") 如何解釋這種高效算法的方法
如何解釋這種高效算法的方法

XGBoost是一種高效的集成學(xué)習(xí)模型框架,利用樹型分類器可以得到強(qiáng)大的分類結(jié)果和十分高效的運(yùn)算效率。這篇文章主要探討如何解釋這種高效算法的方法,以及正確解釋模型的價(jià)值。如果你也被集成樹模型(如梯度提升樹)的可靠性和準(zhǔn)確率所吸引,并且需要對(duì)他們作出解釋,那么這篇文章會(huì)為你帶來很多有益的思考。
假設(shè)我們的任務(wù)是為銀行預(yù)測(cè)個(gè)人的金融狀況。模型準(zhǔn)確率越高,銀行收入就越多。但是因?yàn)槟P偷念A(yù)測(cè)會(huì)用于借貸業(yè)務(wù),因此我們也要能對(duì)模型為什么做出這樣的預(yù)測(cè)給出合理解釋。在嘗試了各種各樣的模型后,我們發(fā)現(xiàn)XGBoost所實(shí)現(xiàn)的梯度提升樹模型能給出最好的準(zhǔn)確率。然而要解釋為什么XGBoost做出某個(gè)預(yù)測(cè)是困難的,所以我們面前有兩個(gè)選擇:1. 轉(zhuǎn)而使用更容易解釋的線性模型。2. 找出如何解釋XGBoost模型的方法。數(shù)據(jù)科學(xué)家們往往都不想犧牲準(zhǔn)確率,所以我們也決定嘗試后者,即對(duì)復(fù)雜XGBoost模型(1247個(gè)深度為6的決策樹)作出解釋。
經(jīng)典全局特征重要性度量
最直接的選擇就是使用XGBoost Python接口中的plot_importance()方法。它能給出一個(gè)簡單的柱狀圖來表示我們數(shù)據(jù)集中每一個(gè)特征的重要性。
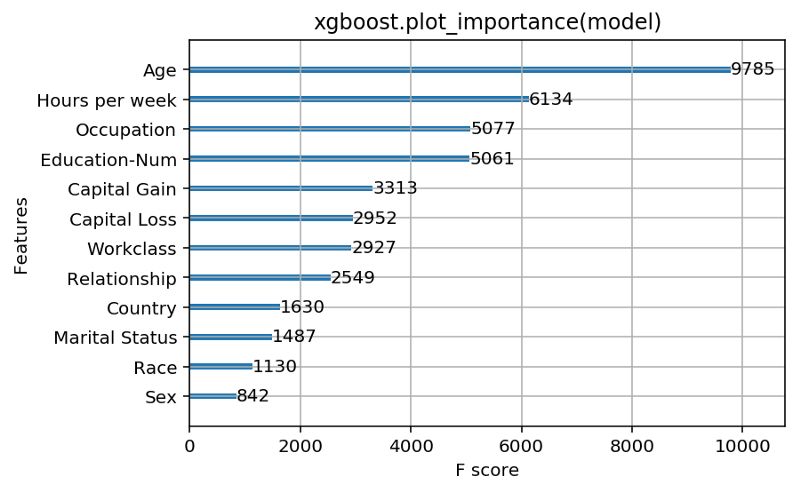
在一個(gè)用來預(yù)測(cè)人們是否會(huì)上報(bào)$50k以上收入的模型上運(yùn)行xgboost.plot_importance方法的結(jié)果
通過觀察XGBoost所返回的特征重要性結(jié)果,我們可以看到年齡毫無疑問比其他特征都要重要。我們可以就此打住,并得出年齡就是我們模型最重要特征的結(jié)論,其次是每周的工作時(shí)長和受教育水平。但是身為優(yōu)秀的數(shù)據(jù)科學(xué)家,我們從文檔中得知在XGBoost中對(duì)特征重要性的度量共有三個(gè)選項(xiàng):
