 從校園實驗室到京東零售:一位算法工程師的風控實戰錄
從校園實驗室到京東零售:一位算法工程師的風控實戰錄

大家好,我是王曉婷,在京東零售研究廣告反作弊算法設計、實現與優化,結合LLM、深度學習、強化學習賦能反作弊系統,用算法識別和打擊數字廣告領域的欺詐行為。本文與大家分享我從高校實驗室到廣告風控戰場的蛻變,一場關于認知覺醒、技術探索與思維重構的旅程。
象牙塔與工業界的思維碰撞
在清華園求學期間,我開始接觸數據挖掘競賽,那時常沉浸于算法優化的世界里。和許多初學者一樣,我認為模型指標就是解決問題的萬能鑰匙,一次一次在異常檢測項目中投入大量精力,當在看到95%+準報率和低于0.35%的誤報率時,那種純粹的喜悅讓我對技術產生了近乎理想化的信仰。
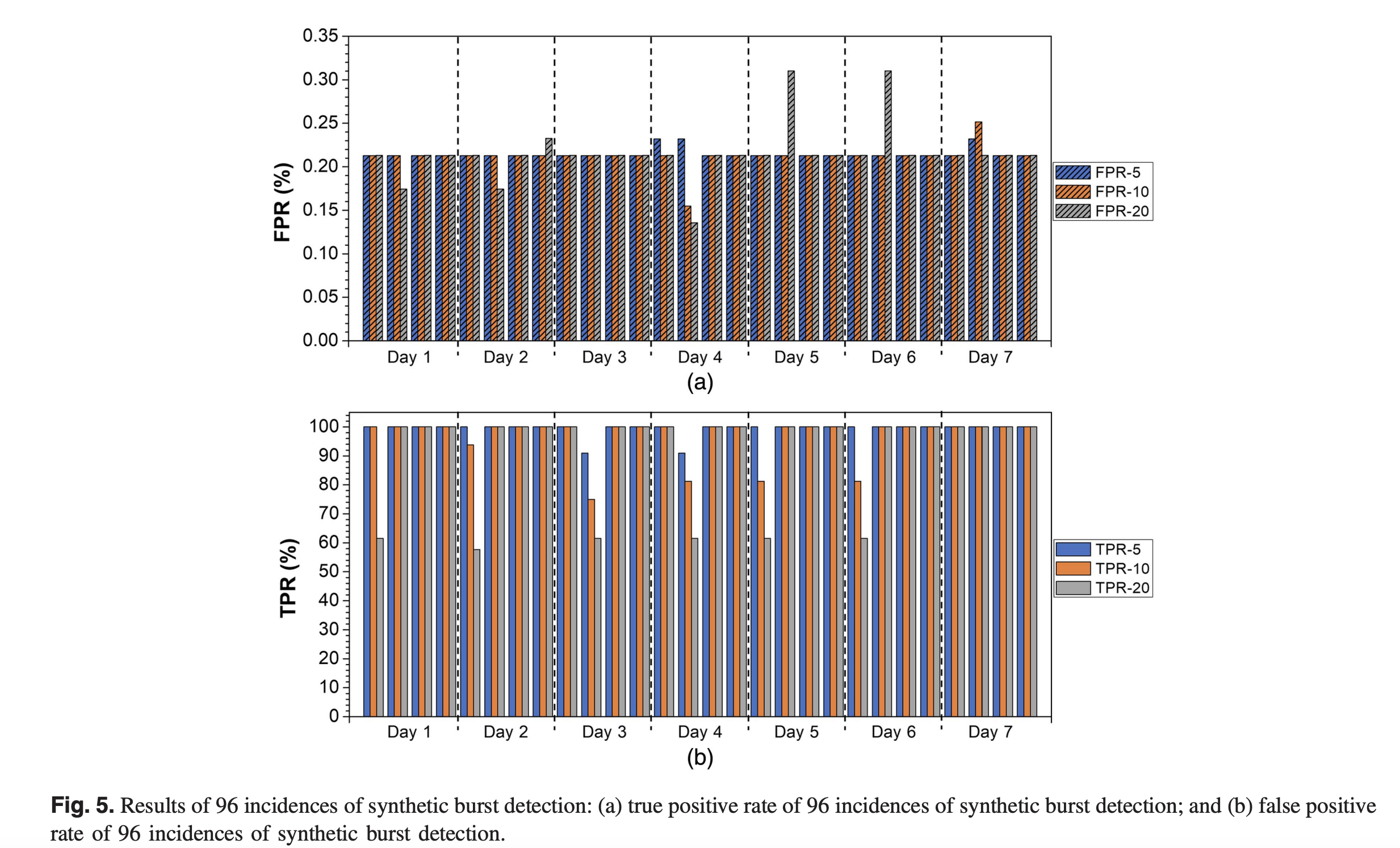
圖1. 曾發表論文中算法取得的高準異常檢測結果(誤報率僅為0.35%以下)
實驗室的環境確實為研究提供了理想條件:規整的數據集、清晰的問題邊界、穩定的評估體系。這種純粹的科研訓練讓我打下了扎實的基礎,但也無形中構建了某種思維定式。
畢業后,我加入京東,投身于廣告風控的實戰戰場,一場認知的風暴悄然來襲,在一次電商大促期間,現實給我上了深刻的一課。面對流量洪峰、以及洪峰中涌現的虛假流量,我曾引以為傲且平穩調度的模型出現了資源和作弊識別之間的掣肘,實驗室里的“完美指標”、優秀的“AUC、TPR、FPR”,在海量流量面前凸顯蒼白,工業界需要的是能在混沌中能持續進化的解決方案。面對這樣的挑戰和日新月異的反作弊需求,迫使我重新審視技術應用的邊界,在技術可能性、業務價值與實施成本之間尋找平衡點,這個過程至今仍在持續。
京東的“反作弊大腦”就像一位24小時在線的智能偵探,主要從多維度打擊作弊行為:在用戶端利用大模型識別假交易,通過智能算法自動揪出異常訂單;在流量端分析每個廣告點擊的數百項特征,一旦發現異常行為,立刻攔截,保障廣告主的每一分錢都花在真實用戶身上。
技術偵探,用AI破解黑產的加密暗號
CPS模式本是為激勵優質推廣設計的共贏機制,在激勵眾多聯盟伙伴積極推廣的同時,也滋生了黑灰產的關注。在廣告CPS中,黑灰產為了騙取平臺傭金,極盡所能地在地址信息中藏匿各種暗號,這些暗號仿若隱秘的“密碼”,在看似平常的地址文本中隱匿著其真實的不軌意圖,損害平臺利益,致使CPS傭金流失。
