") 一份指南,鼓勵大家在家訓練自動駕駛系統(tǒng)的感知能力
一份指南,鼓勵大家在家訓練自動駕駛系統(tǒng)的感知能力
自動駕駛汽車依靠攝像頭、激光雷達以及雷達等等傳感器來感知周圍的變化,感知能力對自動駕駛來說非常重要。本文是一份指南,鼓勵大家在家訓練自動駕駛系統(tǒng)的感知能力。
△神秘的視覺
感知,大概就是感受到周遭正在發(fā)生什么的一種能力。這項技能對自動駕駛來說太重要了。
自動駕駛汽車依靠攝像頭、激光雷達以及雷達等等傳感器來感知周圍的變化。
一位名叫凱爾 (Kyle Stewart-Frantz) 的大叔,準備了一份指南,鼓勵大家在家訓練自動駕駛系統(tǒng)的感知能力。
當然,這個手冊并不是他出于愛好寫出來的,是隨著Lyft和Udacity聯(lián)合發(fā)起的感知挑戰(zhàn)賽(Lyft Perception Challenge),而生的。
比賽考驗的就是系統(tǒng)能不能準確地感受到,可以行駛的路面在哪里,周圍的汽車在哪里。
挑戰(zhàn)賽中,能夠倚仗的所有數(shù)據(jù),都來自車載的前向攝像頭。
攝像頭不存在?
這里的“攝像頭數(shù)據(jù)”并非真實攝像頭記錄的影像,而是一個名為CARLA的模擬器生成的圖景。
畢竟,自動駕駛汽車的軟件開發(fā)大多是在模擬器中進行的,那里快速的原型設計和迭代,比在現(xiàn)實世界里使用真實硬件要高效得多。
那么,來看一下CARLA給的數(shù)據(jù)長什么樣——
左邊是模擬攝像頭捕捉的畫面,右邊則是與之對應的、標記好的圖像。
用這樣的數(shù)據(jù)來訓練算法,讓AI能夠在從未見過的新鮮圖像里,判斷出哪些像素對應的是道路,哪些部分對應的是其他車輛。
這就是挑戰(zhàn)賽的目標。
車前蓋太搶鏡?
要完成比賽任務,自然會想到語義分割。用這種方式來訓練神經(jīng)網(wǎng)絡,成熟后的AI便可以判斷每個像素里包含的物體了。
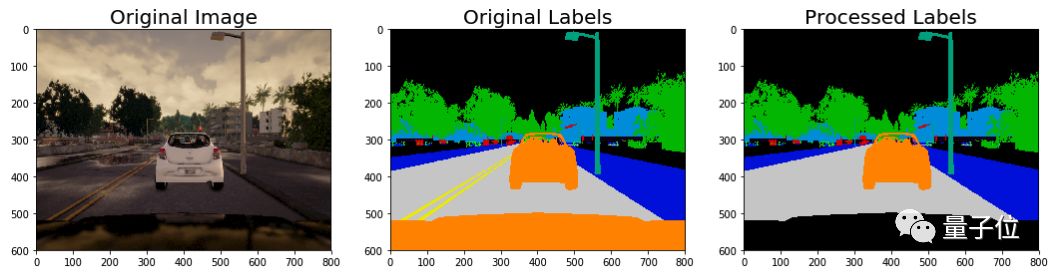
第一步,是對標記好的圖像做預處理。比如,因為設定是“車載前向攝像頭”拍下的畫面,每一幅圖像都會出現(xiàn)車前蓋,可是如果這樣就把所有圖像判定為“車”,就不太好了。
所以要把顯示車前蓋的那些像素的值設為零,或者貼上其他的“非車”標簽。
第二步,車道標識和道路的值是不一樣的,但我們希望這些標識,可以被識別為路面的一部分。
△這不是給汽車的指示,但也太隨性了
所以,要把車道標識和路面,貼上一樣的標簽。
用Python寫出來,預處理功能就長這樣——
1def preprocess_labels(label_image): 2 labels_new = np.zeros_like(label_image) 3 # Identify lane marking pixels (label is 6) 4 lane_marking_pixels = (label_image[:,:,0] == 6).nonzero() 5 # Set lane marking pixels to road (label is 7) 6 labels_new[lane_marking_pixels] = 7 7 8 # Identify all vehicle pixels 9 vehicle_pixels = (label_image[:,:,0] == 10).nonzero()10 # Isolate vehicle pixels associated with the hood (y-position > 496)11 hood_indices = (vehicle_pixels[0] >= 496).nonzero()[0]12 hood_pixels = (vehicle_pixels[0][hood_indices], 13 vehicle_pixels[1][hood_indices])14 # Set hood pixel labels to 015 labels_new[hood_pixels] = 016 # Return the preprocessed label image 17 return labels_new
預處理過后的結(jié)果,就是標記和之前的不太一樣了。
準備活動做好了,神經(jīng)網(wǎng)絡的正式訓練也就可以開始了。
誰是分類小公主?
