 LM Studio使用NVIDIA技術加速LLM性能
LM Studio使用NVIDIA技術加速LLM性能
隨著 AI 使用場景不斷擴展(從文檔摘要到定制化軟件代理),開發者和技術愛好者正在尋求以更 快、更靈活的方式來運行大語言模型(LLM)。
在配備 NVIDIA GeForce RTX GPU 的 PC 上本地運行模型,可實現高性能推理、增強型數據隱私保護,以及對 AI 部署與集成的完全控制。LM Studio 等工具(可免費試用)使這一切成為可能,為用戶提供了在自有硬件上探索和構建 LLM 的便捷途徑。
LM Studio 已成為最主流的本地 LLM 推理工具之一。該應用基于高性能 llama.cpp 運行時構建,支持完全離線運行模型,還可作為兼容 OpenAI 應用編程接口(API)的端點,無縫集成至定制化工作流程。
得益于 CUDA 12.8,LM Studio 0.3.15 的推出提升了 RTX GPU 的性能,模型加載和響應時間均有顯著改善。此次更新還推出數項面向開發者的全新功能,包括通過“tool_choice”參數增強工具調用能力和重新設計的系統提示詞編輯器。
LM Studio 的最新改進提高了它的性能和易用性——實現了 RTX AI PC 上迄今最高的吞吐量。這意味著更快的響應速度、更敏捷的交互體驗,以及更強大的本地 AI 構建與集成工具。
日常 App 與 AI 加速相遇
LM Studio 專為靈活性打造 —— 既適用于隨意的實驗,也可完全集成至定制化工作流。用戶可以通過桌面聊天界面與模型交互,或啟用開發者模式部署兼容 OpenAI API 的端點。這使得將本地大語言模型連接到 VS Code 等應用的工作流或定制化桌面智能體變得輕而易舉。
例如,LM Studio 可以與 Obsidian 集成,后者是一款廣受歡迎的 Markdown 知識管理應用。使用 Text Generator 和 Smart Connections 等社區開發的插件,用戶可以生成內容、對研究進行摘要并查詢自己的筆記 —— 所有功能均由基于 LM Studio 運行的本地大語言模型提供支持。這些插件直接連接到 LM Studio 的本地服務器,無需依賴云服務即可實現快速且私密的 AI 交互。
使用 LM Studio 生成由 RTX 加速的筆記的示例
