 以預測葡萄酒品質作為例子,帶你步入機器學習的大門
以預測葡萄酒品質作為例子,帶你步入機器學習的大門
編者按:Udacity機器學習、深度學習導師Ashwin Hariharan以預測葡萄酒品質作為例子,帶你步入機器學習的大門。
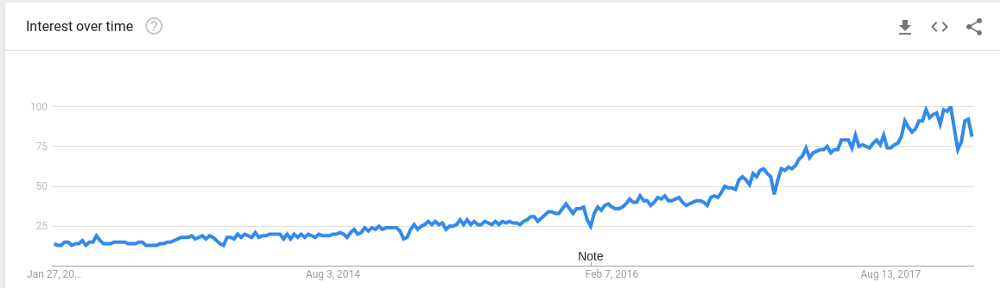
機器學習(ML)是人工智能的一個子領域。它賦予計算機學習的能力,而無需顯式地編程。從搜索趨勢來看,這幾年機器學習的流行度和需求明顯上漲。
這篇機器學習入門教程是我寫的上一篇數據科學教程的姊妹篇。上一篇展示了如何使用數據科學來理解葡萄酒的屬性。如果你還沒有讀過上一篇,推薦首先閱讀一下,你將了解數據科學大概是怎么回事。
什么是機器學習?
人類通過過往的經驗學習。利用眼、耳、觸等感官輸入從周圍獲得數據。我們接著以許多有趣、有意義的方式使用這些數據。最常見的,我們使用它對未來做出精確的預測。換句話說,我們學習。
例如,今年的這個時候會下雨嗎?如果你忘記了女友的生日,她會發瘋嗎?紅燈時應該停下嗎?你應該投資某處不動產嗎?Jon Snow在《權力的游戲》的下一季存活的概率?為了回答這些問題,你需要過去的數據。
另一方面,傳統上計算機不像我們一樣使用數據。它們需要一組明確的指令(算法)以供遵循。
現在問題來了——計算機可以像人類一樣從過去的經驗(數據)中學習嗎?是的——你可以賦予它們學習和預測未來事件的能力,而無需顯式地編程。從自動駕駛到搜索行星,機器學習的應用場景廣闊無垠。
另外,我讀過一篇很棒的解釋數據科學、機器學習、人工智能區別的文章。這是一篇比較詳盡全面的文章,所以我在這里總結一下:
數據科學產生洞見
機器學習產生預測
人工智能產生行動
這些領域間有許多交叉重疊,因此這些術語經常被不加區別地使用。
融資時,是AI。招聘時,是ML。實現時,是線性回歸。調試時,是printf()
在Netflix,機器學習用來從用戶的行為數據中學習,顯示推薦。Google搜索顯示和你有關的結果——同樣,這需要使用很多ML技術不斷學習場景背后的數據。在數據科學和ML地帶,數據就是黃金。如果Tyrion Lannister面對ML和AI的世界,他可能會說:
一家公司需要數據,就像劍需要磨刀石才能保持鋒利。
現在我們理解了什么是機器學習,是時候深入了。
誰應該閱讀這篇教程:
如果你想要入門機器學習,卻因為發現數學,統計學,從頭實現算法太復雜,本文很適合你。
在你學習的某個階段,你將需要進一步深入——你不可能總是回避數學!我希望你讀完本文后,能有動機探索這一領域各個深度的問題。
如果你有Python編程基礎,并閱讀過上一篇文章,你可以開始了。
讓我們開始!