一種典型的作弊方式是,在用戶下單時填寫一個無法正常派送的“真假參半”地址。黑灰產為了實現不法目的,精心設計出各種暗號嵌入地址信息,給傳統文本檢測方法帶來了巨大挑戰。
面對這種新型作弊手段,我們持續觀測數據,發現即便不斷添加過濾規則,異常訂單仍像地鼠般此起彼伏,基于正則表達式的策略方式無法適應日新月異的暗號變種。這讓我意識到:必須突破文本表面特征,深入語義層面理解地址信息(詳細細節見 文本異常檢測:利用大模型偵測地址暗號 )。
在團隊技術討論中,我嘗試將大模型引入檢測系統。在NLP的世界里,大模型如同超級偵探通過深度的網絡層和億級參數,超前掌握語言的深層次結構和語義。在地址異常檢測問題中,大模型的核心能力也能得到很好發揮。基于開源大語言模型并結合LoRA微調技術降低訓練成本,讓人工標注的數千條異常地址樣本教會模型識別"異常模式"。
其次,在地址的生成式識別中,我基于人類反饋的強化學習框架(RHLF框架),在模型給予錯誤答案時及時糾偏,并會及時收集人類專家的判斷,并將這些反饋納入強化學習過程。
通過LLM+RHLF訓練,模型逐漸學會了根據上下文來判斷數字是否屬于暗號的“生成式識別能力”。比如在類似”3棟78910單元1023室”、“3棟2單元1023室ATTTT233”這樣的地址中,大模型通過生成式推理識別出"78910"、“ATTTT233”這類偽裝地址,實現了異常訂單地址的生成式精準抓取,這正是傳統正則表達式無法企及的語義穿透力和識別能力。
經過了三個版本的迭代優化,這套系統實現了精準識別與高效運行的平衡,模型的誤判率降至0.3%,實現準確識別出各類顯性暗號和隱蔽性暗號。這也是我第一次通過將大模型技術與CPS業務場景深度融合,構建了更加精準和高效的反作弊防護體系。
不做最炫的技術,只做最有效的方案
隨著廣告作弊手段的不斷升級進化,反作弊技術正面臨前所未有的挑戰。從早期的單一IP代理,到如今的分布式攻擊網絡;從簡單的機器群控,到精心設計的真人騙傭產業鏈,黑產集團正在以驚人的速度迭代他們的作弊手法。這種"道高一尺,魔高一丈"的對抗態勢,讓傳統的基于統計規則的防御體系逐漸力不從心。就像一位經驗豐富的老刑警突然面對一群裝備精良的高智商罪犯,舊有的破案方法開始顯得捉襟見肘。