Weight:一個(gè)特征在所有決策樹中被用來劃分?jǐn)?shù)據(jù)的次數(shù)。
Cover:一個(gè)特征在所有決策樹中被用來劃分?jǐn)?shù)據(jù)的次數(shù)和每次劃分涉及的樣本個(gè)數(shù)得到的加權(quán)結(jié)果。
Gain:一個(gè)特征被用于劃分?jǐn)?shù)據(jù)時(shí)所帶來的訓(xùn)練損失減益的平均值。
這些都是幾乎在任何樹模型的包里都能見到的典型重要性度量。Weight是默認(rèn)選項(xiàng),所以我們決定試一下另外兩個(gè)選項(xiàng),看結(jié)果是否有所差別。
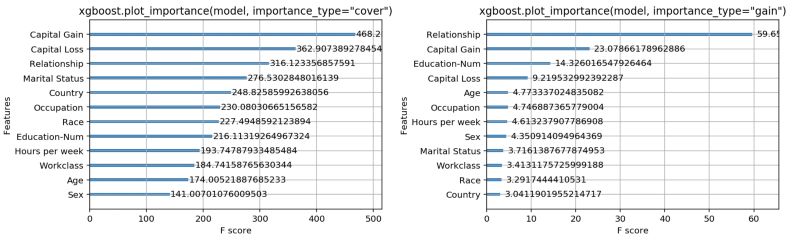
用cover和gain作為選項(xiàng)來運(yùn)行xgboost.plot_importatnce的結(jié)果
我們很驚訝地看到特征重要性的順序較之前有很大不同。以cover為度量時(shí),capital gain這一特征最能用于預(yù)測(cè),而當(dāng)用gain作為度量時(shí),relationship status比其他特征都重要。在搞清哪一種度量最好之前,我們很難直接用這些度量來解釋模型的重要性。
如何判斷特征重要性的度量是好是壞?
比較不同特征歸因方法(feature attribution method)的優(yōu)劣并不容易。為了方便比較,我們定義如下兩個(gè)指標(biāo):
一致性:如果我們對(duì)一個(gè)模型作出修改,使得它更依賴于某一個(gè)特征的話,那么由特征歸因方法所得到的該特征的重要性(attributed importance)不應(yīng)當(dāng)降低。
準(zhǔn)確性:所有特征重要性的和應(yīng)等于模型的總重要性。例如,如果重要性是由R2值計(jì)算得到的,那么各個(gè)特征的R2值相加應(yīng)等于模型的R2值。
如果某種特征歸因方法不滿足一致性,我們就很難用這種方法來比較兩個(gè)模型。因?yàn)榧幢阄覀兯愕靡粋€(gè)特征在一個(gè)模型的重要性更高,也不意味著這個(gè)模型更依賴于該特征。
