") 如何解決JVM解釋器導(dǎo)致應(yīng)用崩潰的bug
如何解決JVM解釋器導(dǎo)致應(yīng)用崩潰的bug

編者按:筆者遇到一個非常典型的問題,應(yīng)用在 X86 正常運行,在 AArch64 上 JVM 就會崩潰。這個典型的 JVM 內(nèi)部問題。筆者通過分析最終定位到是由于 JVM 中模板解釋器代碼存在 bug 導(dǎo)致在弱內(nèi)存模型的平臺上 Crash。
在分析過程中,涉及到非常多的 JVM 內(nèi)部知識,比如對象頭、GC 復(fù)制算法操作、CAS 操作、字節(jié)碼執(zhí)行、內(nèi)存序等,希望對讀者有所幫助。本文介紹了一般分析 JVM crash 的方法,并且深入介紹了為什么在 aarch64 平臺上引起這樣的問題,最后還給出了修改方法并推送到上游社區(qū)中。**對于使用非畢昇 JDK 的其他 JDK 只有在 jdk8u292、jdk11.0.9、jdk15以后的版本才得到修復(fù),讀者使用時需要注意版本選擇避免這類問題發(fā)生。
背景知識
java 程序在發(fā)生 crash 時,會生成 hs_err_pid.log 文件,以及 core 文件(需要操作系統(tǒng)開啟相關(guān)設(shè)置),其中 hs_err 文件以文本格式記錄了 crash 發(fā)生位置的小范圍精確現(xiàn)場信息(調(diào)用棧、寄存器、線程棧、致命信號、指令上下文等)、jvm 各組件狀態(tài)信息(java 堆、jit 事件、gc 事件)、系統(tǒng)層面信息(環(huán)境變量、入?yún)ⅰ?nèi)存使用信息、系統(tǒng)版本)等,精簡記錄了關(guān)鍵信息。而 core 文件是程序崩潰時進(jìn)程的二進(jìn)制快照,完整記錄了崩潰現(xiàn)場信息,可以使用 gdb 工具來打開 core 文件,恢復(fù)出一個崩潰現(xiàn)場,方便分析。
約束
文中描述的問題適用于 jdk8u292 之前的版本。
現(xiàn)象
某業(yè)務(wù)線隔十天半個月總會報過來 crash 問題,crash 位置比較統(tǒng)一,都是在某處執(zhí)行 young gc 的上下文中,crash 的直接原因是 java 對象的頭被寫壞了,比如這樣:

而正常的對象頭由 markoop 和 metadata 兩部分組成,前者存放該對象的 hash 值、年齡、鎖信息等,后者存放該對象所屬的 Klass 指針。這里關(guān)注的是 markoop,64 位機器上它的具體布局如下:

每種布局中每個字段的詳細(xì)含義可以在 jdk 源碼 jdk8u/hotspot/src/share/vm/oops/markOop.hpp 中找到,這里簡單給出結(jié)論就是 gc 階段一個正常對象頭中的 markoop 不可能是全 0,而是比如這樣:

此外,crash 時間上也有個特點:基本每次都發(fā)生在程序剛啟動時的幾秒內(nèi)。
分析
發(fā)生 crash 的 java 對象有個一致的特點,就是總位于 eden 區(qū),我們仔細(xì)分析了 crash 位置的 gc 過程邏輯,特別是會在 gc 期間修改對象頭的相關(guān)源碼更是重點關(guān)注對象,因為那塊代碼為了追求性能,使用了無鎖編程:

補充介紹一下 CAS(Compare And Swap),CAS 的完整意思是比較并替換,并且確保整個操作原子性。CAS 需要 3 個操作數(shù):內(nèi)存地址 dst,比較值 cmp,要更新的目標(biāo)值 value。當(dāng)且僅當(dāng)內(nèi)存地址 dst 上的值跟比較值 cmp 相等時,將內(nèi)存地址 dst 上的值改寫為 value,否則就什么都不做,其在 aarch64 上的匯編實現(xiàn)類似如下:

然而我們經(jīng)過反復(fù)推敲,這塊 gc 邏輯似乎無懈可擊,而且位于 eden 區(qū)也意味著沒有被 gc 搬移過的可能性,這個問題在很長時間里陷入了停滯……
直到某一天又收到了一個類似的 crash,這個問題才迎來了轉(zhuǎn)機。在這個 crash 里,也是 java 對象的頭被寫壞了,但特殊的地方在于,頭上的錯誤值是 0x2000,憑著職業(yè)敏感,我們猜測這個特殊的錯誤值是否來自這個 java 對象本身呢?這個對象的 Java 名字叫 DynamicByteBuffer,來自某個基礎(chǔ)組件。反編譯得到了問題類 DynamicByteBuffer 的代碼:
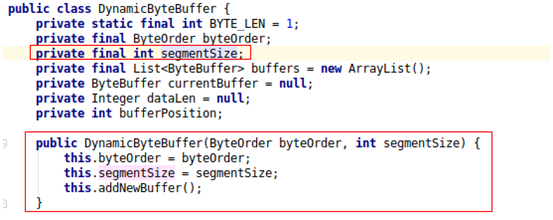
再結(jié)合 core 信息中其他正常 DynamicByteBuffer 對象的布局,確定了這個特殊的 0x2000 值原本應(yīng)該位于 segmentSize 字段上,而且從代碼中注意到這個 segmentSize 字段是 final 屬性,意味著其值只可能在實例構(gòu)造函數(shù)中被設(shè)置,使用 jdk 自帶的命令 javap 進(jìn)行反匯編,得到對應(yīng)的字節(jié)碼如下:
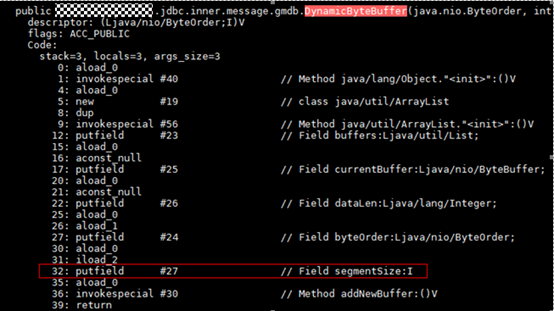
putfield 這條字節(jié)碼的作用是給 java 對象的一個字段賦值,在紅框中的語義就是給 DynamicByteBuffer 對象的 segmentSize 字段賦值。
分析到這里,我們做一下小結(jié),crash 的第一現(xiàn)場并非在 gc 上下文中,而是得往前追溯,發(fā)生在這個 java 對象被初始化期間,這期間在初始化它的 segmentSize 字段時,因為某種原因,0x2000 被寫到了對象頭上。
接下來繼續(xù)分析, JDK 在發(fā)生 crash 時會自動生成的 hs_err 日志,其中有記錄最近發(fā)生的編譯事件 “Compilation events (250 events)”,從中沒有發(fā)現(xiàn) DynamicByteBuffer 構(gòu)造函數(shù)相關(guān)的編譯事件,所以可以推斷 crash 時 DynamicByteBuffer 這個類的構(gòu)造函數(shù)尚未被編譯過(由于 crash 發(fā)生在程序啟動那幾秒,JIT 往往需要預(yù)熱后才會介入,所以可以假設(shè)記錄的比較完整),這意味著,它的構(gòu)造函數(shù)只會通過模板解釋器去執(zhí)行,更具體地說,是去執(zhí)行模板解釋器中的 putfield 指令來把 0x2000 寫到 segmentSize 字段位置。
具體怎么寫其實很簡單,就是先拿到 segmentSize 字段的偏移量,根據(jù)偏移量定位到寫的位置,然后寫入。然而 JVM 的模板解釋器在實現(xiàn)這個 putfield 指令時,額外增加了一條快速實現(xiàn)路徑,在 runtime 期間會自動(具體的時間點是 “完整” 執(zhí)行完第一次 putfield 指令后)從慢速路徑切到快速路徑上,這個切換操作的實現(xiàn)全程沒有加鎖,同步完全依賴 barrier。
注:圖中 bcp 指的是 bytecode pointer,就是讀字節(jié)碼。