0.3.15 更新新增多項開發者功能,包括通過“tool_choice”參數實現更細粒度的工具控制,以及經過升級、支持更長或更復雜提示詞的系統提示詞編輯器。
tool_choice 參數使開發者能夠控制模型與外部工具的交互方式 —— 無論是強制調用工具、完全禁用工具,還是允許模型動態決策。這種增強的靈活性對于構建結構化交互、檢索增強生成(RAG)工作流或智能體工作流尤為重要。這些更新共同增強了開發者基于大語言模型開展實驗和生產用途兩方面的能力。
LM Studio 支持廣泛的開源模型(包括 Gemma、Llama 3、Mistral 和 Orca),支持從 4 位到全精度的各種量化格式。
常見場景涵蓋 RAG、長上下文窗口多輪對話、基于文檔的問答和本地智能體工作流。而 NVIDIA RTX 加速的 llama.cpp 軟件庫可以作為本地推理服務器,讓 RTX AI PC 用戶輕松利用本地大語言模型。
無論是為緊湊型 RTX 設備實現能效優化,還是在高性能臺式機上更大限度地提高吞吐量,LM Studio 能夠在 RTX 平臺上提供從全面控制、速度到隱私保障的一切。
體驗 RTX GPU 的最大吞吐量
LM Studio 加速的核心在于 llama.cpp —— 這是一款專為基于消費級硬件進行高效推理而設計的開源運行時。NVIDIA 與 LM Studio 和 llama.cpp 社區展開合作,集成多項增強功能,以盡可能充分地發揮 RTX GPU 的性能。
關鍵優化包括:
CUDA 計算圖優化:將多個 GPU 操作聚合為單次 CPU 調用,從而降低 CPU 負載并可將模型吞吐量提高最多達 35%。
Flash Attention CUDA 內核:通過改進大語言模型的注意力處理機制(Transformer 模型的核心運算),實現吞吐量額外提升 15%。這可以在不增加顯存或算力需求的前提下,支持更長的上下文窗口。
支持最新 RTX 架構:LM Studio 升級至 CUDA 12.8 版本,確保全面兼容從 GeForce RTX 20 系列到 NVIDIA Blackwell 架構 GPU 的全部 RTX AI PC 設備,使用戶能夠靈活擴展其本地 AI 工作流 —— 從筆記本電腦到高端臺式機。
