") 京東廣告基于Apache Doris的冷熱數(shù)據(jù)分層實(shí)踐
京東廣告基于Apache Doris的冷熱數(shù)據(jù)分層實(shí)踐

一、背景介紹
京東廣告圍繞Apache Doris建設(shè)廣告數(shù)據(jù)存儲服務(wù),為廣告主提供實(shí)時(shí)廣告效果報(bào)表和多維數(shù)據(jù)分析服務(wù)。歷經(jīng)多年發(fā)展,積累了海量的廣告數(shù)據(jù),目前系統(tǒng)總數(shù)據(jù)容量接近1PB,數(shù)據(jù)行數(shù)達(dá)到18萬億行+,日查詢請求量8,000萬次+,日最高QPS2700+。 隨著業(yè)務(wù)的不斷增長與迭代,數(shù)據(jù)量持續(xù)激增,存儲資源逐漸成為瓶頸。近兩年存儲資源經(jīng)歷了多次擴(kuò)容,存儲容量增加了近十倍,而日查詢請求量僅增長兩倍。同時(shí),計(jì)算資源的利用率因頻繁擴(kuò)容而相應(yīng)降低,導(dǎo)致資源浪費(fèi)。通過對查詢請求的分析,我們發(fā)現(xiàn)日常查詢中有99%集中在近一年的數(shù)據(jù)上,數(shù)據(jù)使用呈現(xiàn)出明顯的冷熱現(xiàn)象。基于此,希望借助Apache Doris探索一種滿足線上服務(wù)要求的冷熱數(shù)據(jù)分層解決方案,在數(shù)據(jù)不斷膨脹的情況下,降低數(shù)據(jù)的存儲和使用成本。
二、冷熱分層方案介紹
截至當(dāng)前,我們的數(shù)據(jù)冷熱分層實(shí)踐已歷經(jīng)兩種方案,分別是Doris冷數(shù)據(jù)入湖和Doris冷熱數(shù)據(jù)分層。Doris冷數(shù)據(jù)入湖方案通過SDC(Spark-Doris-Connector)將Doris中的冷數(shù)據(jù)轉(zhuǎn)入湖中,入湖后的冷數(shù)據(jù)可通過Doris外表進(jìn)行查詢。Doris冷熱數(shù)據(jù)分層方案則通過在Doris中設(shè)置數(shù)據(jù)的TTL時(shí)間,由Doris根據(jù)數(shù)據(jù)的TTL時(shí)間自動(dòng)判斷冷熱數(shù)據(jù),并將冷數(shù)據(jù)移至相對廉價(jià)的存儲介質(zhì)。冷數(shù)據(jù)入湖方案借鑒了騰訊游戲的相關(guān)經(jīng)驗(yàn)(https://cloud.tencent.com/developer/article/2251030),并在Apache Doris 1.2版本中進(jìn)行了實(shí)踐;而Doris冷熱數(shù)據(jù)分層方案則是最近上線的新一代冷熱數(shù)據(jù)分層方案。以下將結(jié)合我們過往的實(shí)踐經(jīng)驗(yàn),簡要介紹這兩種方案。
冷熱分層V1:數(shù)據(jù)湖方案
在數(shù)據(jù)湖方案中,需將Doris的數(shù)據(jù)依據(jù)業(yè)務(wù)時(shí)間進(jìn)行冷熱劃分。在類似場景中,業(yè)務(wù)時(shí)間即為Doris表的分區(qū)時(shí)間。為實(shí)現(xiàn)Doris數(shù)據(jù)入湖,需借助Spark-Doris-Connector(SDC)將Doris中的冷數(shù)據(jù)遷移至數(shù)據(jù)湖(如Iceberg)。查詢時(shí),需根據(jù)業(yè)務(wù)時(shí)間對查詢進(jìn)行冷熱區(qū)分,將冷數(shù)據(jù)查詢(冷查詢)與熱數(shù)據(jù)查詢(熱查詢)分別路由至不同的查詢引擎。冷數(shù)據(jù)查詢通過查詢改寫,將查詢重定向至數(shù)據(jù)湖對應(yīng)的外部表;熱數(shù)據(jù)查詢則無需改寫,直接查詢Doris中的OLAP表。