上圖表示接近同一時間點前后,兩條并行流分別構(gòu)建一個 DynamicByteBuffer 類型的對象過程中,各自完成 segmentSize 字段賦值的過程,用 Java 代碼簡單示意如下:
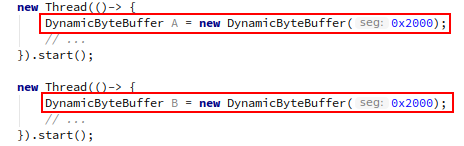
其中第一條執(zhí)行流走的慢速路徑,第二條走的快速路徑,可以留意到,紅色標(biāo)識的是幾次公共內(nèi)存的訪存操作,barrier 就分布在這些位置前后(標(biāo)在下圖中)。
接下來再給一個更加精確一點的指令流模型
簡單介紹一下這個設(shè)計模型:
線程從記錄了指令的內(nèi)存地址 bcp(bytecode pointer) 上取出指令,然后跳轉(zhuǎn)到該指令地址上執(zhí)行,當(dāng)取出的指令是 bcp1(比如 putfeild 指令的慢速路徑)時就是圖中左邊的指令流;
左邊的指令流就是計算出字段的 offset 并 str 到指定內(nèi)存地址,然后插入 barrier,最后將 bcp2 指令(比如 putfeild 指令的快速路徑)覆寫到步驟 1 中的內(nèi)存地址 addr 上;
后續(xù)線程繼續(xù)執(zhí)行步驟 1 時,由于取出的指令變成了 bcp2,就改為跳轉(zhuǎn)到圖中右邊的指令流;
右邊的指令流就是直接取出步驟 2 中已經(jīng)存到指定內(nèi)存地址中的 offset。
回顧整個設(shè)計模型,左邊的指令流通過一個等效于完整 dmb 的 barrier 來保證 str offset 和 str bcp2 這兩條 str 指令的執(zhí)行順序并且全局可見;而右邊的指令流中,ldr bcp 和 ldr offset 這兩條 ldr 指令之間沒有任何 barrier,設(shè)計者可能認(rèn)為一個無條件跳轉(zhuǎn)指令可以為兩條 ldr 指令建立依賴,從而保證執(zhí)行順序,然而從實測結(jié)果來看是不成立的。
這里先來簡單補充介紹一下內(nèi)存順序模型的概念,現(xiàn)代 CPU 為了提高執(zhí)行效率,在指令的執(zhí)行順序上擁有很大的自主權(quán),對每個獨立的 CPU 來說,只要確保語義不變,實際如何執(zhí)行都有可能,這種方式對于單個 CPU 來說沒有問題,當(dāng)放到多個 CPU 共享數(shù)據(jù)的時候,這種亂序執(zhí)行的行為就會引發(fā)每個 CPU 看到數(shù)據(jù)的順序不一致問題,導(dǎo)致跨 CPU 的程序邏輯亂套了。這就需要對讀、寫內(nèi)存指令進(jìn)行約束,來規(guī)范每個 CPU 看到的內(nèi)存生效行為,由此提出了內(nèi)存順序模型的概念:
其中 ARM 采用的是一種弱內(nèi)存模型,這種模型默認(rèn)對讀、寫指令沒有任何約束,需要由程序員自己通過插入 barrier 來手動保證。
再回到這個問題上,測試方式是在 ldr offset 指令后額外加了檢測指令:
就是檢查 offset 值是否為 0,如果為 0 則直接強制 crash(設(shè)計上保證了 java 對象的任何實例字段的 offset 不可能是 0)。
經(jīng)過長時間測試,程序果然在這個位置觸發(fā)了 crash!這說明上面提到的兩條 ldr 指令不存在依賴關(guān)系,或者說這種依賴關(guān)系類似 ARMv8 手冊中描述的條件依賴,并不能保證執(zhí)行順序。ldr offset 指令先于 ldr bcp 執(zhí)行,使得讀到一個非法的 offset 值 0。更說明了,這才是這個案例的第一案發(fā)現(xiàn)場!