而當(dāng)一個(gè)方法不滿足準(zhǔn)確性時(shí),我們不知道每個(gè)特征的重要性跟模型重要性間的關(guān)系是怎么樣的。所以我們就不能對(duì)歸因方法的結(jié)果直接歸一化,因?yàn)闅w一化可能會(huì)打破一致性。
目前的歸因方法是一致和準(zhǔn)確的嗎?
如上所述,一個(gè)歸因方法應(yīng)當(dāng)滿足一致性和準(zhǔn)確性,當(dāng)一個(gè)方法不滿足一致性,我們不能保證具有最高歸因的特征是實(shí)際上最重要的。下面我們來使用兩個(gè)非常簡單的樹模型來檢查歸因方法的一致性:
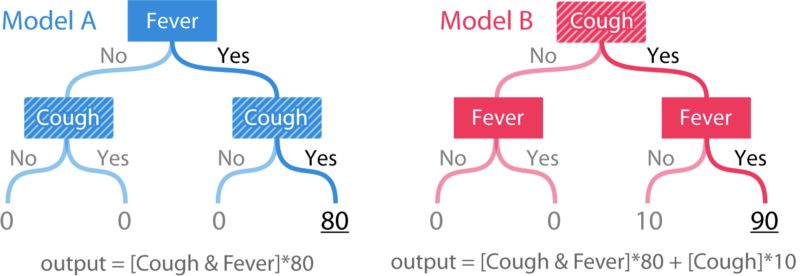
基于兩個(gè)特征的簡單樹模型,模型B中的咳嗽這一個(gè)特征顯然比模型A中的更重要。
模型的輸出是基于不同癥狀對(duì)生病的風(fēng)險(xiǎn)所做出的評(píng)分。當(dāng)發(fā)燒和咳嗽兩個(gè)癥狀同時(shí)出現(xiàn)時(shí),模型A會(huì)給出一個(gè)非零的風(fēng)險(xiǎn)分?jǐn)?shù)。模型B跟模型A類似,但在咳嗽癥狀出現(xiàn)時(shí),模型B會(huì)在模型A的基礎(chǔ)上加10分。為了檢查一個(gè)歸因方法是否滿足一致性,我們要先定義“重要性”。在這里我們將用兩種方法來定義重要性:1)當(dāng)我們移除一組特征時(shí),模型預(yù)期準(zhǔn)確率(accuracy)的變化。 2)當(dāng)我們移除一組特征時(shí),模型預(yù)期輸出(output)的變化。
第一個(gè)定義可以衡量特征對(duì)模型的全局影響,而第二個(gè)定義則是衡量特征對(duì)單一預(yù)測(cè)的局部影響。在A和B兩個(gè)簡單樹模型中,無論從哪個(gè)定義出發(fā),咳嗽特征在模型B中都更重要。
上文中提到的weight,cover和gain三種方法都是全局特征歸因方法。但是對(duì)銀行部署的模型來說,模型需要對(duì)每個(gè)客戶的預(yù)測(cè)提供解釋。為了驗(yàn)證不同方法是否滿足一致性,我們?cè)诤唵螛淠P蜕线\(yùn)行五種不同的特征歸因方法:
1.Tree SHAP.我們提出的一種新穎的局部方法。