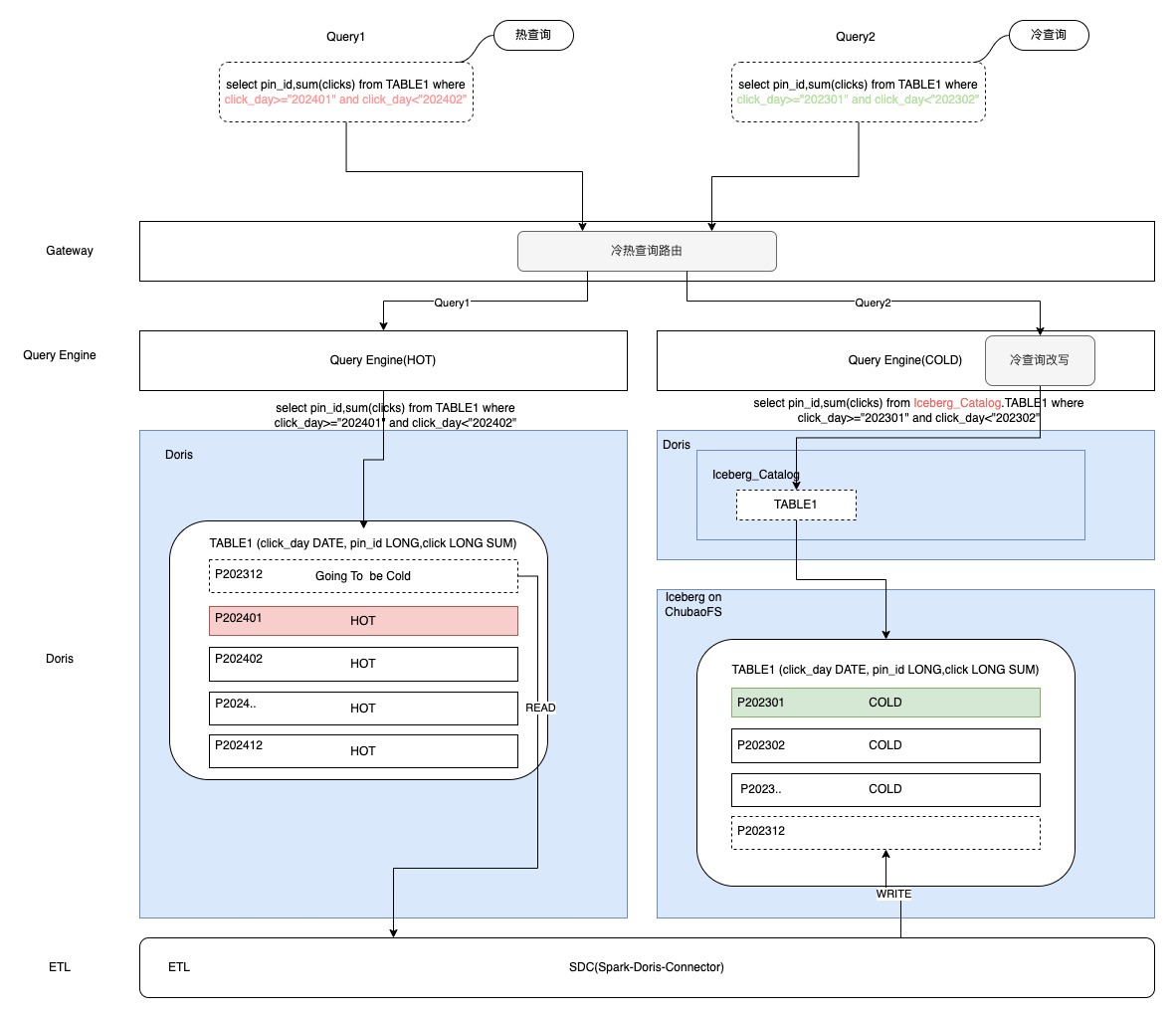
數(shù)據(jù)入湖方案的優(yōu)勢在于,冷數(shù)據(jù)的查詢與下載能夠與線上Doris系統(tǒng)實(shí)現(xiàn)解耦,從而確保線上操作的穩(wěn)定性不受影響。這種解耦設(shè)計(jì)確保了冷數(shù)據(jù)的處理和查詢不會干擾線上Doris系統(tǒng)的正常運(yùn)行。通過將冷數(shù)據(jù)與線上系統(tǒng)分離,可以確保線上系統(tǒng)在處理實(shí)時(shí)數(shù)據(jù)時(shí)保持高效和穩(wěn)定。這對于需要高可用性和低延遲的在線廣告報(bào)表業(yè)務(wù)而言尤為重要。
數(shù)據(jù)入湖方案的主要劣勢包括以下幾點(diǎn):首先,需借助ETL工具實(shí)現(xiàn)數(shù)據(jù)從Doris到數(shù)據(jù)湖的遷移。ETL工具能夠自動(dòng)化數(shù)據(jù)遷移過程,但這也意味著需要額外的資源和時(shí)間來配置及運(yùn)行這些工具。其次,為了獲取完整的數(shù)據(jù)集,必須對Doris中的熱數(shù)據(jù)和數(shù)據(jù)湖中的冷數(shù)據(jù)進(jìn)行UNION操作。這意味著在進(jìn)行數(shù)據(jù)分析或查詢時(shí),需要同時(shí)訪問兩個(gè)不同的數(shù)據(jù)存儲系統(tǒng),這不僅增加了系統(tǒng)的復(fù)雜性,還可能影響查詢性能。例如,如果一個(gè)分析需要同時(shí)查詢熱數(shù)據(jù)和冷數(shù)據(jù),那么查詢時(shí)間可能會顯著增加,因?yàn)橄到y(tǒng)需要從兩個(gè)不同的地方獲取數(shù)據(jù)。最后,數(shù)據(jù)入湖后,Schema變更操作需得到相應(yīng)數(shù)據(jù)湖的支持。這意味著如果需要對數(shù)據(jù)結(jié)構(gòu)進(jìn)行修改,例如添加或刪除字段,必須確保數(shù)據(jù)湖能夠支持這些變更。這可能需要額外的技術(shù)支持和維護(hù)工作。
冷熱分層V2:Apache Doris冷熱數(shù)據(jù)分層方案
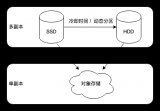
Apache Doris 1.2 的冷熱數(shù)據(jù)分層方案基于本地磁盤,熱數(shù)據(jù)存儲于 SSD,而冷數(shù)據(jù)則轉(zhuǎn)移至性能較低的 HDD,以此實(shí)現(xiàn)數(shù)據(jù)分層。然而,此方案存在以下缺點(diǎn):首先,該方案更適合物理機(jī)部署,而不適用于容器或 Kubernetes (K8S) 部署。當(dāng)前,大多數(shù)公司已轉(zhuǎn)向基于容器或 K8S 的部署方式,物理機(jī)部署已較為罕見。其次,需要預(yù)先估算冷數(shù)據(jù)的存儲空間,然而,冷數(shù)據(jù)量會隨時(shí)間逐漸增加,難以準(zhǔn)確預(yù)估其容量。因此,我們并未在 Doris 1.2 中采用 Doris 原生的冷熱數(shù)據(jù)分層方案,而是希望探索一種基于分布式文件系統(tǒng)作為冷數(shù)據(jù)存儲的新方案。
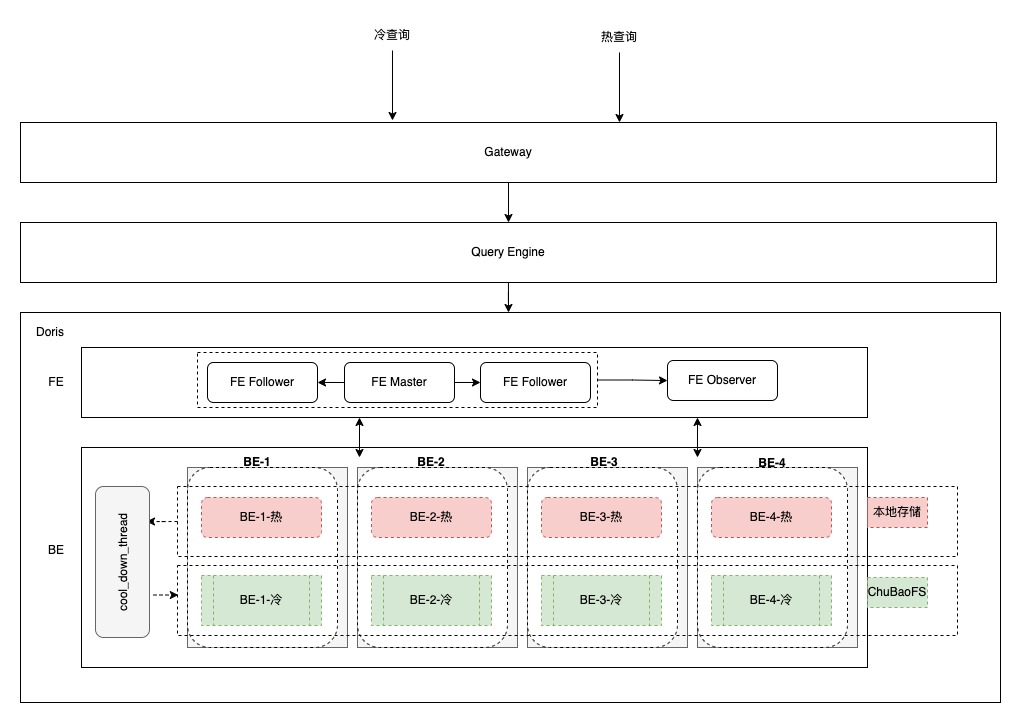