我們將學習構建一個基于葡萄酒屬性預測葡萄酒品質的機器學習模型。讀完本文后,你將理解:
不同的ML算法和技術
如何訓練和創建分類器
構建ML模型的常見錯誤,以及如何擺脫它們
如何分析和解釋模型的表現
機器學習類型
監督學習(本教程將討論這一主題)
顧名思義,監督學習需要人類來“監督”,告訴計算機正確答案。我們傳入包含許多特征的訓練數據,并給出正確答案。
為了類比,想象計算機是一個如同一張白紙的小孩。他什么也不知道。
現在,你如何教會Jon Snow貓和狗的區別?答案很直觀——你帶它出去散步,當你看到一只貓時,你指著貓說:“這是貓。”你繼續走,可能會看到一條狗,所以你指著狗說:“這是狗。”隨著時間的推移,你不斷展示狗和貓,小孩會學習兩者的區別。
當然,你總是可以給Jon看很多貓狗圖片,而不用外出散步。Instagram是你的救星!:P
就我們的葡萄酒數據集而言,我們的機器學習模型將學習葡萄酒的品質(quality)和剩余屬性的關系。換句話說,它將學習識別特征和目標(品質)間的模式。
無監督學習
這里我們不給計算機需要預測的“目標”標簽。相反,我們讓計算機自行發現模式,接著選擇最說得通的模式。這一技術很有必要,因為經常我們甚至不知道要在數據中找出什么。
強化學習
強化學習用來訓練智能體的“表現”,以及學習給定場景下的最佳行動,基于獎勵和反饋。這和AI有很多交叉。
除此之外,還有其他類型的ML,比如半監督學習、聚類。
監督學習可以解決什么問題?
總體來說,監督學習用于解決兩類問題:
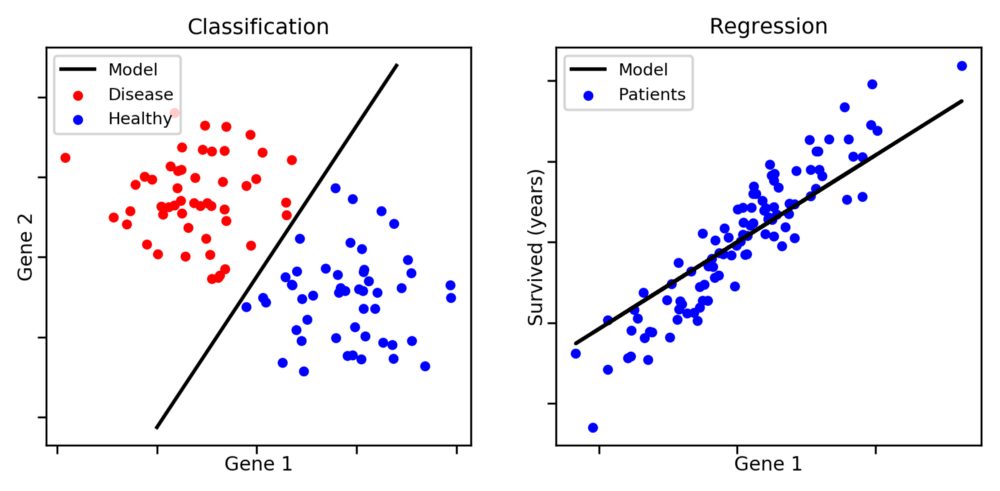
圖片來源:aldro61.github.io
分類:當你需要將特定觀測歸類為一組。在上圖中,給定一個數據點,你需要分類它是藍點還是紅點。其他例子包括,識別垃圾郵件,分配資訊的類別——比如運動、天氣、科學。
回歸:用于預測連續值。例如,預測不動產價格。
注意,分類問題不一定是二元的——我們可以有兩個分類以上的問題。
另一方面,判定癌癥患者的期望壽命會是一個回歸問題。在這一情形下,我們的模型將需要找到一條能夠很好地概括大多數數據點的直線或曲線。
一些回歸問題也可以被轉換為分類問題。此外,某些特定種類的問題可能既是分類問題,又是回歸問題。
機器學習的機制
大部分監督學習問題分為三步:
第一步:預處理、轉換、分割數據
第一步是分析數據,并為訓練作準備。我們觀察數據的傾向性、分布、特征的平均數和中位數等統計數據。上一篇教程介紹了這些。
之后我們可以預處理數據,并在必要時應用特征轉換。
接著,我們將數據分為兩部分——較大的一部分用作訓練,較小的一部分用作測試。分類器將使用訓練數據集進行“學習”。我們需要單獨的數據來測試和驗證,這樣我們可以看到我們的模型在未見數據上工作得有多好。
第二步:訓練
接著我們創建模型。我們通過創建函數或“模型”,并使用數據訓練它做到這一點。函數將使用我們選擇的算法,使用我們的數據訓練自身,并理解模式(也就是學習)。注意,分類器表現得多好取決于它的老師——我們需要以正確的方式訓練它。