那么,大叔選的是怎樣的神經(jīng)網(wǎng)絡?
定制一個FCN-Alexnet或許是個不錯的選項,它擅長把每個像素分到不同的類別里。
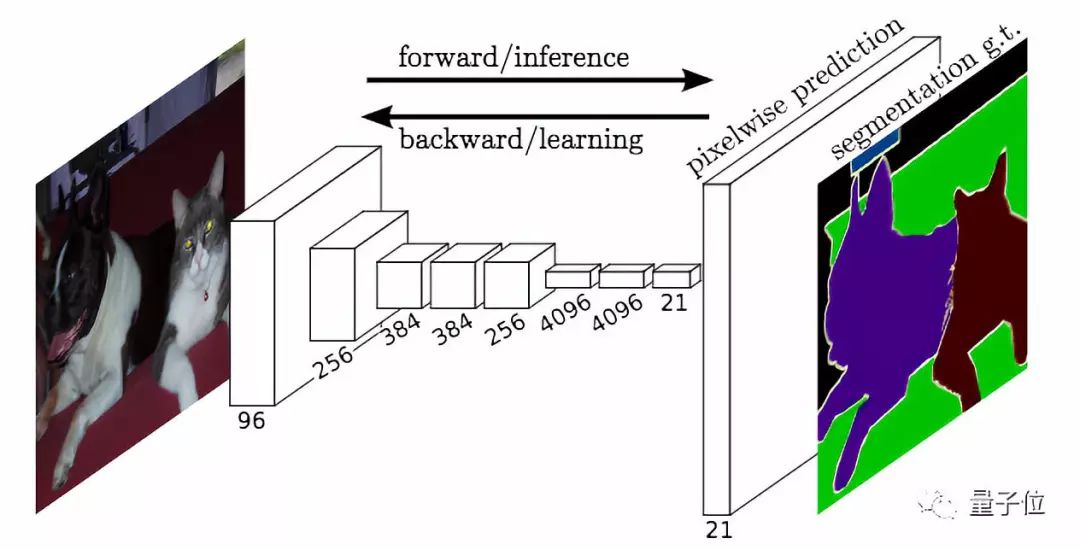
循著以下鏈接,可以找到這個模型的詳細信息——
代碼:
https://github.com/shelhamer/fcn.berkeleyvision.org/tree/master/voc-fcn-alexnet
論文:
https://arxiv.org/pdf/1605.06211.pdf
大叔用一個隨機梯度下降solver,把全部訓練數(shù)據(jù)跑了10次(10 epochs) ,基礎學習率設的是0.0001。
評估訓練成果
拿訓練好的神經(jīng)網(wǎng)絡去跑驗證數(shù)據(jù),凱爾得到了0.6685的F2值,以及0.9574的F0.5值 (前者更重視召回率,后者更重視準確率) 。系統(tǒng)每秒處理6.06幅圖像。
當然,視頻會比這些數(shù)字更加生動
然后還想怎樣?