Apache Doris 2.0 的冷熱數(shù)據(jù)分層功能支持將冷數(shù)據(jù)存儲于如 OSS 和 HDFS 等分布式存儲系統(tǒng)中。用戶可通過配置相應(yīng)的存儲策略來指定數(shù)據(jù)的冷熱分層規(guī)則,進(jìn)而通過為表或分區(qū)設(shè)定存儲策略,實(shí)現(xiàn)冷數(shù)據(jù)自動(dòng)遷移至外部存儲系統(tǒng)。基于分布式存儲的 Doris 冷熱數(shù)據(jù)分層方案具有簡潔性,避免了數(shù)據(jù)湖方案的復(fù)雜性。然而,該方案的缺點(diǎn)在于冷熱數(shù)據(jù)統(tǒng)一在一個(gè)集群中進(jìn)行管理和使用,高優(yōu)先級的熱查詢可能會受到冷查詢的影響,因此需要對冷數(shù)據(jù)查詢進(jìn)行適當(dāng)?shù)南蘖鳌R韵聦⒔榻B我們在從 Doris 1.2 的數(shù)據(jù)湖方案升級至 Doris 2.0 基于分布式存儲的冷熱數(shù)據(jù)分層過程中遇到的一些問題及其解決方案。
三、問題解決
3.1 Apache Doris2.0性能優(yōu)化&問題修復(fù)
為了實(shí)現(xiàn)基于分布式存儲的冷熱數(shù)據(jù)分層,需將Doris集群由1.2版本升級至2.0版本。盡管我們在前期已與社區(qū)共同完成了大量Doris開發(fā)工作,但在具體實(shí)施冷熱數(shù)據(jù)分層過程中,仍遇到了若干問題。以下是幾個(gè)典型問題。
查詢性能下降問題
在性能Diff階段,我們發(fā)現(xiàn),在報(bào)表小查詢場景(平均tp99<20ms)中,Doris 2.0相較于我們之前的Doris 1.2版本,性能下降約50%左右。經(jīng)過分析,我們發(fā)現(xiàn)Doris 2.0的FE默認(rèn)啟用了新的優(yōu)化器,而該優(yōu)化器在SQL Rewrite階段使用了更多的規(guī)則進(jìn)行重寫,從而導(dǎo)致了性能下降。通過進(jìn)一步的壓測、分析以及與社區(qū)的交流,我們得出結(jié)論:除非在Doris 2.0中對新優(yōu)化器進(jìn)行更深層次的優(yōu)化,否則很難使性能達(dá)到Doris 1.2的水平。因此,在我們的應(yīng)用場景中,我們關(guān)閉了Doris 2.0的新優(yōu)化器功能。在使用舊優(yōu)化器的情況下,我們還是遇到了以下性能問題:
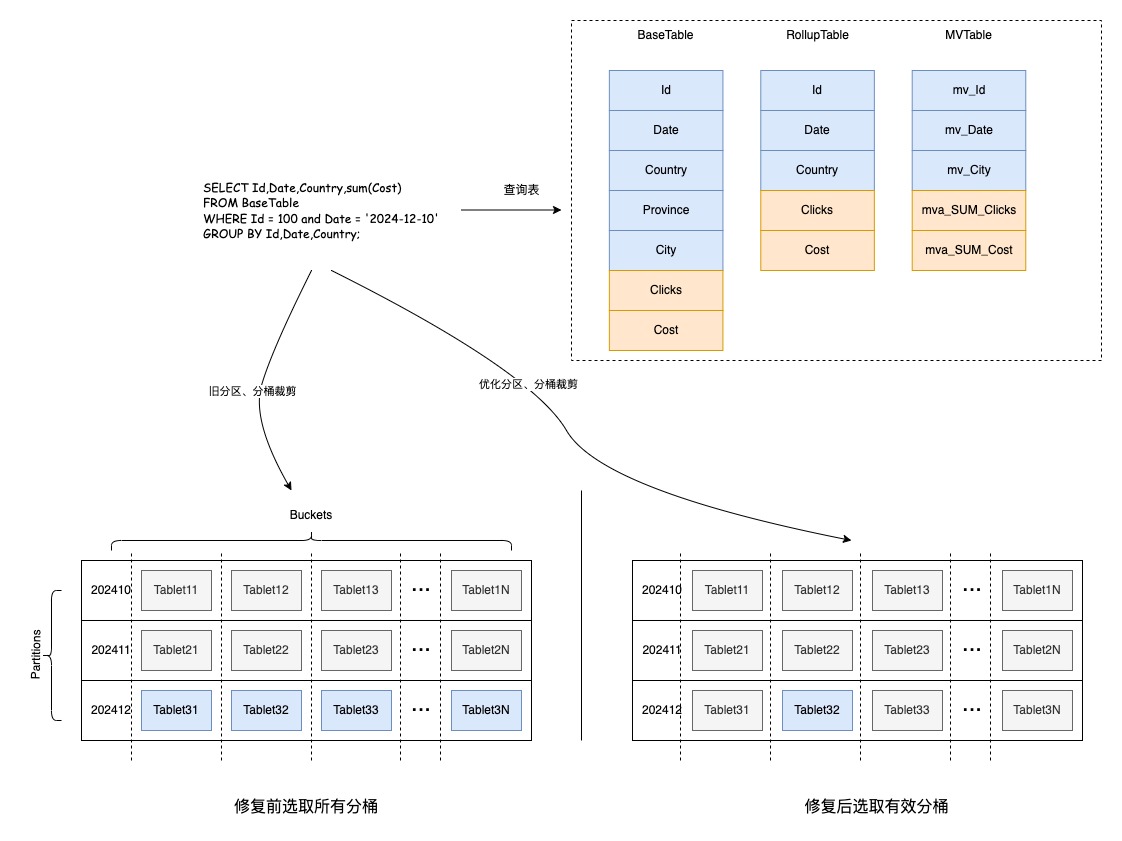
分桶裁剪失效
當(dāng)查詢命中表的Rollup后,底層數(shù)據(jù)掃描量明顯增多,查詢耗時(shí)較1.2明顯升高。查看執(zhí)行計(jì)劃,發(fā)現(xiàn)執(zhí)行計(jì)劃掃描了對應(yīng)分區(qū)下面的所有分桶數(shù)據(jù),分桶裁剪沒有生效。修復(fù)PR:https://github.com/apache/doris/pull/38565
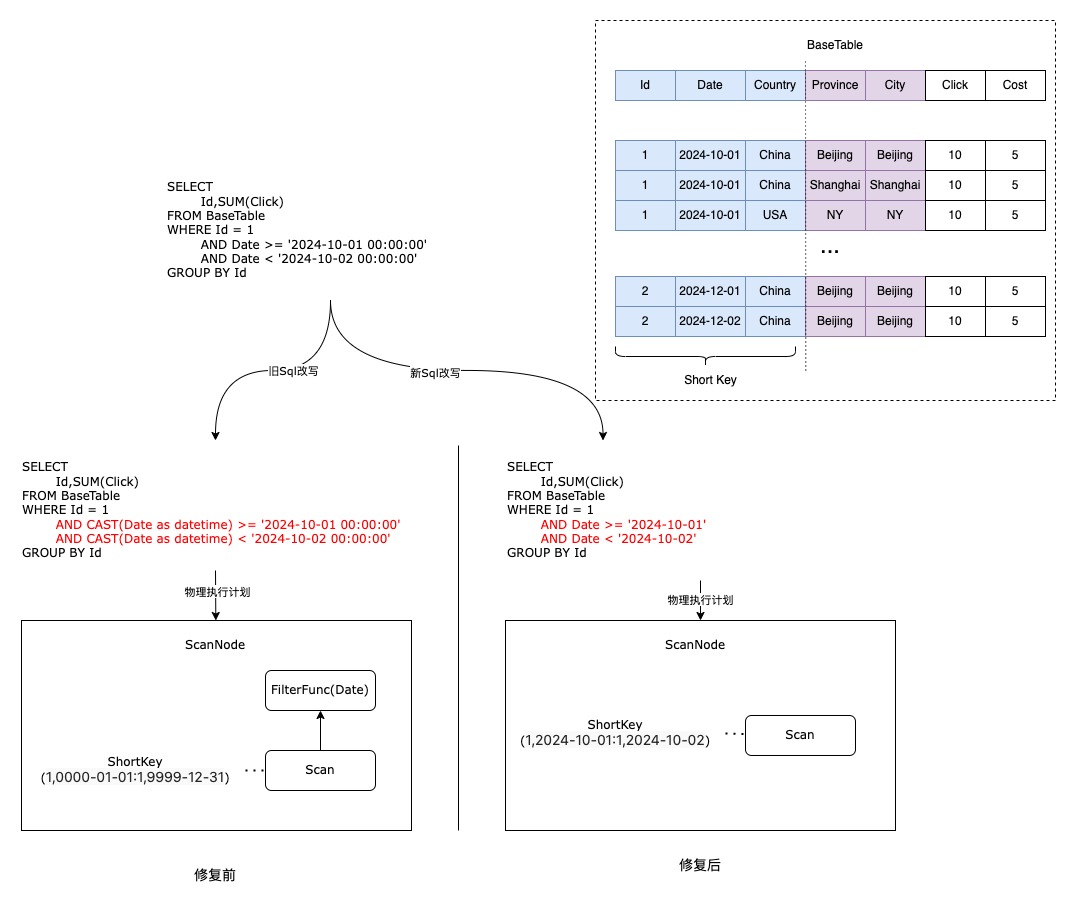
前綴索引失效
當(dāng)從1.2升級到2.0時(shí),升級前于1.2時(shí)創(chuàng)建的Date類型的字段在查詢時(shí)如果將它和DateTime類型(如類似Date>="2024-10-01 00:00:00")進(jìn)行比較,F(xiàn)E會對Date類型進(jìn)行自動(dòng)類型提升(類似CAST(Date as datetime) >= Datetime("2024-10-01 00:00:00"))。 提升后的謂詞在BE處理的時(shí)候和底層數(shù)據(jù)存儲的實(shí)際類型(Date("2024"))不能進(jìn)行比較,導(dǎo)致對應(yīng)前綴索引失效,引起查詢性能大幅下降。這種情況我們通過在FE端進(jìn)行類型對齊進(jìn)行了修復(fù)https://github.com/apache/doris/pull/39446。 修復(fù)后索引生效,性能得到大幅提升。