憂心忡忡的父母:如果你所有的朋友跳橋了,你會跟隨他們嗎?機器學習算法:會。
第三步:測試和驗證
訓練好模型后,我們可以給它新的未見數據,而模型將給出輸出或預測。
第四步:超參數調整
最后,我們將嘗試改善算法的表現。
現在,在我們深入機器學習算法之前,讓我們了解下分類或回歸問題中可能出現的誤差。
偏離導致的誤差——精確度和欠擬合
當模型具有足夠多的數據但復雜度不足以捕捉其中的關系時,偏離出現了。模型持續、系統地錯誤表示數據,導致預測的低精確度。這被稱為欠擬合。
簡單而言,當我們擁有一個貧乏的模型時,偏離出現了。例如,當我們試圖基于《權力的游戲》角色的身高和服飾識別他們是貴族還是農夫時,如果我們的模型只能根據身高劃分和分類角色,那么它會把Tyrion Lannister(矮人)標記為農夫——這大錯特錯!
另一個例子,當我們想要通過顏色和形狀分類目標(例如復活節彩蛋)時,如果我們的模型只能根據顏色劃分和分類目標,它將持續地錯誤標記未來的目標——例如將五顏六色的彩虹標記為復活節彩蛋。
就我們的葡萄酒數據集而言,如果我們的機器學習分類器只“喝”一種葡萄酒,它會欠擬合。:P
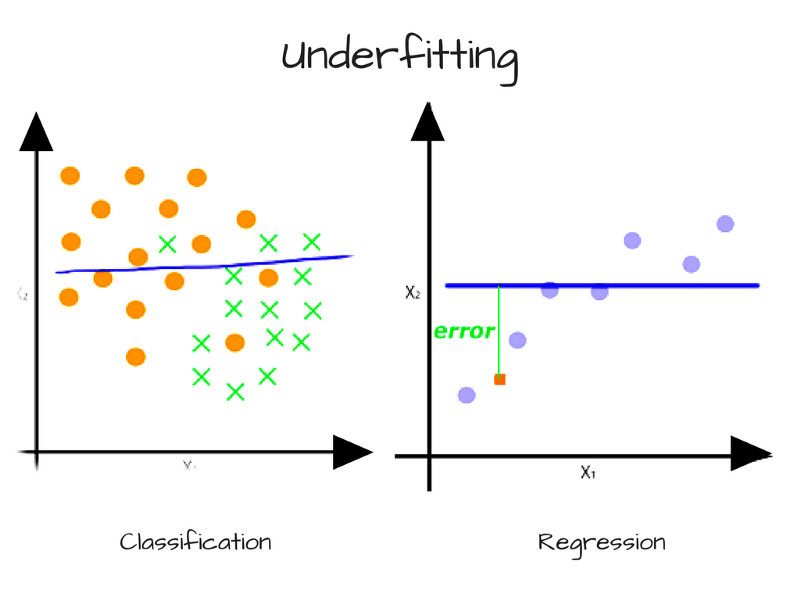
另一個例子是本質上為多項式的連續數據,而模型只能表示線性關系。在這一情形下,我們傳給模型再多的數據也無濟于事,因為模型無法表示內在的關系。為了克服偏離導致的誤差,我們需要更復雜的模型。
方差導致的誤差——準確率和欠擬合
方差是衡量模型對訓練數據的子集有多“敏感”的測度。
訓練模型時,我們通常使用有限數量的樣本。如果我們使用隨機選擇的數據子集反復訓練模型,我們會期望它的預測會因為特定樣本的不同而不同。

出現一些方差是正常的,但過多方差意味著模型無法將其預測推廣到更大的數據集。在這一場景下,模型在已見數據上表現得很精確,但在未見數據點上表現得很糟糕。對訓練集高度敏感也稱為過擬合,一般在模型過于復雜時出現。
通常我們可以通過訓練更多數據降低模型預測的方差,提升預測的準確率。如果無法獲得更多數據,我們也可以通過限制模型的復雜度控制方差。

對于程序員而言,挑戰在于使用能夠解決問題的最優算法,避免高偏離或高方差,因為:
增加偏離將減少方差
增加方差將減少偏離
這通常被稱為偏離和方差的折衷。關于這點的細節,可以參考scott.fortmann-roe.com/docs/BiasVariance.html
和傳統編程不同,當你試圖找到機器學習和深度學習問題的最佳模型時,常常需要涉及大量基于試錯的方法。
現在,你需要對可以用來訓練模型的一些算法有個概念。我不會深入數學或底層的實現細節,但應該足以讓你觀其大略。
一些最常用的機器學習算法:
1. 高斯樸素貝葉斯
這個方法在20世紀50年代就出現了。它屬于概率分類器或條件概率算法家族,假定特征之間相互獨立。對識別垃圾郵件和分類資訊之類的分類問題而言,樸素貝葉斯很有效。
2. 決策樹
基本上這是一個類樹的數據結構,作用和流程圖差不多。決策樹是一種使用類樹的數據結構建模決策和可能結果的分類算法。算法工作的方式是:
將數據集的最佳屬性作為樹的根節點。