大叔說,要讓神經(jīng)網(wǎng)絡表現(xiàn)更好,將來會搜集更多數(shù)據(jù),涉及更加豐富的路況。
另外,要進行一系列的數(shù)據(jù)增強,讓數(shù)據(jù)和數(shù)據(jù)之間的差異更加明顯。
關(guān)于神經(jīng)網(wǎng)絡的結(jié)構(gòu),也還有其他選擇,比如為細粒度預測而生的FCN-8,值得嘗試。
還有,可以引入時態(tài)數(shù)據(jù)(光流) ,來減少推斷需要的幀數(shù),同時保持比較高的準確度。
模擬器不夠真?
當然,只有模擬器也是不夠的,自動駕駛系統(tǒng)終究要接受現(xiàn)實的考驗。
面對真實攝像頭傳出的畫面,系統(tǒng)的辨識結(jié)果并沒有非常理想。不過在許多幀里面,神經(jīng)網(wǎng)絡都能夠在一定程度上,辨認出道路和車輛。
真實世界和模擬器里的駕駛場景,還是不一樣的。
如果模擬器生成的圖像和現(xiàn)實更加接近的話,可能結(jié)果就會好一些了。
不難看到,在和模擬器設定更為接近的路況下,系統(tǒng)的表現(xiàn)還是很不錯的。
如此看來,這只AI還是很有前途。只要把模擬器造得更貼近真實,神經(jīng)網(wǎng)絡應該就能得到更有效的訓練。
這里提供一段代碼,可以用來查看,算法跑出的結(jié)果到底怎么樣——
1from moviepy.editor import VideoFileClip, ImageSequenceClip 2import numpy as np 3import scipy, argparse, sys, cv2, os 4 5file = sys.argv[-1] 6 7if file == 'demo.py': 8 print ("Error loading video") 9 quit1011def your_pipeline(rgb_frame):1213 ## Your algorithm here to take rgb_frame and produce binary array outputs!1415 out = your_function(rgb_frame)1617 # Grab cars18 car_binary_result = np.where(out==10,1,0).astype('uint8')19 car_binary_result[496:,:] = 020 car_binary_result = car_binary_result * 2552122 # Grab road23 road_lines = np.where((out==6),1,0).astype('uint8')24 roads = np.where((out==7),1,0).astype('uint8')25 road_binary_result = (road_lines | roads) * 2552627 overlay = np.zeros_like(rgb_frame)28 overlay[:,:,0] = car_binary_result29 overlay[:,:,1] = road_binary_result3031 final_frame = cv2.addWeighted(rgb_frame, 1, overlay, 0.3, 0, rgb_frame)3233 return final_frame3435# Define pathname to save the output video36output = 'segmentation_output_test.mp4'37clip1 = VideoFileClip(file)38clip = clip1.fl_image(your_pipeline)39clip.write_videofile(output, audio=False)
用到的可視化數(shù)據(jù)在這里:https://s3-us-west-1.amazonaws.com/udacity-selfdrivingcar/Lyft_Challenge/videos/Videos.tar.gz
你也一起來吧?
當然,作為Lyft感知挑戰(zhàn)賽的研發(fā)負責人,凱爾大叔這番苦口婆心的目的,還是吸引更多的小伙伴摻和進來。
道路安全,人人有責。大概就是這個意思,吧。
-
傳感器
+關(guān)注
關(guān)注
2564文章
52615瀏覽量
763883 -
激光雷達
+關(guān)注
關(guān)注
971文章
4196瀏覽量
191998 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14209瀏覽量
169604
原文標題:自動駕駛感知訓練指南:不許你歧視車道線,那也是路面的一部分
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
自動駕駛安全基石:ODD
新能源車軟件單元測試深度解析:自動駕駛系統(tǒng)視角
AI將如何改變自動駕駛?
感知融合如何讓自動駕駛汽車“看”世界更清晰?
從自動駕駛行業(yè),分析數(shù)據(jù)標注在人工智能的重要性
以自動駕駛角度解析數(shù)據(jù)標注對于人工智能的重要性
“多維像素”多模態(tài)雷視融合技術(shù)構(gòu)建自動駕駛超級感知能力 上海昱感微電子創(chuàng)始人蔣宏GADS演講預告
一文聊聊自動駕駛測試技術(shù)的挑戰(zhàn)與創(chuàng)新

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論