在這樣的背景下,我們嘗試將大模型的上下文理解能力引入行為序列分析領域。基于LLM技術,我們構建了一套全新的反作弊系統(詳細細節見 AIGC風控系統:大模型重塑廣告安全新范式 )。這套系統就像一位擁有超強洞察力的偵探,通過深度解析用戶行為軌跡中的矛盾點,識別隱藏在正常交互模式下的異常信號。
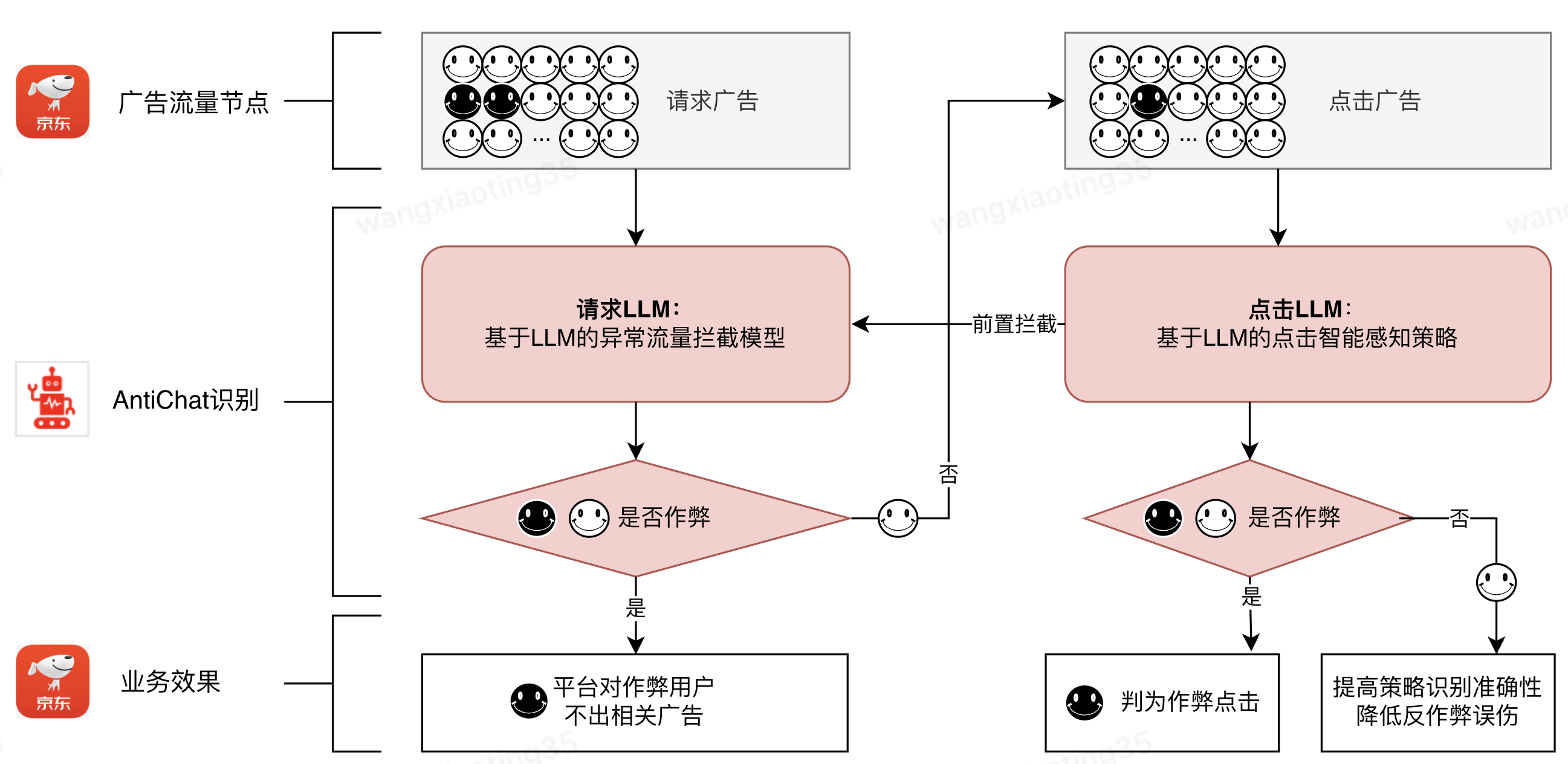
圖2:基于LLM的流量多階段防御
然而,面對京東主站的巨大流量,LLM雖然具備獲得優秀的生成式識別能力,卻很難在當前資源和耗時要求下實現實時在線推理。為了解決這個“既要精準又要快速”的難題,我采用了蒸餾技術:讓大模型擔任”資深教授”,小模型作為“尖子生”,通過特征層蒸餾,將大模型的“辦案經驗”提煉傳授給小模型,經過十余個版本的迭代打磨,最終實現了精度與速度的完美平衡。
這個過程中,我深刻體會到:真正的技術創新,不是簡單粗暴地把最新技術塞進業務場景,而是要在學術前沿與工業實踐之間找到那個微妙的平衡點。像一位技藝精湛的工匠,既要知道最先進的工具怎么用,更要明白什么時候該用什么樣的工具。這種平衡不僅需要對技術有深刻的理解,還需要對業務有深入的洞察。
在從學術研究到工業實踐的跨越中,我深刻體會到廣告風控的本質是一場多維度的復雜博弈。有三點核心認知與各位分享:
1. 成本意識驅動技術選型,技術人也要會算賬
在公司海量流量和實戰場景中,技術人不僅要關注技術本身的先進性,還需要從數據規模、計算成本和產出價值三個維度綜合評估模型的應用。數據規模決定了模型的訓練深度,而計算成本則直接影響到模型的實時性。最終,產出價值體現在誤判率的降低和業務損失的減少上。
技術方案不是越fancy越好,現在每次做模型選型,我都會清晰評估,每提升1%準確率需要多少標注成本?降低10ms延遲能多攔截多少欺詐訂單?這種量化思維幫助我們找到技術投入的黃金平衡點。
2. 持續進化知識體系,充分熟悉業務
在閱讀《Attention Is All You Need》等專業文獻時,我發現了Attention機制在異常檢測中的巨大潛力,并成功將其應用于自部署大語言模型的優化。這一過程中,我學會了如何從大量的研究成果中篩選出對業務有價值的洞見和創新想法。這不僅需要對技術有深刻的理解,還需要具備敏銳的技術敏感度,能夠快速識別和應用前沿技術。