FE CPU使用率高問題
在對Doris2.0進(jìn)行壓力測試時(shí),觀察到FE節(jié)點(diǎn)的CPU使用率相較于Doris1.2顯著上升,在相同的QPS請求下,Doris2.0的CPU使用率幾乎翻倍。資源消耗明顯增加。在測試過程中,我們對FE節(jié)點(diǎn)進(jìn)行了火焰圖分析,識別出性能消耗較高的函數(shù);同時(shí),我們與社區(qū)成員進(jìn)行了充分的溝通,最終確定了多個(gè)資源消耗點(diǎn),并實(shí)施了相應(yīng)的優(yōu)化措施。
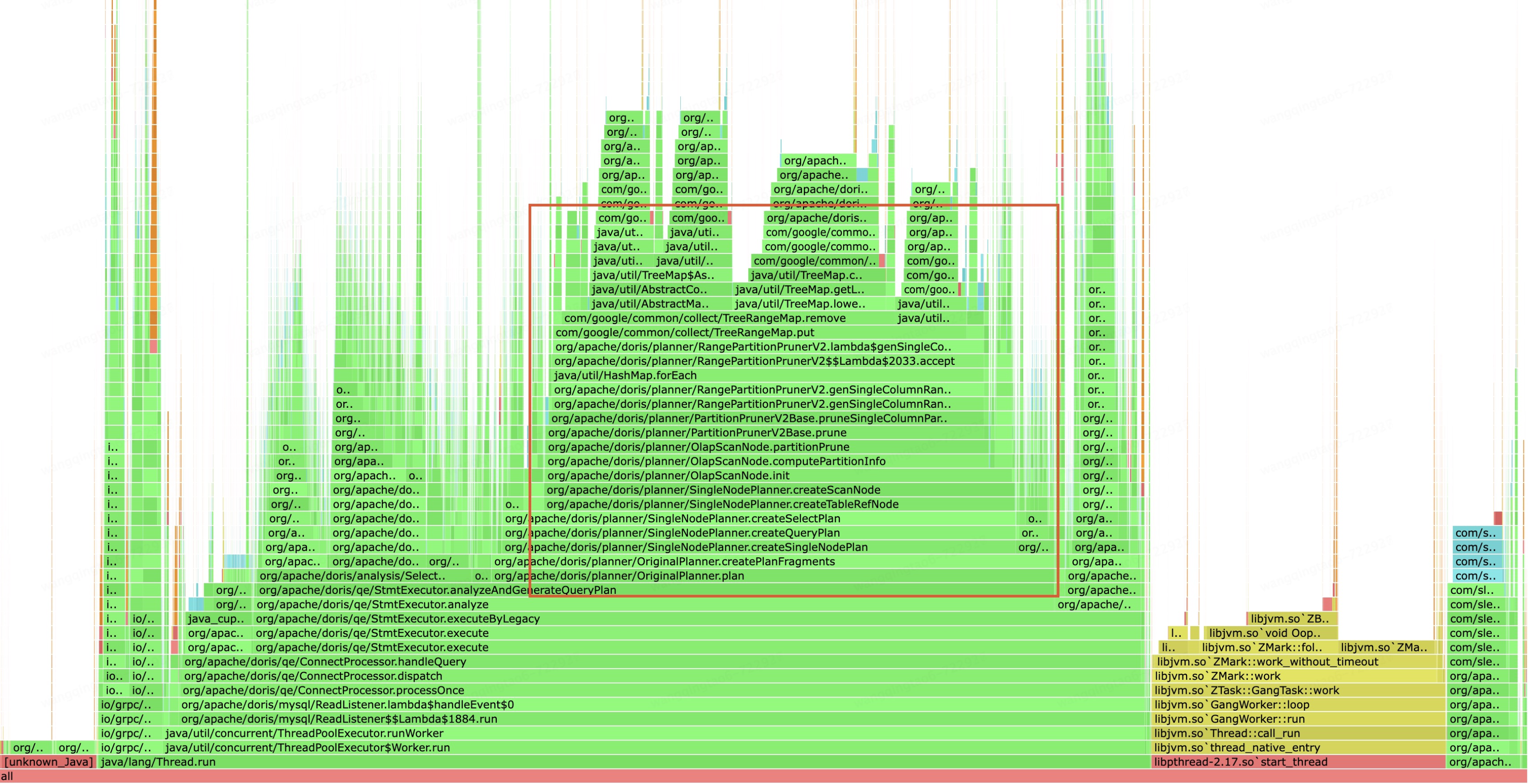
時(shí)間比較效率優(yōu)化
廣告報(bào)表場景下時(shí)間比較操作是幾乎每個(gè)查詢在分區(qū)裁剪時(shí)都會用到,而Doris2.0對時(shí)間的比較需要先轉(zhuǎn)化為字符串再進(jìn)行比較,這種比較沒有直接使用數(shù)據(jù)結(jié)構(gòu)自身的成員變量進(jìn)行比較效率高,這里我們通過PR:https://github.com/apache/doris/pull/31970對分區(qū)裁剪時(shí)的時(shí)間比較操作進(jìn)行了優(yōu)化,優(yōu)化后CPU使用率整體降低25%左右。
物化視圖字段列重寫優(yōu)化
在表有Rollup而沒有物化視圖時(shí),Doris FE對查詢的執(zhí)行計(jì)劃還是會使用只需作用于物化視圖的改寫規(guī)則進(jìn)行優(yōu)化改寫,這些無效的改寫不僅造成CPU利用率提升還會影響查詢延時(shí)。 PR: https://github.com/apache/doris/pull/40000對這種情況進(jìn)行優(yōu)化,在無物化視圖情況下避免無意義的執(zhí)行計(jì)劃改寫。
此外,我們還通過使用for循環(huán)代替流操作、關(guān)鍵路徑減少日志輸出等進(jìn)行了CPU使用率優(yōu)化,最總Doris 2.0 FE CPU消耗最終達(dá)到1.2版本等同水平。
BE 內(nèi)存使用率高
在對 Doris 2.0 版本的集群使用過程中,發(fā)現(xiàn)BE內(nèi)存使用率會極緩慢持續(xù)升高,長期使用的情況下,Doris BE 階段存在 OOM 風(fēng)險(xiǎn)。排查該現(xiàn)象和 SegmentCache的配置有關(guān):
Doris2.0使用了SegmentCache,用于對底層數(shù)據(jù)文件對象緩存。但2.0對于SegmentCache的內(nèi)存使用計(jì)算存在問題且默認(rèn)閾值設(shè)置過大,導(dǎo)致一直觸發(fā)不到SegmentCache使用閾值;隨著segment文件數(shù)量的增加,SegmentCache使用量會越來越大。結(jié)合日常內(nèi)存使用量的評估及壓測驗(yàn)證,我們重新調(diào)整了合理的SegmentCache使用閾值;在保證Cache命中率基本不變的情況下降BE常駐內(nèi)存使用率從 60%以上降低到25%一下,有效避免了 BE 節(jié)點(diǎn) OOM的風(fēng)險(xiǎn)。
