") 如何有效的融合醫(yī)學(xué)領(lǐng)域知識(shí)和機(jī)器學(xué)習(xí)方法
如何有效的融合醫(yī)學(xué)領(lǐng)域知識(shí)和機(jī)器學(xué)習(xí)方法
AI在醫(yī)療中的應(yīng)用場(chǎng)景十分復(fù)雜也十分重要,包括疾病的診斷、預(yù)測(cè)、治療和管理等。有感于 “搞人工智能技術(shù)的人不知道醫(yī)療里重要又可解的問題是什么,搞醫(yī)療的人不知道技術(shù)究竟能幫到什么程度”,前 IBM 認(rèn)知醫(yī)療研究總監(jiān)、平安醫(yī)療科技研究院副院長(zhǎng)謝國彤博士針對(duì)疾病預(yù)測(cè)技術(shù)的核心概念、主要方法和發(fā)展趨勢(shì),帶來詳細(xì)解讀。
去年寫了《我看到的靠譜醫(yī)療 AI 應(yīng)用場(chǎng)景和關(guān)鍵技術(shù)》,原本計(jì)劃要寫個(gè) “連續(xù)劇” 的,后來諸多事情就耽誤了。一晃快一年了,現(xiàn)在推出第二篇,疾病預(yù)測(cè)技術(shù)的概念、方法和趨勢(shì),淺析前文中提到的疾病預(yù)測(cè)技術(shù)的核心概念、主要方法和發(fā)展趨勢(shì)。
疾病預(yù)測(cè)的核心概念
疾病風(fēng)險(xiǎn)預(yù)測(cè)核心解決的問題是預(yù)測(cè)個(gè)體在未來一段時(shí)間內(nèi)患某種疾病(或發(fā)生某種事件)的風(fēng)險(xiǎn)概率。疾病預(yù)測(cè)會(huì)根據(jù)某個(gè)人群定義,例如全人群、房顫人群、心梗住院人群等,針對(duì)某個(gè)預(yù)測(cè)目標(biāo),例如腦卒中、心衰、死亡等,設(shè)定特定的時(shí)間窗口,包括做出預(yù)測(cè)的時(shí)間點(diǎn),和將要預(yù)測(cè)的時(shí)間窗,預(yù)測(cè)目標(biāo)的發(fā)生概率。
利用真實(shí)世界數(shù)據(jù)進(jìn)行疾病預(yù)測(cè)面臨如下一些技術(shù)挑戰(zhàn):
數(shù)據(jù)質(zhì)量差:電子病歷數(shù)據(jù)中很多字段有缺失,導(dǎo)致關(guān)鍵特征無法提取;甚至有無意或有意的輸入錯(cuò)誤,給數(shù)據(jù)分析造成了噪音。
數(shù)據(jù)維度高:醫(yī)療的數(shù)據(jù)涉及患者的病情主訴、既往病史、家族遺傳史、個(gè)人史、體格檢查信息、診斷、檢驗(yàn)、檢查、用藥和手術(shù)等方面。一個(gè)疾病登記庫中每位患者的數(shù)據(jù)往往達(dá)到 2000 維,而真實(shí)電子病歷的數(shù)據(jù)甚至?xí)_(dá)到幾萬維。如此高維度、稀疏的數(shù)據(jù)給預(yù)測(cè)帶來了挑戰(zhàn)。
