nJ):
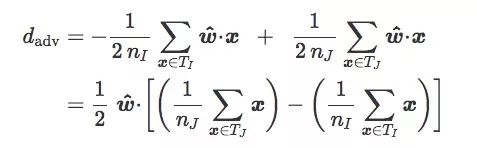
設(shè)TI和TJ的質(zhì)心分別是i和j:

現(xiàn)在有一個離分類邊界最近的質(zhì)心分類器,它的法向量是z^=(j?i)/‖j?i‖:
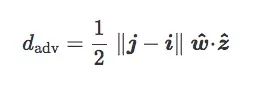
最后,我們將包含w^和z^的平面稱為C的傾斜平面,我們稱之為w^和z^之間的夾角θ為C的傾斜角度:

這個等式的幾何含義如下圖所示:

綜合以上推算,在給定訓(xùn)練集T上,如果兩個質(zhì)心‖j?i‖之間的距離是個固定值,那對抗距離dadv僅取決于傾斜角θ。通俗地講:
當(dāng)θ=0時,對抗距離最大,對抗樣本影響最小;
當(dāng)θ→π/2時,對抗距離最小,對抗樣本對分類器的影響最大。
最后的話
盡管對抗樣本已經(jīng)被研究了很多年,盡管它在理論和實踐中都對機器學(xué)習(xí)領(lǐng)域具有重要意義,但學(xué)界對它的研究還非常有限,它對很多人來說還是個迷。這篇文章給出了線性模型下對抗樣本的生成情況,希望能給對這方面感興趣的新人提供一定見解。
可惜的是,現(xiàn)實并沒有文章描述的這么簡單,隨著數(shù)據(jù)集變大、神經(jīng)網(wǎng)絡(luò)不斷加深,對抗樣本也正變得越來越復(fù)雜。根據(jù)我們的經(jīng)驗,模型包含的非線性因素越多,權(quán)重衰減似乎就越有用。這個發(fā)現(xiàn)可能只是淺層次的,但更深層次的內(nèi)容將交給不斷涌現(xiàn)的新人來解決。可以肯定的一點是,如果要對這個困難給出一個令人信服的解決方案,我們需要在深度學(xué)習(xí)中見證一種新的革命性觀念的誕生。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103543 -
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41235 -
分類器
+關(guān)注
關(guān)注
0文章
153瀏覽量
13449
原文標(biāo)題:L2正則化視角下的對抗樣本
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)中避免過擬合5種方法介紹
關(guān)于labview擬合函數(shù)再利用問題
Matlab數(shù)據(jù)擬合基礎(chǔ)函數(shù)的使用
過擬合的概念和用幾種用于解決過擬合問題的正則化方法

【連載】深度學(xué)習(xí)筆記4:深度神經(jīng)網(wǎng)絡(luò)的正則化
【連載】深度學(xué)習(xí)筆記5:正則化與dropout
深度學(xué)習(xí)筆記5:正則化與dropout
欠擬合和過擬合是什么?解決方法總結(jié)
詳解機器學(xué)習(xí)和深度學(xué)習(xí)常見的正則化
權(quán)值衰減和L2正則化傻傻分不清楚?本文來教會你如何分清
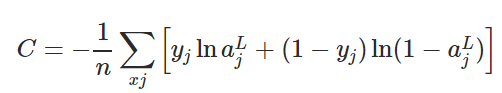
權(quán)值衰減和L2正則化傻傻分不清楚?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論