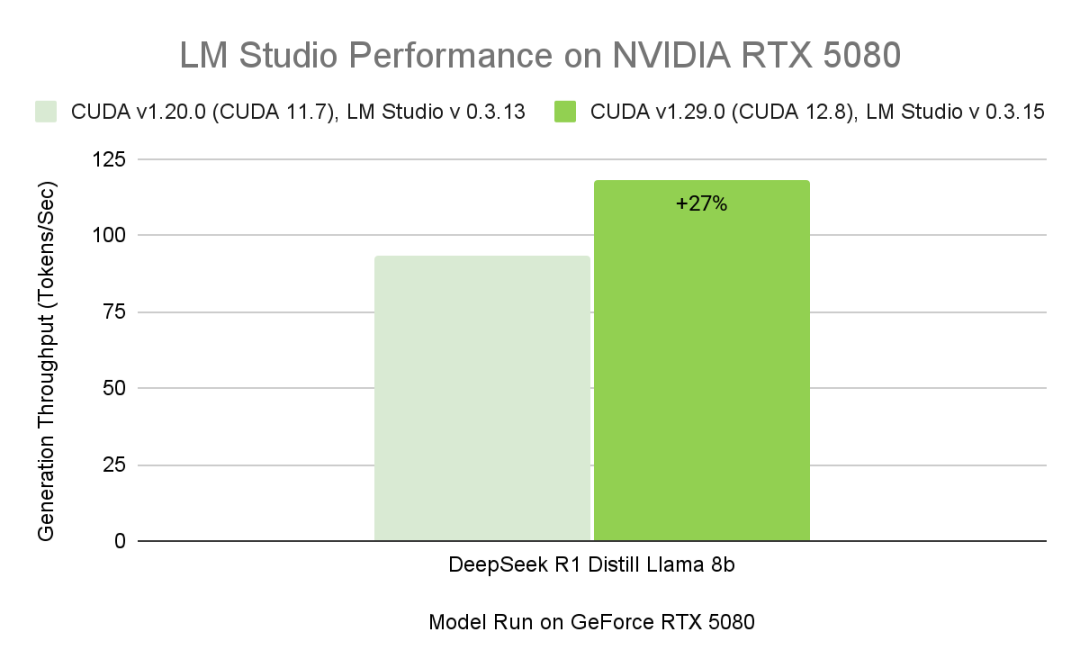
數據展示了不同版本的 LM Studio 和 CUDA 后端在 GeForce RTX 5080 上運行 DeepSeek-R1-Distill-Llama-8B 模型的性能數據。所有配置均使用 Q4_K_M GGUF(Int4)量化,在 BS=1、ISL=4000、OSL=200 并開啟 Flash Attention 的條件下測量。得益于 NVIDIA 對 llama.cpp 推理后端的貢獻,CUDA 計算圖在最新版本的 LM Studio 中實現了約 27% 的加速。
借助兼容的驅動,LM Studio 可自動升級到 CUDA 12.8 運行時,從而顯著縮短模型加載時間并提高整體性能。
這些增強功能顯著提升了所有 RTX AI PC 設備的推理流暢度與響應速度 —— 從輕薄筆記本到高性能臺式機與工作站。
LM Studio 使用入門
LM Studio 提供免費下載,支持 Windows、macOS 和 Linux 系統。借助最新的 0.3.15 版本以及持續優化,用戶將在性能、定制化與易用性方面得到持續提升 —— 讓本地 AI 更快、更靈活、更易用。
用戶既能通過桌面聊天界面加載模型,也可以啟用開發者模式,開放兼容 OpenAI API 的接口。
要快速入門,請下載最新版本的 LM Studio 并打開應用。
1、點擊左側面板上的放大鏡圖標以打開 Discover(發現)菜單。
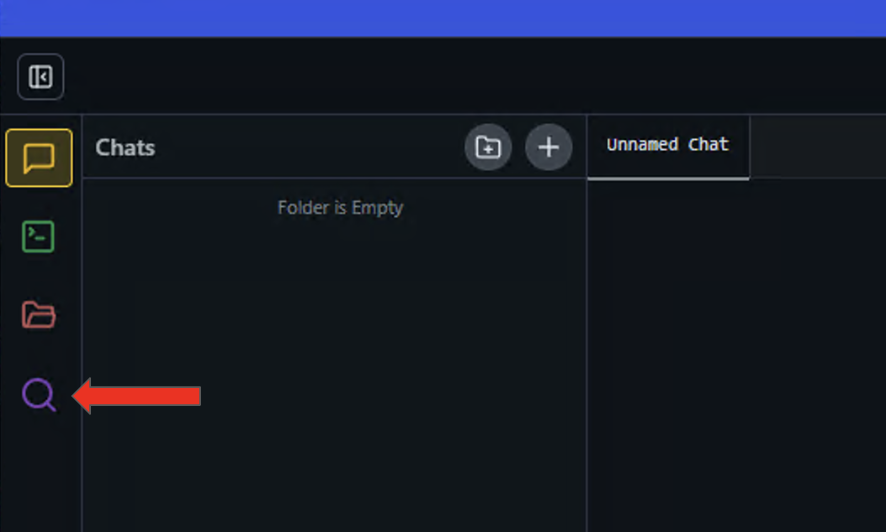
2、選擇左側面板中的運行時設置,然后在可用性列表中搜索 CUDA 12 llama.cpp(Windows)運行時。點擊按鈕進行下載與安裝。
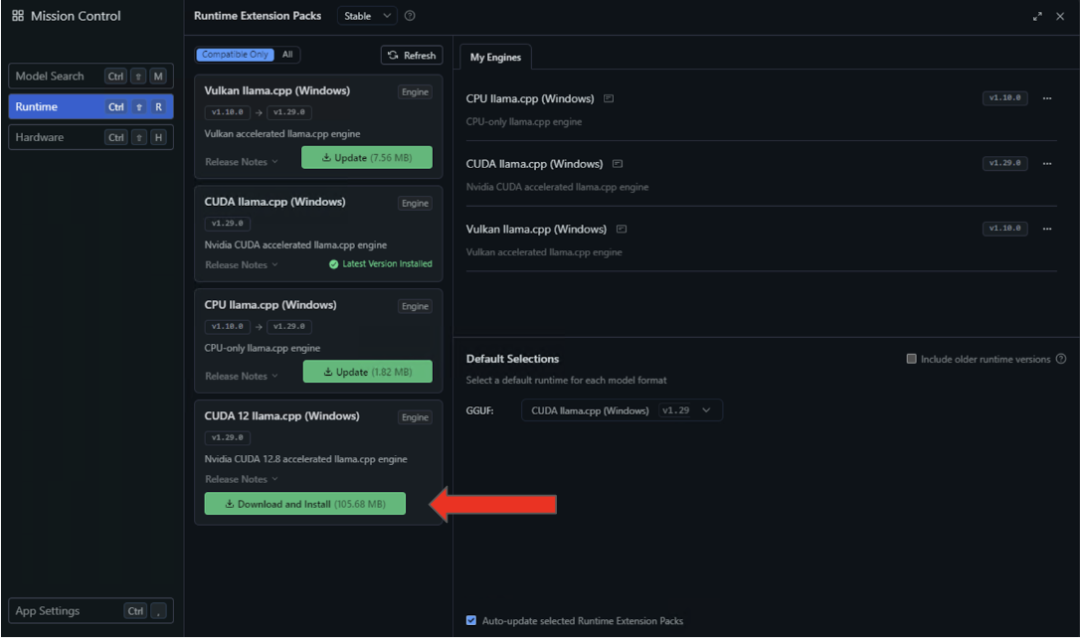
3、安裝完成后,通過在“默認選擇”下拉菜單中選擇 CUDA 12 llama.cpp(Windows),將 LM Studio 默認配置為此運行時環境。
4、完成 CUDA 執行優化的最后步驟:在 LM Studio 中加載模型后,點擊已加載模型左側的齒輪圖標進入設置菜單。

5、在展開的下拉菜單中,將“Flash Attention”功能切換為開啟狀態,并通過向右拖動“GPU Offload”(GPU 卸載)滑塊將所有模型層轉移至 GPU。