數(shù)據(jù)時(shí)序性:患者在一段時(shí)間內(nèi)會(huì)有持續(xù)的醫(yī)療記錄,如住院期間的多次記錄,或者一年內(nèi)的多次門診記錄。如果涉及可穿戴式設(shè)備收集的實(shí)時(shí)數(shù)據(jù),更是每分每秒都在變化。為了從數(shù)據(jù)中更好的提煉預(yù)測(cè)信號(hào),必須對(duì)數(shù)據(jù)的時(shí)間序列信息進(jìn)行分析挖掘。
數(shù)據(jù)不均衡:很多疾病的發(fā)病率都不高,比如房顫患者發(fā)生腦卒中的平均概率是 10%,腦卒中患者出院后導(dǎo)致殘疾的平均概率是 4%。造成數(shù)據(jù)中正例相對(duì)較少,很不均衡,對(duì)機(jī)器學(xué)習(xí)算法的要求更高。
疾病預(yù)測(cè)的主要方法
疾病預(yù)測(cè)的主要方法可以簡(jiǎn)單的分為經(jīng)典回歸方法、機(jī)器學(xué)習(xí)方法和深度學(xué)習(xí)方法三大類。下面分別用三篇論文舉例介紹一下。
基于經(jīng)典回歸方法的疾病預(yù)測(cè)
傳統(tǒng)的疾病風(fēng)險(xiǎn)預(yù)測(cè)主要基于 Cox 比例風(fēng)險(xiǎn)回歸模型(簡(jiǎn)稱 Cox 模型)及邏輯回歸模型。例如,[Wang et al. 2003] 發(fā)表于 JAMA 的文章利用 Cox 模型,基于弗雷明漢(Framingham)心臟研究來建立房顫患者發(fā)生腦卒中及死亡的風(fēng)險(xiǎn)預(yù)測(cè)模型,方法流程見圖 1。該研究用患者在確診房顫前最近一次檢查的數(shù)據(jù)作為風(fēng)險(xiǎn)因素的基線數(shù)據(jù),觀測(cè)的起點(diǎn)為房顫確診,觀測(cè)時(shí)間窗為 10 年。基于之前房顫預(yù)測(cè)腦卒中的研究,兩個(gè)非常重要的連續(xù)變量,即年齡和收縮壓被直接放入了多變量模型。其他的風(fēng)險(xiǎn)因子采用逐步回歸法確定,符合檢驗(yàn)標(biāo)準(zhǔn) P<0.10 的變量會(huì)被放入模型,包括服用抗壓藥物、有心肌梗塞或充血性心臟衰竭病史(在確診房顫前)、有卒中或短暫性腦缺血發(fā)作史(在確診房顫前)、吸煙、心電圖判斷的左心室肥厚、糖尿病和臨床性心臟瓣膜病。

圖 1 基于 Cox 回歸的腦卒中及死亡風(fēng)險(xiǎn)預(yù)測(cè)
該研究 [Wang et al. 2003] 的統(tǒng)計(jì)分析方法采用了 Cox 比例風(fēng)險(xiǎn)模型(proportional hazards model),是由英國統(tǒng)計(jì)學(xué)家 D.R. Cox 提出的一種半?yún)?shù)回歸模型。該模型以生存結(jié)局和生存時(shí)間為應(yīng)變量,可同時(shí)分析多個(gè)因素對(duì)生存期的影響,能分析帶有刪失生存時(shí)間的數(shù)據(jù),且不要求估計(jì)數(shù)據(jù)的生存分布類型。Cox 模型在醫(yī)學(xué)研究中得到了廣泛的應(yīng)用,是傳統(tǒng)生存分析和風(fēng)險(xiǎn)預(yù)測(cè)中應(yīng)用最多的多因素回歸分析方法。