此外,知識體系不僅包括上述的算法前沿,也包括業務洞察力的鉆研能力,只有充分熟悉業務,才能快速通過算法賦能業務,為技術的迭代和創新制定堅實的基礎。
3. 跨領域思考,擁有主動破局的力量
在面對黑產日新月異的攻擊時,我們必須比對手進化得更快。在處理CPS傭金欺詐的場景中,我利用博弈論模型預測黑灰產可能使用的地址暗號設計模式,并提前調整檢測prompt,以此來阻止他們的欺詐行為。這種方法就像是在一場智力游戲中,通過預測對手的下一步行動,提前布局,從而保持主動。
在面對黑產帶來的虛假流量時,我借鑒了復雜系統理論中的耗散結構理論,應對“作弊熵增”的問題。黑產的攻擊手段越來越復雜,像是一個不斷變化的系統,為了應對這種變化,我在防御系統中引入了隨機性和非線性反饋機制,使得我們的防御系統能夠像一個活的有機體一樣,具備自適應和進化的能力。
寫在最后
技術人需要構建"T型能力":既要具備垂直領域的技術深度,又要擁有橫向拓展的視野廣度。
這種能力結構不僅能有效應對當前的業務挑戰,更能為未來的技術革新提供堅實基礎。我也要求自己持續精進技術深度、敏銳培養商業敏感度、始終堅守人文關懷。不斷探索大模型的技術潛力,深入理解業務的核心訴求,同時確保技術應用始終符合倫理規范和用戶利益。
技術人的浪漫,或許就在于這種永不停歇的攻防之舞。每當看到凌晨的A/B test中降低的后鏈路作弊率,看板中實現的業務目標,上線帶來的一次次可觀價值,都是數字時代風控守護者的微小確幸。
審核編輯 黃宇
-
算法
+關注
關注
23文章
4705瀏覽量
95084 -
京東云
+關注
關注
0文章
175瀏覽量
128
發布評論請先 登錄
重構零售數智化:Splashtop 8大核心場景應用實踐

微軟邀您相約2025全零售AI火花大會
實驗室安全管理成焦點,漢威科技賦能實驗室安全升級
從零到一:集成電路封裝測試實驗室建設的關鍵要素

MWC 2025 | 移遠通信推出AI智能無人零售解決方案,以“動態視覺+邊緣計算”引領智能零售新潮流

TüV萊茵蘇州汽車零部件實驗室獲奇瑞汽車認可

京東零售數據資產能力升級與實踐





 工商網監
工商網監
評論