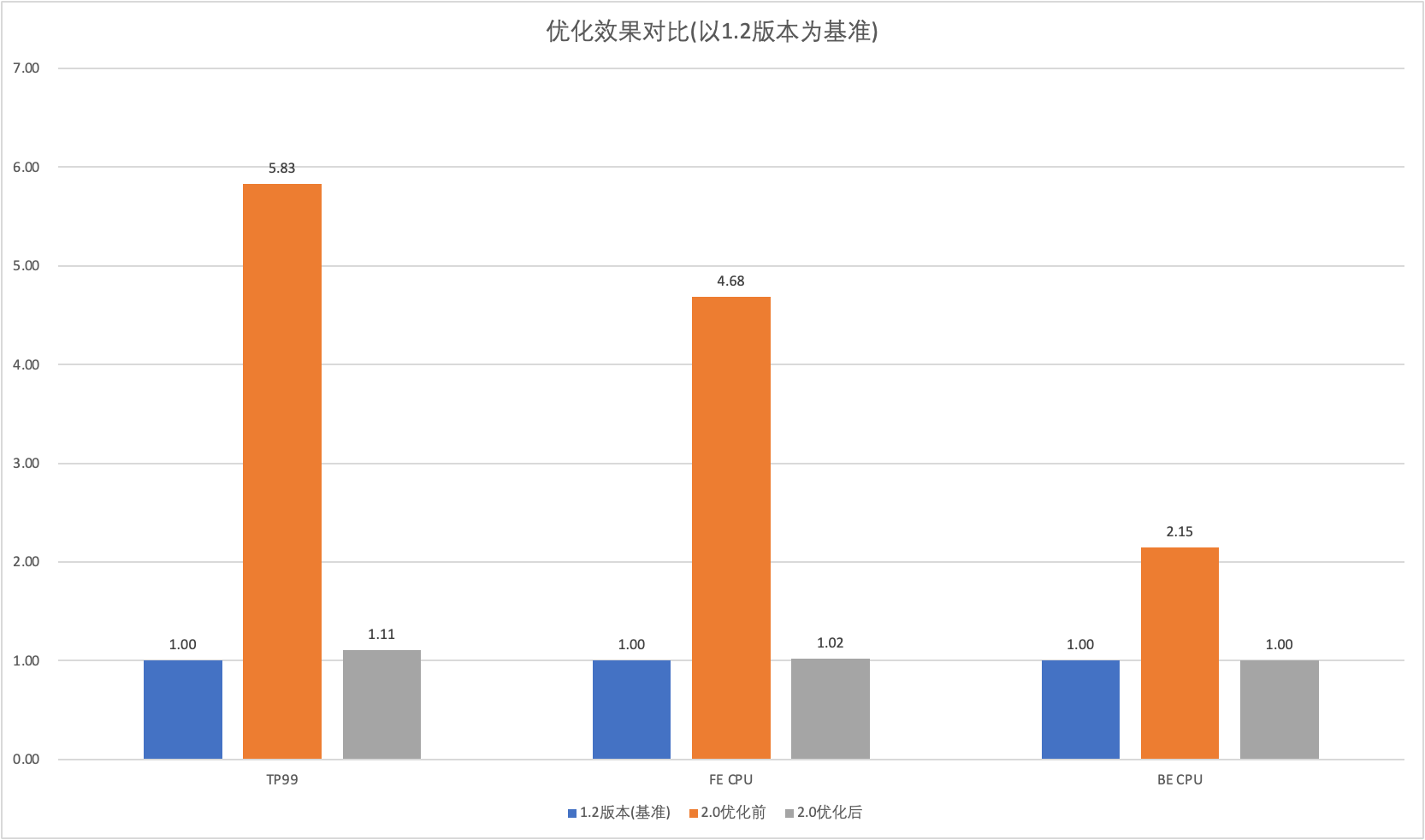
經(jīng)過一系列優(yōu)化后,2.0版本查詢性能參數(shù)(TP99耗時(shí)、FECPU消耗、BE CPU消耗)有了較大優(yōu)化,基本和1.2版本對齊。
3.2 冷數(shù)據(jù) Schema Change(SC)優(yōu)化
Schema Change(SC) 是Apache Doris等實(shí)時(shí)數(shù)倉日常使用當(dāng)中的高頻操作,其中,Add Key Column 的操作是廣告數(shù)據(jù)報(bào)表中使用較多的場景,實(shí)踐中發(fā)現(xiàn)冷數(shù)據(jù)添加 Key 列的SC操作存在如下問題:
1.Schema Change 退化:冷數(shù)據(jù)的Add Key Column 操作會退化成Direct Schema Change(DSC);DSC操作比較重,需要對全量數(shù)據(jù)進(jìn)行重新讀取和寫入。在實(shí)際使用過程中對于含大量冷數(shù)據(jù)的表進(jìn)行 Add Key Column 操作需要重新對遠(yuǎn)端海量數(shù)據(jù)進(jìn)行讀寫,增大系統(tǒng)IO負(fù)載的同時(shí),SC 任務(wù)耗時(shí)也很長。實(shí)踐中一張冷數(shù)據(jù)量20T左右的表,整個(gè)SC耗時(shí)在7天以上,對于需要緊急上線的業(yè)務(wù)體感極差。
2.數(shù)據(jù)冗余:冷數(shù)據(jù)Schema Change(SC)時(shí),Tablet 的每個(gè)副本都會獨(dú)立進(jìn)行 SC 操作,導(dǎo)致原來冷數(shù)據(jù)單副本存儲在SC后變成多副本,冷數(shù)據(jù)存儲資源浪費(fèi)嚴(yán)重。
為了優(yōu)化和修復(fù)上述冷數(shù)據(jù) Schema Change 遇到的問題,我們對冷數(shù)據(jù)的 Schema Change 進(jìn)行了如下優(yōu)化:
實(shí)現(xiàn)冷數(shù)據(jù) Linked Schema Change
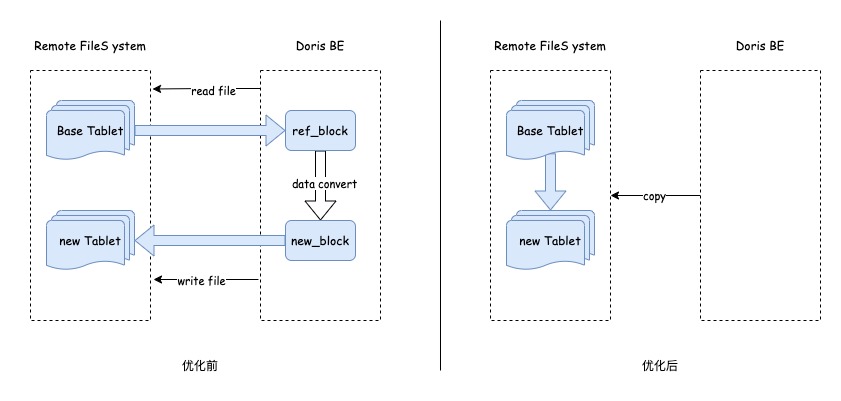
針對冷數(shù)據(jù) Add Key Column類型的SC 退化成 Direct Schema Change 導(dǎo)致 SC 任務(wù)執(zhí)行緩慢的問題,我們對冷數(shù)據(jù)Add Key Column類型SC的流程進(jìn)行深度優(yōu)化,利用遠(yuǎn)端存儲系統(tǒng)(ChubaoFS)的CopyObject接口,實(shí)現(xiàn)在遠(yuǎn)端直接進(jìn)行數(shù)據(jù)復(fù)制,避免數(shù)據(jù)文件從遠(yuǎn)端拉取到Apache Doris,經(jīng)數(shù)據(jù)重寫后再存儲到遠(yuǎn)端存儲系統(tǒng)的巨大IO開銷。該優(yōu)化減少了兩次網(wǎng)絡(luò)傳輸和一次數(shù)據(jù)轉(zhuǎn)換的開銷,這樣能夠極大加速Add Key Column場景下冷數(shù)據(jù)Schema Change的執(zhí)行速度。經(jīng)測算優(yōu)化后SC執(zhí)行速度提升40倍, 相關(guān)PR已合并社區(qū)2.0分支:https://github.com/apache/doris/pull/40963。
實(shí)現(xiàn)冷數(shù)據(jù)單副本SC
