 《機器學習訓練秘籍》:書中選出了7條非常有用的建議
《機器學習訓練秘籍》:書中選出了7條非常有用的建議
《機器學習訓練秘籍》(Machine Learning Yearning)是吳恩達的新作,主要講的是如何應用機器學習算法以及如何構建機器學習項目。本文從這本書中選出了 7 條非常有用的建議。
近年來,人工智能、機器學習和深度學習迅猛發展,給許多行業帶來了變革。吳恩達是業內的領軍人物之一,他是在線課程項目 Coursera 的聯合創始人,前百度 AI Group 領導人,前 Google Brain 項目負責人。目前他正在編寫《機器學習訓練秘籍》(http://www.mlyearning.org/)這本書,教讀者如何組織機器學習項目。
吳恩達在書中寫道:
這本書主要是教你如何應用機器學習算法,而不是教你機器學習算法本身。一些AI技術課程會教你算法,而這本書旨在教你如何使用算法這個利器。如果你想成為 AI領域的技術領袖,并希望學習如何為你的團隊設定方向,這本書會給你幫助。
我們在閱讀這本書的原稿后從中選出了 7 條有趣且實用的建議.
▌1. 選擇正確的評估指標
在評估某個算法時,不應該只使用一個公式或指標,而應使用多個評估指標。其中一種方法就是使用“optimizing”和“satisfying”作為指標。
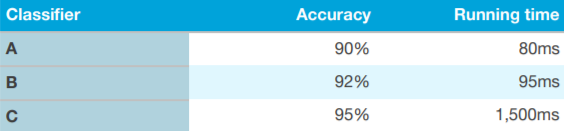
以上圖為例,首先定義一個“acceptable”(可接受)的運行時間(例如小于 100 毫秒),作為“satisfying”指標。只要運行時間低于這個指標,你的分類器就「很好」。“準確度”在這里作為“optimizing”指標。這是一種非常有效且容易的算法評估方法。
▌2. 快速選擇開發/測試集——如果有必要不要害怕更換
當開始一個新項目時,吳恩達在書中解釋道他會很快選擇開發集/測試集,因為這樣可以給團隊制定一個明確的目標。開始時他會先制定第一周的目標,提出一個不太完美的方案并迅速行動起來,比花過多時間思考更好。
如果你突然發現初始的開發/測試集不正確時,不要害怕更改它們。以下是書中給出的開發/訓練集不正確的三個可能原因:
要使用的實際數據分布和開發/測試集不同
開發/測試集過度擬合
評估指標衡量的并不是項目所需要優化的東西
請謹記,更改開發/測試集不是什么大問題。放心更改,讓你的團隊知道你們的新方向。
▌3. 機器學習是一個迭代過程:不要指望第一次就成功
吳恩達寫道他開發機器學習軟件的過程分三步:
從一個想法開始
用代碼實現這個想法
通過實驗判斷這個想法是否成功
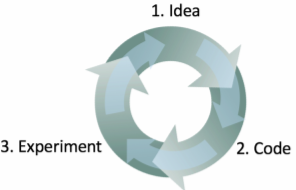
這是一個不斷迭代的過程。循環得越快,進展也就越快。這就是為什么提前確定開發/測試集很重要,因為這樣做可以在這個迭代過程中省下寶貴的時間。每嘗試一個新想法時,在開發/測試集上衡量這個想法的表現,這樣你就可以快速判斷你是否在朝著正確的方向前進。
▌4. 快速構建第一個系統,然后迭代
在第三條建議中,我們提到構建機器學習算法是一個迭代過程。吳恩達專門用一個章節解釋了快速構建第一個系統然后迭代的好處:「不要試圖一開始就設計和構建完美的系統。相反,應該快速構建和訓練出一個基本系統——也許在短短的幾天內。即使這個基本系統與您你構建的“最佳”系統相差甚遠,研究基本系統的表現仍非常有參考價值:你很快就會找到線索,以此確定哪個方向最有希望獲得成功。」
▌5. 并行評估多個想法
當你的團隊針對如何改進某一算法提出了很多想法,你可以高效地并行評估這些想法。舉例來說,構建一個能識別貓照片的算法,吳恩達稱他通常會創建一個電子表格,瀏覽大約 100 張分類錯誤的開發/測試集圖像并在表格上記錄。