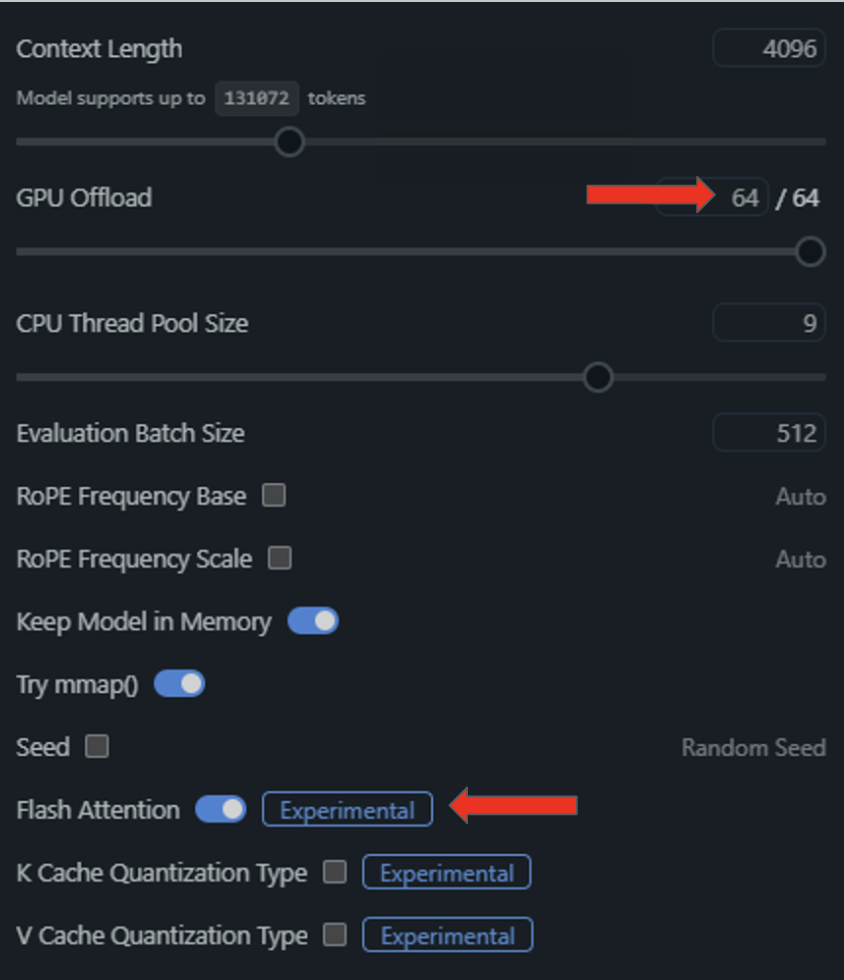
完成這些功能的啟用與配置后,即可在本地設備上運行 NVIDIA GPU 推理任務了。
LM Studio 支持模型預設、多種量化格式及開發者控制項比如 tool_choice,以實現調優的推理。對于希望參與貢獻的開發者,llama.cpp 的 GitHub 倉庫持續積極維護,并隨著社區與 NVIDIA 驅動的性能優化持續演進。
-
NVIDIA
+關注
關注
14文章
5246瀏覽量
105793 -
Studio
+關注
關注
2文章
206瀏覽量
29527 -
LLM
+關注
關注
1文章
320瀏覽量
687
原文標題:LM Studio 借助 NVIDIA GeForce RTX GPU 和 CUDA 12.8 加速 LLM 性能
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
低比特量化技術如何幫助LLM提升性能

《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA Jetson介紹
NVIDIA Studio開創創意性能的新時代
NVIDIA Studio技術如何加速創意工作流
HPC China 2022 | 相聚云端,NVIDIA 加速高性能計算分論壇邀請函
GTC 大會亮點 NVIDIA Studio AI 助力藝術加速
GTC23 | NVIDIA 高性能加速網絡專場限時回放已開啟!
Nvidia 通過開源庫提升 LLM 推理性能
周四研討會預告 | 注冊報名 NVIDIA AI Inference Day - 大模型推理線上研討會
現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理

NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
LLM大模型推理加速的關鍵技術
解鎖NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化






 工商網監
工商網監
評論