腦卒中預(yù)測(cè)模型的評(píng)估考慮了校準(zhǔn)度(calibration)及區(qū)分度(discrimination)。校準(zhǔn)度是指預(yù)測(cè)結(jié)果和實(shí)際結(jié)果的一致度,用 Hosmer-Lemeshow(H-L)統(tǒng)計(jì)量評(píng)價(jià);區(qū)分度采用 c 統(tǒng)計(jì),即受試者工作特征曲線(receiver operating characteristic curve,又稱 ROC 曲線)下的面積(AUC)。腦卒中預(yù)測(cè)模型和腦卒中或死亡預(yù)測(cè)模型的 H-L 統(tǒng)計(jì)量分別為 7.6 和 6.5,腦卒中預(yù)測(cè)模型的 AUC 為 0.66,而腦卒中或死亡預(yù)測(cè)模型的 AUC 為 0.70。
基于機(jī)器學(xué)習(xí)方法的疾病預(yù)測(cè)
盡管傳統(tǒng)的回歸方法在疾病預(yù)測(cè)方面有廣泛的應(yīng)用,但這些方法在預(yù)測(cè)準(zhǔn)確度和模型可解釋方面,都仍有提升的空間。近年來,機(jī)器學(xué)習(xí)領(lǐng)域的特征選擇和有監(jiān)督學(xué)習(xí)建模方法越來越多地用于疾病預(yù)測(cè)問題。一些機(jī)器學(xué)習(xí)方法可以提高預(yù)測(cè)模型的可解釋性,例如決策樹方法。另一方面,一些較新的機(jī)器學(xué)習(xí)方法可以帶來更好的預(yù)測(cè)性能。
2010 年發(fā)表于 KDD 的文章 [Khosla et al. 2010] 采用了特征選擇和機(jī)器學(xué)習(xí)方法來預(yù)測(cè) 5 年內(nèi)的腦卒中發(fā)生率。該研究的數(shù)據(jù)來自心血管健康研究(CHS) 數(shù)據(jù)集,主要針對(duì) 65 歲以上人群。該數(shù)據(jù)記錄了 1989-1999 年 5021 位患者將近 1000 個(gè)的屬性數(shù)據(jù),包括醫(yī)療檢查,問卷,電話聯(lián)系等。預(yù)處理后最終的數(shù)據(jù)集包括 4988 個(gè)樣本,其中 299 個(gè)個(gè)體發(fā)生了腦卒中,共包含 796 個(gè)特征。數(shù)據(jù)被隨機(jī)分成 9:1 的訓(xùn)練集和測(cè)試集,同時(shí)保證正負(fù)樣本比例不變,方法流程見圖 2。