2.Saabas.一種啟發(fā)式的局部方法。
3.mean(|Tree SHAP|).一種基于Tree SHAP的局部結(jié)果取均值的全局方法。
4.Gain.與上文中的XGBoost中的Gain方法相同。
5.Split count.與上文中XGBoost中的weight方法相同。
6.Permutation. 當(dāng)隨機(jī)擾動(dòng)某個(gè)特征時(shí),模型在測(cè)試集上的準(zhǔn)確率的下降。
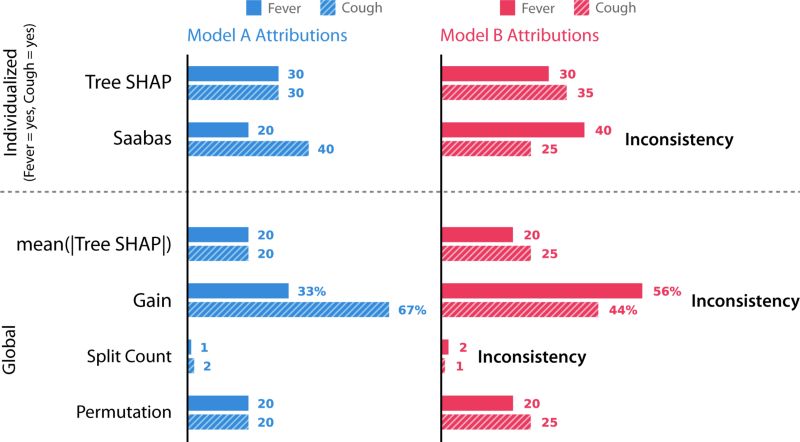
使用六種不同的方法對(duì)模型A和模型B進(jìn)行特征歸因。這六種方法是已知文獻(xiàn)中所有針對(duì)樹模型的特征歸因方法。
但前述的方法都是不一致的,這是由于他們認(rèn)為在模型B中咳嗽的重要性小于模型A。不一致的模型不能將影響最大的特征視為最重要的特征。細(xì)心的讀者可能已經(jīng)發(fā)現(xiàn)我們已經(jīng)在前文中的經(jīng)典特征歸因方法中提出過不一致特征了。同時(shí)對(duì)于精確性來說,Tree SHAP、Sabaas和Gain三種方法是精確的而分裂計(jì)數(shù)和特征置換是不準(zhǔn)確的。
令人驚訝的是,被廣泛使用的基于gain的方法會(huì)引起如此多的不一致的結(jié)果。為了更好的理解其中的原因,讓我們來看看gain是如何計(jì)算模型A和B的。讓我們簡單的假設(shè)25%的數(shù)據(jù)落到了每一個(gè)的葉子節(jié)點(diǎn)并被精確的標(biāo)記(每個(gè)葉子1/4)。
如果將均方根誤差作為損失函數(shù),首先從模型A的1200開始計(jì)量。在第一次分裂的過程中,損失從1200降到了800,那么意味著gain利用fever特征貢獻(xiàn)了400提升;進(jìn)一步利用cough特征分裂得到了0的損失,意味著cough貢獻(xiàn)了800的提升;在模型B中,Cough和Fever分別貢獻(xiàn)了625和800的提升。如下圖所示:
模型A和模型B的分?jǐn)?shù)計(jì)算