Apache Doris 2.0中冷數(shù)據(jù)在進(jìn)行Schema Change時(shí),同一份數(shù)據(jù)的多個(gè)副本之間相互獨(dú)立進(jìn)行(SC)。如此, Schema Change完成后造成冷數(shù)據(jù)將在遠(yuǎn)端存儲存在多份,造成存儲資源浪費(fèi)的同時(shí)也降低SC任務(wù)執(zhí)行效率。為了解決這個(gè)問題,參考Raft協(xié)議對冷數(shù)據(jù)多副本SC場景進(jìn)行了優(yōu)化。即SC只在選舉出來的Leader副本上執(zhí)行,非Leader副本只生成元數(shù)據(jù)。
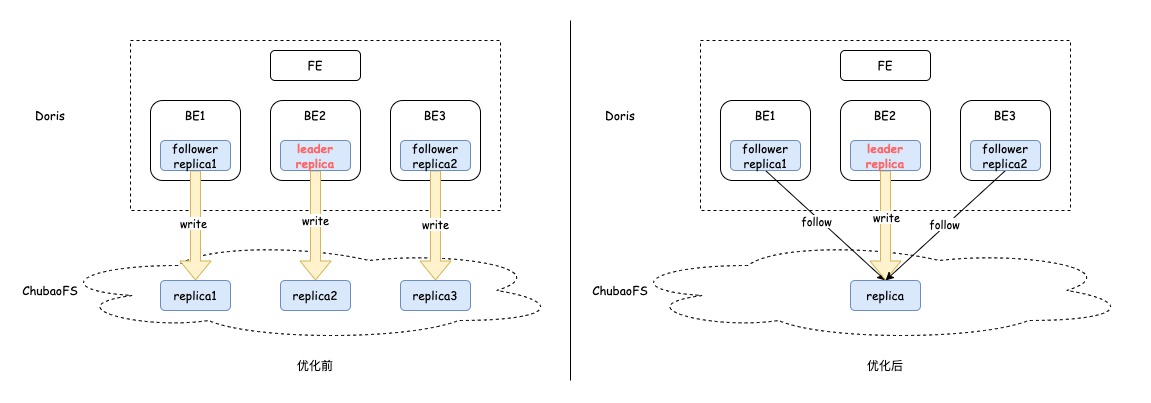
我們已成功解決了SC后數(shù)據(jù)副本冗余的問題。然而,仍存在一個(gè)潛在風(fēng)險(xiǎn):FE會定期檢查BE上的tablet SC操作是否正常。我們允許不超過半數(shù)的tablet副本SC失敗,即使BE上的Leader副本SC失敗,整個(gè)SC任務(wù)仍可能成功。因此,若Leader副本在復(fù)制數(shù)據(jù)時(shí)失敗,可能會導(dǎo)致數(shù)據(jù)丟失。為避免這種情況,我們在FE對Schema Change任務(wù)的健康度判斷時(shí),特別考慮了冷數(shù)據(jù)的“Linked Schema Change”。只有當(dāng)tablet的Leader副本成功時(shí),SC才會被視為成功。這樣可以確保數(shù)據(jù)的完整性和一致性。
實(shí)現(xiàn)冷數(shù)據(jù)的Light Schema Change
對于存量表中可以直接使用Light Schema Change的表,我們希望更進(jìn)一步支持一種冷數(shù)據(jù)Light Schema Change;如果走Light Schema Change,則只需要修改FE 元數(shù)據(jù)信息,不需要進(jìn)行BE端任務(wù)創(chuàng)建及數(shù)據(jù)文件處理;處理時(shí)間會達(dá)到毫秒級。
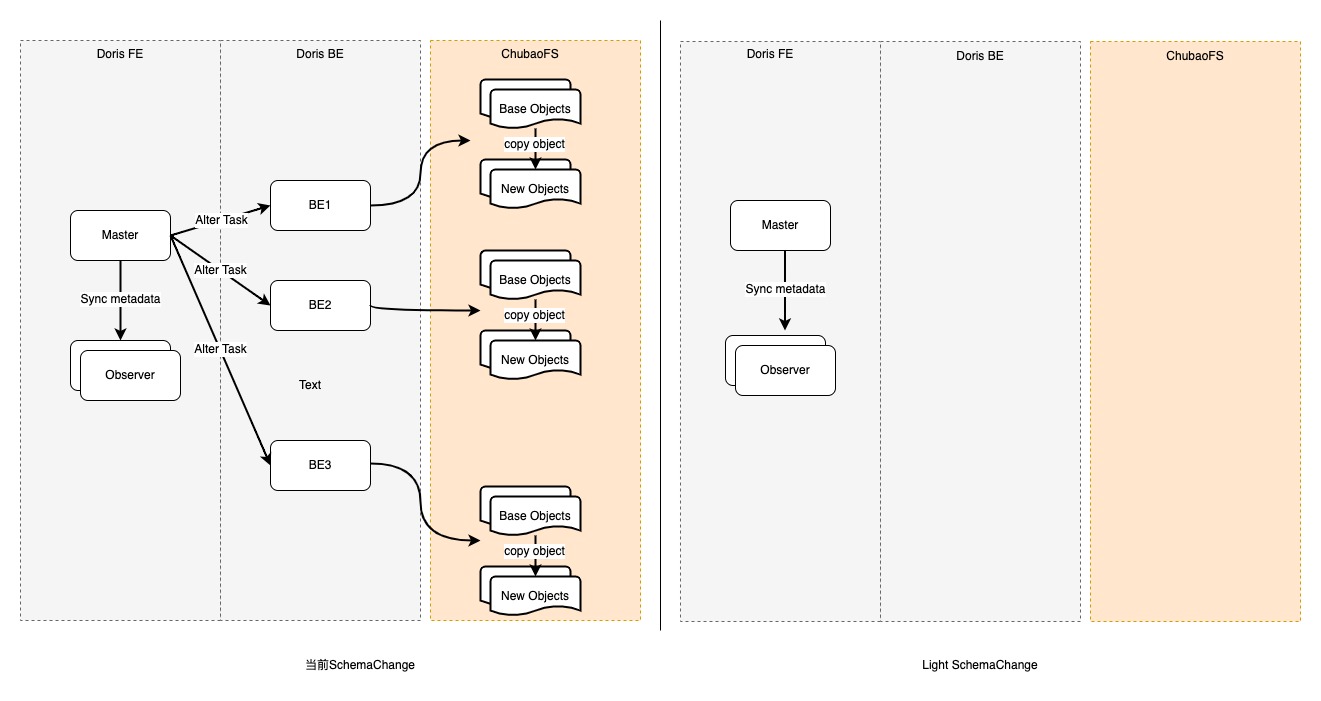
當(dāng)前Light Schema Change只支持Value列字段的添加,不支持Key列字段添加。但對于不涉及分區(qū)、分桶、前綴索引的普通Key列;可以按照Light Schema Change的邏輯進(jìn)行處理。這里對這一功能進(jìn)行了升級。主要改動(dòng)在FE階段Light Schema Change判斷階段,支持對Key列添加的邏輯。以滿足較普通的添加Key列操作。
3.3 其他問題解決
隨著整體數(shù)據(jù)量持續(xù)增長,在引入冷熱數(shù)據(jù)分層方案之前,為緩解線上存儲資源緊缺的現(xiàn)狀,我們將 Doris 歷史數(shù)據(jù)通過 backup 的方式結(jié)轉(zhuǎn)到外部存儲,維持 Doris 集群安全的存儲水位。完成Doris2.0版本升級后,再將結(jié)轉(zhuǎn)的歷史數(shù)據(jù)重新恢復(fù)至 Doris 集群。為了便捷高效地操作歷史數(shù)據(jù),我們實(shí)現(xiàn)了一套統(tǒng)一的結(jié)轉(zhuǎn)和恢復(fù)工具,工具解決了如下三個(gè)問題:
1.歷史數(shù)據(jù)總量大,底表數(shù)量多,如何準(zhǔn)確高效地結(jié)轉(zhuǎn)這些數(shù)據(jù)?