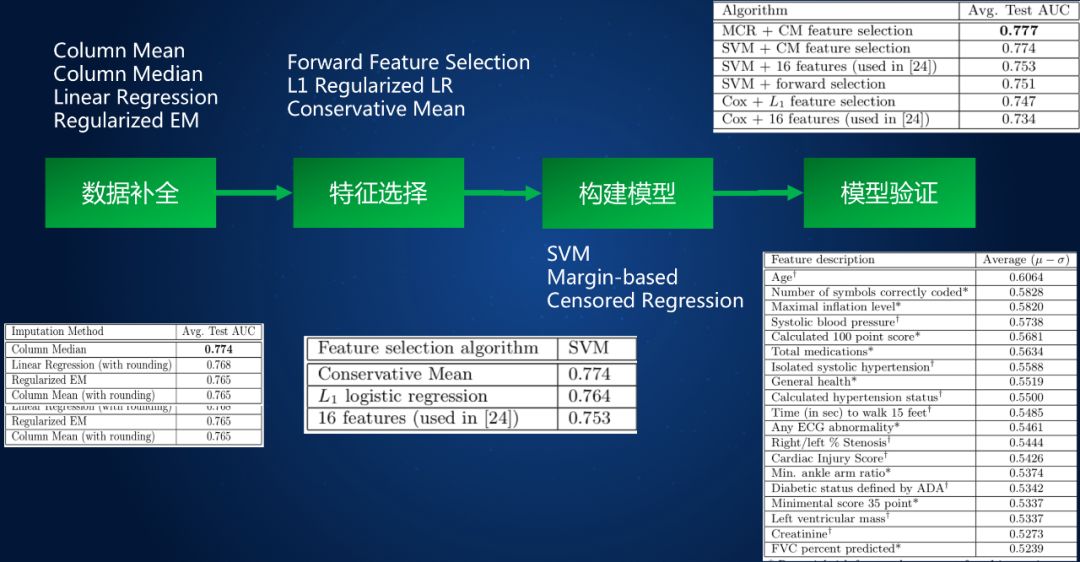
圖 2 基于機(jī)器學(xué)習(xí)的腦卒中風(fēng)險(xiǎn)預(yù)測(cè)
該研究采用了四種方法進(jìn)行缺失值填充,包括均值填充、中位數(shù)填充、線性回歸及期望最大化方法;特征選擇方法有 3 種,包括前向特征選擇、L1 正則化和保守均值特征選擇 (μ - σ);建模時(shí)嘗試了支持向量機(jī)(SVM)和基于邊緣的刪失回歸方法。使用 L1 正則化邏輯回歸進(jìn)行特征選擇,然后使用 SVM 進(jìn)行預(yù)測(cè),采用 10 倍交叉驗(yàn)證的平均測(cè)試 AUC 為 0.764,優(yōu)于 L1 正則化 Cox 模型。將各種特征選擇算法與預(yù)測(cè)算法相結(jié)合的平均顯示,保守均值和基于邊緣的刪失回歸相結(jié)合在 AUC 評(píng)價(jià)標(biāo)準(zhǔn)中能達(dá)到 0.777,為性能最佳的結(jié)果。
基于深度學(xué)習(xí)方法的疾病預(yù)測(cè)
近年來,深度學(xué)習(xí)技術(shù)飛速發(fā)展,對(duì)圖像識(shí)別、語音識(shí)別、自然語言理解等多個(gè)領(lǐng)域產(chǎn)生了顛覆性的改變。對(duì)于電子病歷數(shù)據(jù)分析方面,也已有一些研究利用深度學(xué)習(xí)方法來建立疾病風(fēng)險(xiǎn)預(yù)測(cè)模型,采用了 CNN 或 RNN 的模型。
[Cheng et al. 2016] 基于 30 余萬患者為期 4 年的電子健康檔案 (EHR) 數(shù)據(jù),采用 CNN 網(wǎng)絡(luò)來預(yù)測(cè)未來的疾病發(fā)生事件。研究的關(guān)鍵問題是如何從電子健康檔案的既往時(shí)序數(shù)據(jù)出發(fā),建立有效模型,預(yù)測(cè)患者疾病發(fā)生的風(fēng)險(xiǎn)概率。該研究的數(shù)據(jù)集來源于 319,650 例患者為期 4 年的真實(shí)電子健康檔案,抽取慢性心衰(CHF,充血性心力衰竭)和慢阻肺(COPD,慢性阻塞性肺病)相關(guān)數(shù)據(jù),其中 CHF 測(cè)試數(shù)據(jù)集包括 1127 正例患者,3850 負(fù)例對(duì)照;COPD 測(cè)試數(shù)據(jù)集包括 477 正例患者,2385 負(fù)例對(duì)照。該研究采用卷積神經(jīng)網(wǎng)絡(luò) (CNN) 作為有監(jiān)督學(xué)習(xí)模型,首先將每個(gè)患者的電子健康檔案數(shù)據(jù)簡(jiǎn)化映射為二維 EHR 矩陣,縱軸為患者臨床事件的類型,對(duì)應(yīng)到 ICD-9 的編碼,橫軸為患者臨床事件的發(fā)生時(shí)間,以天為計(jì)算單位。