通常情況下距離根比較近的節(jié)點(diǎn)擁有比靠近葉子節(jié)點(diǎn)更重要的特征。那么對(duì)于gain方法來說,它對(duì)于gain方法來說低層級(jí)靠近葉子節(jié)點(diǎn)的特征卻貢獻(xiàn)了更多的重要性。正是這種偏差導(dǎo)致了不一致性。隨著樹的加深,這樣的偏差也在不斷增長。但對(duì)于Tree SHAP方法來說,在數(shù)學(xué)上對(duì)不同層次的特征進(jìn)行了平均。
模型解釋
結(jié)合了堅(jiān)實(shí)的理論和快速的算法實(shí)現(xiàn)讓SHAP值成為了解釋樹形模型的有力工具。利用這種新方法,我們重新解釋了上文中個(gè)性化銀行模型中的特征。
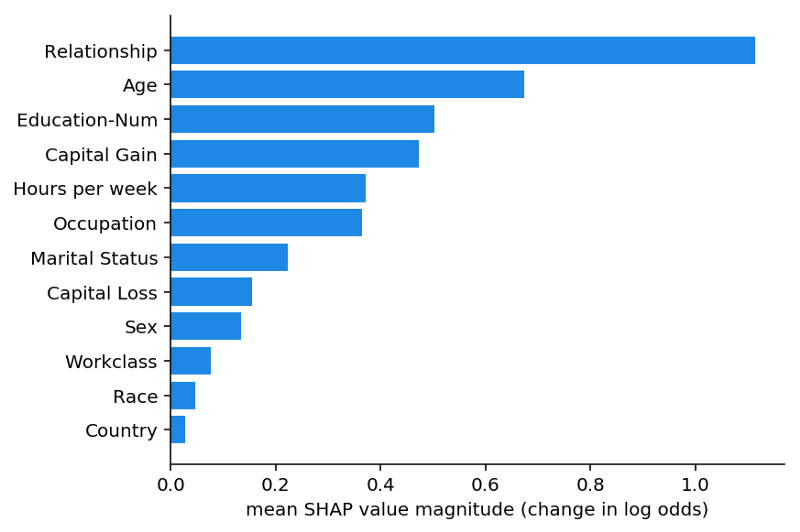
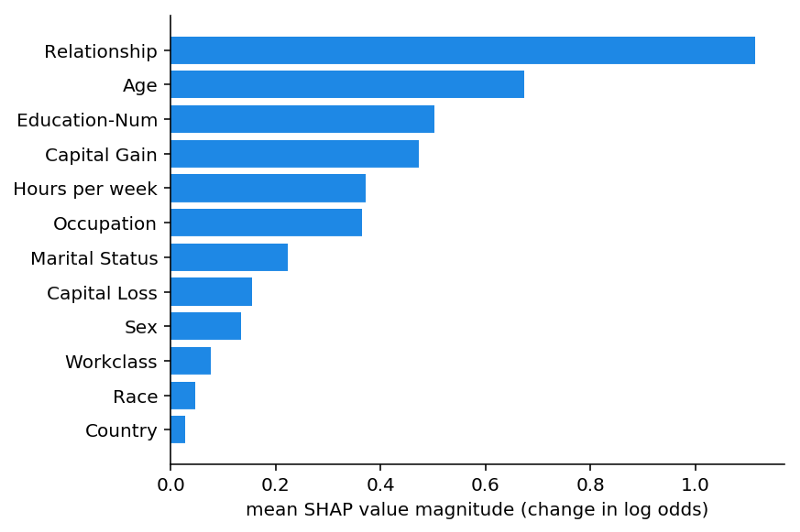
基于SHAP的全局均值方法用于收入預(yù)測(cè)模型
我們可以看到關(guān)系是最重要的特征,其次是年齡特征。SHAP度量保證了一致使得我們的分析更加容易。接下來我們需要對(duì)每一個(gè)客戶繪制響應(yīng)的特征:
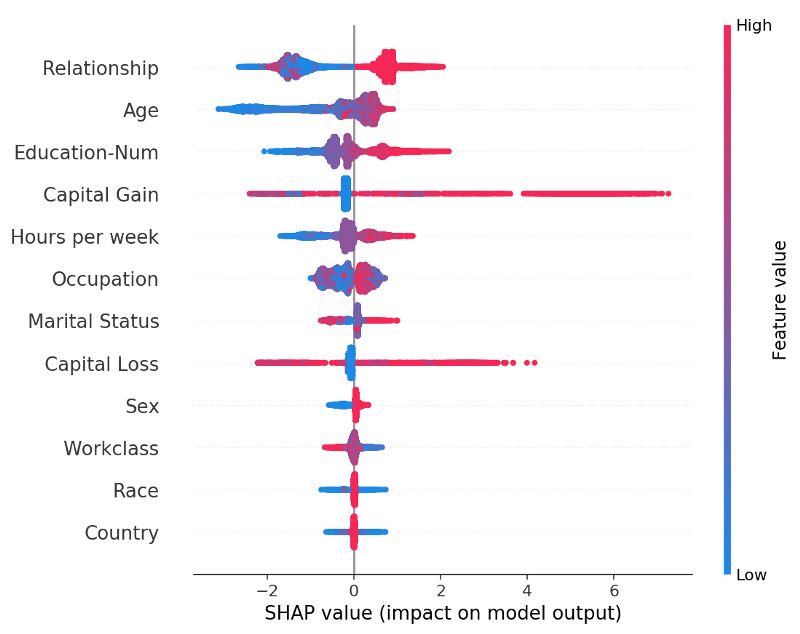
圖中每個(gè)點(diǎn)代表一個(gè)客戶,x坐標(biāo)是特征的重要性,顏色代表特征的取值
上圖中特征根據(jù)均值排列,從中我們可以看到關(guān)系特征在收入達(dá)到50k$上的預(yù)測(cè)十分強(qiáng)烈。同時(shí)我們可以從上圖中看到局外點(diǎn)的影響。圖中的的顏色同時(shí)還顯示了年輕人一般收入較低、受教育程度會(huì)提高收入。
做了這么多,結(jié)果已經(jīng)很棒了。但是我們還可以從中發(fā)現(xiàn)更多的信息。我們可以繪制出度量隨特征的變化如下圖所示:
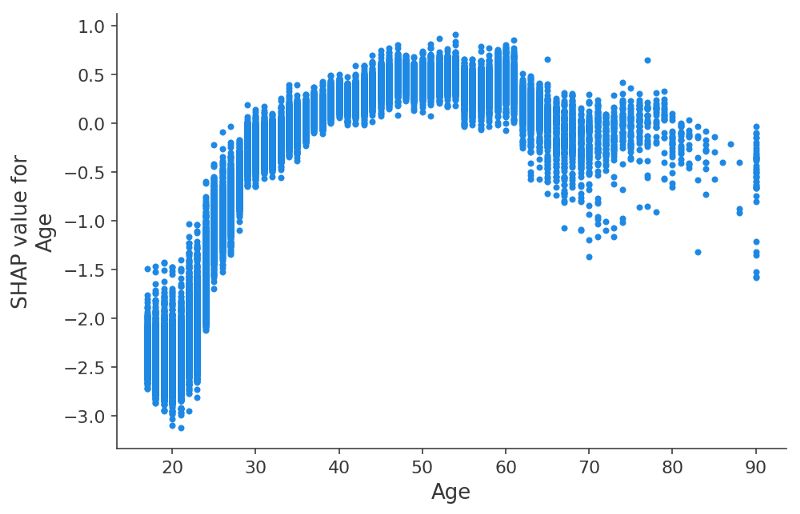
y軸表示了年齡對(duì)于年收入超過50k$的影響程度。
從中可以清晰的看到XGBoost模型抽取的特征,及其相互影響。對(duì)于20多歲的年輕人來說,年齡對(duì)于他們的影響十分小甚至有副作用,這意味著其他特征影響著年齡的重要性。為了了解這種相互影響,我們將受教育年限作為帶顏色的點(diǎn)繪制到了同一副圖中。高等教育在20多歲的年紀(jì)里對(duì)于收入影響不大,但在30多歲時(shí)候卻有著至關(guān)重要的影響。