2.歷史數(shù)據(jù)持續(xù)結(jié)轉(zhuǎn),線上表schema持續(xù)變更,如何將這部分 schema 不一致的數(shù)據(jù)重新恢復(fù)?
3.如何實(shí)現(xiàn)統(tǒng)一的冷熱數(shù)據(jù)分層和熱數(shù)據(jù)自動(dòng)冷卻?
為解決第一個(gè)數(shù)據(jù)結(jié)轉(zhuǎn)的問題,我們實(shí)現(xiàn)了一個(gè)歷史數(shù)據(jù)自動(dòng)結(jié)轉(zhuǎn)工具data migrator。支持將線上集群所有DB任意時(shí)間段內(nèi)的數(shù)據(jù)異步并行結(jié)轉(zhuǎn)至外部離線存儲。
Doris2.0完成升級后啟動(dòng)建設(shè)冷熱數(shù)據(jù)分層,首先需要將結(jié)轉(zhuǎn)至外部存儲的歷史數(shù)據(jù)恢復(fù)至線上環(huán)境。此時(shí)遇到的最大問題是線上表結(jié)構(gòu)已發(fā)生多次變更,導(dǎo)致多次結(jié)轉(zhuǎn)的歷史數(shù)據(jù)備份snapshot文件所對應(yīng)的schema結(jié)構(gòu)與線上表不一致。為了解決schema不一致的問題,我們設(shè)計(jì)開發(fā)了一套自動(dòng)化數(shù)據(jù)恢復(fù)工具narwal_cli,如下圖中Data Restore Process過程所示,narwal_cli工具支持自動(dòng)對齊歷史結(jié)轉(zhuǎn)數(shù)據(jù)和Doris 集群中數(shù)據(jù)的的schema,并定向恢復(fù)至線上環(huán)境。
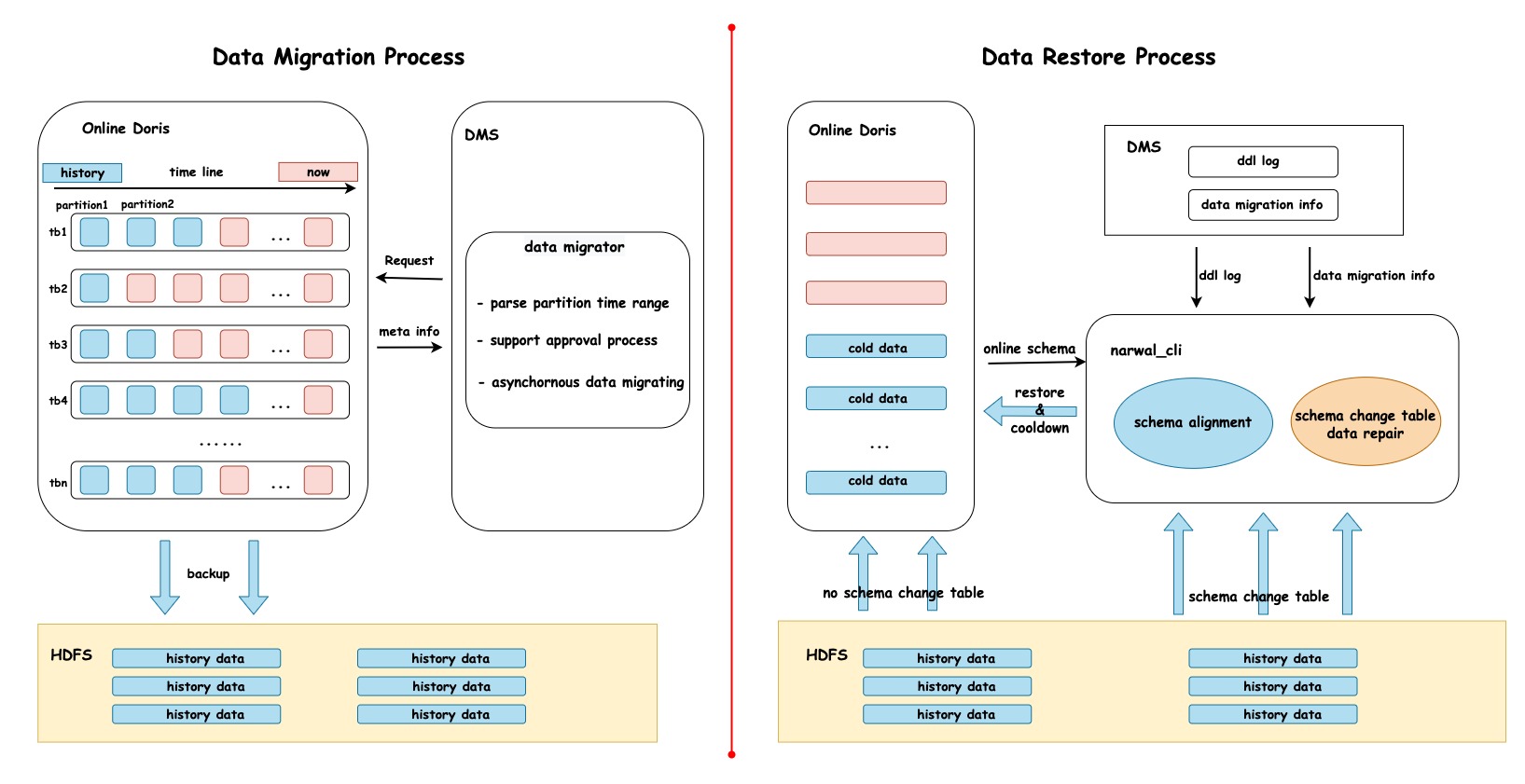
在實(shí)施恢復(fù)過程中,還遇到Flink2Doris實(shí)時(shí)寫入任務(wù)失敗的情況,具體信息如下:LOAD_RUN_FAIL; msg:errCode = 2, detailMessage = Table xxxxx is in restore process. Can not load into it經(jīng)排查,問題原因是Doris表在restore過程中伴隨實(shí)時(shí)數(shù)據(jù)寫入,寫入會對表當(dāng)前的meta info進(jìn)行check,但狀態(tài)檢測粒度較粗,僅檢測tableState而未進(jìn)一步檢測partitionState,造成狀態(tài)誤判,進(jìn)而影響了寫入任務(wù)。問題定位后迅速完成修復(fù)和發(fā)版上線,詳細(xì)信息可參考pr:https://github.com/apache/doris/pull/39595。以上問題解決后,在線上環(huán)境快速準(zhǔn)確地恢復(fù)了所有歷史數(shù)據(jù),且工具兼顧易用性,做到隨時(shí)啟停、斷點(diǎn)續(xù)傳。
在我們的應(yīng)用場景中,我們對歷史恢復(fù)的數(shù)據(jù)和線上的數(shù)據(jù)分別設(shè)置了不同的冷熱分層策略:我們將歷史數(shù)據(jù)的storage_policy設(shè)置為cooldown_ttl=10s,實(shí)現(xiàn)歷史數(shù)據(jù)立刻冷卻至ChubaoFS。對全量熱數(shù)據(jù)則統(tǒng)一設(shè)置了cooldown_ttl=2years,實(shí)現(xiàn)線上熱數(shù)據(jù)隨著兩年時(shí)間窗口推進(jìn)自動(dòng)冷卻。