考慮 EHR 矩陣相關(guān)的特點(diǎn),該研究基于以下假設(shè)建立卷積神經(jīng)網(wǎng)絡(luò)模型:1)假設(shè)臨床事件之間不存在相關(guān)性;2)同一臨床事件在時(shí)間上存在相關(guān)性;3)不同患者入院的時(shí)間長(zhǎng)度不同,體現(xiàn)為 EHR 矩陣的大小不一致。文章最終采用了 INPUT-CONV-POOL-FC 共四層的卷積神經(jīng)網(wǎng)絡(luò)模型,方法流程如下圖 3 所示。
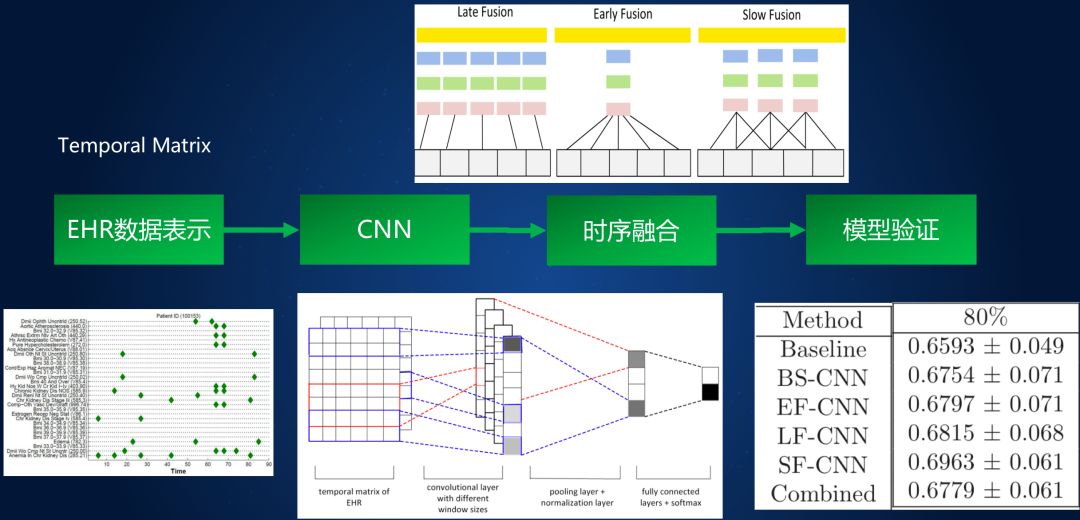
圖 3 卷積神經(jīng)網(wǎng)絡(luò)模型
因?yàn)榛颊叩碾娮咏】禉n案矩陣是變長(zhǎng)的,所以沿時(shí)間軸被分割為不同時(shí)段子矩陣,然后先針對(duì)每個(gè)子矩陣提取特征,再將不同子矩陣的特征集成。按照分割、提取、集成步驟的不同,該研究采用了幾種不同的集成方法,然后比較不同的方法在慢性心衰和慢阻肺兩組測(cè)試數(shù)據(jù)集上的預(yù)測(cè)性能。最終發(fā)現(xiàn)綜合分割、提取、集成的混合策略 SF-CNN 效果最好。
目前更多的人嘗試用RNN(Recurrent Neural Network)的方法來分析電子病歷中的臨床事件之前的時(shí)序關(guān)系(Temporal Relation)。[Chio et.al 2016] 在心衰(HF,Heart Failure)的預(yù)測(cè)上率先使用了基于RNN的方法,基于3884個(gè)正例和28,903個(gè)負(fù)例數(shù)據(jù),時(shí)間跨度從2000年5月,到2013年5月共3年的時(shí)間。針對(duì)單個(gè)臨床事件的建模采用了自然語言理解中常用的one-hot向量的方式,把任何一個(gè)臨床事件都表示成N維的向量,但向量的最后一位是事件發(fā)生時(shí)間距離預(yù)測(cè)時(shí)間的間隔,類似于一個(gè)時(shí)間戳(timestamp)。然后使用了GRU(Gated Recurrent Unit,門循環(huán)單元)從每個(gè)輸入的臨床事件向量計(jì)算相應(yīng)的隱狀態(tài),在最終的隱狀態(tài)上應(yīng)用邏輯回歸模型計(jì)算最后的HF風(fēng)險(xiǎn)概率。跟LR(Logistic Regression),SVM和KNN等多種經(jīng)典回歸或機(jī)器學(xué)習(xí)方法試驗(yàn)對(duì)比后發(fā)現(xiàn),基于RNN方法的預(yù)測(cè)AUC有提高。
疾病預(yù)測(cè)技術(shù)小結(jié)
從以上針對(duì)經(jīng)典回歸方法、機(jī)器學(xué)習(xí)方法和深度學(xué)習(xí)方法的分析可以發(fā)現(xiàn),疾病預(yù)測(cè)技術(shù)必要的組成部分包括數(shù)據(jù)補(bǔ)全、特征表示、特征選擇和預(yù)測(cè)建模等幾個(gè)關(guān)鍵步驟,總結(jié)見表 1。