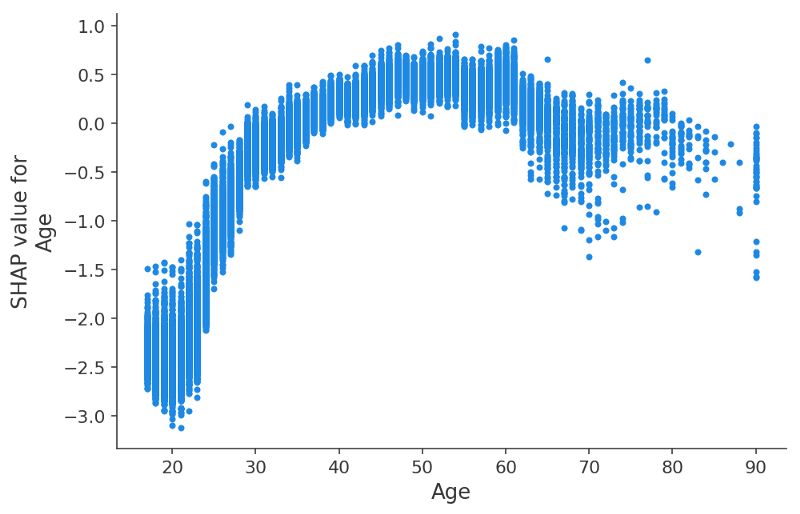
上圖中可以清楚的看出受教育程度和年齡的關(guān)系。同樣我們還可以做出每周工作時(shí)間及其重要性的關(guān)系。
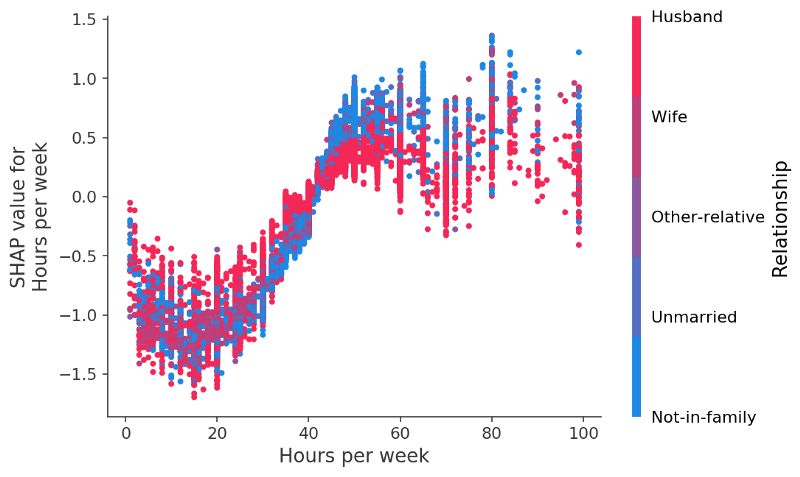
如果我們對(duì)于數(shù)據(jù)中的另一個(gè)變量工作時(shí)間進(jìn)性相同的分析的話,我們會(huì)發(fā)現(xiàn)沒有工作50小時(shí)是比較好的選擇,而如果對(duì)對(duì)于已婚人士來說的話超出的工作時(shí)間并不能為他們帶來更多的收入。
解讀你的模型
我們大概瀏覽了一遍在構(gòu)建和部署模型的時(shí)候如何思考和理解模型。我們可以通過SHAP值作為度量來分析并利用shape工具包來可視化分析結(jié)果。從而尋找出最重要的變量。如果你對(duì)XGBoost感興趣,你還可以嘗試下Apache的XGBoost和微軟的LightGBM這兩個(gè)工具包,相信會(huì)給你帶來不錯(cuò)的結(jié)果。
-
算法
+關(guān)注
關(guān)注
23文章
4705瀏覽量
95094 -
決策樹
+關(guān)注
關(guān)注
3文章
96瀏覽量
13799
原文標(biāo)題:從XGBoost算法開始,更好地理解和改進(jìn)你的模型
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
圖書分享:卡爾曼濾波算法的幾何解釋
算法心得( 高效算法的奧秘)--電子書下載
如何快速高效的在自己的設(shè)備中加入國密算法

如何解釋取消針刺 動(dòng)力電池如何檢測(cè)安全
用于解釋神經(jīng)網(wǎng)絡(luò)的方法是如何發(fā)展的?
如何解釋DCDC“瞬態(tài)響應(yīng)”指標(biāo)資料下載

基于機(jī)器學(xué)習(xí)算法的水文趨勢(shì)預(yù)測(cè)方法

如何解決JVM解釋器導(dǎo)致應(yīng)用崩潰的bug

使用LIME解釋CNN
使用LIME解釋CNN






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論