節點,或者說分岔處,經常被稱為“決策節點”。它通常表示一個測試或條件(比如是多云還是晴天)。
分岔表示每個決策的輸出。
葉節點表示最終輸出,即標簽(在分類問題中),或離散值(在回歸問題中)。
3. 隨機森林
單獨使用時,決策樹傾向于過擬合。而隨機森林有助于糾正可能出現的過擬合。隨機森林使用多棵決策樹——使用大量不同的決策樹(預測不同),結合這些樹的結果以得到最終輸出。
隨機森林使用一種稱為bagging的集成算法,這種算法有助于減少方差和過擬合。
給定訓練集X = x1, …, xn,相應標簽/輸出Y = y1, …, yn,bagging反復(B次)選擇訓練集中的一個隨機樣本(有放回)。
基于這些樣本訓練決策樹。
通過分類樹的多數投票做出最終分類。
除此之外,還有其他機器學習算法,比如支持向量機,集成方法和很多非監督學習方法。
現在,是時候開始我們的訓練了!
首先,我們需要預備我們的數據
在機器學習的游戲中,你回歸,或者你分類
在這篇教程中,我們將把回歸問題轉換為分類問題。所有評分低于5分的葡萄酒分類為0(差),評分為5分或6分的葡萄酒分類為1(一般),7分以上的葡萄酒分類為2(好)。
# 定義類別的分割點。
bins = [1,4,6,10]
# 定義類別
quality_labels=[0,1,2]
data['quality_categorical'] = pd.cut(data['quality'], bins=bins, labels=quality_labels, include_lowest=True)
# 顯示頭兩行
display(data.head(n=2))
# 分離數據為特征和目標標簽
quality_raw = data['quality_categorical']
features_raw = data.drop(['quality', 'quality_categorical'], axis = 1)

如你所見,我們有了一個新的列quality_categorical(品質類別),基于之前選擇的區間分類品質評分。quality_categorical列將作為目標值,而其他列作為特征。
接著,創建數據的訓練子集和測試子集:
from sklearn.model_selection import train_test_split
# 將數據分為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(features_raw,
quality_raw,
test_size = 0.2,
random_state = 0)
# 顯示分離的結果
print("Training set has {} samples.".format(X_train.shape[0]))
print("Testing set has {} samples.".format(X_test.shape[0]))
Trainingset has 1279 samples.
Testingset has 320 samples.