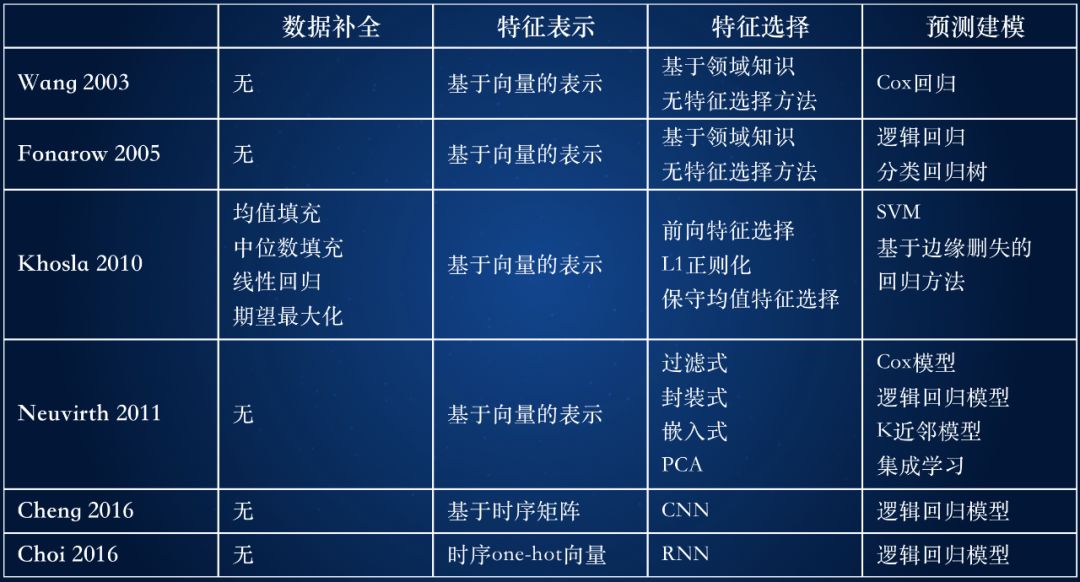
表 1 疾病預(yù)測(cè)方法分析對(duì)比
從中可以看出:
預(yù)測(cè)建模的方法本身并沒有太多的突破:除了 [Khosla et al. 2010] 融合了 SVM 和 Cox 回歸的特性發(fā)明了基于邊緣刪失的回歸方法,絕大多數(shù)的工作創(chuàng)新集中在特征表示和特征選擇。
患者特征從基于向量的表示方法向時(shí)序矩陣轉(zhuǎn)變:經(jīng)典的機(jī)器學(xué)習(xí)和統(tǒng)計(jì)方法普遍采用基于向量的表示方法,采用多種特征選擇算法提取最有預(yù)測(cè)能力的特征。最新的深度學(xué)習(xí)的方法采用時(shí)序矩陣或時(shí)序向量的方法,盡量捕捉真實(shí)世界數(shù)據(jù)中的時(shí)序信號(hào)。
深度學(xué)習(xí)方法變革了特征提取方法,但降低了可解釋性:在特征選擇時(shí)通過 CNN 或 RNN 的方法對(duì)原始特征進(jìn)行多層的變換,把原始特征映射到新的空間中,提高分類的能力,但同時(shí)降低了模型的可解釋性。
疾病預(yù)測(cè)技術(shù)的發(fā)展趨勢(shì)
疾病預(yù)測(cè)技術(shù)的研究可以關(guān)注下面兩個(gè)重點(diǎn):
基于多模態(tài)數(shù)據(jù)的預(yù)測(cè):醫(yī)療數(shù)據(jù)是多模態(tài)的,包含結(jié)構(gòu)化數(shù)據(jù)、文本、影像和流數(shù)據(jù)(心率、血氧、呼吸等)。目前的預(yù)測(cè)方法主要處理結(jié)構(gòu)化的數(shù)據(jù),如果需要文本、影像或者流數(shù)據(jù)中的特征,就先用某些方法把需要的特征從這些非結(jié)構(gòu)化數(shù)據(jù)中抽取出來。如何借助多個(gè)端到端的網(wǎng)絡(luò)處理多模態(tài)的數(shù)據(jù)并進(jìn)行融合、預(yù)測(cè)是很重要的技術(shù)挑戰(zhàn)。
醫(yī)學(xué)領(lǐng)域知識(shí)和機(jī)器學(xué)習(xí)方法的融合預(yù)測(cè):在目前的疾病預(yù)測(cè)方法中,醫(yī)學(xué)領(lǐng)域知識(shí)和機(jī)器學(xué)習(xí)方法是割裂的。經(jīng)典的統(tǒng)計(jì)方法完全基于醫(yī)學(xué)領(lǐng)域知識(shí)手工的挑選待選特征,然后利用統(tǒng)計(jì)的方法計(jì)算每個(gè)特征的重要性,構(gòu)建預(yù)測(cè)模型。