整個(gè)歷史數(shù)據(jù)的恢復(fù)和冷卻全過程,做到對線上業(yè)務(wù)透明,準(zhǔn)確高效地實(shí)現(xiàn)全量歷史數(shù)據(jù)恢復(fù)和冷卻。同時(shí),在冷卻數(shù)據(jù)過程中發(fā)現(xiàn)冷熱數(shù)據(jù)策略設(shè)置異常問題,進(jìn)行了修復(fù),參考pr:https://github.com/apache/doris/pull/35270。實(shí)現(xiàn)統(tǒng)一的冷熱分層和自動(dòng)冷卻后,后續(xù)存儲數(shù)據(jù)量繼續(xù)保持增長,也無需再擴(kuò)容線上存儲資源,僅需擴(kuò)容較低成本的外部離線存儲即可,實(shí)現(xiàn)計(jì)算資源利用率提升的同時(shí),存儲經(jīng)濟(jì)成本大幅降低。
除了以上優(yōu)化,我們還在為 Apache Doris 在讀寫性能提升、問題修復(fù)、功能完善等方面積極貢獻(xiàn),已為社區(qū) 2.0 版本提交并合并 30+ PR。
四、小結(jié)
通過對數(shù)據(jù)進(jìn)行冷熱分層,我們的存儲成本降低了約87%。對比Doris 1.2的冷數(shù)據(jù)入湖方案與Doris 2.0的冷數(shù)據(jù)分層方案,后者在并發(fā)查詢能力上提升了超過10倍,查詢延遲顯著減少。此外,冷熱數(shù)據(jù)分層方案簡化了存儲和查詢的維護(hù)工作,降低了整體復(fù)雜性和成本。冷熱分層架構(gòu)的成功實(shí)施,離不開Apache Doris社區(qū)和中臺OLAP團(tuán)隊(duì)的鼎力支持,特此向所有Apache Doris社區(qū)和中臺OLAP團(tuán)隊(duì)的成員表示衷心的感謝。展望未來,我們期待繼續(xù)與Apache Doris社區(qū)和中臺OLAP團(tuán)隊(duì)在京東廣告場景中開展緊密合作,共同探索存算分離架構(gòu)在該場景中的實(shí)際應(yīng)用。
審核編輯 黃宇
-
數(shù)據(jù)存儲
+關(guān)注
關(guān)注
5文章
999瀏覽量
51738 -
京東
+關(guān)注
關(guān)注
2文章
1024瀏覽量
49272
發(fā)布評論請先 登錄
Apache Doris聚合函數(shù)源碼解析
如何在ARMX64平臺上編譯Doris
如何使用Apache Spark中的DataSource API以實(shí)現(xiàn)數(shù)據(jù)源混合計(jì)算的實(shí)踐
企業(yè)實(shí)踐 | 如何更好地使用 Apache Flink 解決數(shù)據(jù)計(jì)算問題?
京東金融APP就短視頻廣告爭議正式致歉
京東再次為低俗廣告道歉 京東金融低俗借貸廣告被吐槽
利用Apache Spark和RAPIDS Apache加速Spark實(shí)踐
Apache Doris正式成為 Apache 頂級項(xiàng)目
利用KoP如何將Pulsar數(shù)據(jù)快速且無縫接入Apache Doris
中國開源社區(qū)健康案例——Apache Doris社區(qū)
Apache Doris冷熱分層技術(shù)對數(shù)據(jù)存儲有何好處
如何快速實(shí)現(xiàn)MySQL到Doris的高容量數(shù)據(jù)同步
生成式推薦系統(tǒng)與京東聯(lián)盟廣告-綜述與應(yīng)用
啟明信息完成國產(chǎn)化Doris數(shù)據(jù)庫升級替代任務(wù)
大模型時(shí)代下的新一代廣告系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論