在上面的代碼中,我們使用了sklearn的train_test_split方法。該方法接受特征數據(X)和目標標簽(y)作為輸入。它打亂數據集,并將其分為兩部分——80%用于訓練,剩余20%用于測試。
接著,我們將使用一種算法訓練,并評估其表現
我們需要一個函數,接受我們選擇的算法、訓練數據集、測試數據集。函數將運行訓練,接著使用一些表現測度評估算法的表現。
最終我們編寫了一個可以使用任意3種選定的算法的函數,并為每種算法進行訓練。然后匯總結果,并加以可視化。
# 從sklearn導入任意3種監督學習分類模型
from sklearn.naive_bayes importGaussianNB
from sklearn.tree importDecisionTreeClassifier
from sklearn.ensemble importRandomForestClassifier
#from sklearn.linear_model import LogisticRegression
# 初始化3個模型
clf_A = GaussianNB()
clf_B = DecisionTreeClassifier(max_depth=None, random_state=None)
clf_C = RandomForestClassifier(max_depth=None, random_state=None)
# 計算訓練集1%、10%、100%樣本數目
samples_100 = len(y_train)
samples_10 = int(len(y_train)*10/100)
samples_1 = int(len(y_train)*1/100)
# 收集結果
results = {}
for clf in [clf_A, clf_B, clf_C]:
clf_name = clf.__class__.__name__
results[clf_name] = {}
for i, samples in enumerate([samples_1, samples_10, samples_100]):
results[clf_name][i] =
train_predict_evaluate(clf, samples, X_train, y_train, X_test, y_test)
#print(results)
# 可視化選定的3種學習模型的測度
vs.visualize_classification_performance(results)
輸出將類似:

上圖第一行為訓練數據上的表現,第二行為測試數據上的表現。這些表現測度意味著什么?請繼續閱讀……
分類問題的表現測度
精確度
最簡單也最常用的測度,正確預測除以數據點總數。
何時精確度不是一個良好的表現指標?
有時,數據集中的類別分布會有很嚴重的傾向性,也就是說,某些分類有很多數據點,而另一些分類的數據點要少得多。讓我們看一個例子。
在一個由100封郵件組成的數據集中,10封是垃圾郵件,其他90封不是。這意味者數據集有傾向性,并不是均勻分布的。
現在,想象一下,我們訓練一個預測是否是垃圾郵件的分類器。它的表現是90%精確率。聽起來很不錯?并非如此。
分類器可以標記或預測所有100封郵件為“非垃圾郵件”,而仍然能得到90%的精確度!但這個分類器完全無用,因為它把所有郵件都分類為非垃圾郵件。
所以,精確度并不總是一個良好的指標。在特定情況下,其他測度能幫助我們更好地評估模型:
準確率
準確率告訴我們,分類為垃圾郵件的郵件中有多少確實是垃圾郵件,即真陽性/(真陽性 + 假陽性)
召回
召回或靈敏度告訴我們確實是垃圾郵件的郵件中有多少被分類為垃圾郵件,即真陽性/(真陽性 + 假陰性)
我們之前提到的具有90%精確度的分類器,它的準確率和召回是多少呢?讓我們算一下——它的真陽性是0,假陽性是0,假陰性是10。根據前面提到的公式,我們的分類器的準確率和召回均為0——相當反常的評分!現在看起來不那么好了,不是嗎?
F1評分
F1為準確率(precision)和召回(recall)的調和平均數:
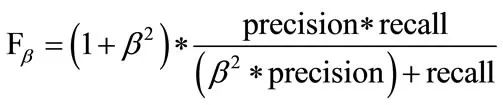
就F1而言,β = 1. 上式是F評分的公式,β值越大,越強調準確率。
現在,讓我們回顧下我們的ML算法的表現:

這些結果表明,高斯樸素貝葉斯的表現不像決策樹和隨機森林那么好。
你覺得為什么高斯樸素貝葉斯的表現不佳?(提示:你可以往上滾動,重新閱讀高斯樸素貝葉斯的解釋!)