機(jī)器學(xué)習(xí)的方法則完全從數(shù)據(jù)出發(fā),并不參考在某個(gè)預(yù)測(cè)領(lǐng)域中過去幾十年積累的已知的風(fēng)險(xiǎn)因素和權(quán)重,也不重視模型的可解釋性,用特征表示和提取的方法從海量數(shù)據(jù)中自動(dòng)的提取特征,構(gòu)建模型。如何有效的融合醫(yī)學(xué)領(lǐng)域知識(shí)和機(jī)器學(xué)習(xí)方法,構(gòu)建可解釋性強(qiáng)的預(yù)測(cè)模型是未來技術(shù)創(chuàng)新的重要方向。
最后,感謝萬祎,賈文笑和李非同學(xué)對(duì)本文的貢獻(xiàn),更要感謝每一位有耐心看完這篇長(zhǎng)文的讀者。
-
醫(yī)療
+關(guān)注
關(guān)注
8文章
1881瀏覽量
59639 -
人工智能
+關(guān)注
關(guān)注
1804文章
48734瀏覽量
246653 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8492瀏覽量
134118
原文標(biāo)題:【大咖解讀】謝國彤:疾病預(yù)測(cè)的機(jī)器學(xué)習(xí)、深度學(xué)習(xí)和經(jīng)典回歸方法
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【卡酷機(jī)器人】——基礎(chǔ)學(xué)習(xí)方法
FPGA技術(shù)的學(xué)習(xí)方法
單片機(jī)的學(xué)習(xí)方法和步驟
一套科學(xué)的嵌入式系統(tǒng)學(xué)習(xí)方法
一種融合節(jié)點(diǎn)先驗(yàn)信息的圖表示學(xué)習(xí)方法
深度解析機(jī)器學(xué)習(xí)三類學(xué)習(xí)方法
如何學(xué)好機(jī)器學(xué)習(xí)?機(jī)器學(xué)習(xí)的學(xué)習(xí)方法4個(gè)關(guān)鍵點(diǎn)整理概述
機(jī)器學(xué)習(xí)入門寶典《統(tǒng)計(jì)學(xué)習(xí)方法》的介紹
面向人工智能的機(jī)器學(xué)習(xí)方法體系總結(jié)

區(qū)塊鏈數(shù)據(jù)集有怎樣的機(jī)器學(xué)習(xí)方法
機(jī)器學(xué)習(xí)方法遷移學(xué)習(xí)的發(fā)展和研究資料說明

深度討論集成學(xué)習(xí)方法,解決AI實(shí)踐難題
融合零樣本學(xué)習(xí)和小樣本學(xué)習(xí)的弱監(jiān)督學(xué)習(xí)方法綜述

聯(lián)合學(xué)習(xí)在傳統(tǒng)機(jī)器學(xué)習(xí)方法中的應(yīng)用
傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論