在表格上記錄:對每張圖像的分析,造成算法分類錯誤的原因,以及可能對未來反思有幫助的評論。填完后,你會得出哪種想法可以避免更多錯誤,然后再去實現它。
▌6. 思考清理貼錯標簽的開發/測試集是否值得
在錯誤分析期間,你可能會注意到開發/測試集中的一些樣本被錯誤標注(mislabeled)。也就是說,在用算法處理前之前,圖片已經被人類標注員貼上了錯誤的標簽。如果你懷疑有一小部分的圖片被錯誤標注是由于這個原因,那么可以在電子表格中添加再一個類別進行記錄:

在完成后,你可以思考修正這些錯誤是否值得。吳恩達給出了兩種可能的場景,讓讀者判斷修正錯誤是否值得:
示例1:
開發集的整體準確率……90%(整體錯誤率為 10%)
貼錯標簽樣本導致的錯誤……0.6%(占開發集錯誤的 6%)
其他原因導致的錯誤……9.4%(占開發集錯誤的 94%)
在這個例子中,相較于你可能改進的 9.4% 的錯誤,由于錯誤標注導致的 0.6% 的不準確率就可能沒那么重要。手動修正開發集中錯誤標注的圖像并沒有什么壞處,但這樣做并不是關鍵:不知道系統的整體錯誤是 10% 還是 9.4% 可能沒什么大不了。
示例 2:
開發集整體準確率……98.0%(整體錯誤率為 2.0%)
貼錯標簽樣本導致的錯誤……0.6%(占開發集錯誤的 30%)
其他原因導致的錯誤……1.4%(占開發集錯誤的 70%)
30% 的錯誤是由于錯誤標注的開發集圖像造成的,這會讓準確率的估計值有很大的誤差。這種情況下,改進開發集的標注質量很值得。處理錯誤標注的樣本將幫助你算出分類器的錯誤是接近 1.4% 還是 2%——這是一個相對明顯的差異。
▌7. 考慮將開發集分為多個子集
如果你的開發集很大,其中 20% 的樣本被算法錯誤分類,那么你可以將這個開發集分為兩個獨立的子集:
比方說,你有一個包含 5000 個樣本的大開發集,其中 1000 個樣本被錯誤分類。假設我們要手動檢查約 100 個錯誤樣本(錯誤樣本的10%),進行錯誤分析。那么你應該隨機選出 10% 的開發集,然后將其放入我們稱之為 Eyeball 的開發集(Eyeball dev set)中,以提醒自己你需要觀察這些數據。Eyeball 開發集有 500 個樣本,我們預計算法錯誤分類的樣本約有 100 個。
開發集的第二個子集叫做 Blackbox 開發集(Blackbox dev set),它包含剩余的 4500 個樣本。你可以用 Blackbox 開發集測定圖像分類的錯誤率,以此自動評估分類器。你也可以使用它來選擇算法或調整超參數。我們將這個子集稱為 “Blackbox”,是因為我們只使用數據集的子集來取得對分類器的“Blackbox”(黑盒)評估。
-
人工智能
+關注
關注
1804文章
48798瀏覽量
247098 -
機器學習
+關注
關注
66文章
8495瀏覽量
134181
原文標題:吳恩達《機器學習訓練秘籍》:7 條關于項目實踐的實用建議
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
對新手非常有用的電子器件基礎資料
機器學習訓練秘籍——吳恩達
展示Python機器學習開源項目以及在分析過程中發現的非常有趣的見解和趨勢

機器學習-8. 支持向量機(SVMs)概述和計算
17個非常有用的 Python 技巧

Vim中默認未啟用但實際非常有用的選項
《機器學習訓練秘籍》中的六個概念
機器學習/人工智能領域一些非常有創意的突破
機器學習對分析地理空間圖像非常有幫助
17個非常有用的Python技巧
一個簡單但非常有用的小前置放大器電路
沒有什么是完美的,但FPGA可能非常有用





 工商網監
工商網監
評論