特征重要性
scikit-learn提供的一些分類算法,有一個特征重要性屬性,可以讓你查看基于選定算法的每個特征的重要性。
比如,scikit-learn中的隨機森林分類器帶.feature_importance_:
# 導入一個帶`.feature_importance_`的模型
model = RandomForestClassifier(max_depth=None, random_state=None)
# 訓練模型
model = model.fit(X_train, y_train)
# 提取特征重要性
importances = model.feature_importances_
print(X_train.columns)
print(importances)
# 繪圖
vs.feature_plot(importances, X_train, y_train)
結果如下:
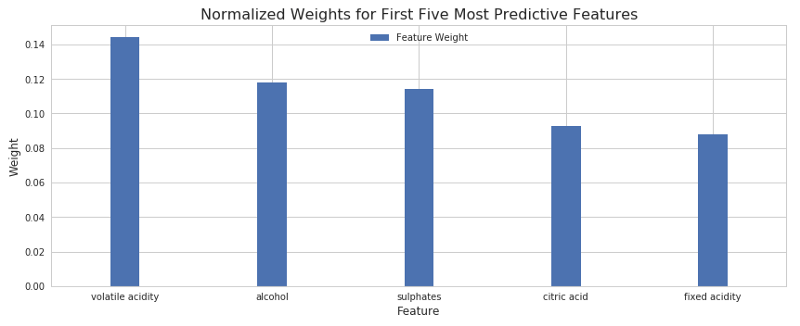
上圖顯示了5個最重要的特征。酒精含量和揮發性酸水平看起來是最具影響力的因子,接著是硫酸鹽、檸檬酸、固定酸度。
超參數調整和優化
你也許已經注意到了,機器學習和數據科學有關。像任何科學一樣,它從一些先驗觀測開始。接著你做出假說,運行一些試驗,然后分析它們多大程度上重現了之前的觀測。這被稱為科學方法,其實這和工程過程也很相似。
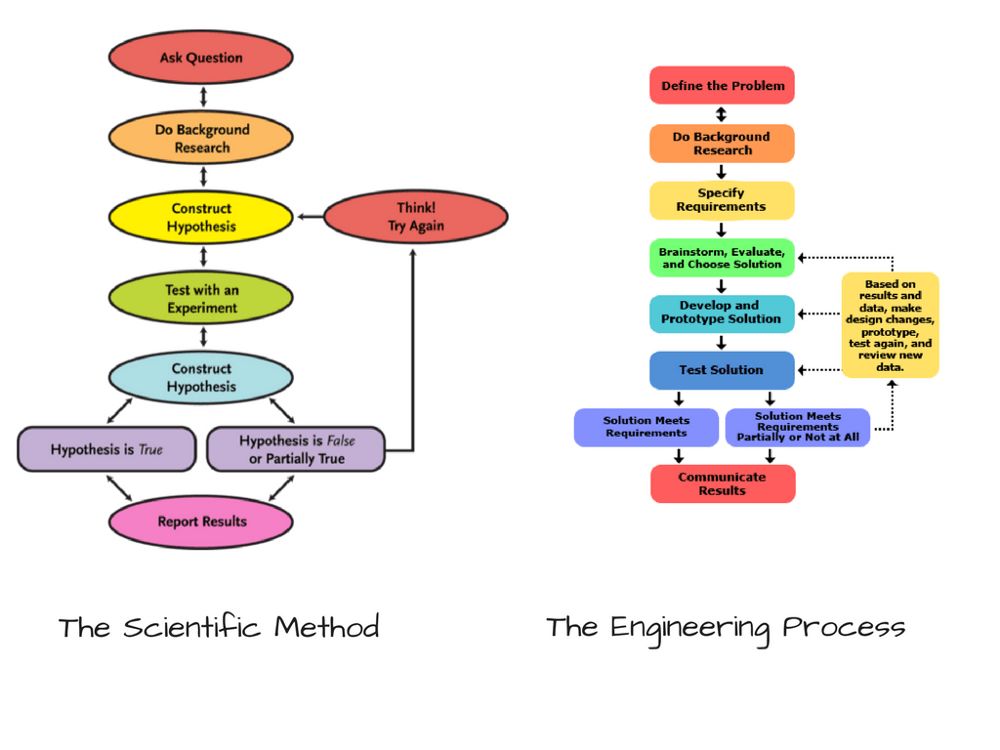
假說可以被認為是“假定”。創建分類器的時候,我們首先假設一些算法,在我們看來,這些算法的效果應該不錯。但我們的假說也可能不對。常常,我們需要調整我們的假說,看看它們能不能做得更好。
當選擇機器學習模型時,我們做了一些關于它們的超參數的假定。超參數是特殊類型的配置變量,其值無法通過數據集直接計算。數據科學家或機器學習工程師需要通過試驗找出這些超參數的最佳值。這一過程稱為超參數調整。
現在,就隨機森林算法而言,哪些可能是它的超參數?