找到了問題的根因后,解決方法也就順利出爐了,那就是在兩條 ldr 指令之間插入 barrier 來確保這兩條 ldr 指令不發(fā)生亂序。實測證明,這種修復(fù)方案非常有效,這類 crash 現(xiàn)象消失。
詳細(xì)的修復(fù) patch 見 https://hg.openjdk.java.net/jdk/jdk/rev/b9529fcbbd33 。目前已經(jīng) backport 到 jdk8u292、jdk11.0.9、jdk15。
總結(jié)
Java 虛擬機 (JVM) 為了追求性能,大量使用了無鎖編程進(jìn)行設(shè)計,而且這么多年以來 JDK(特別是 JDK8)主要都是面向 X86 平臺開發(fā)的,如今才慢慢的開始支持 aarch64 平臺,所以 aarch64 弱內(nèi)存序問題是我們面臨的一個比較嚴(yán)峻的挑戰(zhàn)。
后記
如果遇到相關(guān)技術(shù)問題(包括不限于畢昇 JDK),可以進(jìn)入畢昇 JDK 社區(qū)查找相關(guān)資源(點擊原文進(jìn)入官網(wǎng)),包括二進(jìn)制下載、代碼倉庫、使用教學(xué)、安裝、學(xué)習(xí)資料等。畢昇 JDK 社區(qū)每雙周周二舉行技術(shù)例會,同時有一個技術(shù)交流群討論 GCC、LLVM、JDK 和 V8 等相關(guān)編譯技術(shù),感興趣的同學(xué)可以添加如下微信小助手,回復(fù) Compiler 入群。
責(zé)任編輯:haq
-
應(yīng)用
+關(guān)注
關(guān)注
2文章
439瀏覽量
34482 -
JVM
+關(guān)注
關(guān)注
0文章
160瀏覽量
12575
原文標(biāo)題:一個 JVM 解釋器 bug 在 AArch64 平臺導(dǎo)致應(yīng)用崩潰的問題分析
文章出處:【微信號:wireless-tag,微信公眾號:啟明云端科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Keil單步調(diào)試顯示在USBPHYC狀態(tài)校驗中計數(shù)超時導(dǎo)致進(jìn)入異常,要如何解決這個問題呢?
CYPD3177-24LQXQ適配器電壓崩潰怎么解決?
如何避免存儲示波器再次崩潰?
服務(wù)器數(shù)據(jù)恢復(fù)—raid5陣列中硬盤壞道導(dǎo)致陣列崩潰的數(shù)據(jù)恢復(fù)案例
磁極是如何解決磁集成產(chǎn)品電磁干擾的?

服務(wù)器數(shù)據(jù)恢復(fù)—多塊硬盤離線導(dǎo)致EVA存儲崩潰的數(shù)據(jù)恢復(fù)案例

如何使用Ozone分析Cortex-M異常
變頻器主電路的故障如何解決 | 導(dǎo)致變頻器主板故障的原因是什么
從原理聊JVM(一):染色標(biāo)記和垃圾回收算法
CAN通過模擬開關(guān)進(jìn)行CAN1和CAN2總線的切換,接入總線后導(dǎo)致整個CAN網(wǎng)絡(luò)崩潰怎么解決?
遇見一個編譯優(yōu)化導(dǎo)致的bug

聊聊JVM如何優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論