森林中決策樹的數目
尋找樹的最佳分岔時考慮的特征數
樹的最大深度,即根節點至葉節點的最長路徑
就這些超參數而言,我們的隨機森林分類器使用scikit-learn的默認值。
scikit-learn提供了一個非常方便的API,讓我們可以在“網格”中指定超參數的不同值,然后通過scikit-learn的GridSearchCV API使用這些超參數的可能組合訓練并進行交叉驗證,給出最優配置。這樣我們就不用手工運行這么多迭代。
from sklearn.model_selection importGridSearchCV
from sklean.metrics import make_scorer
clf = RandomForestClassifier(max_depth=None, random_state=None)
# 創建打算調整的參數列表,有必要時使用字典。
"""
n_estimators: 森林中的決策樹數量
max_features: 尋找最佳分割時考慮的特征數量
max_depth: 樹的最大深度
"""
parameters = {'n_estimators': [10, 20, 30], 'max_features': [3, 4, 5, None], 'max_depth': [5, 6, 7, None]}
# 創建F0.5評分
scorer = make_scorer(fbeta_score, bate=0.5, average="micor")
# 進行網格搜索
grid_obj = GridSearchCV(clf, parameters, scoring=scorer)
# 找到最優參數
grid_fit = grid.obj.fit(X_train, y_train)
# 得到最佳逼近
best_clf = grid_fit.best_estimator_
# 分別使用未優化超參數的模型和優化了超參數的模型進行預測:
predictions = (clf.fit(X_train, y_train)).predict(X_test)
best_predicotins = best_clf.predict(X_test)
# 報告之前和之后的評分
print("Unpotimized model ------")
print("Accuracy score on testing data: {:.p6}".format(accuracy_score(y_test, predictions)))
print("F-score on testing data: {:.4f}".format(fbeta_score(y_test,predictions, beta=0.5, average="micro")))
好了。你可以看到,我們模型的表現略有提升。

使用模型進行預測
最終,給我們的模型多個特征的一組值,看看它的預測:
恭喜!你成功搭建了你自己的機器學習分類器,該分類器可以預測好酒和烈酒。
思考題
你的分類器更適合檢測一般的葡萄酒,還是更適合檢測好的葡萄酒?你認為可能的原因是什么?
你會向釀酒廠推薦你的分類器嗎?為什么?
如果使用回歸技術,而不是分類技術,模型的表現將如何?
接下來呢?
嘗試在白葡萄酒數據集上預測酒的品質
去Kaggle逛逛,看看不同的數據集,嘗試下你覺得有趣的數據集
編寫一個使用你的機器學習模型的API服務,然后創建一個web應用/移動應用
-
人工智能
+關注
關注
1804文章
48737瀏覽量
246669 -
機器學習
+關注
關注
66文章
8492瀏覽量
134122 -
數據集
+關注
關注
4文章
1223瀏覽量
25283
原文標題:如何使用機器學習預測葡萄酒品質
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
PSoC Creator在線或W / W /葡萄酒問題
自回歸滯后模型進行多變量時間序列預測案例分享
酒鏈幣數字資產軟件開發平臺
酒鏈幣場景部暑軟件開發平臺
區塊鏈技術給葡萄酒拍賣業務帶來了哪些優勢?
通過RFID技術對藏酒實施智能管理 海爾智慧酒柜為消費者提供貼心的服務
改進粒子群優化神經網絡的葡萄酒質量識別





 工商網監
工商網監
評論